







配置模式下enable secret level 15 cisco123 配置密码为cisco123(进入特权模式需要输入的密码)
配置模式下hostname ar1 更改设备名
特权模式下show IP interface brief 查看接口ip
配置模式下interface g0/0
IP address 12.1.1.1 255.255.255.0 配置ip地址(与华为一样,但是子网掩码不能直接写24)
no shutdown 激活接口,使接口进入up状态
show interface g0/0 查看端口详细配置
show ip interface g0/0 查看接口三层信息
show version 查看内核版本
console控制台密码配置:
配置模式下line console 0
login
password galaxy123
end
删除提示,配置模式下:
no banner exec
no banner incoming
no banner login
远程登陆密码:
telnet方式:不安全
ar2远程登录ar1
ar1:配置模式下line vty 0 4 进入远程试图
transport input ssh telnet ar1的入方向上允许远程ssh,telnet登录
login
password galaxy456
ar2:特权模式下telnet ar1的ip
ssh方式:安全
ar1上
配置模式下:username test password test 创建远程登陆的用户名和密码
line vty 0 4
login local 登录时本地认证
配置模式下:
ip domain-name galaxy 创建域名galaxy
crypto key generate rsa modulus 2048 生成用于保护会话的加密密钥
(密钥长度)
ssh version 2 建议使用版本2(不是必须,但是强烈建议)
ar2:ssh -l test(用户名) 12.1.1.1(ar1的ip)
ar1:who 查看当前谁在远程登录自己的设备
ar1:clear line 数字(上个命令who查看到的最前面的数字) 清空当前的远程登陆用户
对密码进行加密:默认情况下,只有启用密码(enable时)是加密的,要对用户模式密码和启用密码进行加密,必须手工配置,在路由器上show running-config时,会看到除启用加密密码外的其他所有密码
手工配置密码加密,在配置模式下service password-encryption
然后show running-config查看,这时所有密码都进行加密
erase startup-config 清空配置命令(或者reload)
traceroute ip地址 测试中间经过哪些设备
show ip interface 查看ip与接口相关信息
show ip interface brief 查看ip与接口相关信息
show mac address-table 查看mac地址表(该表项包含了vlan,终端设备的mac地址,类型及动态学习,从哪个端口学到的mac地址)
mac address-table aging-time 299 修改mac地址表的老化时间为299秒,默认300秒
mac-address-table aging-time 60 vlan 1 将VLAN 1的MAC地址老化时间改为60秒
show mac address-table interface 接口 查看接口的mac地址表
手工静态指定MAC地址:
mac-address-table static 0013.1a2f.0680 vlan 1 interface f0/2 指定VLAN 1的接口F0/2的MAC地址为0013.1a2f.0680
指定丢弃某个MAC地址:
mac-address-table static 0013.1a2f.0680 vlan 2 drop 此配置将使源MAC为0013.1a2f.0680的数据包在VLAN 2被丢弃,但在别的VLAN通信正常
show interface 接口 查看物理接口的mac地址
show interface vlan 1 查看SVI接口的mac地址
show flash 显示了flash中存放的IOS情况,flash的总大小,可用空间
terminal history size 50 将查看命令设置为50条(默认为10)
copy running-config startup-config 把内存中的配置保存到NVRAM中,路由器开机时会读取它
CDP(Cisco Discovery Protocol)协议是Cisco专有的协议,是使Cisco网络设备能够发现相邻的、直连的其他Cisco设备的协议。CDP是数据链路层的协议,因此使用不同的网络层协议的Cisco设备也可以获得对方的信息。CDP协议默认是启动的。
接口宏(macro)定义:
当在交换机的日常管理中,可能需要多次对多个非连续的接口进行管理和配置,而当需要进入多个非连续接口时,输入的命令较为烦琐,所以为了方便,系统允许人工将多个接口定义成一个组,这个组成为宏(macro),当进入这个宏(macro),就等于进入了组中的所有接口,对宏(macro)做出的配置,将对组中的所有接口生效,即便交换机重启后,所定义的宏(macro)仍旧存在,可以多次使用,直到手工删除。
定义宏(macro):
define interface-range ccie f0/1 - 2 , f0/4 , f0/6 – 7 将接口F0/1,F0/2,F0/4,F0/6,F0/7放入了宏ccie中,对宏ccie所做的配置将对F0/1,F0/2,F0/4,F0/6,F0/7生效。
interface range macro ccie
description abc 对宏ccie所做的配置将对F0/1,F0/2,F0/4,F0/6,F0/7生效。
sh run | b inter 查看结果,可以看到配置文件中,对宏ccie所做的配置将对F0/1,F0/2,F0/4,F0/6,F0/7生效,其它接口配置保存原状
vlan:
enable
conf t
vlan 100,101 创建vlan 100,101
name v100 给vlan 100命名为v100
interface 接口
switchport mode access 将接口配置为access口
switchport mode trunk 将接口配置为trunk口(思科的trunk口默认允许所有的vlan通过)
switchport trunk encapsulation dot1q 使用802.1q封装
switchport access vlan 100 将接口划分到vlan 100中
switchport trunk allowed vlan 100,101 接口允许vlan100,101通过
switchport trunk allowed vlan add 102 增加允许vlan102通过
wr 保存
show vlan brief 查看vlan的简要信息
show interface trunk 查看trunk口信息(允许那些vlan通过,默认全部)
show protocols vlan 100 查看SVI接口状态
同步vlan:
sw3:配置模式:vtp domain galaxy 创建vtp域,名字叫galaxy
vtp password galaxy123 配置vtp密码为galaxy123
vtp mode server vtp角色为服务器
sw4:配置模式:vtp domain galaxy 创建vtp域,名字叫galaxy
vtp password galaxy123 配置vtp密码为galaxy123
vtp mode client vtp角色为客户端
sw5:配置模式:vtp domain galaxy 创建vtp域,名字叫galaxy
vtp password galaxy123 配置vtp密码为galaxy123
vtp mode client vtp角色为客户端
sw6:配置模式:vtp domain galaxy 创建vtp域,名字叫galaxy
vtp password galaxy123 配置vtp密码为galaxy123
vtp mode client vtp角色为客户端
sw7:配置模式:vtp domain galaxy 创建vtp域,名字叫galaxy
vtp password galaxy123 配置vtp密码为galaxy123
vtp mode client vtp角色为客户端
do show vtp status 查看vtp信息
sw3:配置模式:vlan 10
exit
vlan 20
exit
vlan 30
exit
vlan 40
这时其他交换机都同步创建vlan 10 20 30 40(show vlan)(在做好trunk口之后才能做vtp)
DTP:
DTP (Dynamic Trunking Protocol):动态trunk配置协议,不用手工指定trunk封装协议,交换机自动判断是否将接口配置为trunk口,默认封装协议是ISL(思科私有协议)
DTP采用协商的方式来决定是否将接口配置为Trunk,可配置的接口模式,准确地讲,应该是3种,分别为ON,desirable,auto,下面详细介绍各模式功能:
ON其实就是手工静态配置为Trunk,并且还会向对方主动发起DTP信息,要求对方也工作在Trunk模式,无论对方邻居在什么模式,自己永远工作在Trunk模式。
Desirable此模式为DTP主动模式,工作在此模式的接口会主动向对方发起DTP信息,要求对方也工作在Trunk模式,如果对方回复同意工作在Trunk模式,则工作在Trunk模式,如果没有DTP回复,则工作在access模式。
Auto此模式为DTP被动模式,工作在此模式的接口不会主动发起DTP信息,只会等待对方主动发起DTP信息,如果收到对方的DTP信息要求工作在Trunk模式,则自己回复对方同意工作在Trunk模式,最后的模式为Trunk,如果DTP被动模式收不到DTP要求工作在Trunk的信息,则工作在access模式。
以上三种接口模式都会产生DTP信息,ON和desirable是主动产生DTP信息,而auto是被动生产DTP信息,如果手工将接口配置成Trunk模式后,可以关闭DTP信息以节省资源,关闭DTP的模式为nonegotiate。
注:Access模式不是DTP的一部分。开启DTP协商的双方都必须在相同的VTP域内,否则协商不成功。
交换机的型号不同,默认的DTP模式会有所不同,3550默认为desirable模式,3560默认为auto模式。当收不到对方DTP回复时,则选择工作在access模式。
1.SW1与SW2相连,配置SW1为desirable,SW2为Trunk
SW1:
interface f0/23
switchport mode dynamic desirable
SW2:
int f0/23
switchport trunk encapsulation dot1q
switchport mode trunk
