







python正则表达式
一、正则表达式所面向的问题

二、实际应用


三、全面了解







四、实践示例
# 元字符: . * ? + [] () \ ^ $
# 1.普通字符
import re
# re.findall():将符合规则的字符串,以列表的形式,全部返回。
s1 = "testing"
s2 = "Testing"
r1 = re.findall("test", s1)
print(r1) # ['test']
r2 = re.findall("test", s2)
print(r2) # []
r3 = re.findall("test", s2, re.I) # 修饰符re.I:是匹配对大小写不敏感
print(r3) # ['Test']
print("普通字符完毕!")
print("="*60)
# 2.通配符.:匹配除换行符"\n"以外的单个字符
s1 = "testing"
s2 = "testing\n"
r1 = re.findall(".", s1)
print(r1) # ['t', 'e', 's', 't', 'i', 'n', 'g']
r2 = re.findall(".", s2)
print(r2) # ['t', 'e', 's', 't', 'i', 'n', 'g']
r3 = re.findall(".", s2, re.S) # 修饰符re.S:使.匹配包括换行符在内的单个字符
print(r3) # ['t', 'e', 's', 't', 'i', 'n', 'g', '\n']
print("2:通配符完毕!")
print("="*60)
# 3.^脱字符:匹配输入字符串的开始位置(锁定行首)
s = 'testing\nTesting\ntest'
r1 = re.findall("^test", s)
# 匹配所有(单行)以test开头的字符串
print(r1) # ['test']
r2 = re.findall("^test", s, re.M) # 修饰符re.M:多行匹配
print(r2) # ['test', 'test']
r3 = re.findall("^test", s, re.M | re.I) # 多个修饰符通过OR(|)来指定
print(r3) # ['test', 'Test', 'test']
print("3:脱字符完毕!")
print("="*60)
# 4.$匹配输入字符串的结束位置(锁定行尾)
s = 'testing\nTesting\ntest'
r1 = re.findall("testing$", s) # 匹配所有以testing结尾的字符串(从尾行开始匹配)
print(r1) # []
r2 = re.findall("testing$", s, re.M)
print(r2) # ['testing']
r3 = re.findall("testing$", s, re.M | re.I)
print(r3) # ['testing', 'Testing']
print("4:美元符完毕!")
print("="*60)
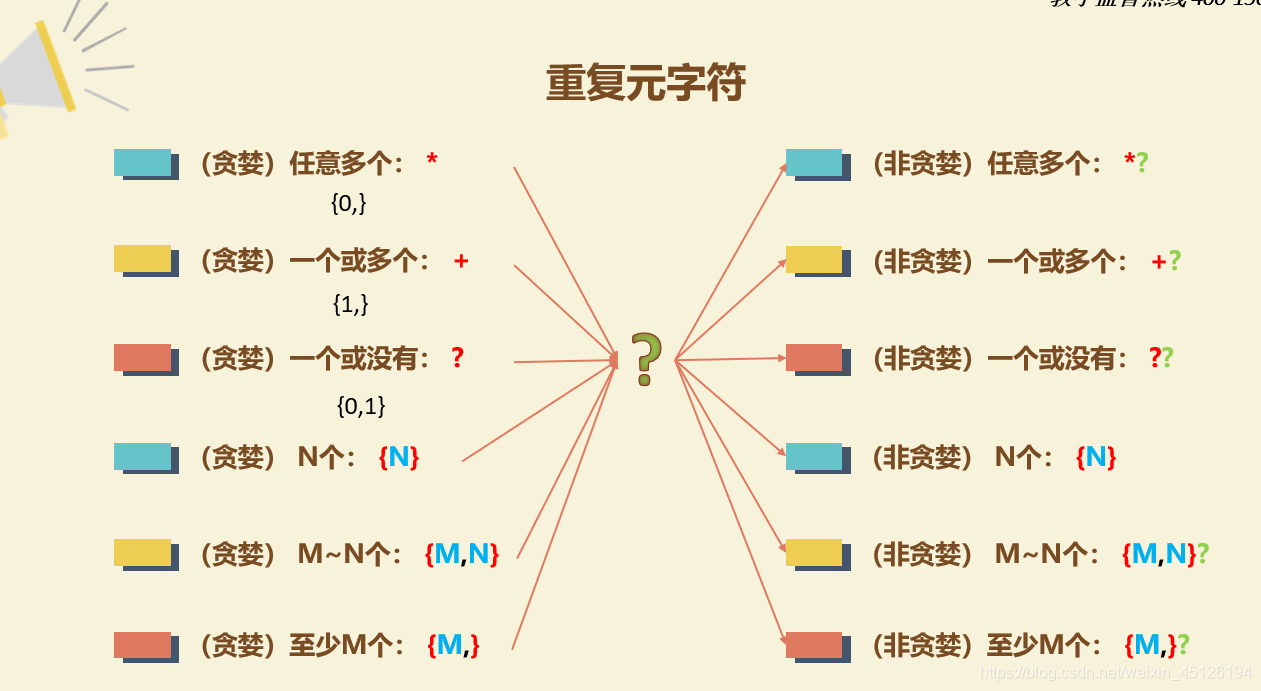
# 5. * + ? 匹配前面的子表示式的次数(*(0-无穷)任意次,+(1-无穷)大于等于1,?(0|1)零次或一次)
s = 'z\nzo\nzoo\nzooo'
r1 = re.findall("zo*", s, re.M)
# 表示"o"可以匹配任意次,若"o"没有(未匹配到),则只返回"z",若"o"有,则有多少个就匹配多少个,并返回
print(r1) # ['z', 'zo', 'zoo', 'zooo']
r2 = re.findall("zo+", s, re.M)
print(r2) # ['zo', 'zoo', 'zooo']
r3 = re.findall("zo?", s, re.M) # zo? z zo
print(r3) # ['z', 'zo', 'zo', 'zo']
print("5:* + ? 完毕!")
