






一、测试工具下载
1.1 下载zookeeper
https://zookeeper.apache.org/releases.html#download
测试我用的是 window版本zookeeper-3.6.3
1.2 生成并修改zoo.cfg
在zookeeper的conf目录下复制一份zoo_sample.cfg文件,并重命名为zoo.cfg
修改zoo.cfg文件里面的路径(dataDir,dataLogDir为新建目录) 配置以下参数
# 存放内存数据库快照的目录
dataDir=D:zookeeper\\apache-zookeeper-3.6.3-bin\\data
# 存放事务日志目录
dataLogDir=D:zookeeper\\apache-zookeeper-3.6.3-bin\\logs
# AdminServer端口
admin.serverPort=7070
#zookeeper新版本启动的过程中,zookeeper新增的审核日志是默认关闭,所以控制台输出ZooKeeper audit is disabled,标准的修改方式应该是在zookeeper的配置文件zoo.cfg新增一行audit.enable=true即可
audit.enable=true
#客户端口
clientPort=2181
1.3 启动服务
进入bin目录下,双击zkServer.cmd
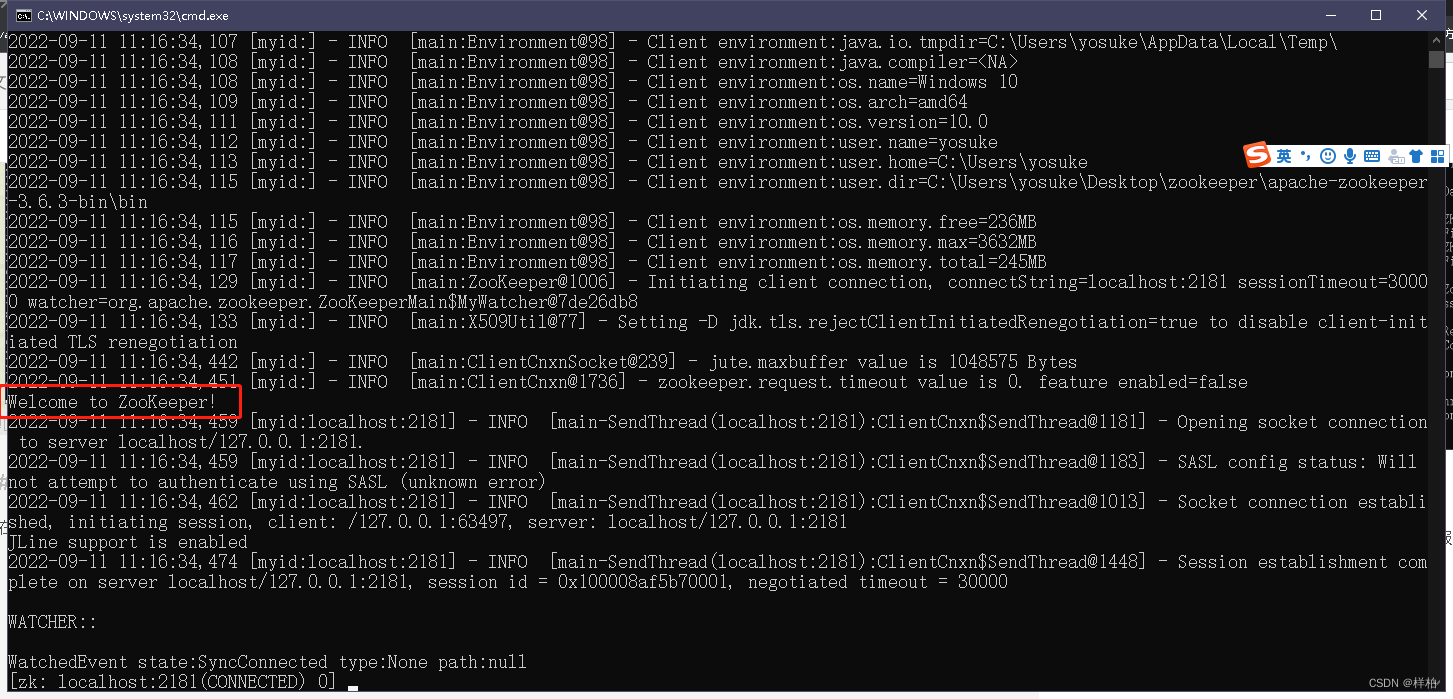
1.4 验证是否安装成功
在bin目录下双击zkCli.cmd,打开客户端(此时的服务端zkServer的dos窗口不要关闭),出现"欢迎"字样,说明安装成功!
