






IOC(控制反转)
一、概念
IOC(Inversion of Control),控制反转。——是一种解耦的设计思想。
所谓的控制反转,就是指将对象的创建,对象的存储(map),对象的管理(依赖查找,依赖注入)交给了spring容器。
(spring容器是spring中的一个核心模块,用于管理对象)
在此之前,当需要对象时,通常是利用new关键字创建一个对象:
//1.创建一个Hello对象
Hello hello = new Hello();
//2.调用hello对象的方法
hello.sayHi();
但由于new对象,会提高代码之间耦合性.
所谓的耦合指的是在软件开发中,在层与层之间产生了某种紧密的关系。这种关系可能会导致,在我们修改或者是替换某一层时会影响其他的层,像这种情况我们就称之为层与层之间产生了耦合。
由于耦合(层与层之间的紧密关系)可能会导致我们在修改某一层时影响到其他的层,而这严重违反了我们对软件进行分层的最初设想 – 软件各层之间应该相互独立、互不干扰,在修改或者是替换某一层时,应该做到不影响其他层。
而使用spring框架,对象的创建可以交给spring来做:
//1.从spring容器中获取bean对象(而不是自己new)
Hello hello = (Hello) ac.getBean("hello");
//2.调用hello对象的方法
hello.sayHi();
只需要将类提前配置在spring配置文件中,就可以将对象的创建交给spring容器,当需要对象时,不需要自己创建,而是直接通过spring获取即可,省去了new对象,可以降低代码之间的耦合性。
二、IOC入门案例
创建Maven—Java工程
引入spring的jar包:在maven工程的pom.xml文件中添加如下配置
<!-- 集中定义依赖版本号 -->
<properties>
<junit.version>4.10</junit.version>
<spring.version>4.1.3.RELEASE</spring.version>
</properties>
<dependencies>
<!-- 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<!-- Spring -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>${spring.version}</version>
</dependency>
</dependencies>
导入后保存pom文件,项目如图所示:
在工程的java/resources目录下,创建applicationContext.xml文件:
在applicationContext.xml中添加如下内容(下面的配置不需要掌握,只是一个文件格式):
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context" xmlns:p="http://www.springframework.org/schema/p"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.0.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-4.0.xsd">
</beans>
创建Hello实体类

在Hello类中添加方法如下:
package com.tedu.spring;
public class Hello {
public void sayHi(){
System.out.println("Hello.sayHi()...");
}
}
将Hello对象的创建交给Spring容器来管理,在核心配置文件中添加如下配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context" xmlns:p="http://www.springframework.org/schema/p"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.0.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-4.0.xsd">
<!-- 声明bean对象,id是唯一标志,class:bean对象的全路径 -->
<bean id="hello" class="com.tedu.spring.Hello"></bean>
</beans>
创建TestIOC测试类

测试步骤及代码如下:
package com.tedu.spring;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TestIOC {
public static void main(String[] args) {
/* 通过spring容器创建创建Hello对象,
* 并调用Hello中的sayHi方法 */
//1.加载spring的核心配置文件
ClassPathXmlApplicationContext ac =
new ClassPathXmlApplicationContext(
"applicationContext.xml"
);
//2.从spring容器中获取bean对象(而不是自己new)
Hello hello = (Hello) ac.getBean("hello");
//3.调用hello对象的方法
hello.sayHi();
}
}
运行结果:

三、IOC小结
这就是spring框架的IOC——控制反转。之前我们自己new对象,例如:User u = new User();而现在,变成由一个初始化的xml配置文件来创建,也就是由spring容器来创建。
Hello hello = (Hello) ac.getBean(“hello”);
当程序运行,spring开始工作后,会加载整个xml核心配置文件,读取到,获取到class属性中类的全路径,利用反射创建该类的对象。
四、Bean对象的单例和多例
1、Bean对象的单例和多例概述
在Spring容器中管理的Bean对象的作用域,可以通过scope属性或用相关注解指定其作用域。
最常用是singleton(单例)或prototype(多例)。其含义如下:
1) singleton:单实例,是默认值。这个作用域标识的对象具备全局唯一性。
当把一个 bean 定义设置scope为singleton作用域时,那么Spring IOC容器只会创建该bean定义的唯一实例。也就是说,整个Spring IOC容器中只会创建当前类的唯一一个对象。
这个单一实例会被存储到单例缓存(singleton cache)中,并且所有针对该bean的后续请求和引用都 将返回被缓存的、唯一的这个对象实例。
singleton负责对象的创建、初始化、销毁。
2) prototype:多实例。这个作用域标识的对象每次获取都会创建新的对象。
当把一个 bean 定义设置scope为singleton作用域时,Spring IOC容器会在每一次获取当前Bean时,都会产生一个新的Bean实例(相当于new的操作)
prototype只负责对象的创建和初始化,不负责销毁。
2、为什么用单实例或多实例?
之所以用单实例,在没有线程安全问题的前提下,没必要每个请求都创建一个对象,这样子既浪费CPU又浪费内存;
之所以用多例,是为了防止并发问题;即一个请求改变了对象的状态(例如,可改变的成员变量),此时对象又处理另一个请求,而之前请求对对象状态的改变导致了对象对另一个请求做了错误的处理;
用单例和多例的标准只有一个:当对象含有可改变的状态时(更精确的说就是在实际应用中该状态会改变),使用多实例,否则单实例;
在Spring中配置Bean实例是单例还是多例方法是:
单例:
<bean id="hello" scope="singleton" class="com.tedu.spring.Hello"></bean>
多例:
<bean id="hello" scope="prototype" class="com.tedu.spring.Hello"></bean>
3、测试spring的单实例和多实例
创建TestIOC2类,测试代码如下:
package com.tedu.spring;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TestIOC2 {
public static void main(String[] args) {
/* 通过spring容器创建创建Hello对象,
* 并调用Hello中的sayHi方法 */
//1.加载spring的核心配置文件
ClassPathXmlApplicationContext ac =
new ClassPathXmlApplicationContext(
"applicationContext.xml"
);
//2.从spring容器中获取bean对象(而不是自己new)
Hello hello1 = (Hello) ac.getBean("hello");
Hello hello2 = (Hello) ac.getBean("hello");
//3.测试
if(hello1 == hello2){
System.out.println("当前实例为单实例...");
}else{
System.out.println("当前实例为多实例...");
}
}
}
将applicationContext.xml中,Hello类bean标签的scope值设置为singleton:
<bean id="hello" scope="singleton" class="com.tedu.spring.Hello"></bean>
运行TestIOC2,运行结果为:

将applicationContext.xml中,Hello类bean标签的scope值修改为prototype
<bean id="hello" scope="prototype" class="com.tedu.spring.Hello"></bean>
再次运行TestIOC2,运行结果为:

五、Spring DI依赖注入
DI(Dependency Injection)依赖注入 。
依赖注入,即组件之间的依赖关系由容器在应用系统运行期来决定,也就是由容器动态地将某种依赖关系的目标对象实例注入到应用系统中的各个关联的组件之中。
简单来说,所谓的依赖注入其实就是,在创建对象的同时或之后,如何给对象的属性赋值。
如果对象由我们自己创建,这一切都变得很简单,例如:
User user = new User();
user.setName("韩少云");
user.setAge(18);
或者:
User user = new User("韩少云", 18);
如果对象由spring创建,那么spring是怎么给属性赋值的?spring提供两种方式为属性赋值:
- set方式注入
- 构造方法注入
1、set方式注入
普通属性注入
需求:通过Spring创建User实例,并为User实例的name和age属性(普通属性)赋值
创建User类,声明name和age属性,并添加对应的setter和getter方法,以及toString方法
package com.tedu.spring;
public class User {
private String name;
private Integer age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "User [name=" + name + ", age=" + age + "]";
}
}
在applicationContext.xml中声明User类的bean实例
<!-- 声明User类的bean实例 -->
<bean id="user" class="com.tedu.spring.User"></bean>
创建测试类—TestDI
package com.tedu.spring;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TestDI {
public static void main(String[] args) {
//1.加载applicationContext.xml核心配置文件
ClassPathXmlApplicationContext ac =
new ClassPathXmlApplicationContext(
"applicationContext.xml"
);
//2.获取User类的实例
User user = (User) ac.getBean("user");
//3.输出User实例
System.out.println( user );
}
}
由于这里没有为User对象的属性赋值,所以此时运行测试,结果为:

修改applicationContext.xml中User实例的声明,为User实例注入属性
<!-- 声明User类的bean实例 -->
<bean id="user" class="com.tedu.spring.User">
<!-- 通过set方式为普通属性赋值 -->
<property name="name" value="韩少云"></property>
<property name="age" value="20"></property>
</bean>
其中name属性的值,必须要和User类中所注入属性对应的get方法的名字去掉get后首字母变为小写的名字相同。
例如:为 User类中的age属性赋值,由于name属性对应的get方法名字为 getAge,当去调用get和 首字母变为小写后的名称为age,因此为age属性注入的配置内容为:
<property name="age" value="20"></property>
普通属性直接通过value注入即可。
运行测试类TestDI,结果为:
上面通过spring提供的set方式对User对象的属性进行了赋值赋值,所以此时运行测试,结果为:

另外一种对象属性注入
需求:通过Spring创建User实例,并为User对象的userInfo属性(对象属性)赋值
创建UserInfo类
package com.tedu.spring;
public class UserInfo {
}
在applicationContext.xml中,声明UserInfo类的bean实例
<!-- 声明UserInfo类的bean实例 -->
<bean id="userInfo" class="com.tedu.spring.UserInfo"></bean>
修改User类,声明userInfo属性,添加对应的setter和getter方法,并重新生成toString方法
public class User {
...