print("="*60)
# 6.{}重复元字符,也是控制匹配子表达式次数的
s = 'z\nzo\nzoo\nzooo'
r1 = re.findall("zo*", s, re.M)
print(r1) # ['z', 'zo', 'zoo', 'zooo']
r2 = re.findall("zo{0,}", s, re.M) # {0,}等同于*
print(r2) # ['z', 'zo', 'zoo', 'zooo']
r2 = re.findall("zo+", s, re.M)
print(r2) # ['zo', 'zoo', 'zooo']
r2 = re.findall("zo{1,}", s, re.M) # {1,}等同于+
print(r2) # ['zo', 'zoo', 'zooo']
r3 = re.findall("zo?", s, re.M)
print(r3) # ['z', 'zo', 'zo', 'zo']
r3 = re.findall("zo{0,1}", s, re.M) # {0, 1}等同于?
print(r3) # ['z', 'zo', 'zo', 'zo']
r4 = re.findall("zo{2}", s, re.M) # 指定贪婪个数为2("o"的匹配次数为两次)
print(r4) # ['zoo', 'zoo']
print("6:{}完毕!")
print("="*60)
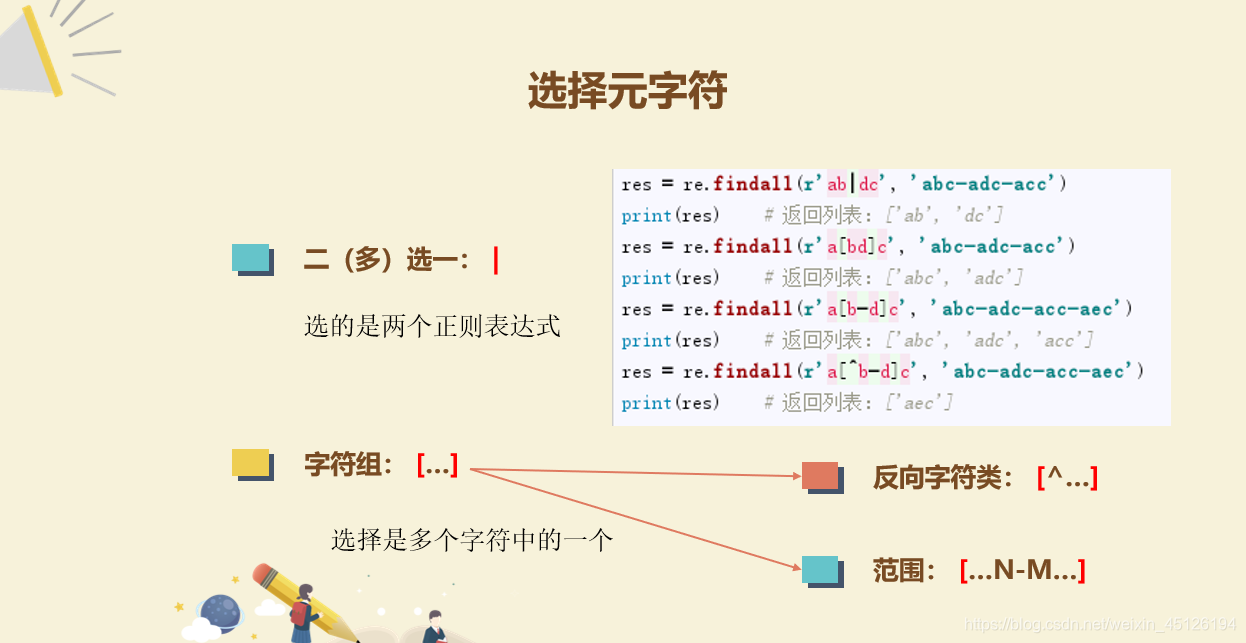
# 7.[]字符组。大括号{}代表次数,中括号[]代表内容
s = 'test\nTesting\nzoo'
r1 = re.findall("[eio]", s, re.M) # 匹配[]中包含的任意字符
print(r1) # ['e', 'e', 'i', 'o', 'o']
r1 = re.findall("[e-o]", s, re.M) # 匹配包含区间的任意字符efghigklmno
print(r1) # ['e', 'e', 'i', 'n', 'g', 'o', 'o']
r1 = re.findall("^[eio]", s, re.M) # 匹配以[eio]包含的任意字符开头的字符
print(r1) # []