2.1 安装kafka
kafka官网下载地址: http://kafka.apache.org/downloads.html
我下载的kafka_2.12-3.1.0.tgz,并解压到D:\kafka目录下(解压的目录不能过深,启动脚本不支持很长的路径)
2.2启动kafka
- 编辑文件Kafka配置文件, D:\kafka_2.13-2.8.0\config\server.properties
- 找到并编辑log.dirs=D:\kafka_2.13-2.8.0\kafka-logs, (自定义文件夹)
- 找到并编辑zookeeper.connect=localhost:2181。表示本地运行(默认的可以不改)
- Kafka会按照默认,在9092端口上运行,并连接zookeeper的默认端口:2181。
1.进入Kafka安装目录,新建cmd窗口:
.\bin\windows\kafka-server-start.bat .\config\server.properties
注意:不要关了这个窗口,启用Kafka前请确保ZooKeeper实例已经准备好并开始运行
2.3 创建主题
#window脚本在window文件夹下
.\bin\windows\kafka-topics.bat--create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic topic01
.\bin\windows\kafka-topics.bat--create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic topic02

2.4写入数据
简单的往topic01里面写入10条数据

二 、代码
scala代码
package cn.ac.iie.hy.datatrans.offset
import cn.ac.iie.hy.datatrans.server.SparkStreamingKafkaOffsetRedisRecoveryNew.scala_convert
import kafka.api.PartitionOffsetRequestInfo
import kafka.common.TopicAndPartition
import kafka.javaapi.consumer.SimpleConsumer
import kafka.javaapi.{OffsetRequest, PartitionMetadata, TopicMetadataRequest, TopicMetadataResponse}
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, KafkaUtils}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.Jedis
import scala.collection.immutable.Map
import scala.collection.mutable
import scala.collection.mutable.HashMap
object SparkStreamingKafkaOffsetRedisRecoveryNew {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sparkstreamingkafkaoffset").setMaster("local[*]")
val streamingContext = new StreamingContext(conf, Seconds(3))
streamingContext.sparkContext.setLogLevel("WARN")//设置日志级别
val topics = Array("topic01", "topic02")
val groups = Array("group01", "group02")
val tuples = topics.zip(groups)
//kafka的参数
var kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"auto.offset.reset" -> "earliest",
//修改为手动提交偏移量
"enable.auto.commit" -> (false: java.lang.Boolean)
)
tuples.foreach(topic_group => {
val jedis = new Jedis("192.168.21.160", 6379)
val topic = topic_group._1
val groupId = topic_group._2
val redisKey = s"${groupId}_${topic}"
//判断redis中是否保存过历史的offset
if (jedis.exists(redisKey)) {
println(s"topic:$topic reids不存在offset!")
val Java_offsetMap: java.util.Map[String, String] = jedis.hgetAll(redisKey) //partition -> offset
val offsetMap: Map[String, String] = scala_convert(Java_offsetMap) //java Map 转scala Map
val partitionToLong: mutable.HashMap[TopicPartition, Long] = getEffectiveOffsets(offsetMap, topic, "localhost")
println("merge: 合并后的offset")
println(partitionToLong.toBuffer)
kafkaParams += "group.id" -> groupId
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
//位置策略
PreferConsistent,
//订阅的策略
Subscribe[String, String](Array(topic), kafkaParams, partitionToLong)
)
stream.foreachRDD { (rdd, time) =>
//获取该RDD对应的偏移量,记住只有kafka的rdd才能强转成HasOffsetRanges类型
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
//执行这个rdd的aciton,这里rdd的算子是在集群上执行的
rdd.foreach { line =>
//println(s"time:${time}==>${line.key()} ${line.value()}")
}
//foreach和foreachPartition的区别
//foreachPartition不管有没有数据都会执行自己的function
//foreach只在有数据时执行自己的function
// rdd.foreachPartition(it =>{
// val list: List[ConsumerRecord[String, String]] = it.toList
// println(list)
// })
//将offset保存回redis
val pipeline = jedis.pipelined()
offsetRanges.foreach(eachRange => {
/**
* redis结构
* key: {groupId}_${topic}
* value :Map(partition -> offset )
*/
val topic: String = eachRange.topic
val fromOffset: Long = eachRange.fromOffset
val endOffset: Long = eachRange.untilOffset
val partition: Int = eachRange.partition
val redisKey = s"${groupId}_${topic}"
pipeline.hset(redisKey,partition.toString,endOffset.toString)
println(s"time $time topic:${eachRange.topic} partitioner:${eachRange.partition}_offset : ${eachRange.untilOffset.toString}")
})
pipeline.sync()
}
}else{
println(s"topic:$topic reids不存在offset!")