private UserInfo userInfo;
public UserInfo getUserInfo() {
return userInfo;
}
public void setUserInfo(UserInfo userInfo) {
this.userInfo = userInfo;
}
...
public String toString() {
return "User [name=" + name + ", age=" + age + ", userInfo=" + userInfo + "]";
}
}
在applicationContext.xml中,将UserInfo对象作为值,赋值给User对象的userInfo属性
<!-- 声明User类的bean实例 -->
<bean id="user" class="com.tedu.spring.User">
<!-- 通过set方式为普通属性赋值 -->
<property name="name" value="韩少云"></property>
<property name="age" value="20"></property>
<!-- 通过set方式为对象属性赋值 -->
<property name="userInfo" ref="userInfo"></property>
</bean>
由于此处是将UserInfo对象作为值赋值给另一个对象的属性,因此ref属性的值,为UserInfo对象bean标签的id值。
对象属性通过ref属性注入。
运行测试类TestDI,结果为:

2、构造方法注入
需求:通过Spring创建User对象,并为User对象的属性(name、age、UserInfo属性)赋值
为User类声明构造函数
//声明无参构造函数
public User() {
}
//声明有参构造函数
public User(String name, Integer age, UserInfo userInfo) {
super();
this.name = name;
this.age = age;
this.userInfo = userInfo;
}
修改applicationContext.xml文件,将set方式修改为构造方法注入。
<bean id="user" class="com.tedu.spring.User">
<!-- 通过set方式为普通属性赋值
<property name="name" value="韩少云"></property>
<property name="age" value="20"></property>
<property name="userInfo" ref="userInfo"></property>
-->
<!-- 通过构造器中参数为属性赋值 -->
<constructor-arg name="name" value="马云"></constructor-arg>
<constructor-arg name="age" value="35"></constructor-arg>
<constructor-arg name="userInfo" ref="userInfo"></constructor-arg>
</bean>
<!-- 声明UserInfo类的bean实例 -->
<bean id="userInfo" class="com.tedu.spring.UserInfo"></bean>
其中,constructor-arg标签name属性的值必须和构造函数中参数的名字相同!
同样的,普通属性直接通过value注入即可;
对象属性通过ref属性注入。
运行测试类TestDI,结果为:

AOP(面向切面编程)
一、AOP是什么
AOP 是软件设计领域中的面向切面编程,它是面向对象编程(OOP)的一种补充和完善实际项目中我们通常将面向对象理解为一个静态过程(例如一个系统有多少模块,一个模块有哪些对象,对象有哪些属性),面向切面中包含一个一个动态过程(在对象运行时动态织入一些功能。)
二、AOP要解决什么问题?
实际项目中通常会将系统分为两大部分:核心关注点和非核心关注点
思考?
编程过程中首先要完成的是什么?核心关注点(核心业务)
非核心关注点如何切入到系统中?硬编码(违背OCP),AOP(推荐)
AOP就是要在基于OCP(开闭原则)在不改变原有系统核心业务代码的基础上动态添加一些扩展功能并可以控制对象的执行(例如权限控制)。
思考:现有一业务,在没有AOP编程时,如何基于OCP原则实现功能扩展?
解决方案:手动通过继承或组合方式实现业务扩展
三、AOP实际项目应用场景?
AOP 通常应用于日志的处理,事务处理,权限处理,缓存处理等等。
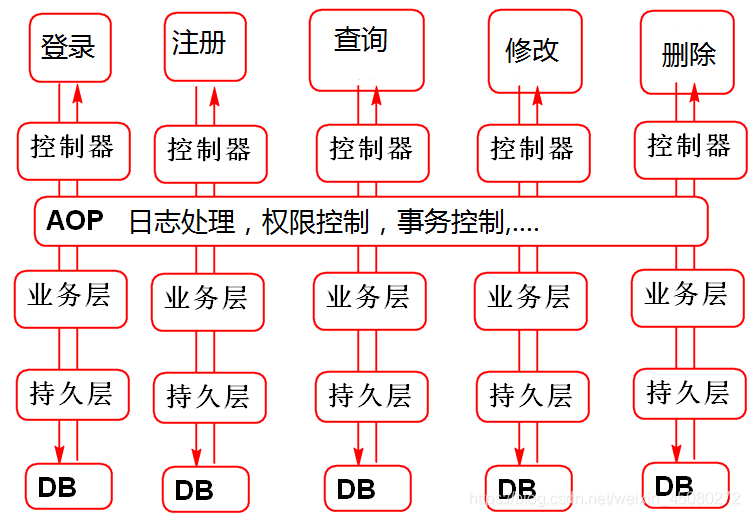
四、AOP底层原理实现分析?
