






Stream类平时用到很多,但总是记不住。做个记录。
1、Stream的种类
- IntStream:表示基本类型int的流。
- LongStream:表示基本类型long的流。
- DoubleStream:表示基本类型double的流。
- Stream:表示对象引用类型T的流,可以是任何Java对象的流。
以上Stream都是Java 8引入的,用于对集合数据进行函数式操作,如映射、过滤、聚合等。
除了上述四种基本的Stream类之外,还有一些其他和Stream相关的接口和类,如BaseStream、Collectors等,用于支持流操作的相关功能。
1-1:Collectors
Collectors是Java Stream API 中提供的用于收集流元素的工具类,它提供了丰富的方法用于对流中的元素进行收集、统计和转换。以下是一些Collectors类中常用的方法:
- toList():将流中的元素收集到List中。
- toSet():将流中的元素收集到Set中。
- toMap():将流中的元素以键值对的形式收集到Map中。
- joining():将流中的元素连接成一个字符串。
- counting():统计流中元素的个数。
- summingInt() / summingLong() / summingDouble():对流中的元素进行求和操作。
- averagingInt() / averagingLong() / averagingDouble():计算流中元素的平均值。
- groupingBy():按照指定条件对流中的元素进行分组。
- partitioningBy():按照指定条件对流中的元素进行分区。
Collectors类方法举例说明:
1. toList():
String[] strArr = {"Hello", "World", "Java"};
List<String> strList = Arrays.stream(strArr)
.collect(Collectors.toList());
System.out.println(strList);
在这个例子中,将一个字符串数组转换为Stream,然后使用Collectors.toList()方法将其收集到List中。
2. toMap():
参数:
- keyMapper: 用于提取流中元素的键的映射函数。
- valueMapper: 用于提取流中元素的值的映射函数。
- mergeFunction: 在遇到重复键时,用于合并值的函数(可选)。
- mapSupplier: 用于提供Map实例的Supplier(可选)。
Map<Long, User> map = users.stream()
.collect(Collectors.toMap(User::getId, o -> o));
这个例子将流中的元素以id为键,对象本身为值,收集到一个Map中。
3. joining():
参数:
- delimiter: 作为连接结果的定界符(可选)。
- prefix: 结果字符串的前缀(可选)。
- suffix: 结果字符串的后缀(可选)。
List<String> list = Arrays.asList("apple", "banana", "orange");
String result = list.stream()
.collect(Collectors.joining(", ", "Prefix-", "-Suffix"));
System.out.println(result);
这个例子中,将一个字符串列表连接成一个字符串,通过参数指定了分隔符、前缀和后缀。
4. counting():
List<String> list = Arrays.asList("apple", "banana", "orange");
long count = list.stream().collect(Collectors.counting());