kafkaParams += "group.id" -> groupId
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
//位置策略
PreferConsistent,
//订阅的策略
Subscribe[String, String](Array(topic), kafkaParams)
)
stream.foreachRDD { (rdd, time) =>
//获取该RDD对应的偏移量,记住只有kafka的rdd才能强转成HasOffsetRanges类型
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
//执行这个rdd的aciton,这里rdd的算子是在集群上执行的
rdd.foreach { line =>
//println(s"time:${time}==>${line.key()} ${line.value()}")
}
//将offset保存回redis
val pipeline = jedis.pipelined()
offsetRanges.foreach(eachRange => {
/**
* redis结构
* key: {groupId}_${topic}
* value :Map(partition -> offset )
*/
val topic: String = eachRange.topic
val fromOffset: Long = eachRange.fromOffset
val endOffset: Long = eachRange.untilOffset
val partition: Int = eachRange.partition
val redisKey = s"${groupId}_${topic}"
pipeline.hset(redisKey,partition.toString,endOffset.toString)
println(s"time $time topic:${eachRange.topic} partitioner:${eachRange.partition} _offset : ${eachRange.untilOffset.toString}")
})
pipeline.sync()
}
}
})
streamingContext.start()
streamingContext.awaitTermination()
}
def getEffectiveOffsets(offsetMap: Map[String, String], topic: String, host: String): HashMap[TopicPartition, Long] = {
// 存储Redis的offset
val redisOffsetMap = new HashMap[TopicPartition, Long]
offsetMap.foreach(patition_offset => {
val tp = new TopicPartition(topic, patition_offset._1.toInt)
redisOffsetMap += tp -> patition_offset._2.toLong
})
println(s" kafka该主题:$topic ----------Redis 维护的offset----------------")
println(redisOffsetMap.toBuffer)
//**********用于解决SparkStreaming程序长时间中断,再次消费时已记录的offset丢失导致程序启动报错问题
import scala.collection.mutable.Map
//存储kafka集群中每个partition当前最早的offset
val clusterEarliestOffsets = Map[Long, Long]()
val consumer: SimpleConsumer = new SimpleConsumer(host, 9092, 100000, 64 * 1024,
"leaderLookup" + System.currentTimeMillis())
//使用隐式转换进行java和scala的类型的互相转换
import scala.collection.convert.wrapAll._
val request: TopicMetadataRequest = new TopicMetadataRequest(List(topic))
val response: TopicMetadataResponse = consumer.send(request)