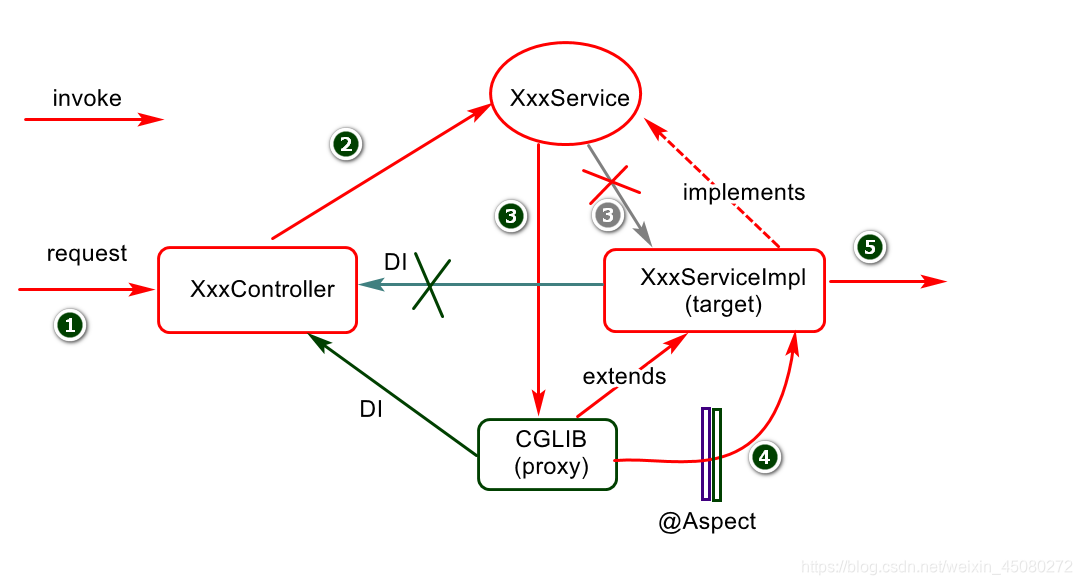
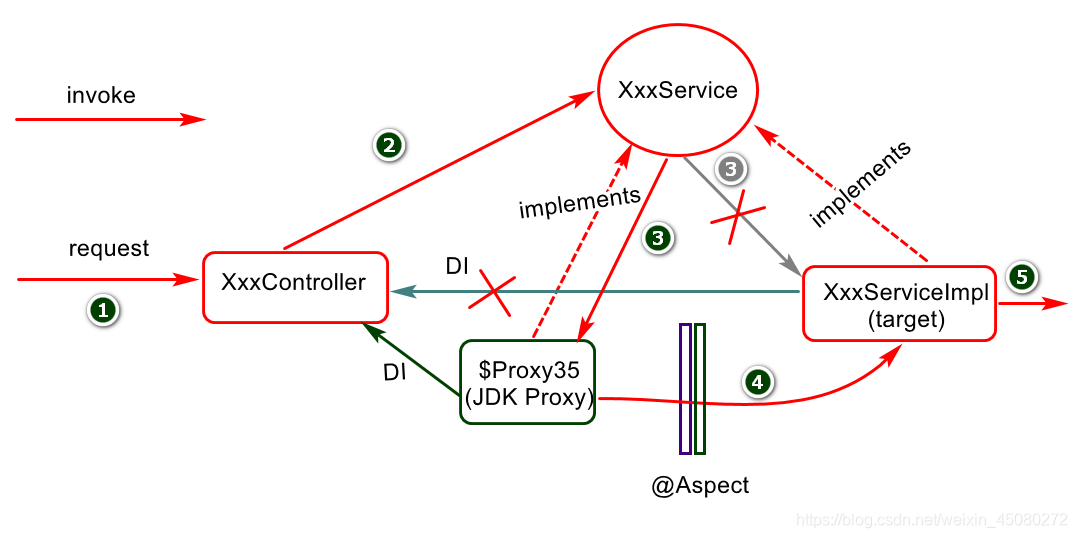
AOP底层基于代理机制实现功能扩展:(了解)
- 假如目标对象(被代理对象)实现接口,则底层默认采用JDK动态代理机制为目标对象创建代理对象(目标类和代理类会实现共同接口)
- 假如目标对象(被代理对象)没有实现接口,则底层默认采用CGLIB代理机制为目标对象创建代理对象(默认创建的代理类会继承目标对象类型)。
Spring boot2.x 中AOP现在默认使用的CGLIB代理,
CGLIB担心业务层类没有实现
假如需要使用JDK动态代理可以在配置文件(applicatiion.properties)中进行如下配置:
*JDK动态代理要求一定要实现接口 根据下面的配置,底层会创建一个代理对象
spring.aop.proxy-target-class=false
springboot中aop的配置
- pom.xml 依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
- application.yml 配置
spring:
# AOP 配置
aop:
auto: true #相当于标注了 @EnableAspectJAutoProxy
proxy-target-class: true #开启 cglib 代理
用注解的方式表示
/**
* Jdk代理:基于接口的代理,一定是基于接口,会生成目标对象的接口的子对象。
* Cglib代理:基于类的代理,不需要基于接口,会生成目标对象的子对象。
* 1. 注解@EnableAspectJAutoProxy开启代理;
* 2. 如果属性proxyTargetClass默认为false, 表示使用jdk动态代理织入增强;
* 3. 如果属性proxyTargetClass设置为true,表示使用Cglib动态代理技术织入增强;
* 4. 如果属性proxyTargetClass设置为false,但是目标类没有声明接口,
* Spring aop还是会使用Cglib动态代理,也就是说非接口的类要生成代理都用Cglib。
*/
@EnableAspectJAutoProxy(proxyTargetClass=true)
public class SpringbootAsyncApplicationTests {
......
}
五、AOP 相关术语
切面(aspect): 横切面对象,一般为一个具体类对象(可以借助@Aspect声明)
连接点(joinpoint):程序执行过程中某个特定的点,一般指被拦截到的的方法
切入点(pointcut):对连接点拦截内容的一种定义,一般可以理解为多个连接点的结合.
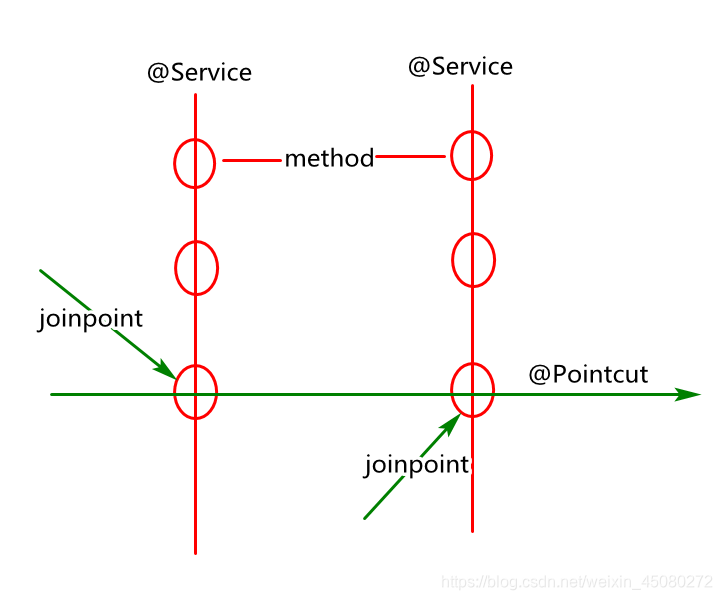
通知(Advice):在切面的某个特定连接点上执行的动作(扩展功能),例如around,before,after等
六、AOP 编程实现
将此日志处理类作为核心业务增强(一个横切面对象)类,用于输出业务开始执行时间,以及业务结束执行时间。
横切面对象主要由两部分构成:
- 切入点(用于@Pointcut标识)
- 功能增强(用通知@Before,@After等进行标识)
/**/
@Aspect//切面类对象(封装扩展功能)
@Service
@Slf4j
public class SysLogAspect {
/**
* @Pointcut注解用于定义切入点
* bean表达式为切入点表达式,
* bean名字为spring容器中某个bean或多个bean的名字
* bean表达式内部指定的bean对象中
* 所有方法为切入点(进行功能扩展的点)
*/
//如果下面的方法格式错误,
@Pointcut("bean(sysUserServiceImpl)")
public void logPointCut() {}
/**
* @Around 描述的方法为环绕通知,用于功能增强
* 环绕通知(目标方法执行之前和之后添加扩展功能,甚至控制目标方法都可以执行)
* @param jp 连接点 (封装了要执行的目标方法信息)
* @return 目标方法的执行结果
*
* @throws Throwable
*/
@Around("logPointCut()")
public Object around(ProceedingJoinPoint jp) throws Throwable{
try {
log.info("start:"+System.currentTimeMillis());
Object result=jp.proceed();//调用下一个切面方法或目标方法
log.info("after:"+System.currentTimeMillis());
return result;
}catch(Throwable e) {
log.error(e.getMessage());
throw e;
}
}
}
其中:
@Aspect 注解用于标识此类为一个AOP横切面对象
@Pointcut 注解用于定义本类中的切入点,本案例中切入点表达式用的是bean表达式,这个表达式以bean开头,bean括号中的内容为一个spring管理的某个bean对象的id。
@Around用于定义一个环绕通知(满足切入点表达式的核心业务方法执行之前和之后执行的一个操作)
术语增强:
切面:用于封装扩展业务的一个类的对象。
通知:切面扩展业务中的一个操作(方法)。
编写测试类:
基于xml方式注解配置的测试实现
@RunWith(SpringRunner.class)
@SpringBootTest
public class AopTests {
@Autowired
private ApplicationContext ctx;
@Test
public void testSysUserService() {
SysUserService userService=
ctx.getBean("sysUserServiceImpl",SysUserService.class);
System.out.println(userService.getClass());
PageObject<SysUserDeptVo> po=
userService.findPageObjects("admin",1);
System.out.println("rowCount:"+po.getRowCount());
}
}
七、AOP 编程增强
1、切面表达式增强
Spring中通过切入点表达式定义具体切入点,其常用AOP切入点表达式定义及说明:
| 指示符 | 作用 |
|---|---|
| bean | 用于匹配指定bean id的的方法执行 |
| within | 用于匹配指定包名下类型内的方法执行 |
| execution | 用于进行细粒度方法匹配执行具体业务 |
| @annotation | 用于匹配指定注解修饰的方法执行 |
2、Bean表达式应用增强
bean表达式应用于类级别,实现粗粒度的控制:
| bean(“userServiceImpl”)) | 指定一个类中所有方法 |
|---|---|
| bean("*ServiceImpl") | 指定所有的后缀为serviceImpl的类 |
说明:bean表达式内部的对象是由spring容器管理的一个bean对象,表达式内部的内部的名字应该时spring容器中某个bean的key.
