







 本文详细介绍了数据库中的计算字段,包括如何创建和使用它们进行算术计算、文本处理、日期时间处理和数值处理。此外,还讲解了聚集函数如COUNT(), AVG(), MAX(), MIN(), SUM()的应用,以及如何通过GROUP BY和HAVING子句进行数据分组和过滤。子查询的概念和用法也在文中提及,展示了如何在查询中嵌套子查询以进行复杂的数据操作。
本文详细介绍了数据库中的计算字段,包括如何创建和使用它们进行算术计算、文本处理、日期时间处理和数值处理。此外,还讲解了聚集函数如COUNT(), AVG(), MAX(), MIN(), SUM()的应用,以及如何通过GROUP BY和HAVING子句进行数据分组和过滤。子查询的概念和用法也在文中提及,展示了如何在查询中嵌套子查询以进行复杂的数据操作。
什么是计数字段?
如何创建计数字段?
如何从应用程序中使用别名引用它们?
不就是连接两个表吗?
- 字段(field)
首先,计算字段实际上不存在数据库表中
7.创建计算字段
- 计算字段的另一常见用途是对检索出的数据进行算术计算
计算字段
拼接字段
执行算术计算(列1*列2)
SELECT prod_id,quantity,item_price,quantity*item_price AS expanded_price
FROM OrderItems
WHERE order_num = 20008;
8.使用函数处理数据
- ptrim():去掉字符串尾的空格
- upper():把文本转换为大写
常用的文本处理函数
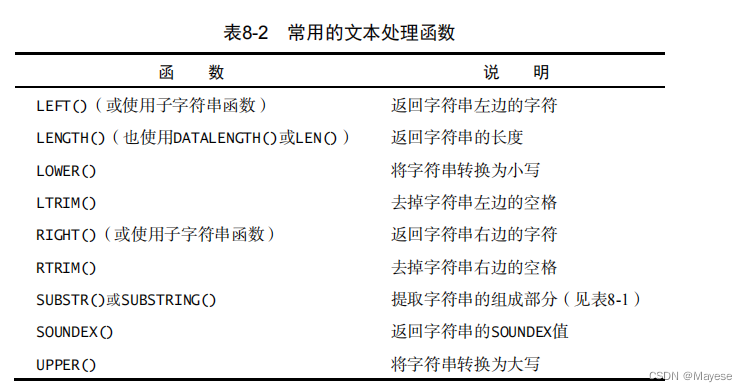
日期和时间处理函数
- yy-mm-dd:mm-ss 一般日期的格式
- datepart(yy,order_date)=2020 :两个参数,返回的成分和从中返回成分的日期。
数值处理函数
- 一般用于代数、三角或几何运算