consumer.close()
//<topic1_Metadata(p1,p2) topic2_Metadata(p1)> => <topic1_Metadata_p1 ,topic1_Metadata_p2 ,topic1_Metadata_p1>
val metadatas: mutable.Buffer[PartitionMetadata] = response.topicsMetadata.flatMap(f => f.partitionsMetadata)
//从kafka集群中得到当前每个partition最早的offset值
metadatas.map(f => {
val partitionId: Int = f.partitionId
val leaderHost: String = f.leader.host
val leaderPort: Int = f.leader.port
val clientName: String = "Client_" + topic + "_" + partitionId
val consumer: SimpleConsumer = new SimpleConsumer(leaderHost, leaderPort, 100000,
64 * 1024, clientName)
val topicAndPartition = new TopicAndPartition(topic, partitionId)
val requestInfo = new HashMap[TopicAndPartition, PartitionOffsetRequestInfo]();
//kafka.api.OffsetRequest.LatestTime
requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(kafka.api.OffsetRequest.EarliestTime, 1));
val request = new OffsetRequest(requestInfo, kafka.api.OffsetRequest.CurrentVersion, clientName)
val response = consumer.getOffsetsBefore(request)
val offsets: Array[Long] = response.offsets(topic, partitionId)
consumer.close()
clusterEarliestOffsets += ((partitionId, offsets(0)))
})
println(s"-------topic:$topic 最早offset--------------")
println(clusterEarliestOffsets)
//外循环是kafka 最早offsets
for ((clusterPartition, clusterEarliestOffset) <- clusterEarliestOffsets) {
val tp = new TopicPartition(topic, clusterPartition.toInt)
val option: Option[Long] = redisOffsetMap.get(tp)
// kafka 有的分区,但Redis 没有, 原因:kafka新增了分区
if (option.isEmpty) { //取最早的offset
println(s"====>topic:$topic 新增了分区: $tp")
redisOffsetMap += (tp -> clusterEarliestOffset)
} else {
var redisOffset: Long = option.get
if (redisOffset < clusterEarliestOffset) { //redis中存的offset对比最早的offset已经丢失,取最早的offset
redisOffset = clusterEarliestOffset
redisOffsetMap += (tp -> redisOffset)
}
}
}
redisOffsetMap
}
}
第一次启动
程序前台打印:(订阅了topic01)
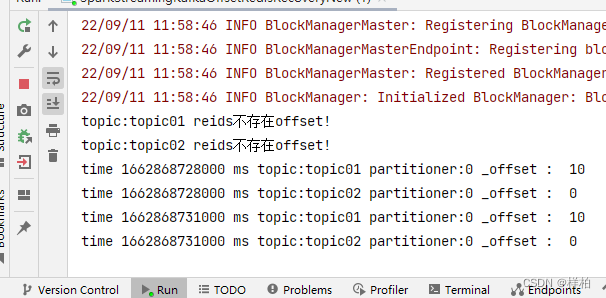
redis monitor监控

- 为了看着方便就没有前台打印数据,从redis维护的offset可以看到已经把10条数据消费完了
三、实际解决的问题
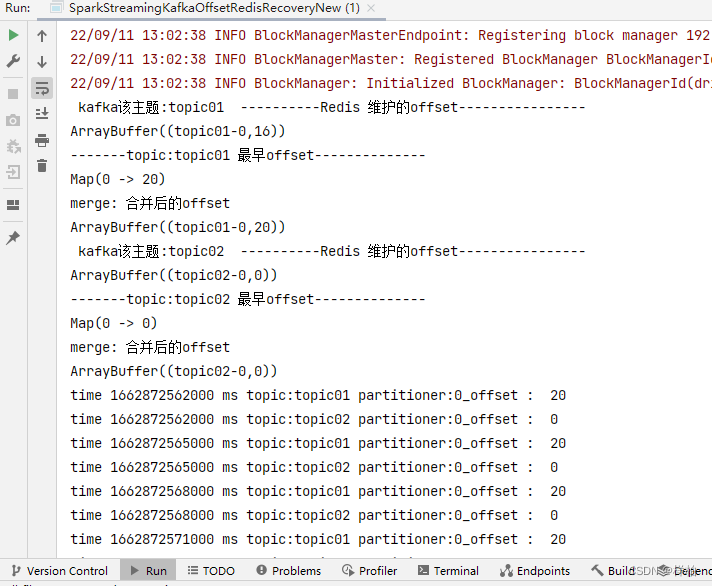
1.sparkstreaming启动时offset超出范围,程序可以进行修正到目前最早offset