show interface f0/23 switchport 查看结果,可以看到,双方接口的DTP协商是开启的,因为双方都会主动发起DTP要求对方工作在trunk,所以最终双方的工作模式为Trunk(两台交换机上都看)
2.配置SW1为desirable,SW2为auto
SW1:
int f0/23
switchport mode dynamic desirable
SW2:
int f0/23
switchport mode dynamic auto
show interface f0/23 switchport 查看结果,可以看到,双方接口的DTP协商是开启的,因为SW1会主动发起DTP要求对方工作在trunk,而SW2会同意工作在Trunk,所以最终双方的工作模式为Trunk,并且封装协议优选ISL
3.配置SW1为auto,SW2为auto
SW1:
int f0/23
switchport mode dynamic auto
SW2:
int f0/23
switchport mode dynamic auto
show interface f0/23 switchport 查看结果,可以看到,双方接口的DTP协商是开启的,但由于双方都不会主动发起DTP要求对方工作在trunk,所以最终双方的工作模式为access
4.配置SW1为desirable,SW2为Trunk,并且关闭DTP(即为nonegotiate)
SW1:
interface f0/23
switchport mode dynamic desirable
SW2:
int f0/23
switchport trunk encapsulation dot1q
switchport mode trunk
switchport nonegotiate
show interface f0/23 switchport 查看结果,可以看到,SW1的DTP协商是开启的,而SW2的DTP协商是关闭的,所以最终SW1的接口选择工作在access模式,而SW2的模式永远都为Trunk
5.配置双方都为desirable,但VTP不在相同域内
vtp domain ccie
int f0/23
switchport mode dynamic desirable
vtp domain cisco
int f0/23
switchport mode dynamic desirable
show interface f0/23 switchport 可以看到,双方的DTP协商都是开启的,并且模式都为desirable,正常情况下,双方最终模式应为trunk,然而,由于双方的VTP域名不同,所以DTP协商会失败,所以最终双方的工作模式为access模式
SVI接口(华为的是vlanif接口)配置:
interface vlan 100 进入vlan 100接口
ip address ip地址 子网掩码(不能是位,比如华为的可以写24,思科不可以)
no shutdown 使SVI接口up(默认shutdown)
no ip cef 关闭思科模拟器交换机设备上的思科快速转发,否则造成vlan间的数据不被转发,思科模拟器的bug(在接口下配置)
将接口转变为二层或三层接口
interface 接口
ip routing 开启思科交换机的三层功能(真实设备默认不开启)
no switchport 关闭二层功能(使得交换机接口变为三层接口)
配置VRRP:
interface vlan 100
no shutdown
ip address ip地址 子网掩码 这里配置的ip地址为SVI接口地址(不是虚拟ip)
vrrp 100 ip地址 配置vrrp组100,IP地址配置的为虚拟ip地址(不同于上边的SVI地址)
vrrp 100 priority 110 配置vrrp组100的优先级为110,使它成为master设备
show vrrp brief 查看vrrp组中不同的主备角色
单臂路由配置:
路由器上配置子接口(默认物理接口shutdown,需要no shutdown才能开始配置子接口),交换机上创建vlan 100,101,交换机和路由器相连的接口使用干道模式,和pc相连的接口允许各自对应的vlan通过
interface 接口 进入接口
no shutdown
no ip address
interface 子接口20 创建子接口,推荐接口id和vlan id相同,避免冲突
encapsulation dot1q 20(vlan id) 子接口封装vlan id
ip address ip地址 子网掩码 配置子接口的ip地址(为vlan 20的网关地址)
interface 子接口30 创建子接口,推荐接口id和vlan id相同,避免冲突
encapsulation dot1q 30(30代表vlan id) 子接口封装vlan id
ip address ip地址 子网掩码 配置子接口的ip地址(为vlan 30的网关地址)
show ip interface brief 查看接口信息,确保子接口正常工作
生成树:
思科设备默认开启生成树,只不过不是华为的MSTP,而是PVST(每个vlan一个生成树)
配置模式:spanning-tree mode pvst 配置思科生成树模式为pvst(默认,show running-config看不到)
SW1:配置模式:spanning-tree vlan 8,10,11 priority 0 配置vlan优先级,将SW1配置为vlan8,10,11的根设备(也可以用来根据vlan指定数据转发路径)
SW1:配置模式:spanning-tree vlan 1,12,9,99 priority 4096 配置vlan优先级(只能为4096的倍数),将SW1配置为vlan 1,12,9,99的备份根
SW2与SW1刚好相反
show spanning-tree vlan 8 查看每个vlan的STP生成树状态
spanning-tree mode mstp
spanning-tree mst configuration 进入MST的配置模式
revision 10 从默认的配置版本号改为10
name liudehao 从默认的空名字改为liudehao
instance 1 vlan 1,3,5 实例1中映射vlan 1,3,5
instance 2 vlan 2,4,6 实例2中映射vlan 2,4,6
show pending 查看实例绑定的vlan情况
show spanning-tree 这时查看生成树就为多生成树
show spanning-tree mst configuration 验证配置结果
spanning-tree mst 1 priority 0 配置实例1的优先级为0(最优,优先级是4096的倍数)
spanning-tree mst 2 priority 4096 配置实例2的优先级为4096
上面两条命令在SW1上配置,表明SW1是实例1的主根(vlan1,3,5优先走SW1),是实例2的备份根
show spanning-tree mst 1 验证生成树状态,如果是在SW1上查看,应当有Root | this switch for MST1,表示SW1是实例1的根设备,通常根设备上的所有接口都为转发状态(在汇聚层查看)
show spannng-tree vlan 1 查看接入层设备的vlan 1的生成树状态,用于辨认vlan 1的流量是交给汇聚层SW1还是SW2做转发(在接入层查看)
no spanning-tree vlan 10 在pvst+可以配置关闭vlan 10的stp,pvst+只支持128个实例,如果交换机上的vlan数量大于128,超过的vlan数量将不会运行stp,会造成环路,可以针对某些vlan配置,不用全部配置
MSTP最多支持65个STP实例,但是映射到实例的VLAN数量是没有限制的。默认所有VLAN都在实例0
Rapid PVST+:Rapid PVST+就是具有RSTP特性的PVST+,是像RSTP一样基于IEEE 802.1w运行的,其它所有运行与规则与PVST+完全相同
spanning-tree vlan 1 port-prority 32 配置接口优先级,越小越优先(范围0-255,默认128,必须为16整数)
spanning-tree vlan 10 root primary 指定交换机为vlan 10的根
spanning-tree mst 1 root primary 配置交换机为实例1和实例2的根交换机
Port Fast:在思科交换机上,通过配置Port Fast功能,便可以使接口跳过STP的计算,从而直接过渡到forwarding状态(相当于边缘端口)
access接口和Trunk接口都可以配置Port Fast功能。如果将交换机连交换机的接口变成Port Fast,则是制造环路
当开启了Port Fast功能的接口,如果在接口上收到BPDU后,就认为对端连接的是交换机,而并非主机或服务器,因此默认在接口收到BPDU后会立即关闭该接口的Port Fast功能
配置:
SW1和SW2之间使用两条线相连,需要关闭SW2的二层功能,因为如果SW2的端口是二层接口,那么就会向SW1发送BPDU,最终会造成SW1由于收到BPDU而关闭Port Fast功能,所以就无法验证Port Fast
interface range 接口
no switchport
在SW1上开启Port Fast功能:无论access还是trunk都可以
interface range 接口
switchport mode access
spanning-tree portfast
验证:
show spanning-tree interface 接口 portfast 已开启Port Fast功能
如果此时SW2的二层功能开启,portfast状态就会关闭
在全局模式下配置Port Fast(只能对access接口生效):
首先将SW2上接口的二层功能关闭
interface range 接口
no switchport
SW1上配置:因为对方(SW2)是三层端口,在本地配置DTP后,会自动形成access模式
interface range 接口
switchport mode dynamic desirable
show interfaces 接口 switchport 查看SW1的端口状态,DTP已经将本地端口变为access模式
在SW1全局开启Port Fast:
spanning-tree portfast default
查看SW1上端口的Port Fast状态:
show spanning-tree interface 接口 portfast SW1上的access端口受全局配置影响,已经变成Port Fast端口
BPDU Guard:
因为开启了Port Fast功能的端口,会跳过STP的计算,从而直接过渡到forwarding状态。当端口连接的是主机或服务器,这样的操作不会有任何问题,但如果连接的是交换机,就会收到BPDU,就证明在此接口开启Port Fast功能是错误的配置。为了杜绝此类错误配置,BPDU Guard功能可以使端口在收到BPDU时,立即被shutdown或进入err-disabled状态。
