







Hive --HQL(hive querry language)
- Hive 是由Fackbook开源用于解决 海量结构化日志 的数据统计。 现在已经交给 --> apche
- Hive是基于Hadoop的一个数据仓库工具,可以将结构话的数据映射为一张表,并提供类SQL查询功能。 本质: 将HQL转换为Mapreduce程序。 数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的
什么是Hive?
Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
总之,hive正是实现了这个,hive是要类SQL语句(HiveQL)来实现对hadoop下的数据管理。hive属于数据仓库的范畴,那么,数据库和数据仓库到底有什么区别了,这里简单说明一下:数据库侧重于OLTP(在线事务处理),数据仓库侧重OLAP(在线分析处理);也就是说,例如mysql类的数据库更侧重于短时间内的数据处理,反之。
-
无hive:使用者…->mapreduce…->hadoop数据(可能需要会mapreduce)
-
有hive:使用者…->HQL(SQL)->hive…->mapreduce…->hadoop数据(只需要会SQL语句)
hadoop中hdfs和hive的关系是什么呢?
hdfs就是个文件系统,和我们的windows系统重磁盘的的类型NTFS,FAT32一样,不过是分布式的。hdfs是文件系统用来装数据的,hive是用来调用计算引擎操作数据的。
-
hive是基于 Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
-
Hive 是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。 Hive定义了简单的类SQL查询语言,称为HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer无法完成的复杂的分析工作。


Hive与关系型数据库的区别?
使用 hive 的命令行接口,感觉很像操作关系数据库,但是 hive 和关系数据库还是有很大的不同,下面我就比较下 hive 与关系数据库的区别,具体如下:
-
Hive 和关系数据库存储文件的系统不同,Hive 使用的是 hadoop 的HDFS(hadoop 的分布式文件系统),关系数据库则是服务器本地的文件系统;
-
hive 使用的计算模型是 mapreduce,而关系数据库则是自己设计的计算模型;
-
关系数据库都是为实时查询的业务进行设计的,而 Hive 则是为海量数据做数据挖掘设计的,实时性很差; 实时性的区别导致 Hive 的应用场景和关系数据库有很大的不同;
-
Hive 很容易扩展自己的存储能力和计算能力,这个是继承 hadoop 的,而关系数据库在这个方面要比数据库差很多。
Hive的数据放在哪儿?
数据在HDFS的warehouse目录下,一个表对应一个子目录。
本地的/tmp目录存放日志和执行计划
hive的表分为两种,内表 和 外表。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。 ++在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。++
- Hive处理的数据存储在HDFS上
- Hvie分析数据底层的默认实现是MapReduce
- 执行程序运行在Yarn上
Hive的体系架构及部署架构
hive的体系架构
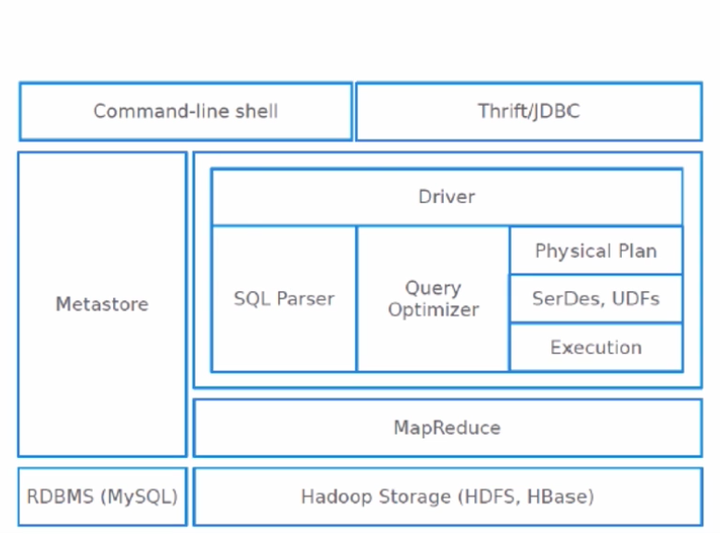

- 从上到下的这个过程,从客户端传递sql至driver来解析sql语句到最后生成物理执行计划交给mapreduce执行这些都是由hive内核完成的,我们输入仅仅只有一条sql语句,那么输出就是相应的作业的输出了,那么左边还剩下两个框Metastore和RDBMS(MySQL)是什么意思呢,我们说了在hive里面有一个统一的元数据管理,也就是叫Metastore,那么这个Metastore的数据我们是可以存放在关系型数据库中的,比如mysql中,当然默认是存放在本机的db文件中,不过这个用的是极少的,建议使用的时候部署在mysql就可以了。我们刚刚说的表,列,列的类型,分隔符等等这些全部是存放在mysql数据库里面一整套元数据的表里面的,这个表个数是有很多很多的。以上就是hive整个的一个体系架构。
Hive的部署框架
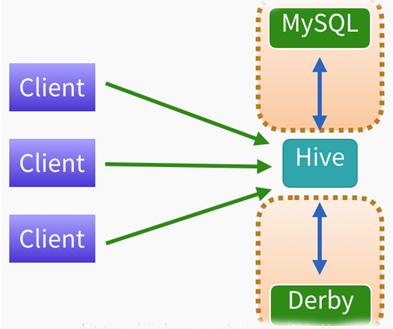

