







总结
租服务器配好conda环境,把环境迁移到没联网的学校服务器,要注意一定要检查两个服务器的CUDA版本是不是不同的,这可能会带来一些问题,因为CUDA是不在conda环境里面的。
最后解决安装dgl版本问题还是采用下载whl文件pip离线安装的。所以我们最好一开始就在autodl租一个跟学校服务器配置相同的服务器喽(也有同学选择先用虚拟机配环境应该也是个不错的选择),学校服务器(teacher09) torch版本1.10.0+cu102,CUDA10.1
问题背景
租autodl服务器https://www.autodl.com/跑代码(pycharm链接远程服务器可以在其帮助文档最佳实践中查看)太花钱,学校服务器不联网用着太不舒服,尝试创建conda环境,配置好环境之后把conda环境打包到学校服务器,是不是完美解决
创建虚拟环境
以最近跑的项目CKBC 常识库补全为例
conda create -n CKBC_myk python=3.8
conda env list
在activate之前,有时候需要先conda init 再重启shell
conda activate CKBC_myk
pip install torch==1.10.0
pip install numpy
pip install tqdm
pip install transformers
pip install matplotlib
安装dgl
安装dgl rgcn跑代码尝试,错误解决
https://www.dgl.ai/pages/start.html
https://pytorch-geometric.com/whl/torch-1.10.0%2Bcu113.html
# 查看cuda版本
nvcc --version
#------打印信息:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Mon_May__3_19:15:13_PDT_2021
Cuda compilation tools, release 11.3, V11.3.109
Build cuda_11.3.r11.3/compiler.29920130_0
# 安装dgl
pip install -U isort==5.10.1 -i https://pypi.mirrors.ustc.edu.cn/simple
pip install dgl-cu113 dglgo -f https://data.dgl.ai/wheels/repo.html
#pip install dgl-cu117 dglgo -f https://data.dgl.ai/wheels/repo.html
生成requirements
-
生成requirements.txt方便后续使用
进conda虚拟环境,cd到项目目录下,执行:好像还是会下很多多余的库
pip freeze > requirements.txt注意:这个会把环境中的所有库都保存下来,配合virtualenv才好用。如果没有virtualenv,这个方法会保存很多多余的库。
可以采用
pip install pipreqs pipreqs --force ./ # 如果报错,pipreqs ./ --encoding=utf-8
打包环境
- 打包环境,直接zip打包是我自己想的,可能会有问题,可以跳过这两段代码,直接往后看,使用conda-pack打包
先传到本地,再传到学校服务器的conda env路径下后解压apt-get update apt-get install zip zip -r CKBC_my.zip CKBC_myk/unzip CKBC_my.zip
找到其他环境迁移的方式:
https://huaweicloud.csdn.net/63806a8ddacf622b8df87613.html
推荐使用conda pack
第二种方式就是利用 conda-pack 命令直接对环境进行 打包。要想使用 conda-pack 包对环境打包实现环境迁移,我们需要提前安装一下 conda-pack包,conda-pack包是一个命令行工具,主要用于打包conda环境(包括环境中安装的软件包的所有二进制文件),此方法最好的地方就是 在没有网络的情况下仍可实现环境的复现,简直不要太优秀,下面说一下使用 conda-pack 的具体操作。
- 安装conda-pack包
或者conda install -c conda-forge conda-packpip install conda-pack - 使用 conda pack 命令开始打包环境
解压tar.gz# 将名字为 my_env 的虚拟环境 打包为 my_env.tar.gz(默认就是这形式) conda pack -n my_env # -o 就是给导出的虚拟环境重新命名,所以导出来的虚拟环境名字为 out_name.tar.gz conda pack -n my_env -o out_name.tar.gz # 指定虚拟环境包的输出路径 conda pack -p /explicit/path/to/my_env
tar -xzvf file.tar.gz -C /home_data/teacher09/anaconda3/envs/
报错了
# 部分报错信息:
import dgl
File "/home_data/teacher09/anaconda3/envs/CKBC_myk/lib/python3.8/site-packages/dgl/__init__.py", line 16, in <module>
self._handle = _dlopen(self._name, mode)
OSError: libcudart.so.11.0: cannot open shared object file: No such file or directory