BPDU Guard可以在接口下或全局开启,但操作会有所不同。
如果BPDU Guard是全局开启,则只对portfast端口有影响,当portfast端口收到BPDU后,会shutdown此端口,需要注意,某些型号的交换机会将接口error-disabled。
如果BPDU Guard是接口下开启,将对任何端口有影响,无论是正常端口还是portfast端口;当端口收到BPDU后,会变成error-disabled状态
配置:
在全局模式下配置BPDU Guard(只对Port Fast端口有影响):
将SW2的端口F0/23和F0/24改成三层接口,禁止从端口上向SW1发送BPDU
interface range f0/23 - 24
no switchport
将SW1的端口F0/23 配置为Port Fast,F0/24为正常端口
intterface f0/23
switchport mode access
spanning-tree portfast
intterface f0/24
switchport mode access
show spanning-tree interface f0/23 portfast 查看SW1的端口F0/23和F0/24 的状态,SW1的端口F0/23已经变成Port Fast状态,而F0/24为正常端口,并且两个端口都为正常UP状态
在SW1全局开启BPDU Guard(只对Port Fast端口有影响)
spanning-tree portfast bpduguard default
在SW2的端口F0/23和F0/24向SW1发送BPDU,测试BPDU Guard,只要将SW2的端口F0/23和F0/24变成二层端口,便可以从此端口向外发送BPDU
int ran f0/23 - 24
switchport
show spanning-tree interface f0/23 portfast 查看SW1的端口状态,可以看见,SW1的portfast端口F0/23收到BPDU后,受到BPDU Guard的影响,端口被shutdown,并且变成error-disabled,(某些型号不会),而全局BPDU Guard不能影响非portfast端口,所以F0/24还是正常状态
在接口模式下配置BPDU Guard(将对任何端口生效):
将SW2的端口F0/23和F0/24改成三层接口,禁止从端口上向SW1发送BPDU
interface range f0/23 - 24
no switchport
将SW1的端口F0/23 配置为Port Fast,F0/24为正常端口
intterface f0/23
switchport mode access
spanning-tree portfast
intterface f0/24
switchport mode access
在SW1的端口F0/23和F0/24开启BPDU Guard
interface range f0/23 - 24
spanning-tree bpduguard enable
show spanning-tree interface f0/23 portfast 查看SW1的端口F0/23和F0/24 的状态,SW1上的端口F0/23为portfast状态,F0/24为正常状态,并且状态都为UP
在SW2的端口F0/23和F0/24向SW1发送BPDU,测试BPDU Guard
interface range f0/23 - 24
switchport
show spanning-tree interface f0/23 portfas 查看SW1的23,24端口状态,SW1的端口在收到BPDU后,受到BPDU Guard的影响,无论是正常端口还是portfast端口,都被err-disabled
BPDU Filtering:
BPDU Filtering可以过滤掉在接口上发出或收到的BPDU,这就相当于关闭了接口的STP,将会有引起环路的可能。
BPDU Filtering的配置同样也分两种,可以在接口下或在全局模式开启,但是不同的模式开启,会有不同效果。
如果BPDU Filtering是全局开启的,则只能在开启了portfast的接口上过滤BPDU,并且只能过滤掉发出的BPDU,并不能过滤收到的BPDU,因为BPDU Filtering的设计目的是当交换机端口上连接的是主机或服务器时,就没有必要向对方发送BPDU,所以要过滤掉BPDU,但如果连接的是交换机,则会收到BPDU,而且会引起环路,所以这样的情况,配置BPDU Filtering就是错误的。
而当一个开启了portfast功能的bbs.freeit.com.cn152接口,在开启了BPDU Filtering后,如果还能收到BPDU,则BPDU Filtering特性会丢失,因此,还会造成接口portfast特性的丢失。
如果是在接口模式下开启的,则可以过滤掉任何接口收到和发出的BPDU。(此理论为重点)
配置:
将SW2的端口F0/23和F0/24改成三层接口,禁止从端口上向SW1发送BPDU
interface range f0/23 - 24
no switchport
将SW1的端口F0/23 配置为Port Fast,F0/24为正常端口,但开启BPDU Guard
intterface f0/23
switchport mode access
spanning-tree portfast
intterface f0/24
switchport mode access
spanning-tree bpduguard enable
show spanning-tree interface f0/23 portfast 查看SW1的端口F0/23和F0/24 的状态,SW1的端口F0/23为Port Fast状态,F0/24为正常状态,并且状态为UP
在SW1上全局开启BPDU Filtering(只能过滤portfast上的BPDU):
spanning-tree portfast bpdufilter default
在SW2的端口F0/23和F0/24向SW1发送BPDU,测试BPDU Filtering:
interface range f0/23 - 24
switchport 只要将SW2的端口F0/23和F0/24变成二层端口,便可以从此端口向外发送BPDU
查看SW1的端口状态:
show spanning-tree interface f0/23 portfast
show interface f0/24
因为F0/24是普通端口,全局配置的BPDU Filtering不能过滤普通端口上的BPDU,所以收到了BPDU后,但由于BPDU Guard,最后端口被err-disabled。
而F0/23是开启了portfast功能的接口,在开启了BPDU Filtering后,如果还能收到BPDU,则BPDU Filtering特性会丢失,因此,造成了端口F0/23的portfast特性丢失
在接口模式下配置BPDU Filtering(将对任何端口生效):
将SW2的端口F0/23和F0/24改成三层接口,禁止从端口上向SW1发送BPDU
interface range f0/23 - 24
no switchport
将SW1的端口F0/23 配置为Port Fast,F0/24为正常端口
intterface f0/23
switchport mode access
spanning-tree portfast
interface f0/24
switchport mode access
在SW1的端口F0/24开启BPDU Guard:
interface range f0/23 - 24
spanning-tree bpduguard enable
show spanning-tree interface f0/23 portfast 查看SW1的端口F0/23和F0/24 的状态
sh protocols f0/23
sh protocols f0/24 SW1上的端口F0/23为portfast状态,F0/24为正常状态,并且状态都为UP
在SW1的端口F0/23和F0/24下开启BPDU Filtering
int range f0/23 - 24
spanning-tree bpdufilter enable
在SW2的端口F0/23和F0/24向SW1发送BPDU,测试BPDU Filtering:
int range f0/23 - 24
switchport
查看SW1的端口状态:
sh spanning-tree interface f0/23 portfast
sh protocols f0/23
sh protocols f0/24
接口下开启的BPDU Filtering,过滤掉了正常端口下的BPDU,也过滤掉了portfast端口下的BPDPU
边缘端口:
配置模式(非接口之下,相当于全局):spanning-tree portfast edge default 在全局(非接口)运行边缘端口,使得所有接入接口(不含trunk口)成为边缘端口,这样可以快速的在多个接入接口实施,不同设备命令可能不同
show spanning-tree interface 接口 detail 验证全局模式的边缘端口配置结果
思科设备不仅可以在全局实施边缘端口还可以在特定接口实施(包含trunk),该场景一般包括单臂路由中交换机的trunk接口或者服务器虚拟化下的trunk接口
spanning-tree portfast edge trunk 在trunk接口开启边缘端口功能
配置BPDU保护:思科和华为不同,思科可以在全局和接口分别实施BPDU保护
思科链路聚合:
interface range 接口 进入多个接口进行配置
shutdown 建议将接口shutdown进行配置(避免出现bug)
channel-group 12 mode on(active) 配置聚合组12,模式为手工(或LACP)模式
在另外一侧配置好后进行no shutdown开启物理接口
show etherchannel summsry 验证链路聚合简要状态
链路聚合搭配trunk链路(允许同时通过多个vlan):
interface range port-channel g0/1-3 将聚合接口1-3一起做trunk链路
switchport trunk encapsulation dot1q 将链路封装为dot1q
switchport mode trunk 更改链路为trunk链路
switchport trunk native vlan 999 将本征vlan(相当于华为的pvid)改为999,防止跨vlan攻击
show interface trunk 验证trunk链路的状态以及本征vlan(相当于华为的pvid)(mode显示为on表示正常状态)
端口安全:
先配置vlan,将用户端对应的接口划分到相应的vlan
