







 本文详细介绍了C语言实现LZW编码的过程,包括算法思想、核心代码和实验结果。LZW编码通过建立字典对ASCII码表进行编码和解码,文章重点解析了编码过程中的关键步骤和解码时的注意事项,还提供了完整的源代码示例。实验结果显示,对于特定类型的文件,如未经压缩的yuv、tga和rgb文件,LZW编码能显著减少文件大小,而文本重复率较高的文件压缩效果更佳。
本文详细介绍了C语言实现LZW编码的过程,包括算法思想、核心代码和实验结果。LZW编码通过建立字典对ASCII码表进行编码和解码,文章重点解析了编码过程中的关键步骤和解码时的注意事项,还提供了完整的源代码示例。实验结果显示,对于特定类型的文件,如未经压缩的yuv、tga和rgb文件,LZW编码能显著减少文件大小,而文本重复率较高的文件压缩效果更佳。
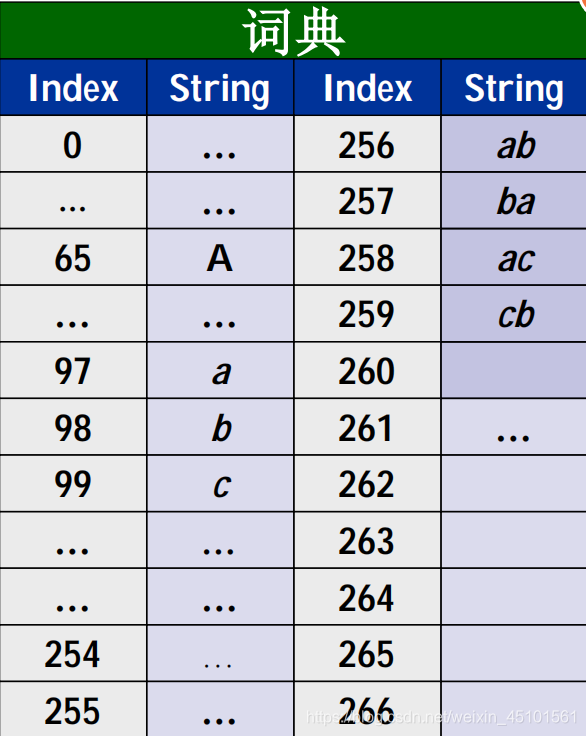
LZW编码
算法思想
首先我们有一个0到255的ASCII码表,然后得到若干字符串对其进行编码,再对编码后的码流进行解码以验证。
编码:
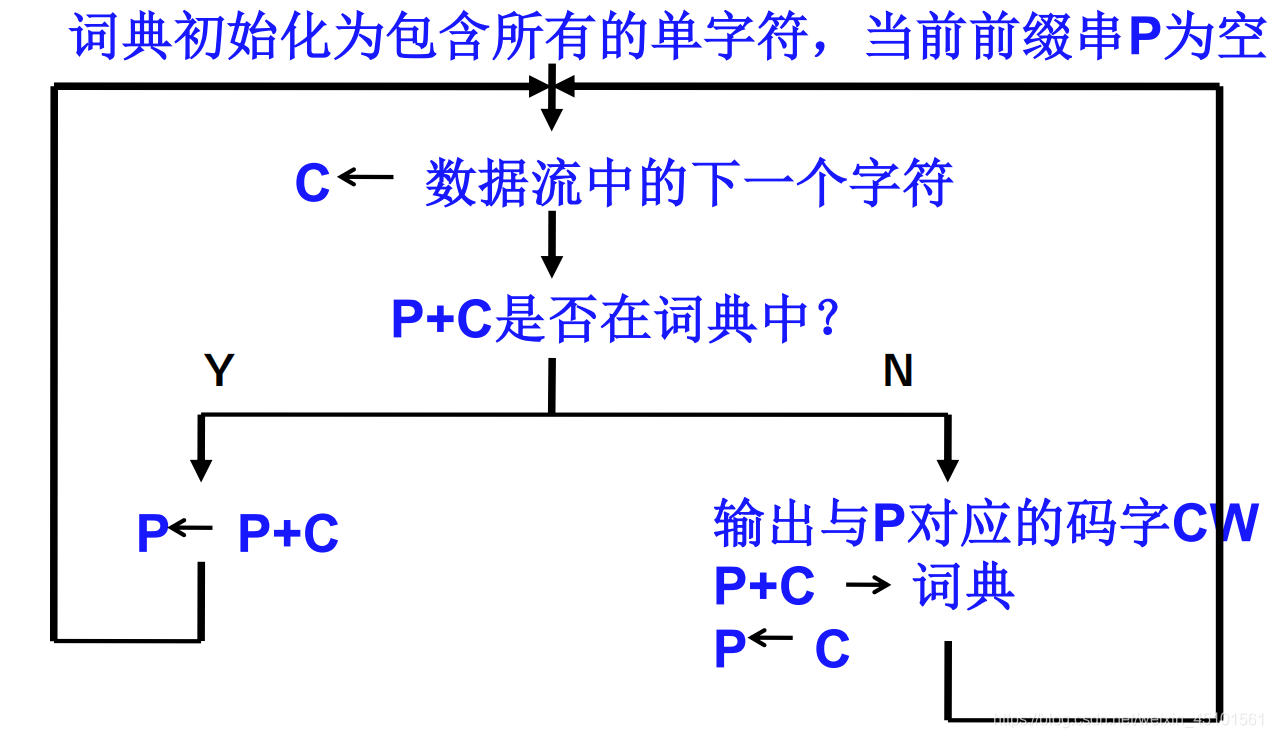 初始化:前缀P为空,第一个字符进入后缀C
初始化:前缀P为空,第一个字符进入后缀C
判断:P+C(P为a,C为b时,P+C为ab)是否在字典中?
是的话将P+C赋给前缀,下一个字符进入后缀,回到判断
否的话将P码字输出,P+C写入词典,C赋给前缀,下一个字符进入后缀,回到判断
解码:
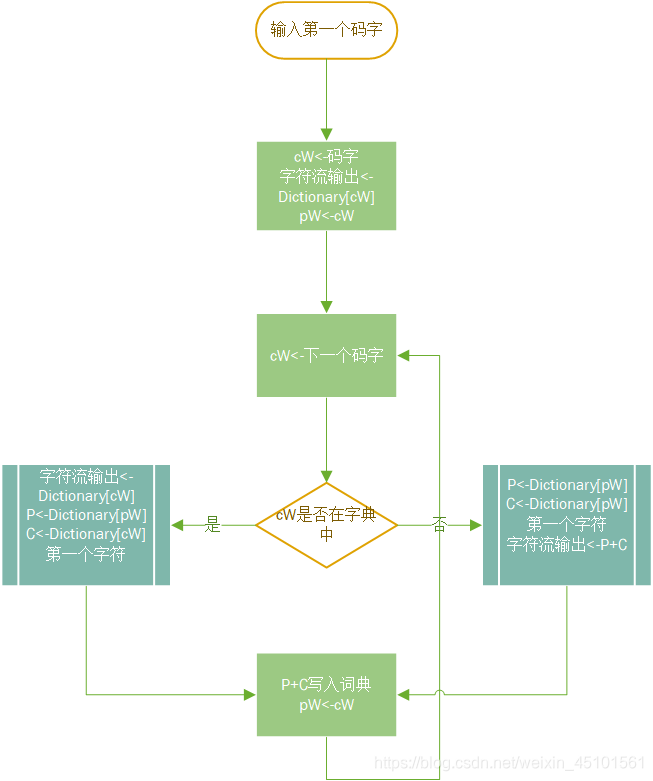 初始化:第一个码字赋值给cW,并在字典中查找到对应的字符并输出,cW再赋值给pW
初始化:第一个码字赋值给cW,并在字典中查找到对应的字符并输出,cW再赋值给pW
依次进入码字
判断:该码字是否在字典中有记录
是的话先将cW在字典中对应的字符输出,再将pW对应的字符和cW对应的字符串中第一个字符连接起来,得到P+C写入词典,cW再赋值给pW,进入下一个码字并判断。
否的话将pW对应的字符串和其字符串中第一个字符连接起来,得到P+C写入词典并输出,cW再赋值给pW,进入下一个码字并判断。
核心代码
要理解代码主要是要理解这几个变量或者函数
1.对结构体的理解
struct {
int suffix;// suffix 指的是P,parent指的是C
int parent, firstchild, nextsibling;
} dictionary[MAX_CODE + 1];