System.out.println("Number of elements: " + count);
这个例子中,统计流中的元素个数。
5. groupingBy():
参数:
- classifier: 分组条件的映射函数。
- downstream: 用于对分组结果进行进一步处理的Collector(可选)。
Map<Integer, List<String>> result = list.stream().collect(Collectors.groupingBy(String::length));
System.out.println(result);
在这个例子中,根据字符串长度对字符串进行分组,得到一个Map,Map的Key是字符串长度,Value是相同长度的字符串列表。
6. partitioningBy():
Map<Boolean, List<String>> result = list.stream().collect(Collectors.partitioningBy(s -> s.length() > 5));
System.out.println(result);
这个例子中,根据字符串长度是否大于5进行分区,得到一个Map,true对应长度大于5的字符串列表,false对应长度不大于5的字符串列表。
2、Stream整体图解
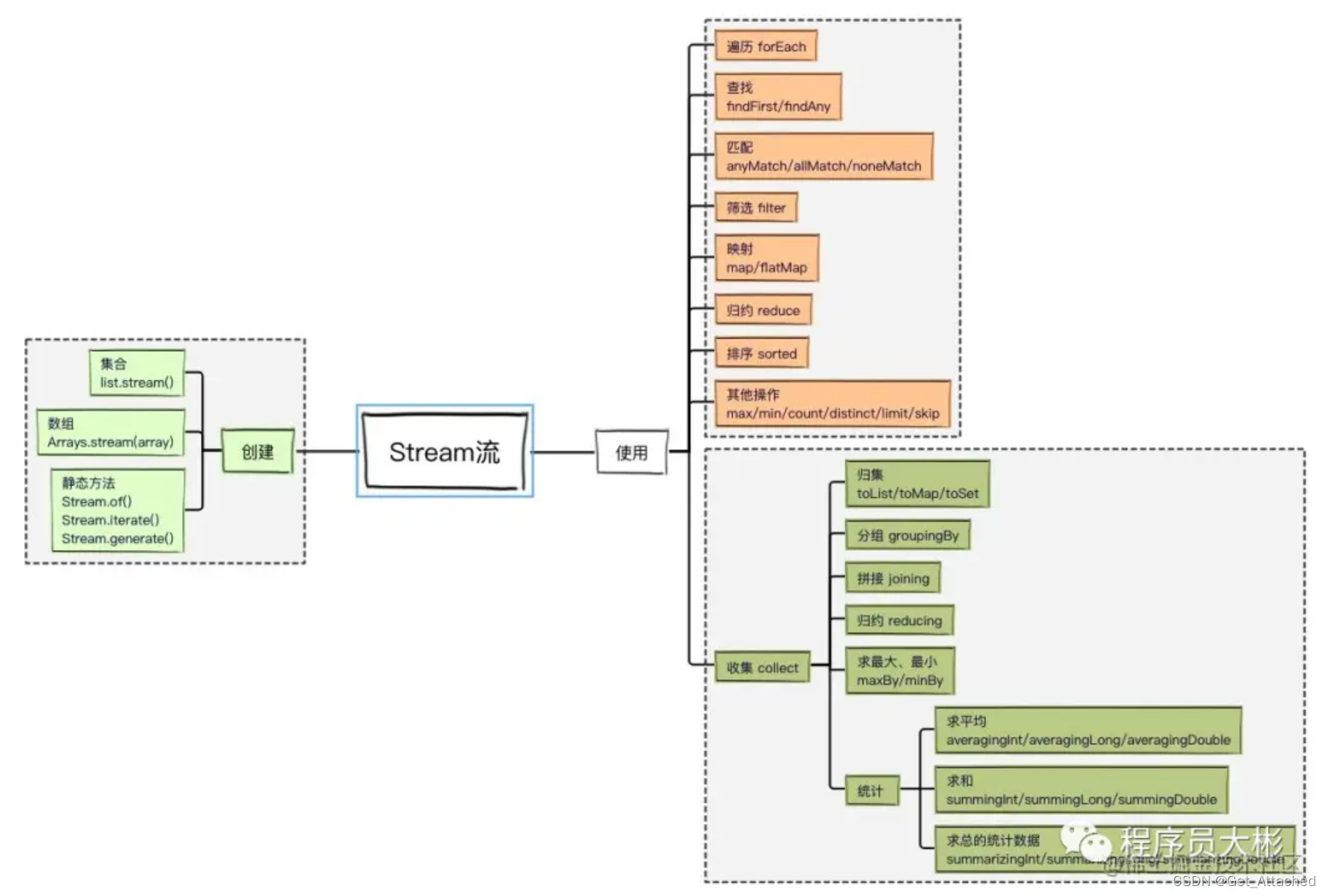
3、创建
-集合自带Stream流的方法
List<String> list = new ArrayList<>();
//创建一个顺序流
Stream<String> stream = list.stream();
//创建一个并行流
Stream<String> parallelStream = list.parallelStream();
-通过Array数组创建
int[] array = {1,2,3,4,5};
IntStream stream = Arrays.stream(array);
-使用Stream的静态方法创建(创建的是对象类的流)
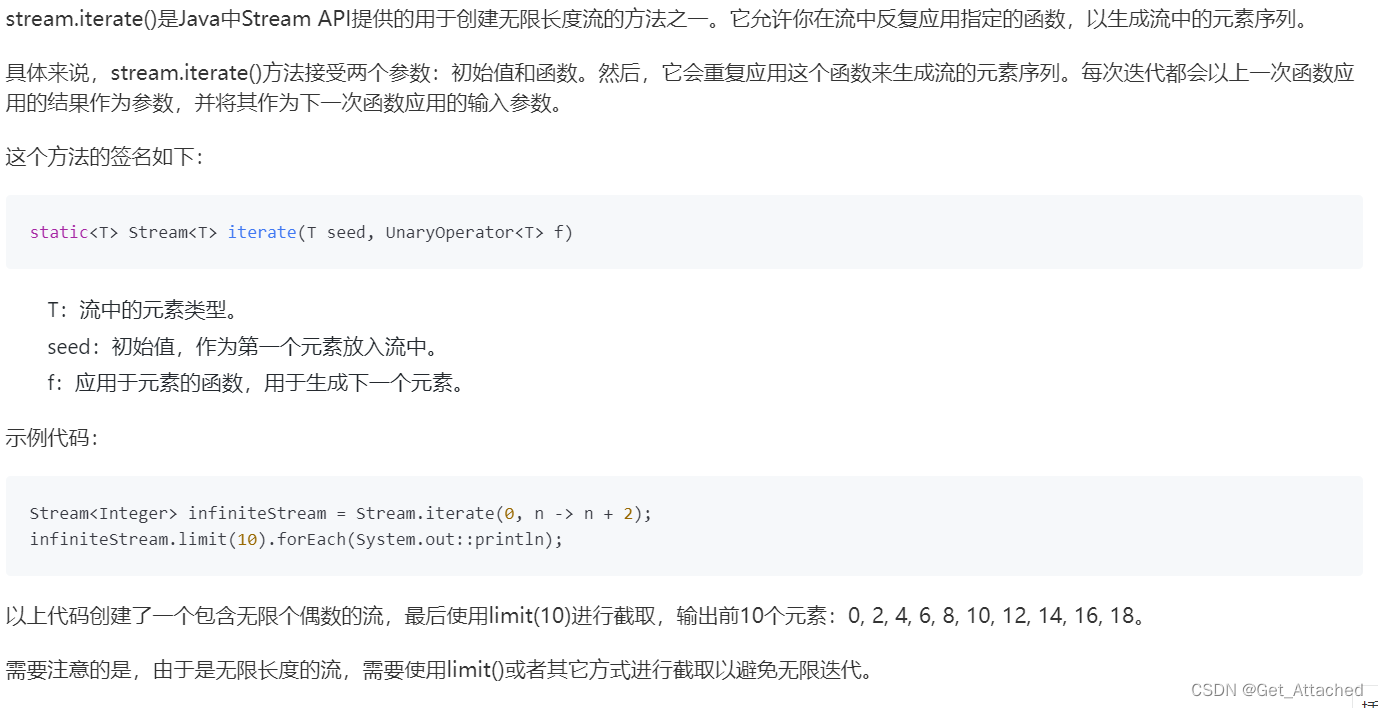
Stream<Integer> stream = Stream.of(1,2,3,4,5);
Stream<Integer> stream = Stream.iterate(0, (x) -> x + 3).limit(3);
Stream<String> stream = Stream.generate(() -> "hello").limit(3);
-数值流(IntStream、LongStream、DoubleStream)
// 生成有限的常量流
IntStream intStream = IntStream.range(1, 3); // 输出 1,2
IntStream intStream = IntStream.rangeClosed(1, 3); // 输出 1,2,3
// 生成一个等差数列
IntStream.iterate(1, i -> i + 3).limit(5).forEach(System.out::println); // 输出 1,4,7,10,13
// 生成无限常量数据流
IntStream generate = IntStream.generate(() -> 10).limit(3); // 输出 10,10,10
4、使用方法
初始化使用对象。
public class Demo{
class User{
private String name;
private Integer age;
}
public static void main(String[] args){
List<User> users = new ArrayList<>();
users.add(new User("aa", 1));
users.add(new User("bb", 2));
}
}
-遍历 forEach