这个原因有2个,第一个可能是kafka的默认保存logs文件过期了,第二个可能是存储压力大人为的删除了kafka数据(我简单的用第一种情况模拟下)
1.1修改 server.properties 文件 将过期时间调整至3分钟
log.retention.minutes=3

- 重启kafka 等待日志过期
此时redis保存的offset为16(),再写入4条等待过期后,启动程序- 用命令行查看数据已经被清除

程序对过期的offset进行了修正
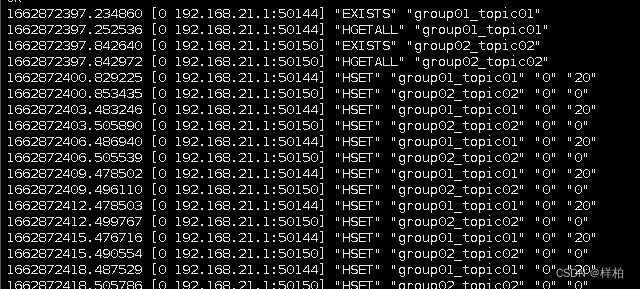
- 用命令行查看数据已经被清除
2.kafka某个topic新增了分区,程序启动时能感知到并在更新到redis进行消费
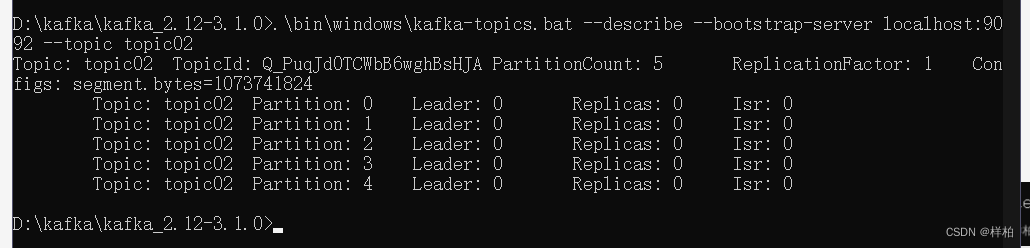
将topic02增加到5个分区

启动程序
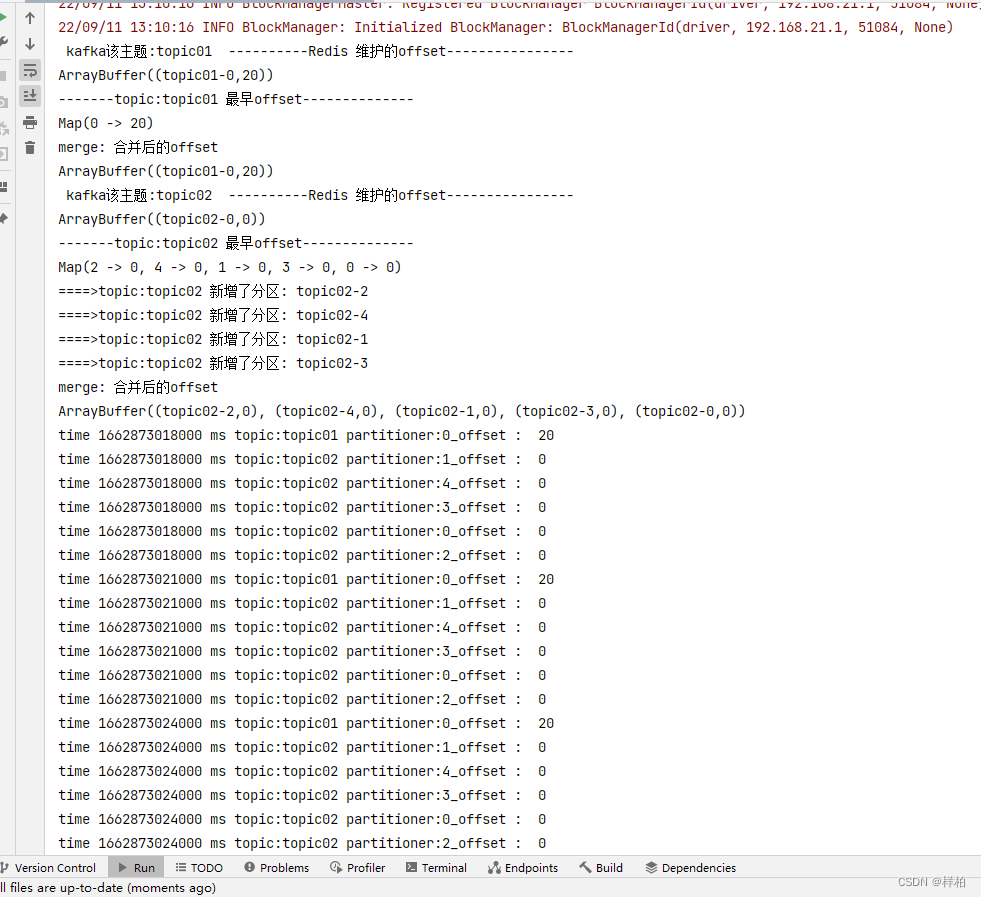
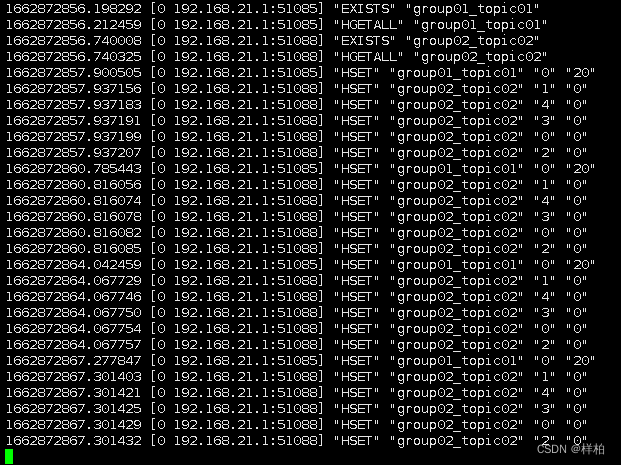
- 可以看到已经将新分区的offset信息保存到redis并进行了订阅
四.修正的策略
2个部分都封装了得到offsetMap的方法 方便调用
1.从有效位置的最早或最晚位置消费:用SimpleConsumer这个底层Api获取分区元数据,比如上面的代码就是从有效的最早位置开始消费。
def getEffectiveOffsets(offsetMap: Map[String, String], topic: String, host: String): HashMap[TopicPartition, Long] = {
// 存储Redis的offset
val redisOffsetMap = new HashMap[TopicPartition, Long]
offsetMap.foreach(patition_offset => {
val tp = new TopicPartition(topic, patition_offset._1.toInt)
redisOffsetMap += tp -> patition_offset._2.toLong
})
println(s" kafka该主题:$topic ----------Redis 维护的offset----------------")
println(redisOffsetMap.toBuffer)
//**********用于解决SparkStreaming程序长时间中断,再次消费时已记录的offset丢失导致程序启动报错问题
import scala.collection.mutable.Map
//存储kafka集群中每个partition当前最早的offset
val clusterEarliestOffsets = Map[Long, Long]()
val consumer: SimpleConsumer = new SimpleConsumer(host, 9092, 100000, 64 * 1024,
"leaderLookup" + System.currentTimeMillis())
//使用隐式转换进行java和scala的类型的互相转换
import scala.collection.convert.wrapAll._
val request: TopicMetadataRequest = new TopicMetadataRequest(List(topic))
val response: TopicMetadataResponse = consumer.send(request)
consumer.close()
//<topic1_Metadata(p1,p2) topic2_Metadata(p1)> => <topic1_Metadata_p1 ,topic1_Metadata_p2 ,topic1_Metadata_p1>
val metadatas: mutable.Buffer[PartitionMetadata] = response.topicsMetadata.flatMap(f => f.partitionsMetadata)
//从kafka集群中得到当前每个partition最早的offset值
metadatas.map(f => {
val partitionId: Int = f.partitionId
val leaderHost: String = f.leader.host
val leaderPort: Int = f.leader.port
val clientName: String = "Client_" + topic + "_" + partitionId