首先从测试环境来看,把hive当成一个引擎,这个hive的底层的元数据可以存放在mysql里面也可以存放在Derby里面,但是derby数据库是单会话的,一次只能有一个连接,所以不建议用derby,直接使用mysql,把所有的元数据管理都放倒mysql里面去。
那么客户端使用的时候,不管你是通过shell还是jdbc的方式,你连到hive就能进行相应的操作了,这是我们测试环境。那么在生产环境如何部署?这还是有一点差别的!
部署环境
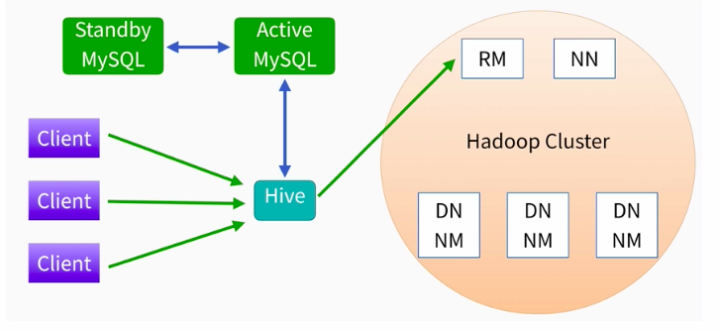
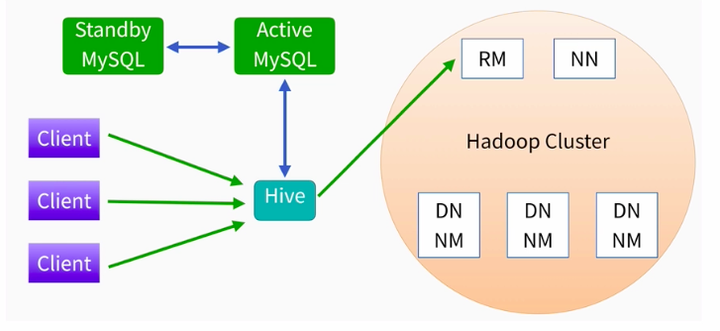
上图右边是hadoop的一个集群,因为hive是构建在hadoop上的一个数据仓库,他使用hdfs进行数据的存储,使用mapreduce进行作业的计算,所以hive是跑在hadoop之上的,在这个hadoop集群之上我们有ResourceManager和NameNode还有DataNode以及NodeManager,
那么你的作业提交上来其实就生成了一个mapreduce作业,他先到ResourceManager上申请资源,然后才能进行运行,我们看图的左边,客户端client还是一样要么是shell要么是你的jdbc,你把你的sql提交给hive就行了。
那么在生产环境我们的元数据是存放在MySQL上面的,那么除了一台机器还不够,还要一台备用机器standby来防止主机出故障,并且备用机要和主机定时进行同步更新!
那么这里面hadoop上面ResourceManager和NameNode都有备用包括DN和NM这些节点都会配很多个,那么hive配几个?其实hive只要在集群上找一台机器配置一个就可以了,为什么呢?因为hive只是一个客户端,你只要把sql提交给hive,然后hive最终是把作业提交到yarn上去执行的,所以你任意找一个机器作为客户端或者找两个机器作为客户端提交sql就可以了!
Hive安装与部署
需要使用到的软件
- MySQL&MySQL connector j
#MYSQL 本体建议使用 apt 方式安装
#MYSQL connector j 需要到官网上去下载
https://dev.mysql.com/downloads/connector/j/
- Hive 我选择了1.2.2的版本。你们可以随意选择。
需要的运行环境
- Hadoop环境
我们首先需要检查我门的hadoop环境是否可以正常运行。
我们可以使用start-all命令,来开启我们的hadoop环境。然后使用jps查看当前的进程。
#在这里这是给你们复习一下hadoop如何开启,同学们没有必要现在就开启hadoop。
#如果你们能过确定你们的hadoop环境没有问题的话。
#开启hadoop服务
start-all.sh
#查看当前进程
jps
- Java环境
Hive工具中默认使用的Derby数据库,该数据库使用简单,操作灵活,但是存在一定的局限性。Hive支持使用第三方数据库(MySQL等),通过配置可以把MySQl集成到Hive工具中,MySQL功能更强大,应用也更广。
默认情况下,Hive元数据保存在内嵌的Derby数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不使用,为了支持多用户会话,则需要一个独立的元数据库,使用MySQL作为元数据库,Hive内部对MySQL提供了很好的支持。
- 所以我们需要将Hive默认自带的Derby替换为MySQL。
使用以下命令即可进行mysql安装,注意安装前先更新一下软件源以获得最新版本:
ps. 这里我们的使用的是Ubuntu系统,软件源都在国外,下载软件速度比较慢,容易出错。所以我们这里需要对软件源进行一个替换。
如何替换软件源?
#打开软件源的列表文件。
sudo vim /etc/apt/source.list
#删除掉列表文件中的所有内容,在vim 命令模式下输入如下:
ggdG
之后我们需要去晚上搜索相关源地址。可以在百度搜索关键字“ Ubuntu 源替换/Ubuntu 清华源/阿里源等”