3、Within表达式应用增强
within表达式应用于类级别,实现粗粒度的切面表达式定义:
| within(“aop.service.UserServiceImpl”) | 指定类,只能指定一个类 |
|---|---|
| within(“aop.service.*”) | 只包括当前目录下的类 |
| within(“aop.service…*”) | 指定当前目录包含所有子目录中的类 |
4、Execution表达式应用增强
execution表达式应用于方法级别,细粒度的控制:
语法:execution(返回值类型 包名.类名.方法名(参数列表))
| execution(void aop.service.UserServiceImpl.addUser()) | 匹配方法 |
|---|---|
| execution(void aop.service.PersonServiceImpl.addUser(String)) | 方法参数必须为字符串 |
| execution(* aop.service….(…)) | 万能配置 |
5、@annotation表达式应用增强
@annotaion表达式应用于方法级别,实现细粒度的切入点表达式定义:
| @annotation(com.jt.common.anno.RequestLog)) | 指定一个需要实现增强功能的方法 |
|---|
其中:RequestLog为我们自己定义的注解,当我们使用@RequestLog注解修饰业务层方法时,系统底层会在执行此方法时进行扩展操作.
八、切面通知应用增强分析
在AOP编程中有五种类型的通知:
1) 前置通知 (@Before)—— 前置通知,在目标方法被调用之前调用通知功能
2) 后置通知 (@After) : 又称之为最终通知(finally),后置通知,在目标方法执行结束后,无论执行结果如何都执行通知定义的任务
3) 返回通知 (@AfterReturning) 方法return之后执行
4) 异常通知 (@AfterThrowing) 方法出现异常之后执行
5) 环绕通知 (@Around) :环绕通知,在目标方法执行前和执行后,都需要执行通知定义的任务。
这五种通知类型注解都有value属性,该属性就是我们的切点表达式,其格式:
@Before(value = "切点表达式")
@Before(value = "execution(public int com.nasus.spring.aop.impl.*.*(int, int))")
其结构如下:
Try{
@Before
核心业务
@AfterReturning
}catch(Exception e){
….
@AfterThrowing
}finally{
….
@After
}
如上四个一起使用时可以直接使用@Around通知替换
案例实现分析:
切入点及前置通知,后置通知,返回通知,异常通知,环绕通知的配置
@Service
@Aspect
public class SysTimeAspect {
@Pointcut("bean(sysUserServiceImpl)")
public void doTime(){}
@Before("doTime()")
public void doBefore(JoinPoint jp){
System.out.println("time doBefore()");
}
@After("doTime()")
public void doAfter(){
System.out.println("time doAfter()");
}
/**核心业务正常结束时执行
* 说明:假如有after,先执行after,再执行returning*/
@AfterReturning("doTime()")
public void doAfterReturning(){
System.out.println("time doAfterReturning");
}
/**核心业务出现异常时执行
说明:假如有after,先执行after,再执行Throwing*/
@AfterThrowing("doTime()")
public void doAfterThrowing(){
System.out.println("time doAfterThrowing");
}
@Around("doTime()")
public Object doAround(ProceedingJoinPoint jp)
throws Throwable{
System.out.println("doAround.before");
Object obj=jp.proceed();
System.out.println("doAround.after");
return obj;
}
}
其中:环绕通知的优先级最高.
切面执行顺序配置增强
注解方式顺序配置需要借助@Order注解
@Order(1)
@Aspect
@Component
public class TxManager {
…
}
注解方式顺序配置
@Order(2)
@Aspect
@Component
public class SysLogAspect {
…
}
说明:数字越小,优先级越高.
