







一、K8S简介
Kubernetes中文官网:Kubernetes
GitHub:github.com/kubernetes/kubernetes
Kubernetes简称为K8s,是用于自动部署、扩缩和管理容器化应用程序的开源系统,起源于Google 集群管理工具Borg。
Kubernetes集群组件逻辑图
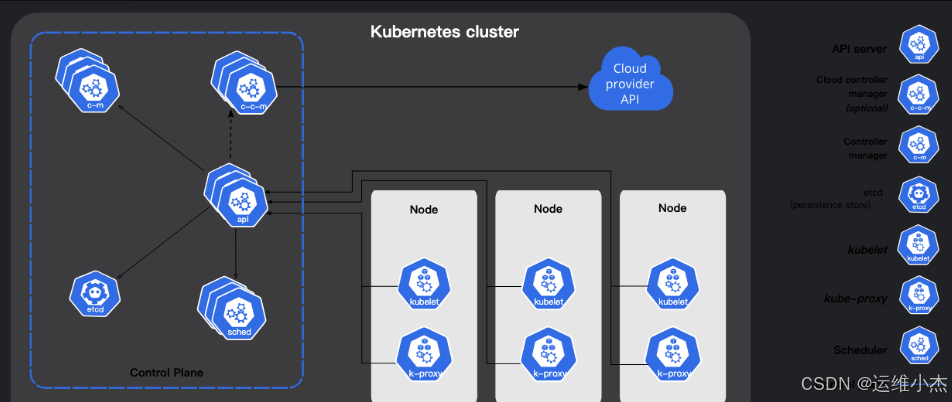 k8s集群属于Master-Slave主从架构,Master节点负责集群管理和资源调度,用于运行控制平面组件(Control Plane Components),Slave节点就是工作负载节点,一般称为Node节点,也叫Worker节点,主要负责运行Pod,一个Pod里可以同时运行多个容器,而容器一般封装的就是基于Dokcer打包的应用,Pod英文叫豌豆荚,每个容器就像是一颗豌豆,简单来说Pod就是一组容器。
k8s集群属于Master-Slave主从架构,Master节点负责集群管理和资源调度,用于运行控制平面组件(Control Plane Components),Slave节点就是工作负载节点,一般称为Node节点,也叫Worker节点,主要负责运行Pod,一个Pod里可以同时运行多个容器,而容器一般封装的就是基于Dokcer打包的应用,Pod英文叫豌豆荚,每个容器就像是一颗豌豆,简单来说Pod就是一组容器。
Master节点组件及功能
| 组件名称 | 功能用途 |
|---|---|
| kube-apiserver | 负责处理接受请求。 |
| etcd | 高可用键值存储,用于k8s集群的后台数据库。 |
| kube-scheduler | 负责选择Worker节点运行新创建的Pod,需要考虑的因素包括资源需求,软硬件及策略约束,亲和性和反亲和性规范、数据位置等。 |
| kube-controller-manager | 负责运行不同类型的控制器进程,每个控制器都是一个单独进程,常见的控制器有节点控制器(Node Controller)、任务控制器(Job Controller)、端点分片控制器(EndpointSlice controller)、服务账号控制器(ServiceAccount controller)等。 |
| cloud-controller-manager | 用于嵌入特定的云平台的控制器。 |
Slave节点组件及功能
| 组件名称 | 功能用途 |
|---|---|
| kubelet | 负责管理Node节点上容器的健康运行,通过接收一组PodSpecs来实现,每个Node节点上都会运行一个kubelet,不会管理不是由 Kubernetes 创建的容器。 |
| kube-proxy | 负责Node节点上的网络代理,用于维护网络规则,这些规则允许从集群内部或外部与Pod进行网络通信,每个Node节点上都会运行一个kube-proxy,k8s的Service就是利用该组件实现的。 |
| Container Runtime | 负责管理容器的执行和生命周期。支持多种类型的容器运行时环境,比如containerd、 CRI-O及CRI自定义实现,k8s使用容器运行时接口(CRI)和用户选择的容器运行时交互。 |
kubeadm工具
使用Kubeadm工具可以快速搭建一个k8s集群,主要包括初始化控制平面节点和加入Worker节点,提供的主要功能如下:
- kubeadm init:初始化一个Master节点
- kubeadm join:将Worker节点加入集群
- kubeadm upgrade:升级K8s版本
- kubeadm token:管理 kubeadm join 使用的令牌
- kubeadm reset:清空 kubeadm init 或者 kubeadm join 对主机所做的任何更改
- kubeadm version:打印 kubeadm 版本
- kubeadm alpha:预览可用的新功能
二、准备工作
软硬件要求
- Linux操作系统,Ubuntu 或 CentOS
- 每台节点至少2G
- Master节点至少2C
- 集群节点网络互通
集群规划
| 操作系统 | CentOS Linux 7(Linux 3.10.0-693.el7.x86_64) |
|---|---|
| Docker | v26.1.4 |
| k8s | v1.20.9 |
| kubeadm | v1.20 |
节点配置