int next_code;// 指向词典中最大的码字下一个码字,例如词典中最大编码为255,next_code指向256
int d_stack[MAX_CODE]; // 一个码字对应一个字符串,主要用来依次输出字符串中的字符,为倒序排列
因为一个码字经常作为其他码字的前缀,所以通过子节点可以很快地找到一个码字的前缀对应的码字,从而逐渐一个字符一个字符输出后缀。
要注意d_stack是用来遍历输出一个码字对应的字符串的,d_stack经常被覆盖,且为倒序排列。
2.对DecodeString的理解
int DecodeString(int start, int code) {
int count;
count = start;
while (0 <= code) {
d_stack[count] = dictionary[code].suffix; // 后缀写入d_stack中
code = dictionary[code].parent; // code依次去找前缀
count++; // 计数
}
return count;
}
这个输入参数:start,指的是从输出字符串d_stack中哪个位置开始存入字符,这个主要是以后解码时,cW不在字典中的情况要涉及到一个小小的细节,后面代码会给出注释。
这个函数主要是用来输出当前码字对应的字符串以及返回该字符串的长度。
其他的代码部分理解都比较简单了。
完整代码
lzw_E.c(核心主程序)
/*
* Definition for LZW coding
*
* vim: ts=4 sw=4 cindent nowrap
*/
#include <stdlib.h>
#include <stdio.h>
#include "bitio.h"
#define MAX_CODE 65535
struct {
int suffix;// suffix 指的是P,parent指的是C
int parent, firstchild, nextsibling; // 后面两个变量是用来一个一个输出字符用的
} dictionary[MAX_CODE + 1];
int next_code;// 指向词典中最大的码字下一个码字,例如词典中最大编码为255,next_code指向256
int d_stack[MAX_CODE]; // 一个码字对应一个字符串,主要用来依次输出字符串中的字符,为倒序排列
#define input(f) ((int)BitsInput( f, 16))