实际操作参考:https://blog.csdn.net/a303549861/article/details/103990030
这个思路不错
Spring中的事务
1、事务的简介
事务(Transaction)是一个业务,是一个不可分割的逻辑工作单元,具备ACID特性,实际工作中可借助Spring进行事务管理。
2、事务四大特性:ACID:
- 原子性(Atomicity)——(一个事务中的多个操作要么都成功要么都失败)
- 一致性(Consistency)——(例如存钱操作,存之前和存之后的总钱数应该是一致的)
- 隔离性(Isolation)——(事务与事务应该是相互隔离的)
- 持久性(Durability)——(事务一旦提交,数据要持久保存)
3、并发事务处理带来的问题
相对于串行处理来说,并发事务处理能大大增加数据库资源的利用率,提高数据库系统的事务吞吐量,从而可以支持更多的用户。但并发事务处理也会带来一些问题,主要包括以下几种情况:
- 脏读(Dirty Reads):一个事务读取到另一个事务尚未提交的数据
- 不可重复读(Non-Repeatable Reads):事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
- 幻读 (Phantom Reads):系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
4、Spring中提供了两种事务管理方式:
- 编程式事务
- 声明式事务
编程式事务指的是通过编码方式实现事务;一般依赖于TransactionTemplate
声明式事务基于 AOP,依赖于注解@Transactional。将具体业务逻辑与事务处理解耦。声明式事务管理使业务代码逻辑不受污染, 因此在实际使用中声明式事务用的比较多。
在这里主要说说声明式事务
4.1、声明式事务
Spring中声明式事务处理有两种方式,一种是在配置文件(xml)中做相关的事务规则声明,另一种是基于@Transactional 注解的方式。
注解底层会调用dataSourceTransactionManager的方法 使用的是一个连接 connection
重点讲解实际项目中最常用的声明式事务管理,以简化事务的编码操作。
4.2 、@Transactional添加的方式
- @Transactional加在类上:说明该事务作用于类中的所有方法
- @Transactional加载方法上:说明该事务只作用域该方法,只能加在public方法上
说明:@Transactional 注解可以用在方法上也可以添加到类级别上。当把@Transactional 注解放在类级别时,表示所有该类的公共方法都配置相同的事务属性信息。当类级别配置了@Transactional,方法级别也配置了@Transactional,应用程序会以方法级别的事务属性信息来管理事务,换言之,方法级别的事务属性信息会覆盖类级别的相关配置信息。
避坑注意事项:
1、@Transactional 注解只能加在 public 方法上,这是由 Spring AOP 的本质动态代理决定的。如果你在 protected、private 或者默认可见性的方法上使用 @Transactional 注解,这将被忽略,也不会抛出任何异常。 Spring默认使用的是jdk自带的基于接口的代理,而没有使用基于类的代理CGLIB。
2、@Transactional注解底层使用的是动态代理来进行实现的,如果在调用本类中的方法,此时不添加@Transactional注解,而是在调用类中使用this调用本类中的另外一个添加了@Transactional注解,此时this调用的方法上的@Transactional注解是不起作用的,因为 @Transactional其实是为你的类做了一个代理,既然是代理类那么只有调用代理类才能真正的执行到增强的方法,如果是在类的内部调用的化意味着没有调用增强的方法,所以声明式事务是不生效的。
3、【重点中的重点】 spring 在扫描 bean 的时候会扫描方法上是否包含 @Transactional 注解,如果包含,spring 会为这个bean动态地生成一个子类(即代理类,proxy),代理类是继承原来那个bean的。此时,当这个有注解的方法被调用的时候,实际上是由代理类来调用的,代理类在调用之前就会启动transaction。然而,如果这个有注解的方法是被同一个类中的其他方法调用的,那么该方法的调用并没有通过代理类,而是直接通过原来的那个bean,所以就不会启动transaction,我们看到的现象就是@Transactional注解无效。(总结来说就是:同类中,无事务的方法,调用添加事务的方法,这个方法的事务并不生效)
4、如果异常被try{}catch{}了,事务就不回滚了,如果想让事务回滚必须再往外抛try{}catch{throw Exception}。
5、@Transactional 注解标识的方法,处理过程尽量的简单。尤其是带锁的事务方法,能不放在事务里面的最好不要放在事务里面。可以将常规的数据库查询操作放在事务前面进行,而事务内进行增、删、改、加锁查询等操作。
6、@Transactional既可以作用于接口,接口方法上以及类及类的方法上。但是Spring官方不建议接口或者接口方法上使用该注解,因为这只有在使用基于接口的代理时它才会生效。
7、你当然可以在接口上使用 @Transactional 注解,但是这将只能当你设置了基于接口的代理时它才生效。因为注解是不能继承的,这就意味着如果你正在使用基于类的代理时,那么事务的设置将不能被基于类的代理所识别,而且对象也将不会被事务代理所包装(将被确认为严重的)。因此,请接受Spring团队的建议并且在具体的类上使用 @Transactional 注解。
4.3、Spring中 @Transactional的配置
步骤一、在Spring配置文件中引入命名空间
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-2.0.xsd">
步骤二、xml配置文件中,添加事务管理器bean配置
<!-- 事务管理器配置,单数据源事务 -->
<bean id="pkgouTransactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="pkGouDataSource" />
</bean>
<!-- 使用annotation定义事务 -->
<tx:annotation-driven transaction-manager="pkgouTransactionManager" />
或者
<tx:annotation-driven />
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
步骤三、在使用事务的方法或者类上添加 @Transactional(“pkgouTransactionManager”)注解
4.4、@Transactional属性介绍
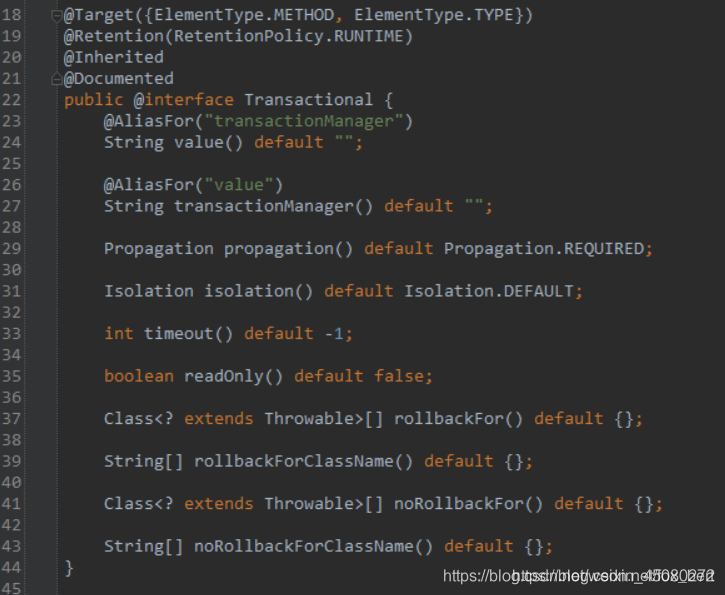
属性说明如下表:
| 属性 | 类型 | 描述 |
|---|---|---|
| value | String | 可选的限定描述符,指定使用的事务管理器 |
| propagation | enum: Propagation | 定义事务的生命周期,有REQUIRED、SUPPORTS、MANDATORY、REQUIRES_NEW、NOT_SUPPORTED、NEVER、NESTED,详细含义可查阅枚举类org.springframework.transaction.annotation.Propagation源码。 |
| isolation | enum: Isolation | 可选的事务隔离级别设置,决定了事务的完整性 |
| readOnly | boolean | 读写或只读事务,默认读写 |
| timeout | int (in seconds granularity) | 事务超时时间设置 |
| rollbackFor | Class对象数组,必须继承自Throwable | 导致事务回滚的异常类数组 |
| rollbackForClassName | 类名数组,必须继承自Throwable | 导致事务回滚的异常类名字数组 |
| noRollbackFor | Class对象数组,必须继承自Throwable | 不会导致事务回滚的异常类数组 |
| noRollbackForClassName | 类名数组,必须继承自Throwable | 不会导致事务回滚的异常类名字数组 |
下来分别看一下这些属性的具体情况
4.1、propagation属性(事务传播行为)——7种事务传播行为
事务传播(Propagation)特性指不同业务(service)对象中的事务方法之间相互调用时,事务的传播方式.
重点掌握 Propagation.REQUIRED (最常用)
spring事务有7种传播行为
使用 propagation 指定事务的传播行为, 即当前的事务方法被另外一个事务方法调用时如何使用事务, 常用属性值有:
-SUPPORTS :对于只包含查询的方法一般使用这个。
@Transactional(propagation = Propagation.REQUIRED)
| Propagation.REQUIRED | (默认值)如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置 |
|---|---|
| Propagation.SUPPORTS | 支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行 |
| Propagation.MANDATORY | 支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常 |
| Propagation.REQUIRES_NEW | 创建新事务,无论当前存不存在事务,都创建新事务 |
| Propagation.NOT_SUPPORTED | 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起(不需要事务管理的(只查询的)) |
| Propagation.NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常 |
| Propagation.NESTED | 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作 |
4.2、isolation属性(事务隔离级别)——5种事务隔离级别
事务的隔离级别主要是解决上面的三种并发读问题(脏读、不可重复度、幻读),使用 isolation 指定事务的隔离级别, 属性值为:
@Transactional(isolation = Isolation.READ_COMMITTED)
| default | (默认值)使用底层数据库的默认隔离级别,对大多数据库来说默认隔离级别都是READ_COMMITTED |
|---|---|
| repeatable_read(可重复读)(MySql默认) | 防止脏读和不可重复读,不能处理幻读问题。 性能比serialiable好 |
| read_committed(读已提交数据)(Oracle默认) | 防止脏读,但可能出现不可重复读和幻读。性能比repeatable read好 |
| read_uncommited (读未提交数据) | 允许事务读取其它事务未提交的数据变更 (会出现脏读, 不可重复读) 基本不使用。性能最好 |
| serializable(串行化) | 不会出现任何并发问题,因为对同一数据的访问是串行的,非并发访问的。 性能最差。 |
最常用的取值为 READ_COMMITTED
事务的隔离级别要得到底层数据库引擎的支持, 而不是应用程序或者框架的支持.