| 主机 | 角色 | IP | CPU | 内存 | 磁盘 |
|---|---|---|---|---|---|
| mogu | master | 196.168.200.132 | 4C | 10Gi | 30G |
| node002 | node1 | 196.168.200.129 | 4C | 10Gi | 30G |
| node003 | node2 | 196.168.200.130 | 4C | 10Gi | 30G |
环境配置
配置主机名
分别修改3台主机名称
hostnamectl set-hostname mogu/node002/node003
more /etc/hostname
修改hosts配置
配置修改所有节点的IP和域名映射
vim /etc/hosts
192.168.200.132 mogu
192.168.200.129 node002
192.168.200.130 node003
关闭Swap分区
kubelet要求必须禁用交换分区,所以kubeadm初始化时回检测swap是否关闭,如果没有关闭会报错,如果不想关闭安装时kubelet命令需要添加–fail-swap-on=false,关闭Swap分区必须在所有节点上执行如下命令:
# 临时关闭,重启恢复
swapoff -a
# 永久关闭,注释swap行
vim /etc/fstab
# /dev/mapper/centos-swap swap swap defaults 0 0
禁用SELinux
所有节点执行如下命令:
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
然后重启,验证 Swap 是否禁用
reboot
free -h #输出中的 Swap 部分应该显示为 0B
关闭防火墙
所有节点执行如下命令:
systemctl disable firewalld
systemctl stop firewalld
修改内核参数
modprobe br_netfilter
echo "modprobe br_netfilter" >> /etc/profile
tee /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 重新加载配置
sysctl -p /etc/sysctl.d/k8s.conf
配置集群时钟同步
Centos7默认使用Chrony工具而非NTP进行时间同步,修改硬件时钟为UTC,时区为本地时区,所有节点执行如下修改:
# 硬件时钟设置为UTC
timedatectl set-local-rtc 0
# 设置本地时区,显示本地时间
timedatectl set-timezone Asia/Shanghai
# 手动加载RTC设置
hwclock --systohc
# 验证
timedatectl
配置k8s的Yum源
国外yum源因为网络问题下载比较慢,此处修改为国内aliyun,用于安装k8s各个组件。
设置静态IP方法参考此文档:《CentOS 设置静态 IP 配置》
Centos 7 配置国内yum源参考此文档:《Centos 7 配置国内yum源》
cat /etc/yum.repos.d/CentOS-Base.repo
#追加以下内容
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
常用包安装
yum install vim bash-completion net-tools gcc -y
三、安装Docker
k8s运行需要容器运行环境,每个节点都需要安装Docker。
Docker安装部署参考此文档:《Docker安装部署及常用命令》
四、安装K8S集群
安装三大组件-kubeadm、kubelet、kubectl
- kubeadm:用来初始化k8s集群的指令。
- kubelet:在集群的每个节点上用来启动 Pod 和容器等。
- kubectl:用来与k8s集群通信的命令行工具,查看、创建、更新和删除各种资源。
所有节点都执行以下命令:
# 所有节点都安装
yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9
# 所有节点设置开机启动
systemctl enable kubelet
初始化k8s集群
- apiserver-advertise-address:apiserver监听地址