r1 = re.findall("[^eio]", s, re.M) # 匹配[]未包含的任意字符
print(r1) # ['t', 's', 't', '\n', 'T', 's', 't', 'n', 'g', '\n', 'z']
r1 = re.findall("[^e-o]", s, re.M) # 匹配[]未包含的任意字符
print(r1) # ['t', 's', 't', '\n', 'T', 's', 't', '\n', 'z']
print("7:[]完毕!")
print("="*60)
# 8.|选择元字符
s = 'z\nzood\nfood'
r = re.findall("z|food", s, re.M) # 表示匹配的表达式有两个,即"z"和"food"
print(r) # ['z', 'z', 'food']
r = re.findall("[z|f]ood", s, re.M)
print(r) # ['zood', 'food']
print("8:| 完毕!")
print("="*60)
# 9.():分组元字符,匹配表达式的字符保存到一个临时区域,返回值为()内的内容
s = 'z\nzood\nfood'
r = re.findall("[z|f]o*", s, re.M)
print(r) # ['z', 'zoo', 'foo']
r = re.findall("[z|f](o*)", s, re.M)
print(r) # ['', 'oo', 'oo']
print("9:()完毕!")
print("="*60)
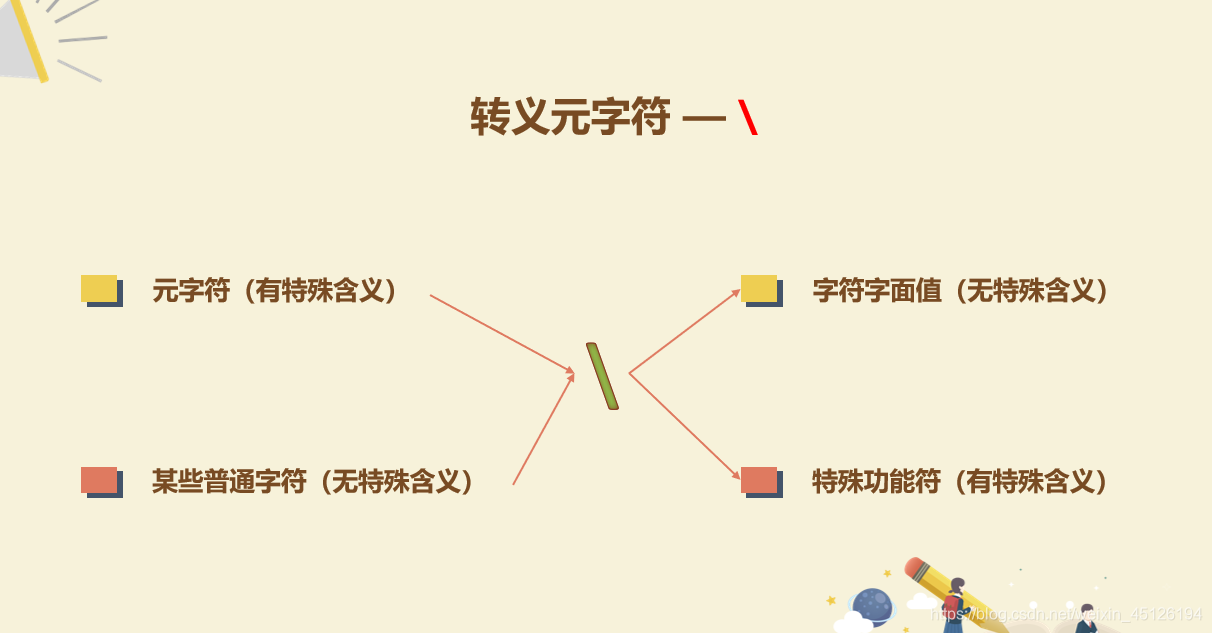
# 10.
# 取消字符串的转义在前面加r或者\
# 取消正则语法的转义,加\
s = 'z\nzood\nfood'
print(s) # z
s1 = r'z\nzood\nfood' # r取消字符串转义
print(s1) # z\nzood\nfood
s2 = 'z\\nzood\\nfood' # \取消字符串转义
print(s2) # z\nzood\nfood
s = '12345@qq.com'
r = re.findall("\.", s) # 取消正则语法转义
print(r) # ['.']