Oracle 支持的 2 种事务隔离级别:READ_COMMITED , SERIALIZABLE
Mysql 支持 4 中事务隔离级别。
具体看看这几种隔离级别的情况:
第1级别:Repeatable Read(可重读)
(1)这是MySQL的默认事务隔离级别
(2)它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行
(3)此级别可能出现的问题——幻读(Phantom Read):当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行
(4)InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题
#首先,更改隔离级别
set tx_isolation=‘repeatable-read’;
select @@tx_isolation;
@@tx_isolation |
+-----------------+
| REPEATABLE-READ
#事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务B:开启一个新事务(那么这两个事务交叉了)
在事务B中更新数据,并提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
commit;
#事务A:这时候即使事务B已经提交了,但A能不能看到数据变化?
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 | --->还是看不到的!(这个级别2不一样,也说明级别3解决了不可重复读问题)
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务A:只有当事务A也提交了,它才能够看到数据变化
commit;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
第2级别:Read Committed(读取提交内容)
(1)这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)
(2)它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变
(3)这种隔离级别出现的问题是——不可重复读(Nonrepeatable Read):不可重复读意味着我们在同一个事务中执行完全相同的select语句时可能看到不一样的结果。
|——>导致这种情况的原因可能有:(1)有一个交叉的事务有新的commit,导致了数据的改变;(2)一个数据库被多个实例操作时,同一事务的其他实例在该实例处理其间可能会有新的commit
#首先修改隔离级别
set tx_isolation=‘read-committed’;
select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+
#事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务B:也启动一个事务(那么两个事务交叉了)
在这事务中更新数据,且未提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务A:这个时候我们在事务A中能看到数据的变化吗?
select * from tx; --------------->
+------+------+ |
| id | num | |
+------+------+ |
| 1 | 1 |--->并不能看到! |
| 2 | 2 | |
| 3 | 3 | |
+------+------+ |——>相同的select语句,结果却不一样
|
#事务B:如果提交了事务B呢? |
commit; |
|
#事务A: |
select * from tx; --------------->
+------+------+
| id | num |
+------+------+
| 1 | 10 |--->因为事务B已经提交了,所以在A中我们看到了数据变化
| 2 | 2 |
| 3 | 3 |
+------+------+
第3级别:Read Uncommitted(读取未提交内容)
(1)所有事务都可以看到其他未提交事务的执行结果
(2)本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少
(3)该级别引发的问题是——脏读(Dirty Read):读取到了未提交的数据
#首先,修改隔离级别
set tx_isolation='READ-UNCOMMITTED';
select @@tx_isolation;
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+
#事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务B:也启动一个事务(那么两个事务交叉了)
在事务B中执行更新语句,且不提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务A:那么这时候事务A能看到这个更新了的数据吗?
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 | --->可以看到!说明我们读到了事务B还没有提交的数据
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务B:事务B回滚,仍然未提交
rollback;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务A:在事务A里面看到的也是B没有提交的数据
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 | --->脏读意味着我在这个事务中(A中),事务B虽然没有提交,但它任何一条数据变化,我都可以看到!
| 2 | 2 |
| 3 | 3 |
+------+------+
第4级别:Serializable(可串行化)
(1)这是最高的隔离级别
(2)它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。
(3)在这个级别,可能导致大量的超时现象和锁竞争
#首先修改隔离界别
set tx_isolation='serializable';
select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| SERIALIZABLE |
+----------------+
#事务A:开启一个新事务
start transaction;
#事务B:在A没有commit之前,这个交叉事务是不能更改数据的
start transaction;
insert tx values('4','4');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
update tx set num=10 where id=1;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
4.3、rollbackFor属性(事务回滚设置)
Spring框架的事务管理默认地只在发生不受控异常(RuntimeException 和 Error)时才进行事务回滚。
也就是说,当事务方法抛出受控异常( Exception 中除了 RuntimeException 及其子类以外的)时不会进行事务回滚。
- 受控异常(checked exceptions):就是非运行时异常,即Exception中除了RuntimeException及其子类以外的。
- 不受控异常(unchecked exceptions):RuntimeException和Error。
rollbackFor 属性在这里就可以发挥它的作用了
@Transactional(rollbackFor = Exception.class)
这里你可以使用 java 已声明的异常;也可以使用自定义异常;也可同时设置多个异常类,中间用逗号间隔
@Transactional(rollbackFor = {SQLException.class,UserAccountException.class})
只要出现异常就回滚 rollbackFor = Throwable.class,
读到一个数据库里面未提交的数据 就是脏读 防止脏读 设置隔离级别 你读到的数据只能是别人已经提交的事务
4.4、noRollbackFor属性(事务不回滚设置)
默认情况下 Spring 的声明式事务对所有的运行时异常进行回滚. 可以通过noRollbackFor属性进行设置例外异常.
如:
@Transactional(noRollbackFor = {UserAccountException.class})
上面设置了遇到UserAccountException异常不回滚。
一般不建议设置这个属性,通常情况下默认即可.
4.5、readOnly 属性
@Transactional(readOnly = false)
默认为 :false
指定事务是否为只读. 表示这个事务只读取数据但不更新数据,
这样可以帮助数据库引擎优化事务.
如果只有查询数据操作, 应设置 readOnly=true
4.6、timeout 属性
@Transactional(timeout = 5)
指定强制回滚之前事务可以占用的时间. 单位:秒
timeout 事务的超时时间,默认值为-1,表示没有超时显示。如果配置了具体时间,则超过该时间限制但事务还没有完成,则自动回滚事务。
如果执行时间超过这个时间就强制回滚。
案例一:
@Transactional(timeout = 30,
readOnly = false,
isolation = Isolation.READ_COMMITTED,
rollbackFor = Throwable.class,
propagation = Propagation.REQUIRED)
@Service
public class SysUserServiceImpl implements SysUserService {
@Transactional(readOnly = false)
@Override
public PageObject<SysUserDeptVo> findPageObjects(String username, Integer pageCurrent) {
…
}
}
案例二
/**
* @Transactional默认只有遇到 RuntimeException 和 error 的时候才回滚
* 可以通过 rollbackFor 的设置来增加回滚的条件
*/
@Transactional(propagation = Propagation.REQUIRED,
isolation = Isolation.DEFAULT,
rollbackFor = {Exception.class},
timeout = 5)
@Service
public class UsersServiceImpl implements UsersService{
@Resource
UsersBeanMapper usersBeanMapper;
@Transactional(readOnly = true)
@Override
public UsersBean getUserByLogin(String username, String pwd) throws Exception{
UsersBean UsersBean=usersBeanMapper.selectByUsersBean(new UsersBean(username, pwd));
return UsersBean;
}
@Override
public int deleteById(Integer id) throws Exception{
try{
int row=usersBeanMapper.deleteByPrimaryKey(id);
if(row<1){
throw new MyException("我没有找到对应的ID,无法进行删除");
}
return row;
}catch(Exception e){
throw new RuntimeException("我执行的时候出错了");
//throw new SQLException("我执行sql的时候出错了");
}
}
......