- control-plane-endpoint:控制平面的IP地址或DNS名称
- image-repository:镜像仓库,此处为国内阿里云镜像仓库加速下载
- service-cidr:为Service分配的IP地址段
- pod-network-cidr:为pod分配的IP地址段
只在master节点运行此命令:
将192.168.200.132地址修改为你的master节点地址。
kubeadm init \
--apiserver-advertise-address=192.168.200.132 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.20.9 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=172.20.0.0/16
安装成功界面
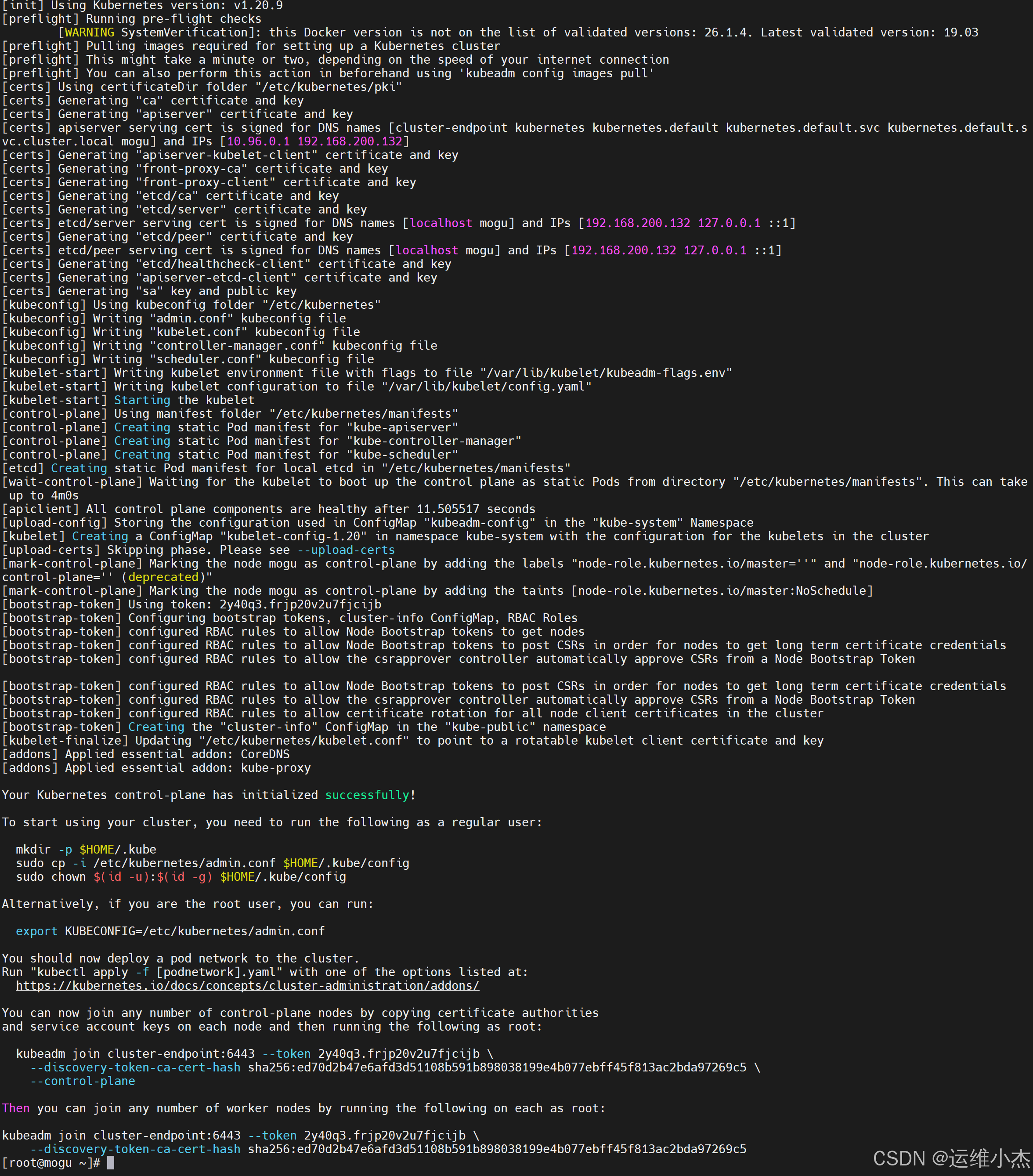
记住以上输出的kubeadm join命令,等下需要用该命令将节点加入集群。
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.200.132:6443 --token 5w7ahu.dy5kcaknlve8aubb \
--discovery-token-ca-cert-hash sha256:4d0b9177579a64c52215bddc7a059a5ca891668c7ac9e13dc5ae679227abd11a
初始化需要下载多个镜像,可能时间比较久,最终安装的镜像如下
配置k8s访问用户,在master节点执行以下命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
如果是root用户,则可以执行以下命令:
export KUBECONFIG=/etc/kubernetes/admin.conf
加入节点
所有从节点Node节点执行如下命令:
此命令来自于刚才安装成功后的控制台输出。
kubeadm join 192.168.200.132:6443 --token 5w7ahu.dy5kcaknlve8aubb \
--discovery-token-ca-cert-hash sha256:4d0b9177579a64c52215bddc7a059a5ca891668c7ac9e13dc5ae679227abd11a
如果不小心忘记了上述join命令,可以在Master 节点上执行以下命令重新生成 Token:
kubeadm token create --print-join-command
修改角色
master节点执行以下命令标记worker节点,需要将node002/node003按照salve主机名称进行修改
kubectl label node node002 node-role.kubernetes.io/worker=worker
kubectl label node node003 node-role.kubernetes.io/worker=worker
master节点执行查看节点信息
kubectl get nodes
NAME STATUS ROLES AGE VERSION
mogu NotReady control-plane,master 3h36m v1.20.9
node002 NotReady worker 166m v1.20.9
node003 NotReady worker 166m v1.20.9
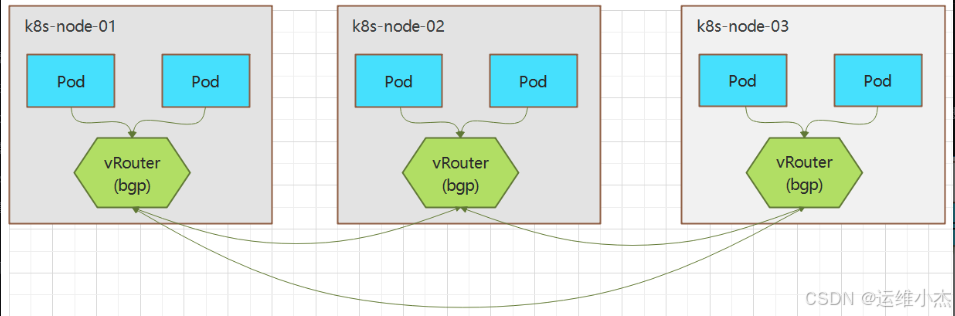
安装Calico网络插件
Calico是一套开源的纯三层的虚拟化网络解决方案,是目前K8s主流的网络方案。
它把每个节点都作为一个虚拟路由器,把Pod当做路由器上一个终端设备为其分配一个IP地址,通过BGP协议生成路由规则,实现不同节点上的Pod网络互通。
Calico系统示意图
所有节点都需执行以下命令:
- 下载calico.yaml并保存到本地
mkdir -p /root/calico
cd /root/calico
curl https://docs.projectcalico.org/v3.15/manifests/calico.yaml -O
- 修改配置calico.yaml中的CALICO_IPV4POOL_CIDR地址,value值为初始化开始时指定的–pod-network-cidr参数值,注意格式对齐
