







Pandas教程
选择要处理的 pandas DataFrame 或 Series 的特定值是您将要运行的几乎所有数据操作中的一个隐含步骤,因此在 Python 中处理数据时您需要学习的第一件事就是如何快速有效地与选择与你研究的数据相关的要点。
数据介绍:
主要是通过wine-reviews数据集进行分析:129971*13

1.从reviews中筛选出列:description,同时把它assign到变量desc中
一般来说,当我们从 DataFrame 中选择一列时,我们会得到一个 Series。
查看类型:type(desc)
2.从description中选择出第一个值,命名为first_description

3.从reviews表中筛选出第一行,命名为first_row
first_row = reviews.iloc[0]
4.从reviews中的description列中筛选出前十行,命名为first_descriptions
first_descriptions = reviews.description[:10]
5.选择索引标签为 1、2、3、5 和 8 的记录,将结果分配给变量 sample_reviews。
tips:使用loc和iloc来选择DataFrame的行
sample_reviews = reviews.loc[[1,2,3,5,8]]
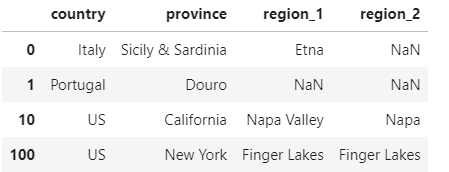
6.创建一个包含索引标签0,1,10和100的country,province,region_1和regionS_2列的变量DF。
tips:提示:使用 loc 运算符。(请注意,也可以使用 iloc 运算符解决此问题,但这需要额外的努力将每个列名转换为相应的整数值索引。)

#注意不可以使用:reviews.iloc(),ilco需要使用数字索取器numeric indexers
7.创建一个包含前 100 条记录的国家和品种列的变量 df。
iloc:使用 Python stdlib 索引方案,其中包含范围的第一个元素,排除最后一个元素。iloc[0:1000]返回1000个
loc:同时,包含索引。iloc[0:1000]返回1001个

8.创建一个 DataFrame italian_wines,其中包含对意大利制造的葡萄酒的评论。提示:reviews.country 等于什么?

9.创建一个 DataFrame :top_oceania_wines,其中包含来自澳大利亚或新西兰的葡萄酒的至少 95 分(满分 100 分)的所有评论。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