解决问题
上面的报错,我最开始以为是环境打包有问题,重新弄了几遍还是不行,中间又尝试是dgl相关的几个包的问题,但是在学下服务器又报一些其他的错误,看文件以为是找不到那个文件,重新去找到python-package里的那个文件替换还是不行,同时又学了一下liunx中文件的权限等,解决问题还问了同学,网上查了很多资料,一直以为是环境打包或者可能是miniconda和anaconda两个服务器不同的问题,后面我有搬出来chatgpt,逐渐解决问题,把我与chatgpt的对话放在文末
📌注意单纯的迁移环境,我仍然遇到了问题,一定要检查两个服务器的CUDA版本是不同的,这可能会带来一些问题,通过nvcc -version查看学校服务器的版本。发现是:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Sun_Jul_28_19:07:16_PDT_2019
Cuda compilation tools, release 10.1, V10.1.243
查看torch版本
conda activate CKBC_myk
python -c "import torch; print(torch.__version__)"
# 1.10.0+cu102
在https://pytorch-geometric.com/whl/查找对应的版本
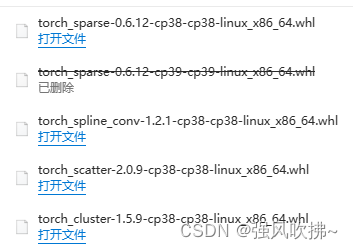
下载四个文件,上传到服务器先pip uninstall 掉对应的四个库,再pip install *.whl重新安装即可
https://www.dgl.ai/pages/start.html重新安装dgl
pip install dgl-cu102 dglgo -f https://data.dgl.ai/wheels/repo.html
离线安装需要下载dgl文件https://data.dgl.ai/wheels/repo.html
找到对应版本下载上传到服务器安装即可
chatgpt帮我分析问题实录
self._handle = _dlopen(self._name, mode)
OSError: libcudart.so.11.0: cannot open shared object file: No such file or directory
-
这是一条错误消息,表示程序尝试打开一个动态链接库(.so文件)失败。
-
具体来说,这条消息指出,程序尝试打开名为libcudart.so.11.0的动态链接库,但无法找到该文件。因此,打开失败,并引发了一个OSError异常。
-
这个错误的原因可能是:
-
您的系统中确实没有这个动态链接库。在这种情况下,您可能需要安装该库才能继续使用。
-
您的系统中有这个动态链接库,但程序无法找到它。在这种情况下,您可能需要检查您的环境变量,确保系统知道该库的位置。
-
希望这对您有帮助!如果您还有其他问题,请随时告诉我。
有这个文件,系统也知道位置
-
如果您的系统中有这个动态链接库文件,并且系统也知道该文件的位置,但程序仍然无法打开该文件,那么可能存在其他问题。
-
其中一个可能的原因是,动态链接库文件可能已损坏或损坏。在这种情况下,您可能需要重新安装该文件或尝试使用一个备用文件。
-
另一个可能的原因是,程序所需的库的版本与您的系统中安装的版本不匹配。在这种情况下,您可能需要卸载现有版本并安装所需版本的库,以确保程序可以使用所需的库。
-
还有一个可能的原因是,程序使用的库可能依赖于其他库,而这些库可能尚未安装或无法找到。在这种情况下,您可能需要安装所有必需的库,以确保程序可以正常运行。
-
希望这些信息能帮助您解决问题。如果您还有其他问题,请随时告诉我。
服务器没有联网,我无法直接安装
-
如果您的服务器没有联网,则无法直接在线安装库或软件。但是,您仍有一些选择:
-
将所需的库或软件下载到另一台联网的计算机上,然后将其复制到服务器上。您可以使用USB闪存驱动器或网络共享(如Samba或NFS)将文件复制到服务器上。
-
如果所需的库或软件非常大,则可能无法通过复制文件来解决问题。在这种情况下,您可能需要使用本地包管理器(例如apt或yum)手动安装库或软件。此方法需要您事先下载所需的所有包(包括依赖项),然后手动安装这些包。
-
如果您无法通过上述方法解决问题,您还可以尝试编译所需的库或软件。这通常需要您下载源代码,并使用编译器(例如gcc或clang)在本地机器上编译库或软件。编译后,您可以将生成的二进制文件复制到服务器上。
-
希望这些信息能帮助您解决问题。如果您还有其他问题,请随时告诉我。
我就是将所需的库或软件下载到另一台联网的计算机上,然后将其复制到服务器上。再那台联网的计算机上没有问题,但是复制过来就报错了
-
如果您在另一台联网的计算机上下载并使用了库或软件,但是将其复制到服务器上后出现错误,可能是因为以下原因之一:
-
复制过程中可能会发生数据丢失或损坏,导致库或软件无法正常工作。在这种情况下,您可能需要重新下载文件并重新复制。
-
您的服务器可能没有安装所需的运行时环境或其他依赖项。在这种情况下,您可能需要安装所有必需的依赖项,以确保库或软件可以正常运
(CKBC_myk) teacher09@gpu1:~/mayuke/CKBC/whl-torch1.10.0-cu113$ pip install torch_cluster-1.6.0-cp38-cp38-linux_x86_64.whl
Processing ./torch_cluster-1.6.0-cp38-cp38-linux_x86_64.whl
torch-cluster is already installed with the same version as the provided wheel. Use --force-reinstall to force an installation of the wheel.