- name: CALICO_IPV4POOL_CIDR
value: "172.20.0.0/16"
- 验证是否成功
kubectl apply -f calico.yaml
kubectl get pod -A | grep calico
- 如果启动不成功可能是镜像没下载下来,可执行以下命令进行手动pull(亦或科学上网进行下载),然后重新观察pod状态。
#查看需要下载的calico镜像
grep image calico.yaml
image: calico/cni:v3.15.5
image: calico/pod2daemon-flexvol:v3.15.5
image: calico/node:v3.15.5
image: calico/kube-controllers:v3.15.5
#拉取对应镜像
docker pull calico/cni:v3.15.5
docker pull calico/pod2daemon-flexvol:v3.15.5
docker pull calico/node:v3.15.5
docker pull calico/kube-controllers:v3.15.5
五、测试K8S集群
创建nginx pod
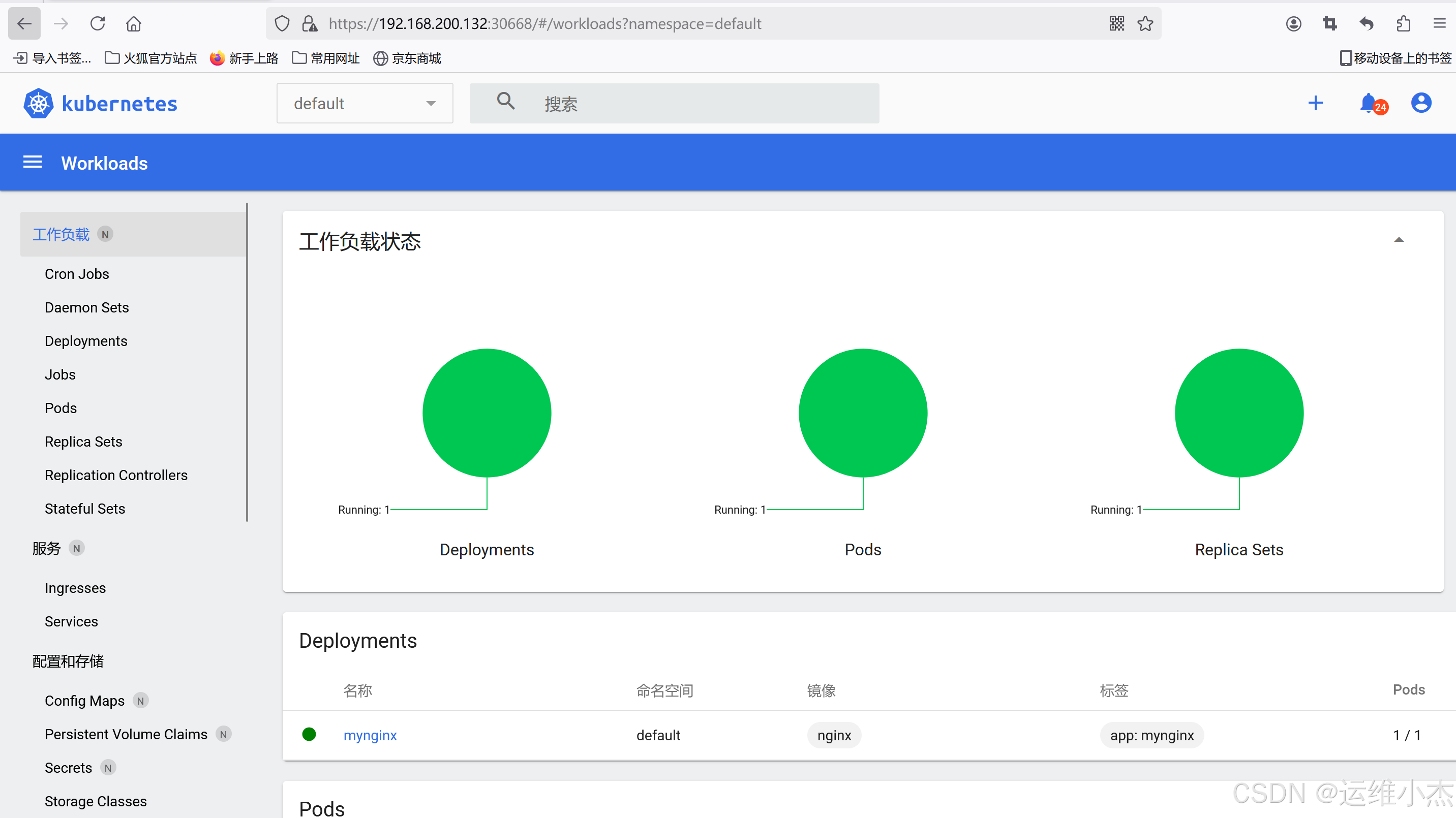
默认会在默认命名空间default中创建一个名称为mynignx的deployment,同时会创建一个名称以myniginx为前缀,叫mynginx-5b686ccd46-kzcv7的Pod。
kubectl create deployment mynginx --image=nginx
# 查看
kubectl get pod,svc
#NAME READY STATUS RESTARTS AGE
#pod/mynginx-5b686ccd46-kzcv7 1/1 Running 0 107s
#
#NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
#service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 47h
对外暴露访问
基于第一步创建的deployment再创建一个名叫mynginx的Service,资源类型由–type=ClusterIP修改为–type=NodePort,会在每个Node节点上监听30161端口,用于接收集群外部访问。
kubectl expose deployment mynginx --port=80 --type=NodePort
# 查看
kubectl get pod,svc
#NAME READY STATUS RESTARTS AGE
#pod/mynginx-5b686ccd46-kzcv7 1/1 Running 0 3m39s
#NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
#service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 47h
#service/mynginx NodePort 10.100.242.53 <none> 80:30933/TCP 13s
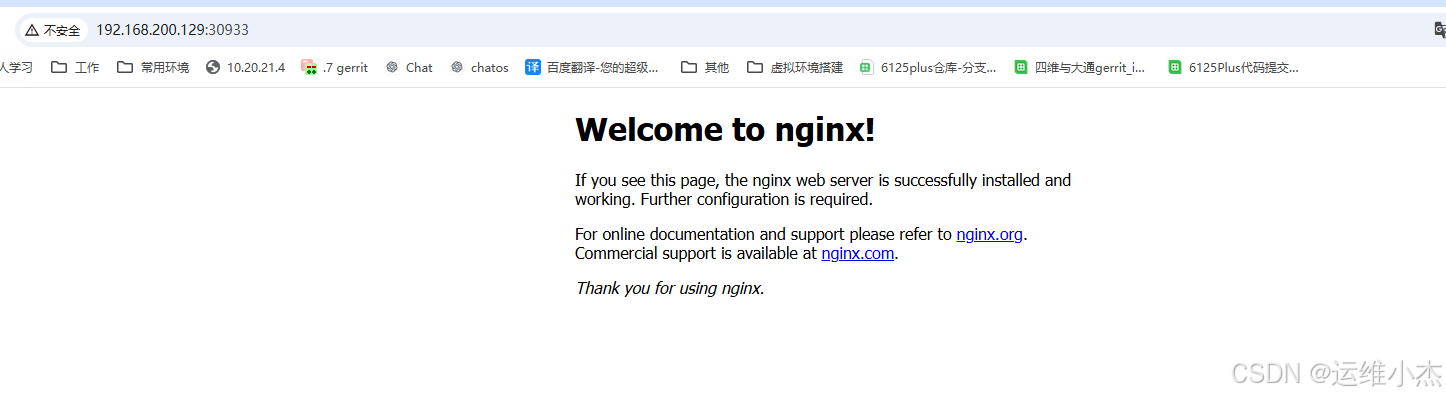
访问nginx
浏览器输入<任意一个节点IP>:,都可以访问nginx首页表示测试成功。
六、安装Dashboard
k8s官方提供了一个简单的Dashboard,主要提供工作负载,服务,配置和存储,集群等管理功能。
Dashboard是可视化插件,它可以给用户提供一个可视化的 Web 界面来查看当前集群的各种信息。
用户可以用 Kubernetes Dashboard 部署容器化的应用、监控应用的状态、执行故障排查任务以及管理 Kubernetes 各种资源。
Github:github.com/kubernetes/dashboard
下载recommended.yaml
官方部署dashboard的服务没使用nodeport,将yaml文件下载到本地,在service里添加nodeport。
curl -O https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
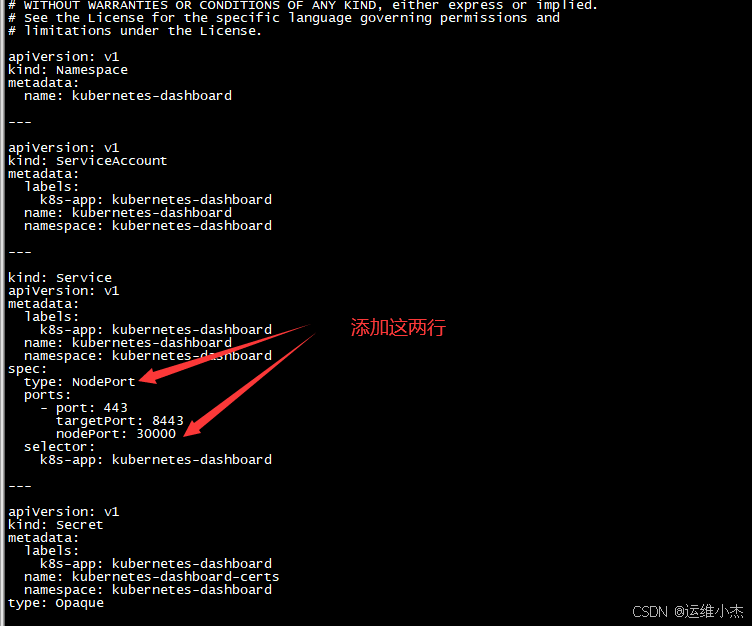