interface range 接口 批量进入多个接口
switchport port-security 开启端口安全功能,这些接口默认只能学习到一个mac地址
switchport port-security mac-address sticky 开启端口安全的粘性mac功能
验证开启端口安全后的mac地址表,显示的是STATIC,和华为不同,华为是sticky
show mac address-table static 查看安全mac地址
端口安全的违规行为和自动恢复:
可以修改终端上的mac地址,从而使交换机在一个接口上学习到两个mac地址
mac-address 1.1.1 修改终端设备mac地址
show interface 接口,接口 is down ,line protocol is down 查看交换机的日志,接口由于违规被关闭
自动恢复:配置模式:errdisable recovery cause all 开启差错的自动恢复,这里选择了使接口关闭的所有原因
errdisable recover interval 30 后续如果没有违规行为将每隔30s尝试一次,使其恢复正常
在终端设备上no mac-address,这时违规的接口恢复正常
静态路由配置:
配置模式:ip route 目的地址 掩码 出接口 下一跳 适用于多点接入网络
ip route 目的地址 掩码 出接口 适用于点到点网路(只有两台设备)(如果是有很多设备不建议使用这条命令,因为是ARP代劳)
show ip route 查看静态路由配置结果
浮动静态路由:
配置模式:ip route 目的地址 掩码 出接口 管理距离(默认1,值越小越优先,路由表中显示的是管理距离小的那个路由,当那个路由消失后此条路由才会出现在路由表中)
浮动静态默认路由:
配置模式:ip route 0.0.0.0 0.0.0.0 出接口 管理距离
配置模式:ip route 0.0.0.0 0.0.0.0 出接口 下一跳
配置模式:ip route 0.0.0.0 0.0.0.0 下一跳
ospf配置:
router ospf 1
router-id 1.1.1.1
network 12.1.1.0 0.0.0.255 area 0(或者在接口下ip ospf 1 area 0)
show ip ospf neighbor 查看ospf邻居状态
show ip ospf interface brief
ip ospf network point-to-point 修改默认的网络类型,默认类型是广播,为了加速邻居的收敛以及减少LSA,推荐使用点到点
show ip route ospf 查看ospf邻居表
clear ip ospf process 重置ospf进程(y)(重置ospf进程后,会重新选举DR/BDR)
show ip ospf interface 查看ospf接口
show ip ospf database 查看ospf的LSA数据库
acl:
配置模式下access-list 1 deny 172.16.1.0 0.0.0.255
access-list 1 permit any
interface g0/0
ip access-group 1 in(入方向)
show access-list 1 验证acl是否命中
或者第二种:
ip access-list 1 standard 数值
deny host 地址
permit any
interface g0/0
ip access-group 1 in(入方向)
acl设备本身发起的流量:(这种是不成功的,无法管控从设备本身发出来的流量)
access-list 1 deny 10.1.1.0 0.0.0.255
access-list 1 permit any
interface g0/0
ip access-group 1 out(出方向)
扩展acl:可以命名
ip access-list extended liudehao
deny icmp 10.1.10.1 0.0.0.0 10.1.1.1 0.0.0.0 拒绝从10.1.10.1到10.1.1.1的所有icmp流量
interface g0/0
ip access-group liudehao in 在0/0口应用acl,应用成功
ip access-list extended liudehao
permit any any 允许所有流量
show run interface g0/0 查看到后应用的ACL覆盖了前面应用的ACL,并且是出方向和入方向分别实施了ACL
将ACL应用于VTY接口(实现远程telnet):
配置模式:
ip access-list extended VTY 创建ACL列表,名字为VTY
permit tcp host 10.1.10.12 any eq 23 仅允许源地址为10.10.10.12的ip向目标端口23(即telnet)的流量,意味着其他流量将被拒绝
配置模式:line vty 0 4 进入vty接口
access-class VTY in 将刚刚配置的ACL应用到VTY接口下的入方向上(此时只有10.1.10.12这个ip可以telnet)
show users 在本端设备上查看,发现10.1.10.12远程到这台设备上
sh ip access-lists 查看acl记录
Log和log-input作用:
当路由器为用户转发了数据之后,如果管理员想查看路由器曾经为哪些用户转发过数据,在正常情况下,这是无法查证的。但是,可以通过接口配置ACL,并且强制ACL记录下曾经转发过的用户记录,这样,就能从路由器得知哪些用户是发起过数据的,并且发送了多少数据,但是用户发出的数据内容,是无法记录的。要达到以上目的,那在配置ACL时,使用Log和log-input的功能,并且将配置好的ACL用于接口上。
Log和log-input的区别是:Log只能记录数据包通过时的源IP和目的IP,而log-input除了记录源IP和目的IP之外,还会记录源的MAC地址。
配置log:
access-list 100 permit ip host 10.1.1.2 any log
interface 接口
ip access-group in
测试ping
sh ip access-lists 查看acl记录,可以看到拒绝和允许的流量
配置log-input:
access-list 130 permit ip an an log-input
interface 接口
ip access-group 130 in
测试ping
为acl做标记:
access-list 100 remark Deny_R2 写上拒绝R2的注释
access-list 100 permit ip host ip地址 any
注意:在ACL中是无法查看注释的,但在running-configuration中可以看出
配置NAT(PAT端口转换):
配置模式:
ip access-list standard NAT 将ACL命名为NAT
permit 10.1.10.0 0.0.0.255 命中10.1.10.0/24网络的主机可以被NAT转换
exit
interface range g0/1 - 2
ip nat inside NAT的入接口(表明NAT的流量必须从这些接口进入才可以进行转换)
interface g0/0
ip nat outside NAT的出接口
exit
ip nat inside source list NAT interface g0/0 overload 将符合ACL过滤的流量转换成g0/0接口的地址出去访问,overload表示一个地址可以被多个端口使用(相当于华为的easy-ip)
静态地址端口转换:
配置模式:
ip nat inside source static tcp 10.1.10.13 23 202.100.1.1 2323 使用静态转换,将内网设备10.1.10.13的23端口转换为公网202.100.1.1的2323端口,使得外网用户可以访问202.100.1.1的2323端口,之后转换为内网10.1.10.13的23端口
show ip translations 查看地址端口转换信息
此时另一台设备telnet 202.100.1.1 2323,就可以访问(此时不成功,因为上边做的ACL的缘故)
ip access-list extended VTY
permit tcp host 202.100.1.2 any eq telnet
此时另一台设备telnet 202.100.1.1 2323,就可以访问(此时成功)
RIP配置:
router rip
version 1(或2)
network 10.0.0.0
show ip route
debug ip rip 该命令可以查看RIP路由协议的动态更新过程
clear ip route * 清空路由表
debug ip rip 该命令可以查看RIP路由协议的动态更新过程
show ip protocols 该命令查看IP路由协议配置和统计信息
实验一:被动接口配置
被动接口配置:不需要向这些接口发送路由更新,所以可以考虑将路由器的该接口设置为被动接口;被动接口只能接收路由更新,不能以广播或组播方式发送更新,但是可以以单播的方式发送更新;拓扑图为R1连接两台pc机,另外一个口连接R2
router rip
version 1
passive-interface 接口
实验二:R1,R2,R3在同一网段,172.16.1.0/24,ip分别为1,2,3
配置单播更新的命令如下:由于RIPv1路由协议采用广播更新,默认情况下,路由更新将发送给以太网上任何一个设备,为了防止这种情况发生,把路由器R1的g0/0配置成被动接口,然而路由器R1还想把路由更新发送给R3,这时候必须采用单播更新,为指定的相邻路由器R3发送路由更新
router rip
neighbor ip地址
实验三:明文认证,MD5认证,触发更新
明文认证+触发更新:
key chain test 配置钥匙链
key 1 配置key id
key-string cisco 配置key id的密钥
interface 接口
ip rip authentication mode text 配置认证为明文认证(默认就是明文认证,也可以不用配置)
ip rip authentication key chain test 在接口上调用钥匙链
ip rip triggered 在接口上启用触发更新
show ip protocols 查看(由于是触发更新,可以看到hold down计时器为0)
debug ip rip 虽然我们打开了debug ip rip,但是由于采用触发更新,所以并没有看到每30秒更新一次的信息,而是清除了路由表这件事件触发了路由更新。而且所有的更新中都有“triggered”的字样,同时在接收的更新中带有“text authentication”的字样,证明接口s0/0/0和s0/0/1启用了触发更新和明文认证
show ip rip database 查看rip数据库