将我们找到的源地址,黏贴进我们刚刚打开的source.list文件中。之后保存退出。
#在vim中如何保存退出
按 esc 键
shift + :
wq
回车
到此我们就已经完成了源地址的替换。我们需要对新的软件下进行一下更新,然后进行mysql的安装。
sudo apt-get update #更新软件源
sudo apt-get install mysql-server #安装mysql
上述命令会安装以下包: apparmor mysql-client-5.7 mysql-common mysql-server mysql-server-5.7 mysql-server-core-5.7 因此无需再安装mysql-client等。安装过程会提示设置mysql root用户的密码,设置完成后等待自动安装即可。默认安装完成就启动了mysql。
- 启动和关闭mysql服务器:
service mysql start
#开启之后不要关掉。这里只是让大家知道如何关闭
service mysql stop
- 确认是否启动成功,mysql节点处于LISTEN状态表示启动成功:
sudo netstat -tap | grep mysql
#注意无法使用netstat命令,我们需要安装 net-tools软件包。
sudo apt install net-tools
- mysql完成安装后,我们需要登录mysql进行配置,更改密码等操作。
#我们可以使用超级用户直接免密登录mysql
sudo su
mysql -u root
- 开启mysql之后,我们需要手动更改密码。
alter user 'root'@'localhost' IDENTIFIED WITH mysql_native_Password BY "你想要的密码"
#保存
flush privileges
我们需要新建一个hive的数据库
create database hive;


将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码
grant all privileges on *.* to root@localhost identified by '你数据库root用户的连接密码'
如何这上面的语句报错,尝试用下面的。
grant all privileges on *.* to root@localhost
我们之后可以使用如下命令登录mysql数据库。
mysql -u root -p
到此数据部分的设置已经完成
安装HIVE
在安装Hive之前,请首先安装Hadoop
- 下载并解压Hive安装包
首先需要下载Hive安装包文件, Hive官网下载地址
将解压到/usr/local中
sudo tar -zxvf ./apache-hive-3.1.2-bin.tar.gz -C /usr/local
cd /usr/local/
将文件夹名改为hive
sudo mv apache-hive-3.1.2-bin hive
- 为了方便使用,我们把hive命令加入到环境变量中去, 请使用vim编辑器打开profile文件,命令如下:
sudo vim /etc/profile


在该文件最前面一行添加如下内容:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin


保存退出后,运行如下命令使配置立即生效:
source /etc/profile
完成之后我们可以使用如下命令查看环境变量是否设置完成以及当前Hive的版本。
hive --version


上图显示,我们的hive使用的是hive 1.2.2的版本,至此,我们hive已经成功安装并且完成了环境变量的配置。
配置HIVE
修改/usr/local/hive/conf下的hive-site.xml 执行如下命令:
#进入到hive的配置目录
cd /usr/local/hive/conf
#然后我们复制一个模板
sudo cp hive-default.xml.template hive-site.xml


上面命令是将hive-default.xml.template复制了一份名为hive-site.xml; 然后,使用vim编辑器新建一个配置文件hive-site.xml,命令如下:
sudo vim hive-site.xml
将hive-site.xml中所有内容都删除掉。填入如下信息:
<div class="highlight">
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive</value>(mysql地址localhost)
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>(mysql的驱动)
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>SS
<name>javax.jdo.option.ConnectionUserName</name>(用户名)
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>(密码)
<value>123456</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
然后,按键盘上的“ESC”键退出vim编辑状态,再输入:wq,保存并退出vim编辑器。
我们需要将mysql驱动程序进行解压抽取,然后拷贝到hive/lib的文件夹中。
sudo cp mysql-connector-java-8.0.22.jar /usr/local/hive/lib/


我们在启动hive之前,需要对数据库进行初始化。
schematool -dbType mysql -initSchema
启动HIVE
我们已经完成所有步骤,我们需要启动我们的HIVE数据仓库。
- 启动Hadoop集群
cd /././hadoop/sbin/
start-all.sh
- 启动hive
cd /usr/local/hive/bin
hive
HIVE 测试
- 通过如下命令我们可以知道现在的hadoop中的HDFS存了什么。
hadoop fs -ls -R /


- 进入hive并创建一个测试库和测试表
cd /usr/local/hive/bin
hive
- 创建库:
create database hive_1;


- 显示库:
show databases;
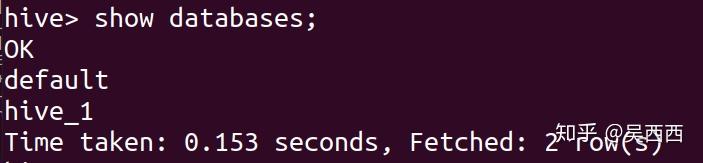

库创建成功
- 当我们完成创建之后,我们来看看HDFS发生了什么变化。


多了一个hive_1.db的库,就是我们刚刚创建的。
我们来看看和我们hive关联的mysql数据库发生了什么变化?

















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