编辑文件内容,修改type和nodePort(也可以不声明,会自动生成随机端口号)
vim recommended.yaml
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30000
selector:
k8s-app: kubernetes-dashboard
应用recommended.yaml文件配置
kubectl create -f recommended.yaml
查看kubernetes-dashboard的service状态
kubectl get svc -n kubernetes-dashboard

在浏览器输入我们的这台机器的ip+端口,进入登录页面
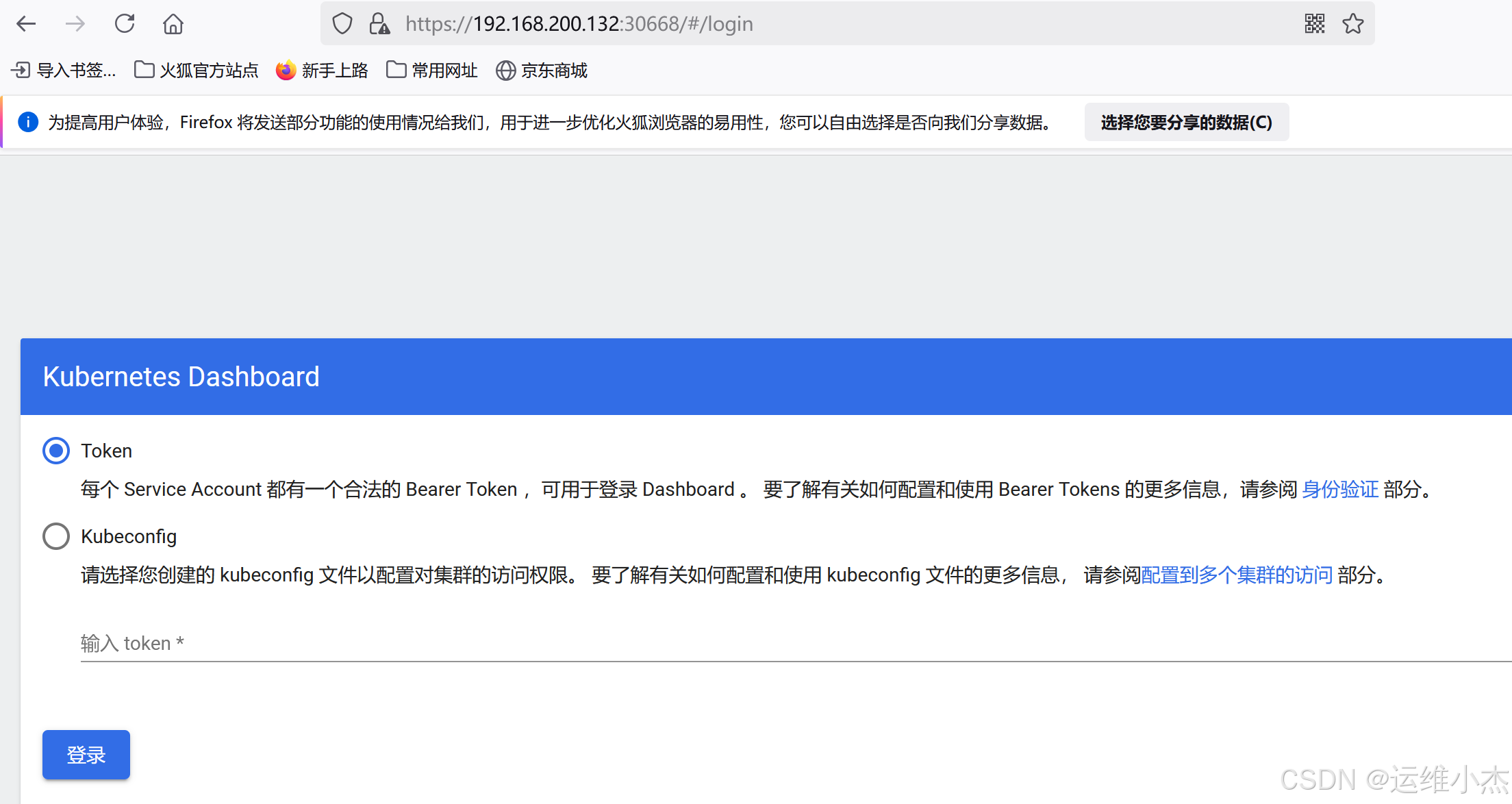
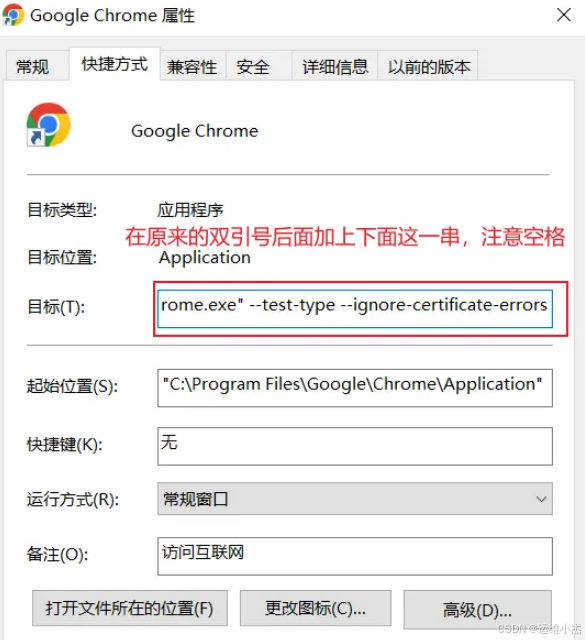
注意使用https://访问,如果浏览器弹出高级按钮,点击展开高级按钮显示报错,仍然无法访问dashboard上面的页面,那么需要配置一下谷歌浏览器:
--test-type --ignore-certificate-errors
创建访问账号
vim dashboard-token.yaml
内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
配置应用
kubectl apply -f dashboard-token.yaml
获取token
kubectl get secret -n kubernetes-dashboard
NAME TYPE DATA AGE
admin-user-token-tmzgr kubernetes.io/service-account-token 3 19s
default-token-8sh9t kubernetes.io/service-account-token 3 37m
kubernetes-dashboard-certs Opaque 0 37m
kubernetes-dashboard-csrf Opaque 1 37m
kubernetes-dashboard-key-holder Opaque 2 37m
kubernetes-dashboard-token-dqfst kubernetes.io/service-account-token 3 37m
查看名为admin-user-token-tmzgr的secret
kubectl describe secret admin-user-token-tmzgr -n kubernetes-dashboard
Name: admin-user-token-tmzgr
Namespace: kubernetes-dashboard
Labels: <none>
Annotations: kubernetes.io/service-account.name: admin-user
kubernetes.io/service-account.uid: 5ef603d5-2d51-4feb-baf3-bbe408bbb9bc
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1066 bytes
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IkVZSVNYSXZXWmlTZVQ3ZEQta25sRHZ5Z0xvbEZTOUk4VkduSXdwYXhaYm8ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLXRtemdyIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI1ZWY2MDNkNS0yZDUxLTRmZWItYmFmMy1iYmU0MDhiYmI5YmMiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.qf226Ri5-PEH-NTiHjFreC1pRL34MdekMnLVp3mN33aKvifYevF7T6wTyJ-n5UyFYSJN-7FCFYPrWa9A4niGPGAUpdoPvoyEoDpHBruSj9hpSiKsfl2sRm8oXwydbSxJlAKsAB9t42peDQgw-5vghiLcdeApnBuPsFxJtG_9DDBNksp5JpFvnNTtmxbzh0A3sE8BnzaoQHGAFMGMEJyL0FRFGxxOxr_A_XkY6ZHjBt5cUnQ7A6yrHjGcE68eo4Rgxaz3iKhZlHI4W8_1WNv4tpNLBordw1Pj7Ww6fv7JAePLowleN9YfYfX6ctrn93SFzmZs2ytJYpBU-ZTDdnEnaQ