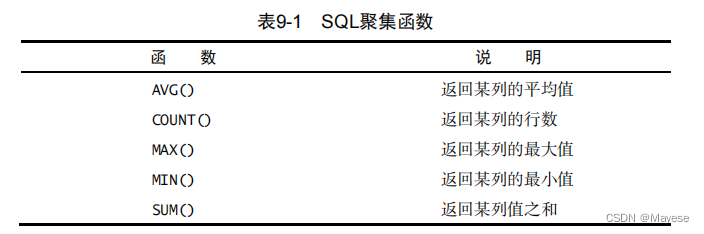
9.汇总函数
聚集函数(aggregate function)
5个聚集函数
- 获取表中的行数
- 获得表中某些行的和
- 找出表列的最大值、最小值、平均值
- AVG()只能用来确定特定数值列的平均值,而且列名必须作为函数参
数给出。为了获得多个列的平均值,必须使用多个 AVG()函数。AVG()函数忽略列值为NULL的行 - COUNT()函数进行计数。可利用 COUNT()确定表中行的数目或符合特定条件的行的数目。使用 COUNT()对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。使用 COUNT(column)对特定列中具有值的行进行计数,忽略 NULL 值。如果指定列名,则 COUNT()函数会忽略指定列的值为 NULL 的行,但如果 COUNT()函数中用的是星号(),则不忽略。
- MAX()函数:MAX()返回指定列中的最大值。MAX()要求指定列名,
- MIN()函数:MIN()的功能正好与 MAX()功能相反,它返回指定列的最小值
MIN()函数忽略列值为 NULL 的行。 - SUM()函数:SUM()用来返回指定列值的和(总计)。
--对表中行数计数并计算其列值之和
SELECR AVG(prod_price) AS avg_price FROM Products;
--counts函数的使用
SELECT COUNT(*) AS num_cust FROM Customers;
聚集不同的值(distinct)
- 对所有行执行计算,指定ALL参数或不指定参数(因为ALL是默认行)
- 只包含不同的值,指定DISTINCT参数
SELECT AVG(DISTINCT prod_price) AS avg_price
FROM Products
WHERE vend_id = 'DLL01';
组合聚集函数
SELECT COUNT(*) AS num_items,
MIN(prod_price) AS price_min,
MAX(prod_price) AS price_max,
AVG(prod_price) AS price_avg
FROM Products;
10.分组数据
- 介绍如何分组数据,以便汇总表内容的子集。
- 使用分组可以将数据分为多个逻辑组,对每个组进行聚集计算。
- SELECT语句子句:GROUP BY和HAVING
数据分组
使用count(*)返回的是所有值的,不是我们想要的单个值的形式,因此说明分组很有必要。
创建分组(group by)
- 不用指定计算和估计每个组了,系统会自动完成。
- 规定
(1)group by子句可以包含任意数目的列,因而可以对分组进行嵌套,更细致地进行分组
(2)如果在group by子句中嵌套了分组,数据将在最后指定的分组上进行汇总。
(3)group by子句中列出的每一列都必须是检索列或者有效的表达书
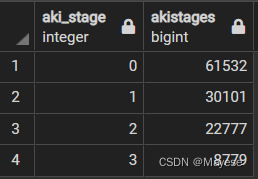
SELECT aki_stage,count(distinct icustay_id) AS akistages
FROM kdigo_stages
GROUP BY aki_stage
结果为什么有点奇怪?icustays总共的值有61532,同样怎么会有这么多icu住院患者呢?估计是原来合并的时候出现的问题,是不是把两个表直接合并,没有去重呢?还有0代表的意思是什么,健康人?非AKI患者?
SELECT count(distinct icustay_id) as aki FROM kdigo_stages
结果为:61532
过滤分组
WHERE过滤指定的是行而不是分组,实际上where 没有分组的概念。
- HAVING子句:分组后的情况汇总
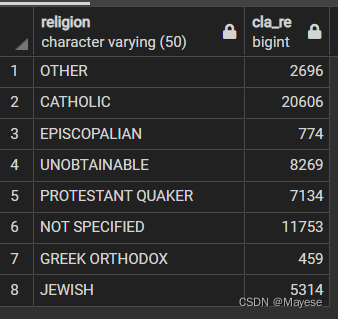
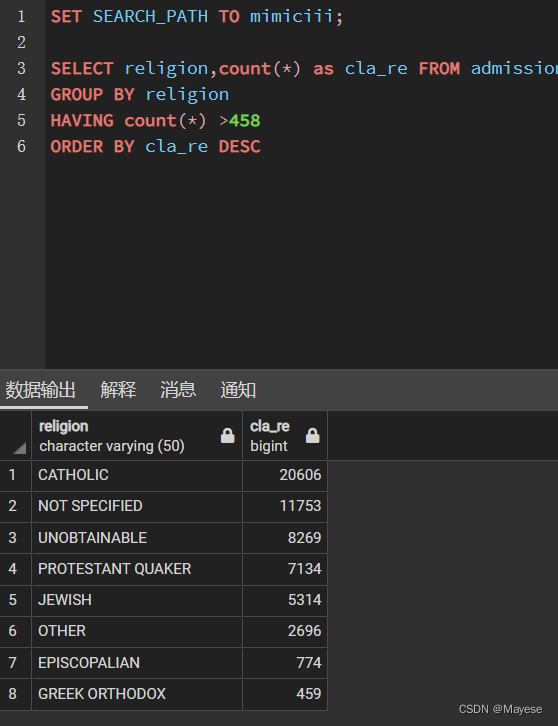
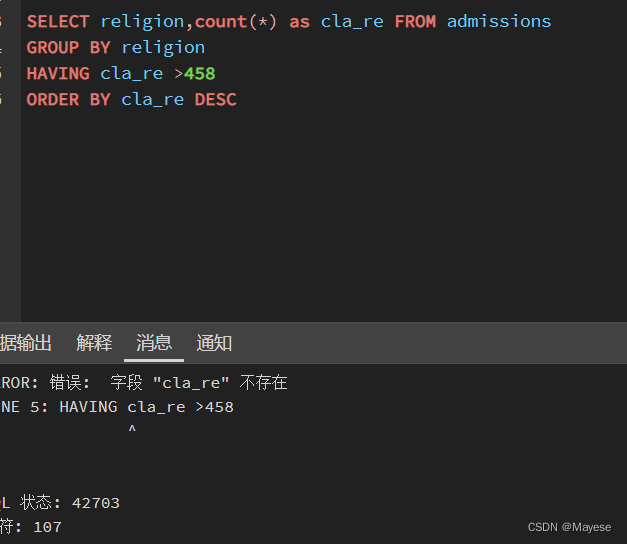
SELECT religion,count(*) as cla_re FROM admissions
GROUP BY religion
HAVING count(*) >458
结果:不能使用HAVING cla_re >458主要是因为这是计算字段,并不存在表中;
分组和排序(order)
- group by和order by的区别

为什么order by就可以用新列名,而HAVING 就不可以使用呢?
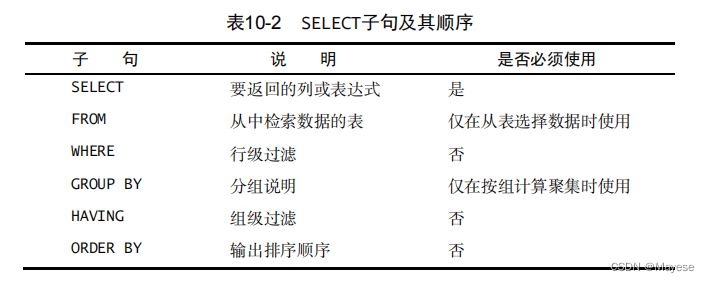
SELECT 子句顺序
11.使用子查询
子查询
- 子查询(subquery):嵌套在其他查询中的查询
利用子查询进行过滤
感觉在分组类型中比较适合应用,你看分组后的情况,再加上原来数据的列嘛
- 使用子查询的SELECT 语句只能查询单个列,企图检索多个列将返回错误。
SELECT cust_id FROM Orders
WHERE order_num IN(SELECT order_num
FROM OrderItems
WHERE prod_id = 'RGAN01');
作为计算字段使用子查询
SELECT cust_name,cust_state,
(SELECT COUNT(*)
FROM Orders
WHERE cust_id = cust_id) AS orders
FROM Customers
ORDER BY cust_name;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