MD5认证:只需要在接口上将认证改为MD5即可
key chain test 配置钥匙链
key 1 配置key id
key-string cisco 配置key id的密钥
interface 接口
ip rip authentication mode md5 配置认证为MD5认证
ip rip authentication key chain test 在接口上调用钥匙链
ip rip triggered 在接口上启用触发更新
注意事项:
在以太网接口下,不支持触发更新;
触发更新需要协商,链路的两端都需要配置
在认证的过程中,如果定义多个key ID,明文认证和MD5认证的匹配原则是不一样的:
明文认证的匹配原则是:
A. 发送方发送最小Key ID的密钥
B. 不携带Key ID号码
C. 接收方会和所有Key Chain中的密钥匹配,如果匹配成功,则通过认证。
举例:
【实例1】
路由器R1有一个Key ID,key1=cisco;
路由器R2有两个Key ID,key1=ccie,key2=cisco
根据上面的原则,R1认证失败,R2认证成功,所以在RIP中,出现单边路由并不稀奇。
MD5认证的匹配原则是:
A. 发送方发送最小Key ID的密钥
B. 携带Key ID号码
C. 接收方首先会查找是否有相同的Key ID,如果有,只匹配一次,决定认证是否成功。如果没有该Key ID,只向下查找下一跳,匹配,认证成功;不匹配,认证失败。
【实例2】
路由器R1有三个Key ID,key1=cisco,key3=ccie,key5=cisco;
路由器R2有一个Key ID,key2=cisco
根据上面的原则,R1认证失败,R2认证成功。
EIGRP:(Enhanced Interior Gateway Routing Protocol,增强型内部网关路由协议)
EIGRP是Cisco公司开发的一个平衡混合型路由协议,它融合了距离向量和链路状态两种路由协议的优点,支持IP、IPX、ApplleTalk等多种网络层协议。由于TCP/IP是当今网络中最常用的协议
EIGRP是一个高效的路由协议,它的特点如下:
- 通过发送和接收Hello包来建立和维持邻居关系,并交换路由信息;
- 采用组播(224.0.0.10)或单播进行路由更新;
- EIGRP的管理距离为90或170;
- 采用触发更新,减少带宽占用;
- 支持可变长子网掩码 (VLSM),默认开启自动汇总功能;
- 支持IP、IPX、AppleTalk等多种网络层协议;
- 对每一种网络协议,EIGRP都维持独立的邻居表、拓扑表和路由表;
- EIGRP使用Diffusing Update算法(DUAL)来实现快速收敛.并确保没有路由环路;
- 存储整个网络拓扑结构的信息,以便快速适应网络变化;
- 支持等价和非等价的负载均衡;
- 使用可靠传输协议(RTP)保证路由信息传输的可靠性;
- 无缝连接数据链路层协议和拓扑结构,EIGRP不要求对OSI参考模型的2层协议做特别的配置
运行EIGRP的整个网络AS号码必须一致,其范围为1-65535之间
配置:
router eigrp 1
no auto-summary
network 1.1.1.0 0.0.0.255
network 192.168.12.0
show ip eigrp neighbors 查看EIGRP邻居
show ip eigrp interface
IS-IS:路由器默认都是L1-2路由器
router isis
net 49.0001.0000.0000.0000.00
interface 接口
ip router isis 接口开启isis功能
no shutdown 使接口up
show clns neighbor 显示isis邻居
show isis hostname 查看动态主机名字映射(*代表自己)
缺省情况下,Hello包每10秒中发送一次,holddown时间为30秒,即3倍的关系。可以在接口下通过“isis hello-interval” 命令修改Hello包发送的周期,同时通过“isis hello-multiplier”命令定义holddown是Hello周期的倍数
show clns interface 接口 该命令显示clns接口状态的基本信息
show clns route 该命令查看CLNS第二层路由信息
show isis topology 该命令显示IS-IS的拓扑结构信息,包含到其它中间系统的路径信息
show isis database 该命令显示IS-IS链路状态数据库
isis priority 64 修改接口优先级,默认为64
show isis route 该命令查看CLNS第一层路由信息
show ip protocols 该命令显示和IP路由协议相关的信息
DIS选举规则:
只有形成邻接关系的路由器才有资格参与选举;
接口优先级最高成为DIS;
如果接口优先级相同,则最高的SNPA地址成为DIS;
DIS选举是抢占的。
bgp配置:
router bgp 1 配置bgp的进程号
bgp router-id 1.1.1.1 配置bgp的router-id
neighbor 2.2.2.2 remote-as 1 指定bgp对等体为2.2.2.2,AS号为1
show ip bgp summary 查看bgp邻居
修改源地址:如果上面源地址为10.1.1.1(源10.1.1.1与对端2.2.2.2建立邻居关系),就建立不了bgp邻居关系,需要将10.1.1.1改为1.1.1.1(loopback0)才可以
router bgp 1
neighbor 2.2.2.2 update-source loopback 0(1.1.1.1)
修改TTL值:如果邻居之间为ebgp邻居关系,由于默认的TTL值为1,此时会导致一些bgp无法建立邻居关系,默认值改为255
router bgp 1
neighbor 2.2.2.2 ebgp-multihop
bgp路由表(bgp路由引入,network方式)
show ip bgp 查看bgp路由表(默认没有表项)
router bgp 1
network ip地址 mask 子网掩码 该ip地址必须在igp路由中是存在的,也就是说show ip route必须可以看到,且子网掩码匹配才能导入
路由重发布方式:
route-map loop permit 10
match interface loopback 22
router bgp 1
redistribute connected route-map loop
关闭ibgp与igp之间的同步
router bgp 1
no synchronization
将下一跳改为自己
router bgp 1
neighbor 1.1.1.1 next-hop-self
路由汇总:创建路由汇总100.1.0.0/22
首先先将路由通告到bgp中
router bgp 1
aggregate-address 100.1.0.0 255.255.252.0 as-set as-set可以保留as-past属性
show ip bgp 100.1.0.0 查看到并没有路径丢失
show ip bgp 可以查看到bgp路由,用于发现路径是否丢失
抑制不需要通告的明细路由:将100.1.1.0/24放入route-map,在suppress-map中的route-map所包含的路由便会被抑制而不会通告给邻居
access-list 1 permit 100.1.1.0
route-map sup permit 10
match ip address 1
router bgp 1
aggregate-address 100.1.0.0 255.255.252.0 as-set suppress-map sup
show ip bgp 可以查看到明细路由100.1.1.0被抑制了,如果是在邻居上查看路由前面的标识s表示该路由在汇总时被抑制而不发给邻居
不抑制明细路由:在使用了抑制路由之后,如果希望某些路由还是发给某邻居而不抑制,那么可以使用不抑制的映射列表unsuppress-map,在该列表后面包含的路由都将被发给邻居
access-list 3 permit 100.1.3.0
route-map unsup permit 10
match ip address 3
router bgp 4
neighbor 5.5.5.5 unsuppress-map unsup
重分布汇总路由:手工创建静态路由方式的汇总路由,并指向null 0以防止路由黑洞。手工创建的默认路由是不能被重分布进BGP的
ip route 100.1.0.0 255.255.252.0 null 0
router bgp 1
redistribute static
配置BGP默认路由:没有指定邻居,则向所有邻居通告默认路由
router bgp 1
default-information originate
只对单个邻居发送默认路由:
router bgp 1
neighbor 2.2.2.2 default-originate
路由过滤配置:
配置使用As-path filter路由过滤
ip as-path access-list 1 permit ^2$ 只收起源于AS 2的路由,过滤其它所有路由
router bgp 1
neighbor 2.2.2.2 filter-list 1 in 在入方向应用As-path filter
show ip bgp 查看过滤后的结果,除了自己本地路由之外,没有收到任何路由,因为^2$不与任何路由匹配,并不表示为起源于AS 2的路由
改写起源于AS 2的路由
ip as-path access-list 2 permit _2$
router bgp 1
neighbor 2.2.2.2 filter-list 2 in 起源于AS 2的路由格式应该为_2$,因为AS的方向问题,并且符合_可以表示逗号的意思
show ip bgp 查看过滤后的结果,使用As-path filter过滤路由成功,只有起源于AS 2的路由
配置distribute-list路由过滤:该方式配置全局过滤路由,只接收100.1.2.0的路由
配置全局过滤路由
access-list 2 permit 100.1.2.0
router bgp 1
distribute-list 2 in
show ip bgp 除了本地路由外,只接收到100.1.2.0的路由,说明路由过滤成功
针对单个邻居过滤路由:配置过滤路由只针对某个邻居R2生效
router bgp 1
no distribute-list 2 in
neighbor 2.2.2.2 distribute-list 2 in
show ip bgp 只从R6收到100.1.2.0的路由,说明针对单个邻居过滤路由生效
配置bgp peer group:
peer group里所有的邻居必须为ibgp或者ebgp,不能一个peer group里面同时有ibgp和ebgp邻居
使用Peer Group配置同AS内的iBGP邻居
router bgp 1