print("10:r \ 完毕!")
print("="*60)
# 11.贪婪模式和非贪婪模式
s = "abcadcaec4534234"
r1 = re.findall(r".+", s) # 贪婪模式:.*, .+尽可能多的匹配字符
print(r1) # ['abcadcaec4534234']
r1 = re.findall(r".*", s) # *与+的区别如下
print(r1) # ['abcadcaec4534234', '']
r1 = re.findall(r"ab.+?", s) # 非贪婪模式:?尽可能少的匹配字符
print(r1) # ['abc']
r1 = re.findall(r"ab.*?", s) # *与+的区别如下
print(r1) # ['ab']
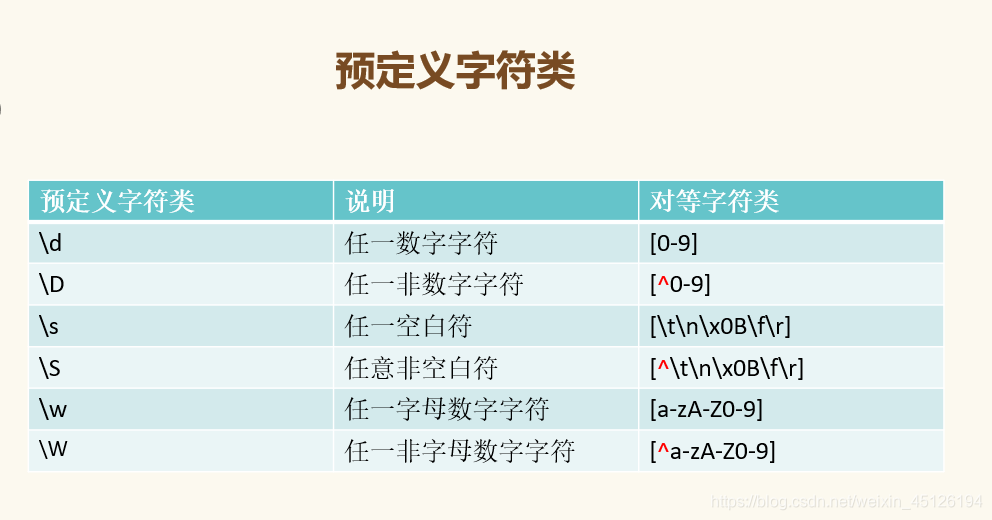
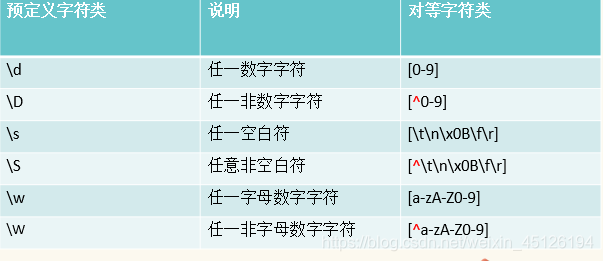
预定义字符组
import re
# 字符组[]
# 预定义字符组
# \d == [0-9]
s = "<a href='asdf'>98745168465</a>"
r = re.findall("\d", s) # 匹配所有数字字符
print(r) # ['9', '8', '7', '4', '5', '1', '6', '8', '4', '6', '5']
r = re.findall("\d.*\d", s) # 指定开头\d,指定结尾\d
print(r) # ['98745168465']
# \D == [^0-9]
r = re.findall("\D", s) # 匹配所有非数字字符
print(r)
# \s:匹配任意的空白符:空格、换行(\n)、制表符(tab)
s = "j0ohqngkadij*+-/你 好\t\n_ajgoaenoigjarif"
r = re.findall('\s', s)
print(r) # [' ', '\t', '\n']
# \w:匹配字母数字下划线汉字
s = "j0ohqngkadij*+-/你 好\t\n_ajgoaenoigjarif"
r = re.findall('\w', s)
print(r)
s = "email:123456@qq.com"
r = re.findall("\d+@\w+\.com$", s)
print(r) # ['123456@qq.com']
其他预定义字符组














 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