登录界面
输入上面的token,进入dashboard首页
七、部署过程可能出现的报错
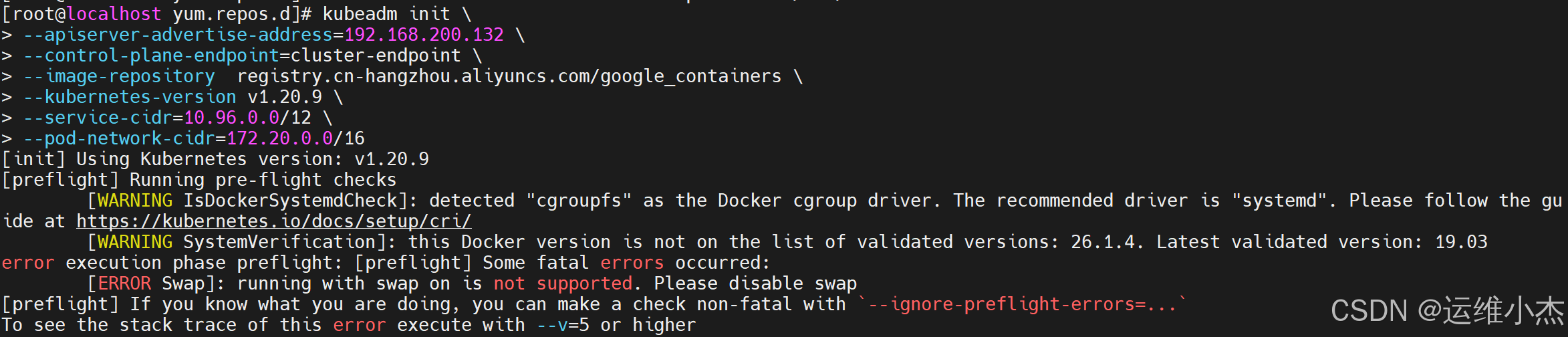
主节点初始化报错
[root@localhost yum.repos.d]# kubeadm init
–apiserver-advertise-address=192.168.200.132
–control-plane-endpoint=cluster-endpoint
–image-repository registry.cn-hangzhou.aliyuncs.com/google_containers
–kubernetes-version v1.20.9
–service-cidr=10.96.0.0/12
–pod-network-cidr=172.20.0.0/16
[init] Using Kubernetes version: v1.20.9
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”. Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 26.1.4. Latest validated version: 19.03
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Swap]: running with swap on is not supported. Please disable swap
[preflight] If you know what you are doing, you can make a check non-fatal with--ignore-preflight-errors=...
To see the stack trace of this error execute with --v=5 or higher
处理方法
Docker 的 cgroup 驱动是 cgroupfs,而 Kubernetes 推荐使用 systemd。
Kubernetes 推荐使用 systemd 作为容器运行时的 cgroup 驱动,而你的系统当前使用的是 cgroupfs。你可以通过以下步骤将 Docker 配置为使用 systemd 作为 cgroup 驱动。
步骤 1:编辑 Docker 配置文件
打开 /etc/docker/daemon.json 文件,如果不存在,则创建它:
sudo vi /etc/docker/daemon.json
将以下内容添加到该文件中:
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
步骤 2:重启 Docker 服务
修改配置后,重新启动 Docker 服务:
sudo systemctl restart docker
步骤 3:验证 cgroup 驱动
运行以下命令来验证 Docker 是否已成功切换为 systemd 驱动:
docker info | grep -i cgroup
你应该看到类似下面的输出:
Cgroup Driver: systemd
从节点join报错

处理办法:
编辑 /etc/sysctl.conf 文件,将 net.ipv4.ip_forward=1 这一行添加或取消注释:
sudo vi /etc/sysctl.conf
找到以下行:
#net.ipv4.ip_forward = 1
取消注释并修改为:
net.ipv4.ip_forward = 1
然后执行以下命令使修改生效:
sudo sysctl -p
主节点或从节点执行kubectl get nodes报错
[root@centos02 kubernetes]# kubectl get nodes
The connection to the server localhost:8080 was refused - did you specify the right host or port?