Could not fetch URL https://pypi.org/simple/pip/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host=‘pypi.org’, port=443): Max retries exceeded with url: /simple/pip/ (Caused by SSLError(SSLCertVerificationError(1, ‘[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate (_ssl.c:1131)’))) - skipping
WARNING: There was an error checking the latest version of pip.
-
这个错误信息提示在安装所提供的whell文件时出现了问题。具体来说,您的系统中已经安装了相同版本的torch-cluster,因此无法再次安装。
-
另外,您的系统无法从PyPI服务器获取最新版本信息,因为它无法验证SSL证书。这可能是由于服务器的证书过期或无效导致的。
-
如果您希望强制重新安装所提供的whell文件,可以使用 --force-reinstall 选项。例如:
-
pip install --force-reinstall torch_cluster-1.6.0-cp38-cp38-linux_x86_64.whl -
但是,如果您希望更新到最新版本的torch-cluster,则需要解决无法验证SSL证书的问题。可以尝试以下方法之一:
-
尝试更新服务器的时间,以确保它与网络时间同步。
-
尝试更新服务器的证书颁发机构(CA)
服务器没有联网
-
如果您的服务器没有联网,则无法自动下载和安装库或软件。但是,您仍有一些选择:
-
将所需的库或软件下载到另一台联网的计算机上,然后将其复制到服务器上。您可以使用USB闪存驱动器或网络共享(如Samba或NFS)将文件复制到服务器上。
-
如果所需的库或软件非常大,则可能无法通过复制文件来解决问题。在这种情况下,您可能需要使用本地包管理器(例如apt或yum)手动安装库或软件。此方法需要您事先下载所需的所有包(包括依赖项),然后手动安装这些包。
-
如果您无法通过上述方法解决问题,您还可以尝试编译所需的库或软件。这通常需要您下载源代码,并使用编译器(例如gcc或clang)在本地机器上
我在服务器A用conda创建虚拟环境,并将miniconda3/envs/CKBC_myk,采用conda pack打包环境,并传输到服务器B上的anaconda3/envs/CKBC_myk,使用同样的环境,我的代码在服务器A是正常运行的,但是到服务器B上就发生了报错,报错信息如
-
如果在服务器A上使用conda创建了虚拟环境,并将其打包并复制到服务器B上,但在服务器B上运行代码时报错,可能是由于以下原因之一:
-
虚拟环境打包的过程中可能发生了数据丢失或损坏,导致虚拟环境无法正常工作。在这种情况下,您可能需要重新创建虚拟环境并重新打包。
-
服务器B上的Anaconda安装可能与服务器A上的Anaconda安装不同,或者服务器B上的系统可能与服务器A上的系统不同。在这种情况下,虚拟环境可能需要在服务器B上重新安装或调整。
-
服务器B上的环境变量可能与服务器A上的环境变量不同。在这种情况下,您的代码可能需服务器B上的虚拟环境可能缺少在服务器A上运行代码所需的任何库或软件。在这种情况下,您需要确保在服务器B上的虚拟环境中安装所有必要的库或软件。
-
在服务器A上运行代码时,可能有一些环境变量或配置文件被修改,而这些修改在服务器B上的虚拟环境中没有反映出来。在这种情况下,您可能需要将服务器A上的所有修改都复制到服务器B上。
-
我建议您仔细检查服务器B上的虚拟环境,确保其与服务器A上的虚拟环境尽可能相似,并试图确定导致问题的原因。如果您仍然无法解决问题,可能需要提供更多信息,例如报错信息、代码片段和您尝试的解决方案,以便更好地帮助您。
import dgl
File “/home_data/teacher09/anaconda3/envs/CKBC_myk/lib/python3.8/site-packages/dgl/init.py”, line 16, in
self._handle = _dlopen(self._name, mode)
OSError: libcudart.so.11.0: cannot open shared object file: No such file or directory
上面是部分报错信息 -