#define output(f, x) BitsOutput( f, (unsigned long)(x), 16)
int DecodeString(int start, int code);
void InitDictionary(void);
// 打印从256开始,由LZW算法编码得到的码表。
void PrintDictionary(void) {
int n;
int count;
for (n = 256; n < next_code; n++) {
count = DecodeString(0, n);
printf("%4d->", n);
while (0 < count--) printf("%c", (char)(d_stack[count]));
printf("\n");
}
}
// 将码字对应的字符串中的字符一个一个存入数组d_stack当中,便于字符串输出
// 当start=0,code=258时,
// 假设码字258对应aba,P=ab,C=a,先将suffix即C中的a存入d_stack[0],然后P=a,C=b,将b存入d_stack[1],最后再将a存入d_stack[2],便于输出aba
// 返回的是这个码字对应的字符串的长度
int DecodeString(int start, int code) {
int count;
count = start;
while (0 <= code) {
d_stack[count] = dictionary[code].suffix; // 后缀写入d_stack中
code = dictionary[code].parent; // code依次去找前缀
count++; // 计数
}
return count;
}
// 初始化码表为ASCII码表
void InitDictionary(void) {
int i;
for (i = 0; i < 256; i++) {
dictionary[i].suffix = i;
dictionary[i].parent = -1;
dictionary[i].firstchild = -1;
dictionary[i].nextsibling = i + 1;
}
dictionary[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5081
5081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