解决办法
步骤1:查看各节点是否有"/etc/kubernetes/admin.conf"文件。如果没有则从主节点复制到本机环境
scp /etc/kubernetes/admin.conf root@192.168.200.129:/etc/kubernetes/
步骤2:配置环境变量并刷新
vim /etc/profile
export KUBECONFIG=/etc/kubernetes/admin.conf
#保存退出并执行以下代码使用环境变量生效
source /etc/profile
执行kubectl get cs 发现controller-manager和scheduler有报错

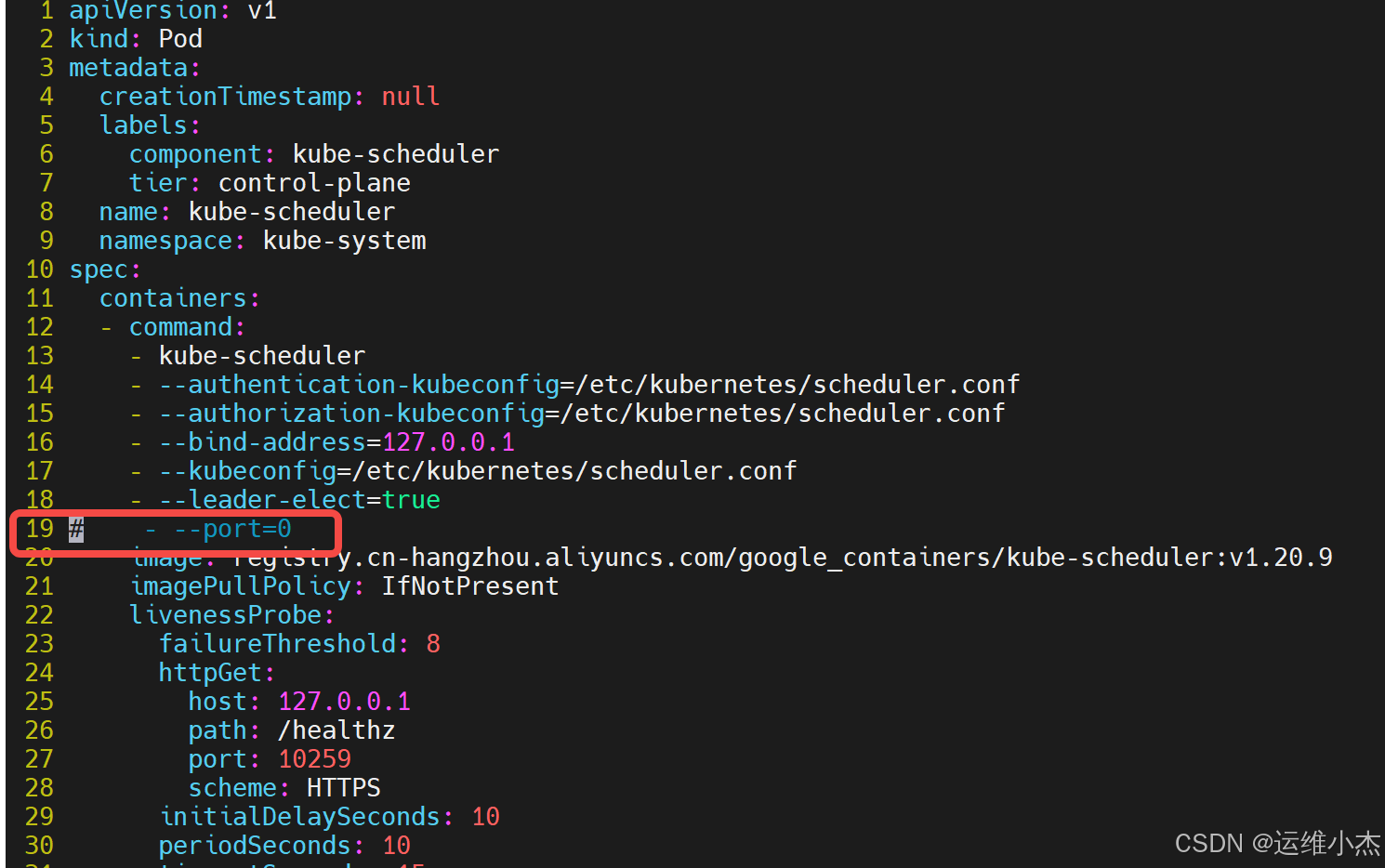
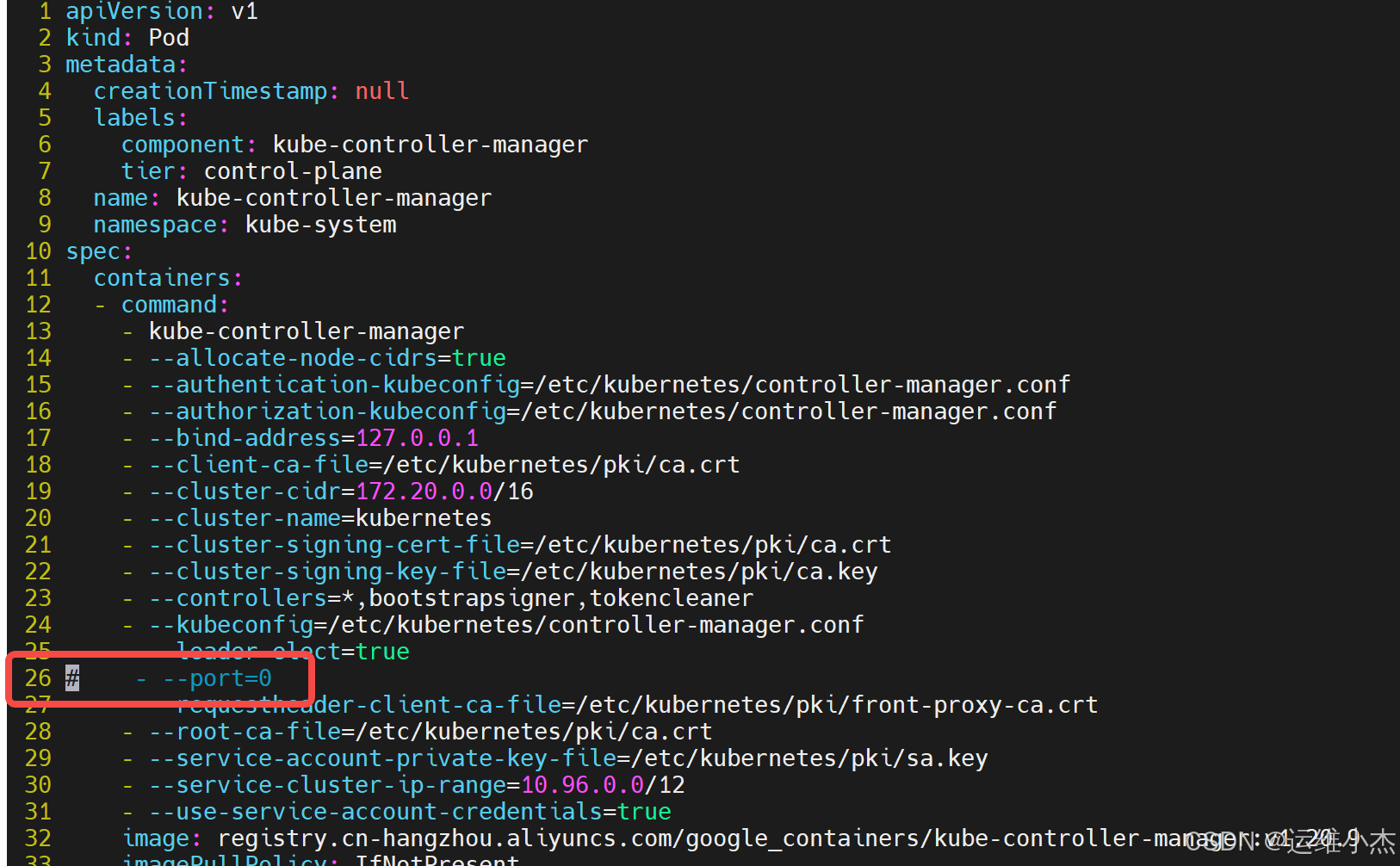
解决办法
出现这种情况是kube-controller-manager.yaml和kube-scheduler.yaml设置的默认端口是0,在文件中注释掉就可以了。(每台master节点都要执行操作)
步骤1:修改kube-scheduler.yaml文件
vim /etc/kubernetes/manifests/kube-scheduler.yaml
注释掉端口号
步骤2:修改kube-controller-manager.yaml文件
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
注释掉端口号
步骤3:重启 master 的 kubele
systemctl restart kubelet.service
再次查看状态
kubectl get cs

Calico部署过程报错
报错1:calico-node-zxr7x 0/1 CrashLoopBackOff 1 8s 192.168.200.129 node002
[root@node002 ~]# kubectl get pods -n kube-system -o wide NAME
READY STATUS RESTARTS AGE IP NODE
NOMINATED NODE READINESS GATES
calico-kube-controllers-bc4f7c685-hn7d6 0/1 ContainerCreating
0 55m node002
calico-node-5s2hq 0/1 Running
0 25h 192.168.200.130 node003
calico-node-t96xv 0/1 Running
1 25h 192.168.200.132 mogu
calico-node-zxr7x 0/1 CrashLoopBackOff
1 8s 192.168.200.129 node002
coredns-54d67798b7-k5ps7 1/1 Running
1 29h 172.20.80.68 mogu
coredns-54d67798b7-mkqtc 1/1 Running
1 29h 172.20.80.69 mogu
etcd-mogu 1/1 Running
2 29h 192.168.200.132 mogu
kube-apiserver-mogu 1/1 Running
2 29h 192.168.200.132 mogu
kube-controller-manager-mogu 1/1 Running
2 29h 192.168.200.132 mogu
kube-proxy-mf8qh 1/1 Running
2 28h 192.168.200.129 node002
kube-proxy-mx8tj 1/1 Running
2 29h 192.168.200.132 mogu
kube-proxy-q8lts 1/1 Running
10 28h 192.168.200.130 node003
kube-scheduler-mogu 1/1 Running
2 29h 192.168.200.132 mogu
[root@node002 ~]# kube logs calico-node-zxr7x -n kube-system
-bash: kube: 未找到命令 [root@node002 ~]# kubectl logs calico-node-zxr7x -n kube-system 2024-12-12 08:16:08.117 [INFO][10] startup/startup.go 356:
Early log level set to info 2024-12-12 08:16:08.117 [INFO][10]
startup/startup.go 372: Using NODENAME environment for node name
2024-12-12 08:16:08.117 [INFO][10] startup/startup.go 384: Determined