根据您提供的信息,您在服务器B上的虚拟环境中尝试导入dgl库,但操作失败,并出现了一条报错信息:“libcudart.so.11.0: cannot open shared object file: No such file or directory”。这意味着系统无法打开文件"libcudart.so.11.0",可能是因为文件不存在或无法访问。
-
libcudart.so是CUDA的共享库,它包含了用于运行CUDA程序的功能。如果无法打开这个文件,则可能是因为没有安装CUDA或者安装的CUDA版本与您的系统不兼容。另外,如果文件存在,但无法访问,则可能是因为文件的权限设置问题。
-
要解决这个问题,您需要检查服务器B上的CUDA版本,确保它与您的系统兼容。如果需要,可以尝试安装或升级CUDA。如果文件存在,但无法访问,则可以尝试修改文件的权限,使其可以被访问。
-
另外,您可能需要确保在服务器B上的虚拟环境中安装了所有需要的库或软件,包括dgl库。如果您仍然无法解决问题,可以尝试提供更多的信息,例如您的代码片段和您尝试的解决方
如何检查服务器B上的CUDA版本
-
要检查服务器B上的CUDA版本,您可以使用以下方法之一:
-
在服务器B上运行以下命令:
nvcc --version -
这会显示安装在服务器B上的CUDA版本号。
-
查看服务器B上安装的CUDA软件包。通常,CUDA软件包会在/usr/local/cuda目录下安装。您可以使用ls命令查看该目录下的文件,以确定安装的CUDA版本。例如:
ls /usr/local/cuda -
查看服务器B上安装的CUDA驱动。您可以使用以下命令查看安装的CUDA驱动版本:
cat /proc/driver/nvidia/version -
这可以显示安装在服务器B上的CUDA驱动版本号。
-
查看服务器B上的系统信息。您可以使用uname命令查看系统内核版本,然后使用lsb_release命令查看操作系统版本。这可以
查看torch版本
-
要查看服务器B上安装的torch版本,您可以在服务器B上使用以下命令:
-
python -c "import torch; print(torch.__version__)" -
这会在终端中显示安装的torch版本号。
-
如果您使用的是conda虚拟环境,则可以在该虚拟环境中使用上述命令。例如,如果您使用的是名为"myenv"的conda虚拟环境,则可以使用以下命令:
-
conda activate myenv -
python -c "import torch; print(torch.__version__)" -
注意:如果您使用的是pip安装的torch,则需要在终端中使用pip命令查看版本号。例如:
-
pip show torch
-
这会显示torch包的版本号以及其他信息。
<module ‘torch.version’ from ‘/home_data/teacher09/anaconda3/envs/CKBC_myk/lib/python3.8/site-packages/torch/version.py’>
-
您正在导入torch.version模块。这是一个内置的Python模块,包含有关torch库的信息。
-
如果您想要查看torch库的版本号,可以使用torch.__version__属性。例如:
-
import torch
print(torch.version) -
这应该会显示安装的torch版本号。如果您使用的是conda虚拟环境,则需要先激活虚拟环境,然后才能运行上述代码。
-
注意:如果您使用的是pip安装的torch,则需要使用pip命令查看版本号。例如:
-
pip show torch
-
这会显示torch包的版本号以及其他信息。
这是在线安装dgl的方法pip install dgl-cu102 dglgo -f https://data.dgl.ai/wheels/repo.html,如何离线安装呢
-
要在服务器B上离线安装dgl,您需要:
-
使用联网计算机下载dgl安装包:https://data.dgl.ai/wheels/repo.html
-
将下载的安装包复制到服务器B上。
-
在服务器B上打开终端,进入安装包所在的目录。
-
在终端中使用以下命令安装dgl:
-
pip install dgl-*.whl
-
注意:您需要根据服务器B上的CUDA版本和操作系统类型选择适当的安装包。例如,如果服务器B上的CUDA版本为10.2,则需要使用dgl-cu102的安装包。如果服务器B上的操作系统为Linux,则需要使用名称中包含"linux"的安装包。
-
如果您使用的是conda虚拟环境,则需要先激活















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