val consumer: SimpleConsumer = new SimpleConsumer(leaderHost, leaderPort, 100000,
64 * 1024, clientName)
val topicAndPartition = new TopicAndPartition(topic, partitionId)
val requestInfo = new HashMap[TopicAndPartition, PartitionOffsetRequestInfo]();
//kafka.api.OffsetRequest.LatestTime
requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(kafka.api.OffsetRequest.EarliestTime, 1));
val request = new OffsetRequest(requestInfo, kafka.api.OffsetRequest.CurrentVersion, clientName)
val response = consumer.getOffsetsBefore(request)
val offsets: Array[Long] = response.offsets(topic, partitionId)
consumer.close()
clusterEarliestOffsets += ((partitionId, offsets(0)))
})
println(s"-------topic:$topic 最早offset--------------")
println(clusterEarliestOffsets)
//外循环是kafka 最早offsets
for ((clusterPartition, clusterEarliestOffset) <- clusterEarliestOffsets) {
val tp = new TopicPartition(topic, clusterPartition.toInt)
val option: Option[Long] = redisOffsetMap.get(tp)
// kafka 有的分区,但Redis 没有, 原因:kafka新增了分区
if (option.isEmpty) { //取最早的offset
println(s"====>topic:$topic 新增了分区: $tp")
redisOffsetMap += (tp -> clusterEarliestOffset)
} else {
var redisOffset: Long = option.get
if (redisOffset < clusterEarliestOffset) { //redis中存的offset对比最早的offset已经丢失,取最早的offset
redisOffset = clusterEarliestOffset
redisOffsetMap += (tp -> redisOffset)
}
}
}
redisOffsetMap
}
2.从指定时间往后的offset开始消费(固定时间,相对时间)
def getEffectiveOffsets_SpecifiedTime(offsetMap: Map[String, String], topic: String, day:Long,kafkaConsumer: KafkaConsumer[String,String]): HashMap[TopicPartition, Long] = {
// 存储Redis的offset
val redisOffsetMap = new HashMap[TopicPartition, Long]
offsetMap.foreach(patition_offset => {
val tp = new TopicPartition(topic, patition_offset._1.toInt)
redisOffsetMap += tp -> patition_offset._2.toLong
})
println(s" kafka该主题:$topic ----------Redis 维护的offset----------------")
println(redisOffsetMap.toBuffer)
//day天前 0点
val fetchDataTime = LocalDate.now.atStartOfDay(ZoneId.systemDefault).toInstant.toEpochMilli - day * 24 * 60 * 60 * 1000