bgp router-id 1.1.1.1
neighbor as1 peer-group 创建Peer Group为as1
neighbor as1 remote-as 1 配置as1中的邻居为as 1
neighbor as1 update-source loopback 0 更新时使用地址为Loopback0的地址
neighbor 2.2.2.2 peer-group as1 将邻居2.2.2.2放入Peer Group(as1)中
neighbor 3.3.3.3 peer-group as1 将邻居3.3.3.3放入Peer Group(as1)中
将Peer Group “as1”的weight值改为111,将对Peer Group中所有邻居生效:
router bgp 1
neighbor as1 weight 111
show ip bgp 查看修改结果
使用Peer Group配置不同AS内的eBGP邻居
router bgp 1
neighbor as45 peer-group 创建Peer Group为as45
neighbor as45 update-source loopback 0 配置as45更新时使用地址为Loopback0的地址
neighbor as45 ebgp-multihop 指定TTL为255,但并没有指定as45中的邻居AS,因为并不是所有eBGP邻居都在同一AS,所以需要单独为各个邻居指定AS之后,才将邻居放入Peer Group(as1)中,也可以看见,在指定邻居为其它AS之后,就不可能再放入本AS的Peer Group中,否则有如上报错信息
neighbor 4.4.4.4 remote-as 4
neighbor 4.4.4.4 peer-group as1
% Peer with AS 4 cannot be in this peer-group, members must be all internal or all external (报错提示)
neighbor 4.4.4.4 peer-group as45
neighbor 5.5.5.5 remote-as 5
neighbor 5.5.5.5 peer-group as1
% Peer with AS 5 cannot be in this peer-group, members must be all internal or all external (报错提示)
neighbor 5.5.5.5 peer-group as45
修改单个邻居参数的配置:
router bgp 1
neighbor 5.5.5.5 weight 5 将Peer Group “as45”的中邻居5.5.5.5的weight值改为5,此改动只对Peer Group中的单个邻居生效,而不会影响其它邻居
show ip bgp 查看修改结果,对Peer Group中单个邻居修改的参数,只对Peer Group中单个邻居生效,而不影响其它邻居
路由反射器:
router bgp 1
neighbor 3.3.3.3 route-reflector-client 在R2上配置,表示R2为反射器,R3(3.3.3.3)为路由反射器的客户端,
BGP后门路由:相当于路由引入
R1,R2,R3环形连接,R3连接33.0.0.0网段,R1所在AS为AS1,R2和R3所在AS为AS2,底层为ospf网络,R1访问33.0.0.0有两条路径R1-R2-R3或R1-R3,R1和R2,R2和R1、R3建立BGP邻居,R3和R1之间建立EIGRP,R3除了将33.0.0.0通告在EIGRP,还通告在了BGP,由于EBGP的AD为20,EIGRP为90,这样的话R1将去往33.0.0.0的路由通过R2在传给R3,不符合要求,调整EBGP的AD值来解决该问题
基于上述问题,eBGP有种特殊的路由处理方式,就是将某些路由在BGP进程中通过命令network导入BGP路由表,将其变成本地路由,从而将AD值改为200,大于任何IGP协议的AD值,但是该路由只对自己本地生效,只影响自己的选路,并不会传递给其它BGP邻居。这样的路由处理被称为BGP backdoor(BGP 后门路由)。可以看出,BGP后门路由的使用可以使BGP中的某些路由不通过BGP传递,而优先使用其它后门链路,可以实现对特定流量的路径调整
配置:
EIGRP配置:
配置R1与R3之间的EIGRP
R1:
router eigrp 100
no auto-summary
network 13.1.1.1 0.0.0.0
R3:
router eigrp 100
no auto-summary
network 13.1.1.3 0.0.0.0 13.1.1.0为R1和R3之间相连的网段
network 33.3.3.3 0.0.0.0 R1与R3之间建立EIGRP,R3将33.0.0.0通告进EIGRP
show ip eigrp topology 查看R1从EIGRP收到的路由,R1从与R3的直连链路收到33.0.0.0
配置BGP后门路由:
R1通过BGP后门路由将33.0.0.0变为本地路由:
router bgp 1
network 33.3.3.0 backdoor
sh ip bgp 查看R1的BGP路由表,33.0.0.0前面标记为r,说明该路由在BGP中为RIB-failure,所以不会被使用
sh ip route 查看R1的IGP路由表,R1去往33.0.0.0的最终路径是直接从R3走,符合需求
traceroute 33.3.3.3 跟踪R1去往33.0.0.0的路径
BGP Dampening:
对于衡量什么样的路由算是不稳定的路由,什么样的路由才能传递给邻居,BGP有一套自己的机制,称为BGP Dampening
对于路由每次翻动,BGP都会给该路由加上一个惩罚值,并且如果翻动多次,惩罚值都会全部累加,当惩罚值累加到一定程度,也就是累加到最大抑制值,那么该路由就被认为是不稳定的,也就不再发给邻居,但是路由的惩罚值会随着时间而减少,当减到释放值时,该路由又可以重新发给邻居。惩罚值的减少,是和某个时间有关系的,这个时间称为半衰期,每过一个半衰期的时间,惩罚值就减少到原来的一半。虽然路由每翻动一次,都会累加惩罚值,但惩罚值并不是无限累加的,是有一定限制的,这就是最大抑制值,无论路由翻动多少次,累加的惩罚值都不会超过最大抑制值
Penalty(惩罚值):路由每翻动一次加1000。
Suppress limit(抑制值):默认为2000,当某条路由的惩罚值累加到2000时,便会被抑制而不发给邻居。
Half-life (半衰期) :默认为15分钟,每经过一个半衰期时间,惩罚值减到原来的一半。(每5秒会计算一次)
Resume limit (释放值) :默认为750,当某条被抑制的路由的惩罚值减到释放值时,就可以再次发给邻居。(每10秒查看一次)
Maximum suppress limit(最大抑制值):默认为过4个半衰期时间可以减到释放值,即60分钟,按释放值750计算,那么4个半衰期减到750,原来的值就是12000
注:
★并不是所有的路由都能配置BGP Dampening,只有从eBGP收到的路由才能配置BGP Dampening,从iBGP收到的路由是不可以的。
★BGP Dampening可以针对所有BGP路由配置,也可以针对特定路由配置,但不可以针对特定邻居配置。
★BGP Dampening所有值都可自定义,但有范围限制。
配置:
R1和R2相连,属于不同的AS,R2后边有两个网络,R1和R2建立BGP邻居关系,R2将身后的两个网络通过network 20.1.1.0 mask 255.255.255.0也通告进BGP中,R1就会收到R2通告的两个网段
针对所有路由配置BGP Dampening:在R1上对所有路由配置BGP Dampening
router bgp 1
bgp dampening
sh ip bgp dampening parameters 查看BGP Dampening参数,以上值为BGP Dampening默认值
sh ip bgp dampening dampened-paths 查看被BGP Dampening监控的路由,因为没有路由发生翻动,所以路由为空
测试 bgp dampening:将10.1.1.0/24的接口断开,表示翻动一次。
int loopback 10
shutdown
sh ip bgp 10.1.1.0 R1上查看10.1.1.0/24,可以看到,由于10.1.1.0/24发生了一次翻动,所以有了penalty值,为980
sh ip bgp 10.1.1.0 R1上再次查看10.1.1.0/24,10.1.1.0/24翻动了两次,现在penalty值为1903,但还是低于抑制值2000
sh ip bgp 10.1.1.0 R1上再次查看10.1.1.0/24,翻动3次后,penalty值为2780,大于抑制值2000,可以被抑制了
sh ip bgp dampening dampened-paths 查看被抑制的路由,可以看到10.1.1.0/24是被抑制的路由,需要注意,只有该路由重新活动后,才能看见被抑制,否则断开的路由也是不会显示在抑制表中的
sh ip bgp 查看R1的BGP路由表,BGP路由表中也显示了10.1.1.0/24是被抑制的
针对特定路由配置BGP Dampening:在R1上只针对20.1.1.0配置BGP Dampening,只对20.1.1.0/24配置BGP Dampening,并且自定义Dampening值
access-list 20 permit 20.1.1.0
route-map damp permit 10
match ip address 20
set dampening 15 800 2100 60
exit
route-map damp permit 20
router bgp 1
bgp dampening route-map damp
sh ip bgp dampening parameters 查看BGP Dampening参数,以上值为自定义的值
sh ip bgp 20.1.1.0 查看20.1.1.0/24的情况,由于20.1.1.0/24翻动了一次,当前penalty值为1000
sh ip bgp 20.1.1.0 再次查看20.1.1.0/24的情况,由于20.1.1.0/24翻动3次后,penalty值为2886,大于抑制值2000,可以被抑制了
sh ip bgp dampening dampened-paths 查看被抑制的路由,20.1.1.0/24已经被抑制
sh ip bgp 查看R1的BGP路由表情况,20.1.1.0已经被抑制
BGP重分布进IGP:
因为BGP通常拥有庞大的路由表,所以在将BGP路由表重分布进IGP时,很有可能导致IGP协议停止工作或路由器崩溃,所以为了预防此类事件的发生,慢慢的,IOS默认不允许将BGP重分布进IGP,但是并非所有BGP都不能重分布进IGP,为了放宽限制,默认情况下,只可以将从eBGP邻居学习到的路由和本地路由重分布进IGP,也就是说iBGP路由是不能重分布进IGP的,但是可以手工调整允许将iBGP学习到的路由重分布进IGP。