}
5、在使用@Transactional时踩过的坑
1、 在业务层捕捉异常后,发现事务不生效。
这是许多新手都会犯的一个错误,在业务层手工捕捉并处理了异常,你都把异常“吃”掉了,Spring自然不知道这里有错,更不会主动去回滚数据。例如:下面这段代码直接导致增加余额的事务回滚没有生效。
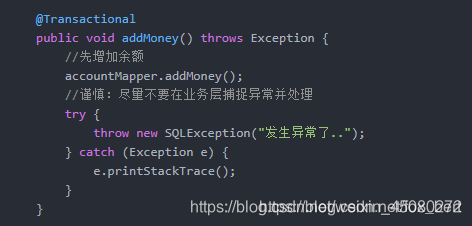
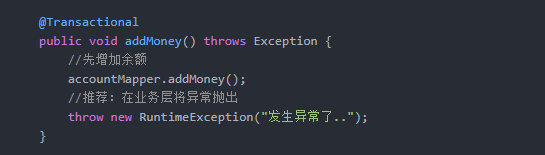
推荐做法:若非实际业务要求,则在业务层统一抛出异常,然后在控制层统一处理。
2、同一个类中的某个方法调用另一个有注解(@Transactional)的方法时,失效
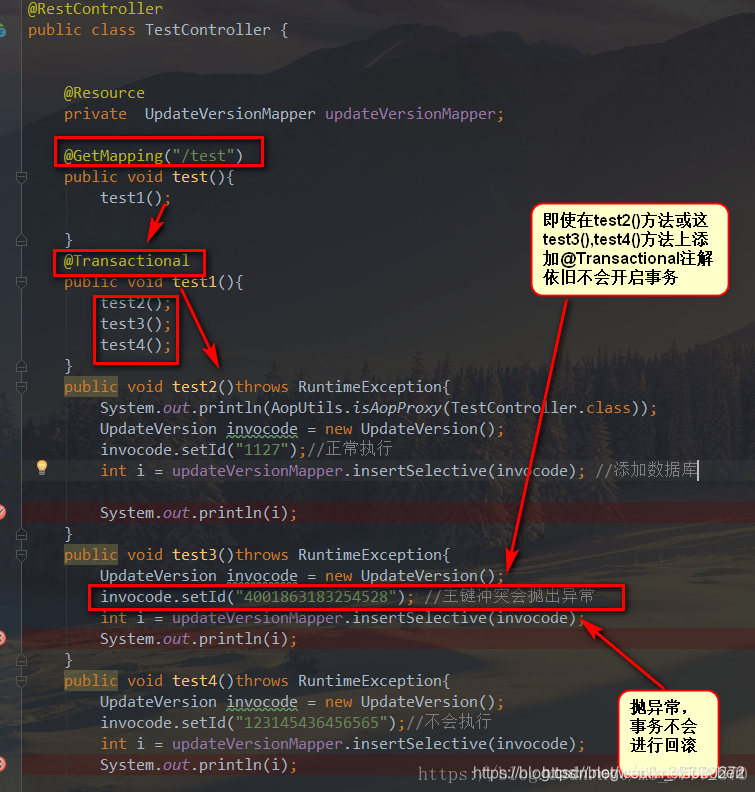
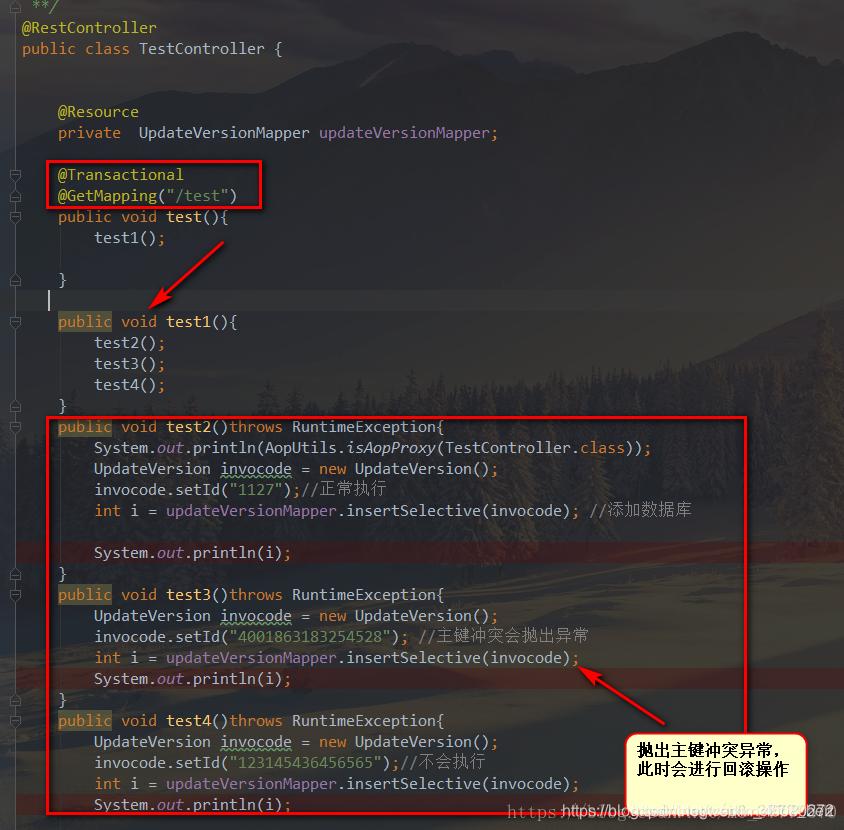
@Transactional注解底层使用的是动态代理来进行实现的,如果在调用本类中的方法,此时不添加@Transactional注解,而是在调用类中使用thisi调用本类中的另外一个添加了@Transactional注解,此时this调用的方法上的@Transactional注解是不起作用的。
Transactional是Spring提供的事务管理注解。
重点在于,Spring采用动态代理(AOP)实现对bean的管理和切片,它为我们的每个class生成一个代理对象。只有在代理对象之间进行调用时,可以触发切面逻辑。
而在同一个class中,方法B调用方法A,调用的是原对象的方法,而不通过代理对象。所以Spring无法切到这次调用,也就无法通过注解保证事务性了。
也就是说,在同一个类中的方法调用,则不会被方法拦截器拦截到,因此事务不会起作用。
SpringBoot声明式事务@Transactional配置及使用
SpringBoot声明式事务@Transactional配置及使用
Spring中的bean
Spring中的设计模式(9种)
一、简单工厂模式
参考:https://www.zhihu.com/collection/242000960
又叫做静态工厂方法(StaticFactory Method)模式,但不属于23种GOF设计模式之一。
- 实现方式:BeanFactory。 Spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得Bean对象,但是否是在传入参数后创建还是传入参数前创建这个要根据具体情况来定。
- 实质:由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类。
如下配置,就是在 HelloItxxz 类中创建一个 itxxzBean。
<beans>
<bean id="singletonBean" class="com.itxxz.HelloItxxz">
<constructor-arg>
<value>Hello! 这是singletonBean!value>
</constructor-arg>
</ bean>
<bean id="itxxzBean" class="com.itxxz.HelloItxxz"
singleton="false">
<constructor-arg>
<value>Hello! 这是itxxzBean! value>
</constructor-arg>
</bean>
</beans>
二、工厂设计模式
Spring使用工厂模式可以通过 BeanFactory 或 ApplicationContext 创建 bean 对象。
两者对比:
- BeanFactory :延迟注入(使用到某个 bean 的时候才会注入),相比于BeanFactory 来说会占用更少的内存,程序启动速度更快。
- ApplicationContext :容器启动的时候,不管你用没用到,一次性创建所有 bean 。BeanFactory 仅提供了最基本的依赖注入支持,ApplicationContext 扩展了 BeanFactory ,除了有BeanFactory的功能还有额外更多功能,所以一般开发人员使用ApplicationContext会更多。
ApplicationContext的三个实现类:
- ClassPathXmlApplication:把上下文文件当成类路径资源。
- FileSystemXmlApplication:从文件系统中的 XML 文件载入上下文定义信息。
- XmlWebApplicationContext:从Web系统中的XML文件载入上下文定义信息。
例如:
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.FileSystemXmlApplicationContext;
public class App {
public static void main(String[] args) {
ApplicationContext context = new FileSystemXmlApplicationContext(
"C:/work/IOC Containers/springframework.applicationcontext/src/main/resources/bean-factory-config.xml");
HelloApplicationContext obj = (HelloApplicationContext) context.getBean("helloApplicationContext");
obj.getMsg();
}
}
三、单例模式
单例模式有8种:https://blog.csdn.net/SmallCatBaby/article/details/83929478
在我们的系统中,有一些对象其实我们只需要一个,比如说:线程池、缓存、对话框、注册表、日志对象、充当打印机、显卡等设备驱动程序的对象。事实上,这一类对象只能有一个实例,如果制造出多个实例就可能会导致一些问题的产生,比如:程序的行为异常、资源使用过量、或者不一致性的结果。
1、使用单例模式的好处:
- 对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
- 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻 GC 压力,缩短 GC 停顿时间。
2、Spring 中 bean 的默认作用域就是 singleton(单例)的。除了 singleton 作用域,Spring 中 bean 还有下面几种作用域:
- prototype : 每次请求都会创建一个新的 bean 实例。
- request : 每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
- session : 每一次HTTP请求都会产生一个新的 bean,该bean仅在当前 HTTP session 内有效。