node name: node002 2024-12-12 08:16:08.120 [INFO][10]
startup/startup.go 416: Checking datastore connection 2024-12-12
08:16:08.142 [INFO][10] startup/startup.go 440: Datastore connection
verified 2024-12-12 08:16:08.142 [INFO][10] startup/startup.go 107:
Datastore is ready 2024-12-12 08:16:08.170 [INFO][10]
startup/startup.go 481: Initialize BGP data 2024-12-12 08:16:08.172
[INFO][10] startup/startup.go 720: Using autodetected IPv4 address on
interface br-00f09bbc3c59: 172.18.0.1/16 2024-12-12 08:16:08.172
[INFO][10] startup/startup.go 551: Node IPv4 changed, will check for
conflicts 2024-12-12 08:16:08.185 [WARNING][10] startup/startup.go
1066: Calico node ‘mogu’ is already using the IPv4 address 172.18.0.1.
2024-12-12 08:16:08.185 [INFO][10] startup/startup.go 320: Clearing
out-of-date IPv4 address from this node IP=“172.18.0.1/16” 2024-12-12
08:16:08.197 [WARNING][10] startup/startup.go 1270: Terminating
问题原因:
发现报错描述172.18.0.1/16地址已经被mogu节点占用了,排查发现是部署在mogu节点的harbo容器启动时创建了bridge网络生成的网卡把172.18.0.1/16网段占用了,导致calico启动失败。
解决办法:
停止mogu节点上的harbor容器,重新启动harbor容器会重新生成新的网段bridge网络。
报错2:calico启动后发现其中一个po虽然是Ready状态,但status为0/1
calico-node-t96xv 0/1 Running 1 26h 192.168.200.132 mogu <none> <none>
通过查看日志发现报错如下:
Warning Unhealthy 7m48s kubelet Readiness probe failed:2024-12-12 09:01:21.036 [INFO][141] confd/health.go 180: Number of node(s) with BGP peering established = 0
calico/node is not ready:BIRD is not ready: BGP not established with192.168.200.129,192.168.200.130 Warning Unhealthy 7m38s kubelet Readiness probe failed:2024-12-12 09:01:31.005 [INFO][178]
confd/health.go 180: Number of node(s) with BGP peering established = 0
问题原因:
需调整calicao网络插件的网卡发现机制,修改IP_AUTODETECTION_METHOD对应的value值。
官方提供的yaml文件中,ip识别策略(IPDETECTMETHOD)没有配置,即默认为first-found,这会导致一个网络异常的ip作为nodeIP被注册,从而影响node-to-nodemesh。我们可以修改成can-reach或者interface的策略,尝试连接某一个Ready的node的IP,以此选择出正确的IP。
修改配置文件:
kubectl edit daemonset calico-node -n kube-system
修改前效果:
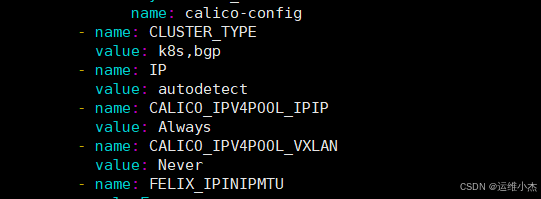
添加如下2行代码:
- name: IP_AUTODETECTION_METHOD
value: interface=ens*
效果如下:
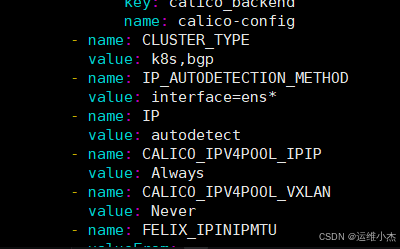
再次查看pods状态正常如图:



















 5136
5136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