val partitionToLong = SpecifiedTimeConsumer_java.getPartitionToLong(kafkaConsumer, topic, fetchDataTime)
println(s"-------time:$day 天最早offset--------------")
println(partitionToLong.toString)
import scala.collection.JavaConverters._
partitionToLong.asScala.foreach(f=>{
val tp: TopicPartition = f._1
val clusterEarliestOffset: Long = f._2
val option: Option[Long] = redisOffsetMap.get(tp)
// kafka 有的分区,但Redis 没有, 原因:kafka新增了分区
if (option.isEmpty){
println(s"====>topic:$topic 新增了分区: $tp")
redisOffsetMap += (tp -> clusterEarliestOffset)
}else{
var redisOffset: Long = option.get
if (redisOffset < clusterEarliestOffset) { //redis中存的offset对比 day天前的offset已经丢失 ,取day天前的offset
redisOffset = clusterEarliestOffset
redisOffsetMap += (tp -> redisOffset)
}
}
})
redisOffsetMap
}
2.1 调用的getPartitionToLong方法代码及其演示方法功能
package cn.ac.iie.hy.datatrans.offset;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndTimestamp;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.TopicPartition;
import java.time.LocalDate;
import java.time.ZoneId;
import java.util.*;
/**
* 23:10 分
*/
public class SpecifiedTimeConsumer_java {
private static HashMap<TopicPartition, Long> getPartitionToLong(KafkaConsumer<String, String> consumer, String topic, Long fetchDataTime) {
HashMap<TopicPartition, Long> topicPartitionLong = new HashMap<>();
// 获取topic的partition信息
List<PartitionInfo> partitionInfos = consumer.partitionsFor(topic);
List<TopicPartition> topicPartitions = new ArrayList<>();
Map<TopicPartition, Long> timestampsToSearch = new HashMap<>();
for (PartitionInfo partitionInfo : partitionInfos) {
topicPartitions.add(new TopicPartition(partitionInfo.topic(), partitionInfo.partition()));
timestampsToSearch.put(new TopicPartition(partitionInfo.topic(), partitionInfo.partition()), fetchDataTime);
}
consumer.assign(topicPartitions);
// 获取每个partition偏移量
Map<TopicPartition, OffsetAndTimestamp> map = consumer.offsetsForTimes(timestampsToSearch);
OffsetAndTimestamp offsetTimestamp = null;
System.out.println("开始设置各分区初始偏移量...");