- global-session: 全局session作用域,仅仅在基于portlet的web应用中才有意义,Spring5已经没有了。Portlet是能够生成语义代码(例如:HTML)片段的小型Java Web插件。它们基于portlet容器,可以像servlet一样处理HTTP请求。但是,与 servlet 不同,每个 portlet 都有不同的会话
3、Spring 实现单例的方式:
- xml 的方式
<bean id="userService" class="top.snailclimb.UserService" scope="singleton"/>
- 注解的方式
@Scope(value = "singleton")
Spring 通过 ConcurrentHashMap 实现单例注册表的特殊方式实现单例模式。Spring 实现单例的核心代码如下
// 通过 ConcurrentHashMap(线程安全) 实现单例注册表
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(64);
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "'beanName' must not be null");
synchronized (this.singletonObjects) {
// 检查缓存中是否存在实例
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
//...省略了很多代码
try {
singletonObject = singletonFactory.getObject();
}
//...省略了很多代码
// 如果实例对象在不存在,我们注册到单例注册表中。
addSingleton(beanName, singletonObject);
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
}
//将对象添加到单例注册表
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, (singletonObject != null ? singletonObject : NULL_OBJECT));
}
}
}
四、代理设计模式
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么Spring AOP会使用JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候Spring AOP会使用Cglib ,这时候Spring AOP会使用 Cglib 生成一个被代理对象的子类来作为代理,如下图所示:
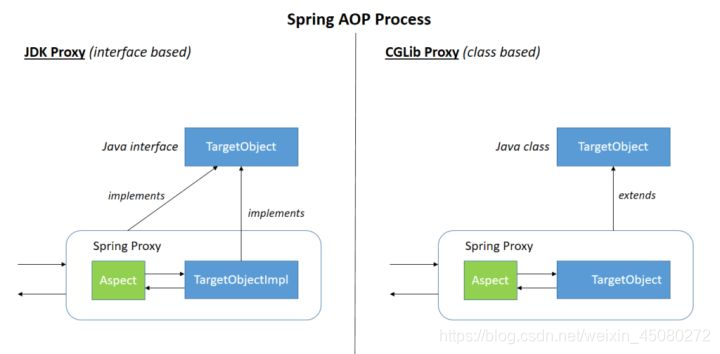
五、适配器模式
Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配Controller。
六、装饰者模式
七、观察者模式
八、模板方法
什么是模板方法(Template method):父类定义了骨架(调用哪些方法及顺序),某些特定方法由子类实现。
最大的好处:代码复用,减少重复代码。除了子类要实现的特定方法,其他方法及方法调用顺序都在父类中预先写好了。
所以父类模板方法中有两类方法:
- 共同的方法:所有子类都会用到的代码
- 不同的方法:子类要覆盖的方法,分为两种:
1)抽象方法:父类中的是抽象方法,子类必须覆盖
2)钩子方法:父类中是一个空方法,子类继承了默认也是空的
注:为什么叫钩子,子类可以通过这个钩子(方法),控制父类,因为这个钩子实际是父类的方法(空方法)!
模板方法看这个就懂了:https://www.cnblogs.com/postnull/p/4981447.html
参考:https://blog.csdn.net/qq_34337272/article/details/90487768
SpringMvc
SpringMvc的工作流程图:
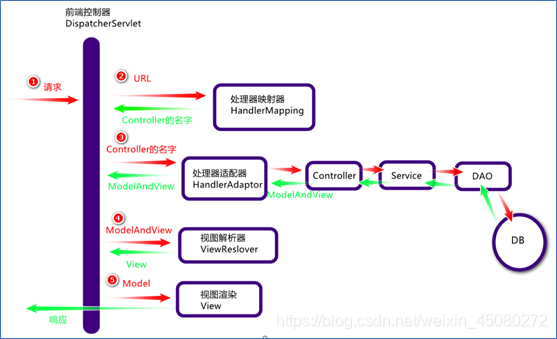
流程说明:
用户发送请求 至 前端控制器(DispatcherServlet);
提示:DispatcherServlet的作用:接收请求,调用其它组件处理请求,响应结果,相当于转发器、中央处理器,是整个流程控制的中心
拦截所有请求前端控制器(DispatcherServlet)收到请求后调用处理器映射器(HandlerMapping)
处理器映射器(HandlerMapping)找到具体的Controller(可以根据xml配置、注解进行查找),并将Controller返回给DispatcherServlet;前端控制器(DispatcherServlet)调用处理器适配器(HandlerAdapter)。
处理器适配器经过适配调用具体的Controller;(Controller–> service --> Dao --> 数据库)
Controller执行完成后返回ModelAndView,
提示:Model(模型数据,即Controller处理的结果,Map) View(逻辑视图名,即负责展示结果的JSP页面的名字)
处理器适配器(HandlerAdapter)将controller执行的结果(ModelAndView)返回给前端控制器(DispatcherServlet);前端控制器(DispatcherServlet)将执行的结果(ModelAndView)传给视图解析器(ViewReslover)
视图解析器(ViewReslover)根据View(逻辑视图名)解析后返回具体JSP页面前端控制器(DispatcherServlet)根据Model对View进行渲染(即将模型数据填充至视图中);
前端控制器(DispatcherServlet)将填充了数据的网页响应给用户。

流程说明(重要):
- 客户端(浏览器)发送请求,直接请求到 DispatcherServlet。
- DispatcherServlet 根据请求信息调用 HandlerMapping,解析请求对应的 Handler。
- 解析到对应的 Handler(也就是我们平常说的 Controller 控制器)后,开始由 HandlerAdapter 适配器处理。
- HandlerAdapter 会根据 Handler 来调用真正的处理器开处理请求,并处理相应的业务逻辑。
- 处理器处理完业务后,会返回一个 ModelAndView 对象,Model 是返回的数据对象,View 是个逻辑上的 View。
- ViewResolver 会根据逻辑 View 查找实际的 View。
- DispaterServlet 把返回的 Model 传给 View(视图渲染)。
- 把 View 返回给请求者(浏览器)














 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