ICMP重定向:
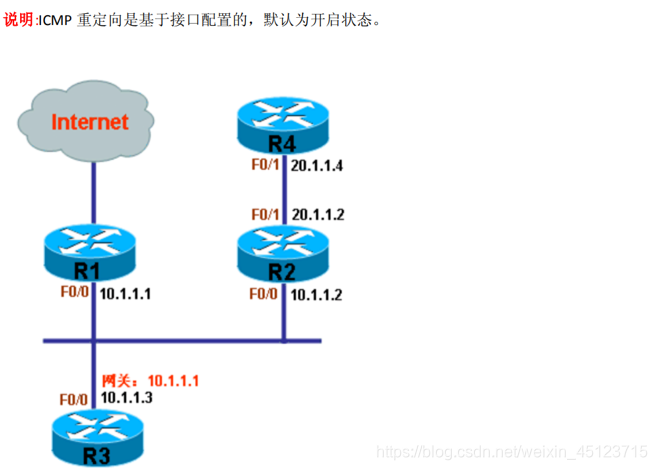
以上图为例,测试ICMP重定向,其中,R1,R2,R3的接口F0/0在10.1.1.0/24网段,R2和R4的接口F0/1在20.1.1.0/24网段,而R3将去往任何目的的数据全部交给R1
配置:
R1:ip route 0.0.0.0 0.0.0.0 10.1.1.2 R1将去往任何目的地的数据包全部交给10.1.1.2,即交给R2
R3:ip route 0.0.0.0 0.0.0.0 10.1.1.1 R3将去往任何目的地的数据包全部交给10.1.1.1,即选择R1作为网关
R4:ip route 0.0.0.0 0.0.0.0 20.1.1.2 R4在20.1.1.0/24,将下一跳指向R2
测试ICMP重定向:
在R3上向目标网络20.1.1.0发送数据包来测试ICMP重定向,并且打开debug观察数据包:
debug ip icmp
R3:ping 20.1.1.4 从上面信息可以看出,由于R3的网关是10.1.1.1,所以会将去往20.1.1.0/24的数据包发给网关R1,但是R1从接口F0/0收到数据包后,检查路由表得知需要再将数据包从相同接口F0/0发给10.1.1.2,不仅满足发送ICMP重定向情况的第一条同接口进出,也满足第二条源和下一跳同网段,所以R1向源发送了ICMP重定向,数据包中明确告诉R3将去往20.1.1.4的数据包直接交给10.1.1.2,即交给R2。从上也可以看出,让R1来转发数据包确实是无谓举动
更改R3的路由方式:
ip route 0.0.0.0 0.0.0.0 f0/0 如果将R3的路由改为直接指定出接口,而不使用下一跳IP地址,则不会造成R1发送ICMP重定向,因为R3在此类路由方式下,并不会将数据包发向R1
debug ip icmp 测试R3更改路由方式后的情况
ping 20.1.1.4 可以看出,R1并没有再发送ICMP重定向,因为R3并没有将去往20.1.1.0/24的数据包发向R1,具体原因,由普通ARP的原理可以得知
关闭ICMP重定向:
int f0/0
no ip redirects 在R1接口上关闭ICMP重定向
ip redirects 开启ICMP重定向,ICMP重定向功能不建议关闭。注:在接口上开启HSRP后,默认会关闭ICMP重定向的功能,在IOS 12.1(3)T和以后的版本可以手工开启ICMP重定向功能
代理ARP:
代理ARP在路由器接口上默认是开启的,并且是基于接口打开或关闭的
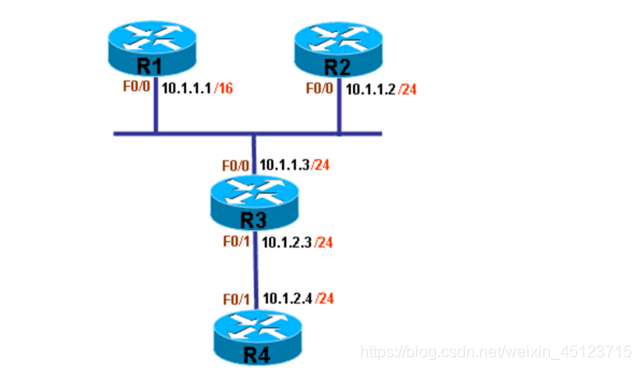
以上图为例,测试代理ARP,其中R3和R4的接口F0/1在10.1.2.0/24网段,而R1,R2和R3的接口F0/0在10.1.1.0/24网段,但由于R1的接口F0/0的掩码为16位,所以R1会认为整个10.1.0.0/16都是接口F0/0的直连网段,其中包含10.1.2.0/24;但是R2的接口F0/0的掩码为24位,所以R2会认为10.1.2.0/24是在远程网络
R2:ip route 10.1.2.0 255.255.255.0 f0/0 R2直连网段10.1.1.0/24,并且通过配置静态路由将去往远程网段10.1.2.0/24定义为直连网段
R4:ip route 0.0.0.0 0.0.0.0 10.1.2.3
R1:sh ip route 查看R1的路由情况,可以看见,R1与10.1.0.0/16直连,R1会认为10.1.2.0/24也是自己的直连网段,所以我们不用写到10.1.2.0/24的静态路由
ping 10.1.2.4 测试R1到10.1.2.0/24的连通性,因为R1认为自己直连10.1.0.0/16网段,所以在向10.1.2.0/24发送数据包时,直接在本网段广播请求目标二层链路地址,这个广播被R3收到,又因为R3能够到达10.1.2.0/24,并且开启代理ARP功能,所以R3将自己接口的二层链路地址回复给R1,最终R1将去往10.1.2.0/24的数据包封装为R3的二层链路地址,从而将数据包交给R3处理,最后网络通信成功
R4:sh interfaces f0/1
R3:sh int f0/0
R1:sh arp 查看R4(10.1.2.4)的F0/1的MAC地址与R3(10.1.1.3)的F0/0的MAC地址,并且查看R1去往10.1.2.4的ARP表
从结果中可以看出,R1获得的10.1.2.4的MAC地址并非目标R4的MAC地址,而是R3的接口F0/0的MAC地址,这就是由于R3的代理ARP功能,使得R3会代替目标R4回复源主机的二层链路地址请求
sh ip route
ping 10.1.2.4 查看R2的路由表并测试到10.1.2.0/24的连通性,因为R2路由表中的静态路由指示去往10.1.2.0/24为直连网段,所以同上原因,因为R3代理ARP的功能,最后与10.1.2.0/24的网络通信正常
测试关闭代理ARP的情况:
int f0/0
no ip proxy-arp 关闭R3接口F0/0的代理ARP功能,关闭了R3接口F0/0的代理ARP功能,要开启,输入命令ip proxy-arp。
ping 10.1.2.4
sh arp 查看R1与10.1.2.0/24的连通性和ARP情况,可以看见,当R3关闭了代理ARP功能后,R1不能与10.1.2.0/24通信,因为R1认为目标与自己直连,所以会在直连网段直接请求目标的二层链路地址,但R3关闭了代理ARP功能,即使自己与目标可达,但也不会使用自己的MAC地址去回复R1,最后R1也无法获得任何目标的MAC地址,ARP表中显示10.1.2.4的记录为Incomplete,最终与10.1.2.0/24的通信以失败告结
ping 10.1.2.4
sh arp 查看R2与10.1.2.0/24的连通性,虽然R2拥有到10.1.2.0/24的静态路由,但因为静态路由指定去往目标为直连接口,所以R2会认为10.1.2.0/24与接口F0/0直连,由于R3关闭了代理ARP,R2与R1一样,不能与10.1.2.0/24通信
no ip route 10.1.2.0 255.255.255.0 f0/0
ip route 10.1.2.0 255.255.255.0 10.1.1.3
sh ip route 更改R2的静态路由方式,并查看路由表
R2将去往目标10.1.2.0/24的静态路由改为下一跳指向10.1.1.3(R3),所以R2并不会再认为10.1.2.0/24是自己的直连网段,因此在需要与10.1.2.0/24通信时,会请求下一跳地址10.1.1.3的二层链路地址,最终将数据包交给10.1.1.3(R3)处理
ping 10.1.2.4 查看更改静态路由后R2与10.1.2.0/24的通信情况,更改静态路由到达目标网络为下一跳地址后,R2不再直接请求目标10.1.2.4的二层链路地址,而是改为请求下一跳地址的二层链路地址,因为请求的地址10.1.1.3,所以R3作出了回应,最后R2与目标通信成功
由以上情况可以看出,当配置静态路由时,如果指定远程目标为直连,则可能因为下一跳路由器关闭了代理ARP而造成通信失败,但静态路由指定为下一跳地址时,通信不会受到任何影响
代理ARP在没有配置默认网关或不使用路由的网络中,比较有优势
默认路由产生的三种方法:
IP Default-Gateway
IP Default-Network
IP route 0.0.0.0 0.0.0.0
IP Default-Gateway:通过在路由器上配置命令IP Default-Gateway加上IP地址,可以手工为路由器指定一个默认网关,该默认网关的作用与PC完全相同。而命令IP Default-Gateway只有在路由器关闭路由功能后(命令no ip routing),才能使用,如果路由器处于boot模式时,同样也可以通过该命令配置默认网关,这样便可以帮助像TFTP这样的传输
配置:
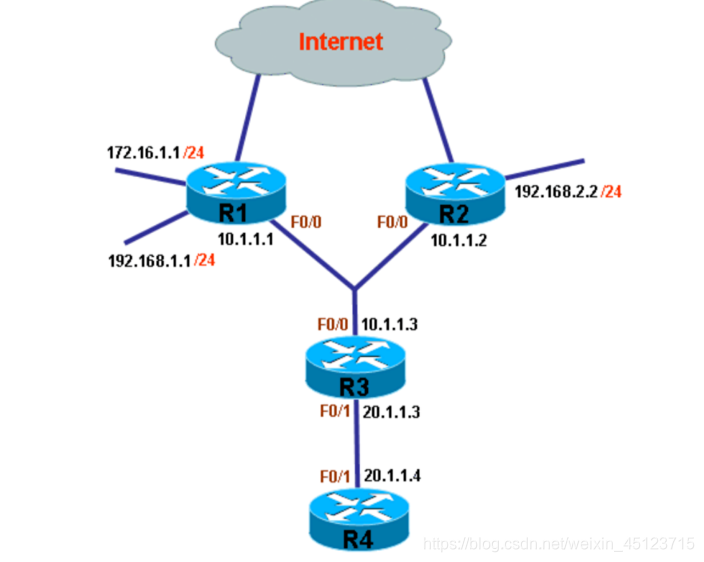
在R3上配置IP Default-Gateway
no ip routing
ip default-gateway 10.1.1.1 在R3上关闭路由功能,并指定默认网关为10.1.1.1(R1)
sh ip route 在R3上查看默认网关,R3上路由功能已关闭,并且所有数据包全部交给网关10.1.1.1
此时R3可以ping通172.16.1.1和192.168.1.1
IP route 0.0.0.0 0.0.0.0:为路由器配置默认网关时,IP Default-Gateway只能在关闭路由功能后起作用,在路由功能开启的情况下,通过命令IP route 0.0.0.0 0.0.0.0同样可以为路由器配置默认网关。
两者的区别在于,IP Default-Gateway只能在路由功能关闭时工作,并且一台路由器只能配置一条,而IP route 0.0.0.0 0.0.0.0可以在路由功能开启时工作,一条路由器可以配置多条IP route 0.0.0.0 0.0.0.0
IP Default-Network:
为路由器配置默认网关的方法除了IP Default-Gateway 与IP route 0.0.0.0 0.0.0.0之外,还有IP Default-Network,不同之处在于,IP Default-Gateway只能工作在非路由模式下,而IP route 0.0.0.0 0.0.0.0可以工作在路由模式下,但不会自动被动态路由协议传递给邻居。如果使用IP Default-Network,则被IP Default-Network所定义的网络将成为路由器的默认网关,所有未知目标的数据包全部发往该网络,IP Default-Network的不同之处是它所定义的默认网关,会自动被动态路由协议传递,能够自动传递IP Default-Network默认网关的路由协议有RIP,IGRP,EIGRP,而OSPF和IS-IS不会传递。
IP Default-Network是Classful的,所指定的网段必须是没有划过子网的主类网络,否则不会产生默认网关。如果需要IGRP和EIGRP自动传递IP Default-Network的默认网关,那么IP Default-Network所指定的网络必须在EIGRP进程里通告,或者将该网络重分布进EIGRP;对于RIP,不需要在进程下通告便会自动传递,但由于IOS的不同,RIP的操作可能存在着不同,某些IOS只能在IP Default-Network所指定的网络为直连网络时,才会被RIP传递,否则无效,所以请以自身IOS为准,因为思科并没有文档指出IOS版本号。
注:RIP version 1与version 2都支持对IP Default-Network默认网关的自动传递。
配置:
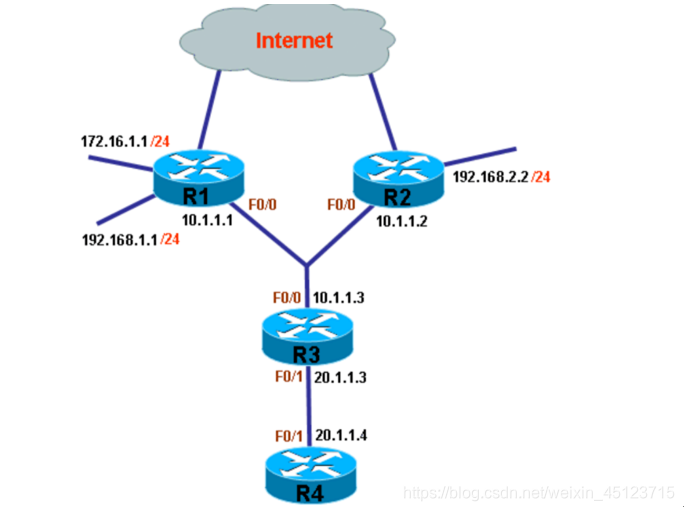
在R3上配置IP Default-Network:
在R3上手工配置到192.168.1.0/24的静态路由:ip route 192.168.1.0 255.255.255.0 10.1.1.1配置该静态路由,目的在于让192.168.1.0/24事先存在于路由表中
sh ip route
ping 192.168.1.1
ping 172.16.1.1 查看R3的路由表,并测试到远程网络192.168.1.0/24与172.16.1.0/24的连通性,因为路由表中只有去往192.168.1.0/24的静态路由,所以R3与192.168.1.0/24的通信正常,而与172.16.1.0/24不能通信
ip default-network 192.168.1.0 在R3上配置ip default-network,配置默认网关的网段为192.168.1.0
sh ip route 查看R3的路由表情况并再次测试连通性
测试:
ping 192.168.1.1
ping 172.16.1.1
可以看见,R3当前的路由表中,存在一条指向192.168.1.0的默认网关,所以会将所有未知目标的数据包发往192.168.1.0,最终R3能够与192.168.1.0/24和172.16.1.0/24通信
.测试ip default-network与RIP的关联说明:
在R3与R4之间配置RIP:
R3:
router rip
network 20.0.0.0
R4:
router rip
network 20.0.0.0
在R3上指定10.0.0.0为默认网关,并查看路由表情况:
ip default-network 10.0.0.0
sh ip route
因为路由表中10.1.1.0/24是10.0.0.0/8的子网,所以并没成为自己的默认网关,但这并不影响协议的自动传递。需要注意,如果不是直连网段,可能无法传递。
sh ip route 查看R4的路由表情况, R4已经成功从RIP中收到默认网关,并且指向R3的方向
测试ip default-network与EIGRP的关联:
在R3与R4之间配置EIGRP:
R3:
router eigrp 1
no auto-summary
network 20.1.1.3 0.0.0.0
R4:
router eigrp 1
no auto-summary
network 20.1.1.4 0.0.0.0
在R3上指定192.168.1.0为默认网关:
ip route 192.168.1.0 255.255.255.0 10.1.1.1
ip default-network 192.168.1.0
sh ip route 查看R3的路由表情况,R3已经成功将192.168.1.0定为默认网关
sh ip route 。 查看R4的路由表情况,因为ip default-network 指定的网段192.168.1.0并没有在EIGRP进程中,所以默认网关无法被传递
R3将默认网关的网段192.168.1.0引入EIGRP:
将一条路由导入EIGRP,可以原本就是EIGRP进程的,或者重分布,或者通过命令network,但network的网段必须为直连
router eigrp 1
redistribute static metric 10000 100 255 1 1500
sh ip route 再次查看R4的路由表情况,R4已经成功收到指向192.168.1.0的默认网关
测试ip default-network同时在RIP与EIGRP的关联:
在R3与R1之间配置RIP,R3与R2之间配置EIGRP:
R1:
router rip
network 192.168.1.0
network 10.0.0.0
R2:
router eigrp 1
no auto-summary
network 192.168.2.2 0.0.0.0
network 10.0.0.0
R3:
router rip
network 10.0.0.0
exit
router eigrp 1
network 10.0.0.0
R1通过RIP向R3通告192.168.1.0/24,R2通过EIGRP向R3通告192.168.2.0/24
ip default-network 192.168.1.0
exit
sh ip route 在R3上将192.168.1.0配置为默认网关,并查看路由表,192.168.1.0/24已经成功成为默认网关
ip default-network 192.168.2.0
exit
sh ip route 增加192.168.2.0/24为默认网关,并查看路由表,因为当路由器上配置多条ip default-network后,拥有最低AD值的被使用,由于EIGRP通告的192.168.2.0/24的AD值为90,而RIP通告的192.168.1.0/24的AD值为120,所以192.168.2.0被优先使用,而忽略了路由条目在路由表中的上下排列顺序
测试ip default-network与ip route 0.0.0.0 0.0.0.0共存
测试ip default-network与ip route 0.0.0.0 0.0.0.0共同存在于路由表时,路由器对默认网关的选择
ip route 0.0.0.0 0.0.0.0 20.1.1.4
exit
sh ip route 在R3使用命令ip route 0.0.0.0 0.0.0.0配置指向R4的默认网关,并查看路由表,R3当前的默认网关为20.1.1.4,即R4
ip default-network 172.16.0.0
exit
sh ip route 在R3上配置静态路由到172.16.0.0/16,并使用命令ip default-network指定为默认网关,并查看路由表
因为ip default-network 后面的网段172.16.0.0是通过静态路由指定的,所以优先于ip route 0.0.0.0 0.0.0.0,最终172.16.0.0成为了默认网关,需要注意,只有当ip default-network 后面的网段是通过静态路由指定时,才优先于ip route 0.0.0.0 0.0.0.0被使用。
no ip default-network 172.16.0.0
ip default-network 192.168.1.0
sh ip route 在R3上将ip default-network的网段改为通过RIP学习到的192.168.1.0指定为默认网关,并查看路由表
因为只有当ip default-network 后面的网段是通过静态路由指定时,才优先于ip route 0.0.0.0 0.0.0.0被使用,而192.168.1.0/24是通过RIP学习到的,所以此时ip route 0.0.0.0 0.0.0.0优先
实验(思科是sla,华为是nqa)
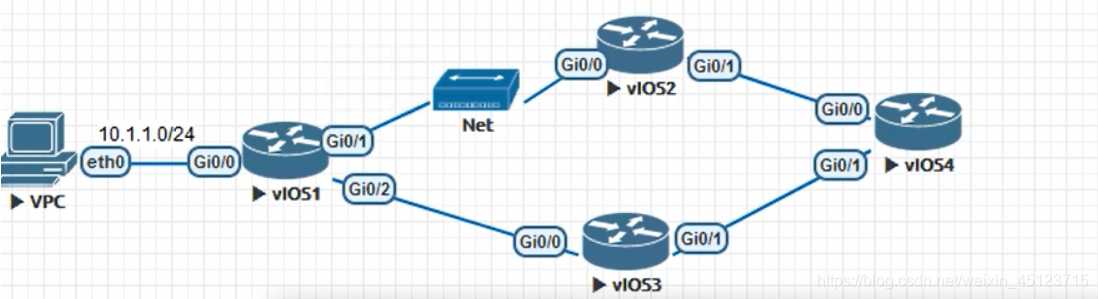
1.各个接口配置ip
interface g0/0
IP address IP地址
2.配置ospf:配置模式下:
router ospf 1
router-id 1.1.1.1
network 12.1.1.0 0.0.0.255 area 0
show ip ospf neighbor 查看ospf邻居状态
show ip route 查看路由表
3.
ar1:配置模式:ip sla 10(10代表编号,自定义)
icmp-echo 12.1.1.2(ar2的g0/0接口) 发送icmp包向ar2用于链路检测
frequency 10
timeout 5000
配置模式下ip sla schedule 10 start-time now sla启动生效
配置模式下ip sla 20
icmp-echo 13.1.1.2(ar3的g0/0接口)
frequency 10
timeout 5000
配置模式下ip sla schedule 20 start-time now 调用 sla 10并且现在启动生效
show ip sla summary 显示ip sla摘要(显示需要检测的对端的ip地址)
配置模式下:track 1 IP sla 10 reachability
配置模式下:track 2 IP sla 20 reachability
ip route 61.1.1.0 255.255.255.0 12.1.1.2 track 1
ip route 221.1.1.0 255.255.255.0 13.1.1.2 track 2
ip route 0.0.0.0 0.0.0.0 12.1.1.2 track 1
ip route 0.0.0.0 0.0.0.0 13.1.1.2 2 track 2
协议优先级(华为)=管理距离(思科)
show ip route static 查看静态路由
nat
配置模式下access-list 1 permit 10.1.1.0 0.0.0.255 配置一个访问列表1
access-list 2 permit 10.1.1.0 0.0.0.255
ip nat inside source list 1 interface g0/1 overload 做nat转换,转换前为内部的源地址,转换后为g0/1的地址
ip nat inside source list 2 interface g0/2 overload 做nat转换,转换前为内部的源地址,转换后为g0/2的地址
配置模式下:interface g0/0
ip nat inside 将g0/0定义为内部地址
interface g0/1
ip nat outside 将g0/1定义为外部地址
interface g0/2
ip nat outside 将g0/2定义为外部地址
特权模式下show ip nat translations 当有流量经过时查看nat转换地址信息
pc:ip 10.1.1.10 255.255.255.0 10.1.1.1 配置ip地址,子网掩码,网关
no ip nat inside source list 1 interface g0/1 overload
no ip nat inside source list 2 interface g0/2 overload
no access-list 2
配置模式下route-map ctc permit 10 路由策略调用sla 10
match ip address 1 匹配访问列表1
match interface g0/1 匹配接口g0/1
配置模式下
route-map cnc permit 10 路由策略调用sla 10
match ip address 1 匹配访问列表1
match interface g0/2 匹配接口g0/2
ip nat inside source route-map ctc interface g0/1 overload
ip nat inside source route-map cnc interface g0/2 overload


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