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : map.entrySet()) {
// 如果设置的查询偏移量的时间点大于最大的索引记录时间,那么value就为空
offsetTimestamp = entry.getValue();
if (offsetTimestamp != null) {
int partition = entry.getKey().partition();
long timestamp = offsetTimestamp.timestamp();
long offset = offsetTimestamp.offset();
// 设置读取消息的偏移量 只用返回的map可以注释
consumer.seek(entry.getKey(), offset);
topicPartitionLong.put(new TopicPartition(topic, partition), offset);
}
}
System.out.println("设置各分区初始偏移量结束...");
return topicPartitionLong;
}
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "group01");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
String topic = "topic01";
//今天0点开始
//long fetchDataTime = LocalDate.now().atStartOfDay(ZoneId.systemDefault()).toInstant().toEpochMilli();
//10 分钟前开始
long fetchDataTime = System.currentTimeMillis() - 30 * 60 * 1000;
HashMap<TopicPartition, Long> partitionToLong = getPartitionToLong(consumer, topic, fetchDataTime);
//int count = 0;
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
String value = record.value();
System.out.println("消息:" + value);
}
}
}
}
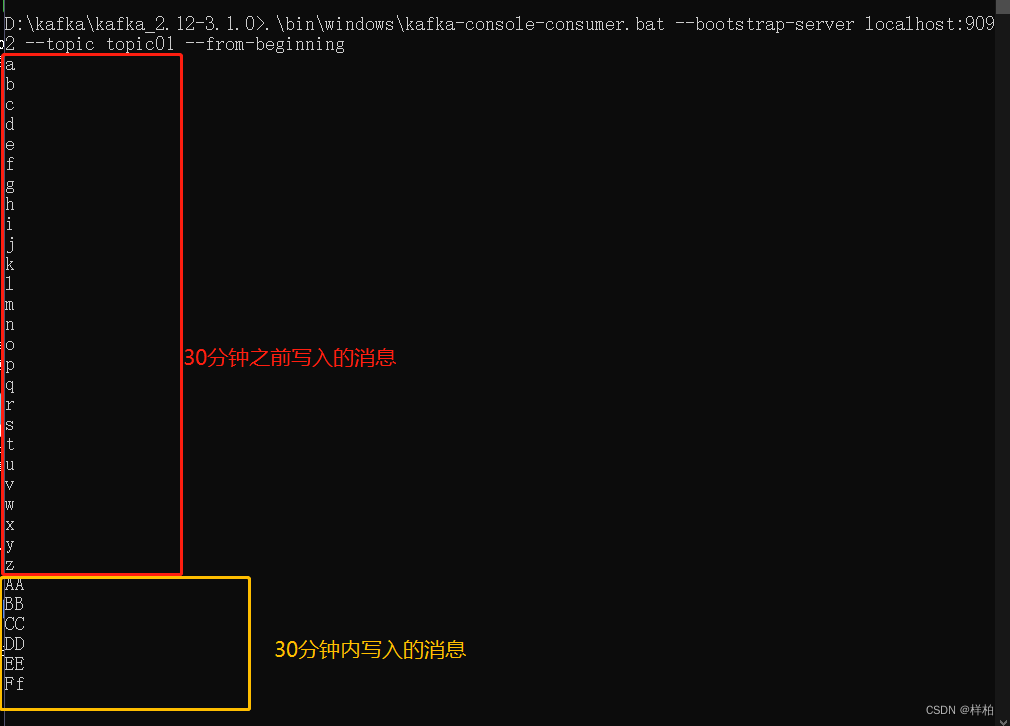
相对时间 30分钟前进行消费
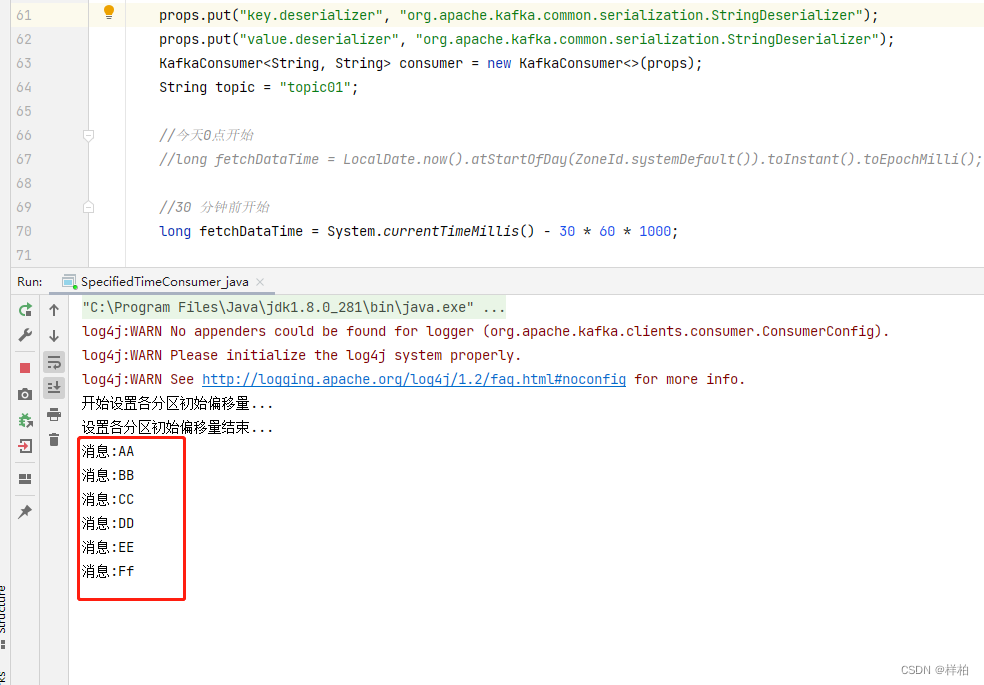
固定时间昨天0点进行消费
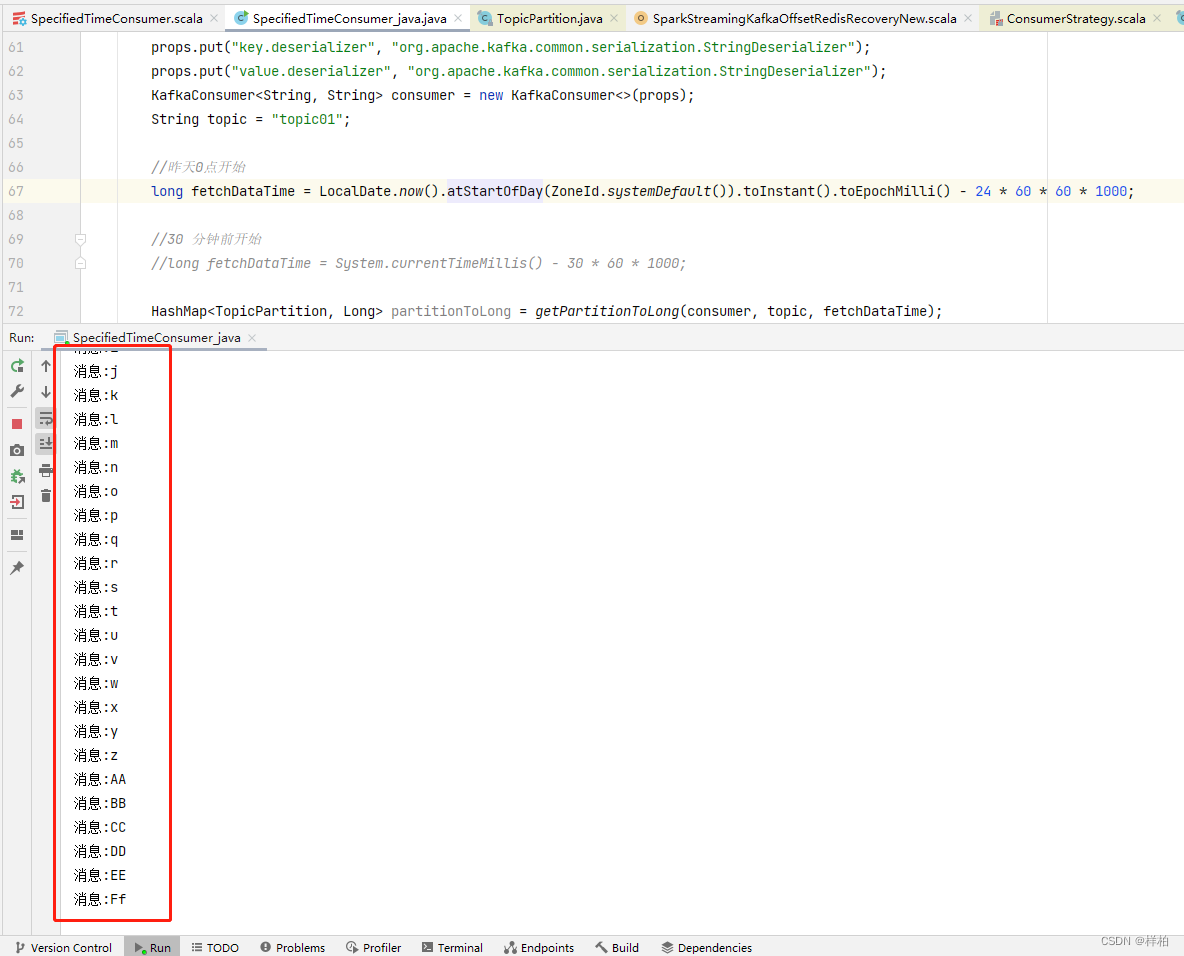
半小时前的消息全部能消费到
今天0点开始(当前时间0:12 )
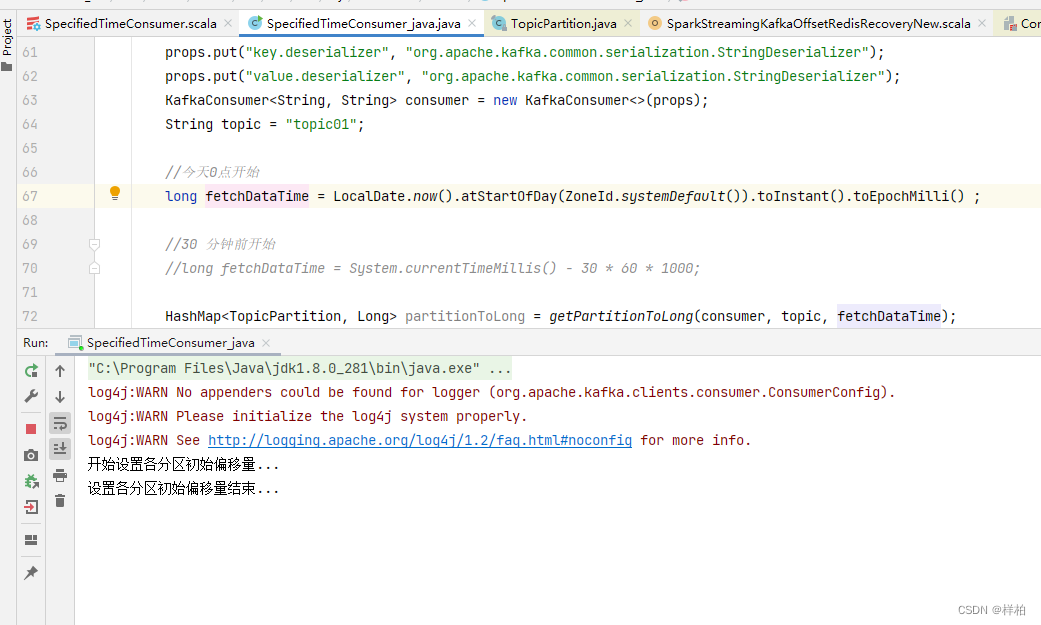
数据都是在0点前写入的,没有消费到数据
用到的命令
#启动redis
redis-server /usr/local/redis/redis.conf
#监控redis
redis-cli -h localhost -p 6379 monitor
#启动kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties
#创建topic
.\bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic topic01
#生产者
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic topic01
#消费者
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic topic01 --from-beginning
#查看所有分区
.\bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --list
#查看分区
.\bin\windows\kafka-topics.bat --describe --bootstrap-server localhost:9092 --topic topic02
#增加分区
.\bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --alter --topic topic02 --partitions 5














 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