users.stream().forEach(user -> System.out.println(user));
-查找 find
User user = users.stream().findFirst().orElse(null);
-筛选 filter
users.stream().filter(user -> "bb".equals(user.name)).forEach(System.out::println);
-匹配 match
// 判断是否存在name是Tom的用户
boolean existTom = users.stream().anyMatch(user -> "Tom".equals(user.getName()));
// 判断所有用户的年龄是否都小于5
boolean checkAge = users.stream().allMatch(user -> user.getAge() < 5);
-映射 map
users.stream().map(User::getName).forEach(System.out::println);
// List<List<User>> 转 List<User>
List<List<User>> userList = new ArrayList<>();
List<User> users = userList.stream().flatMap(Collection::stream).collect(Collectors.toList());
-归约 reduce(做对象计算)
// 求用户年龄之和
Integer sum = users.stream().map(User::getAge).reduce(Integer::sum).orElse(0);
// 求用户年龄的乘积
Integer product = users.stream().map(User::getAge).reduce((x, y) -> x * y).orElse(0);
-⭐️排序 sorted
Stream中的Comparator用于对流中的元素进行比较和排序。它通常用于对流中的元素进行自定义排序。
List<String> words = Arrays.asList("banana", "apple", "grape", "orange");
List<String> sortedWords = words.stream()
.sorted(Comparator.comparing(String::length)) // 按字符串长度升序排列
.collect(Collectors.toList());
上面的示例使用了Comparator.comparing()方法,它接受一个Function作为参数,用于提取需要比较的属性,并对流中的元素进行排序。这里按照单词长度升序对字符串进行排序。除了comparing()方法外,还有reversed()方法可以用于倒序排序。当需要按照多个属性对流中的元素进行排序时,可以使用Comparator的thenComparing()方法进行多属性排序。
// 按年龄倒序排
List<User> collect = users.stream()
.sorted(Comparator.comparing(User::getAge).reversed())
.collect(Collectors.toList());
//多属性排序
List<String> words = Arrays.asList("banana", "apple", "grape", "orange");
List<String> sortedWords = words.stream()
.sorted(Comparator.comparing(String::length) // 首先按长度排序
.thenComparing(Comparator.naturalOrder())) // 长度相同时按照字典顺序排序
.collect(Collectors.toList());
-⭐️收集 collect
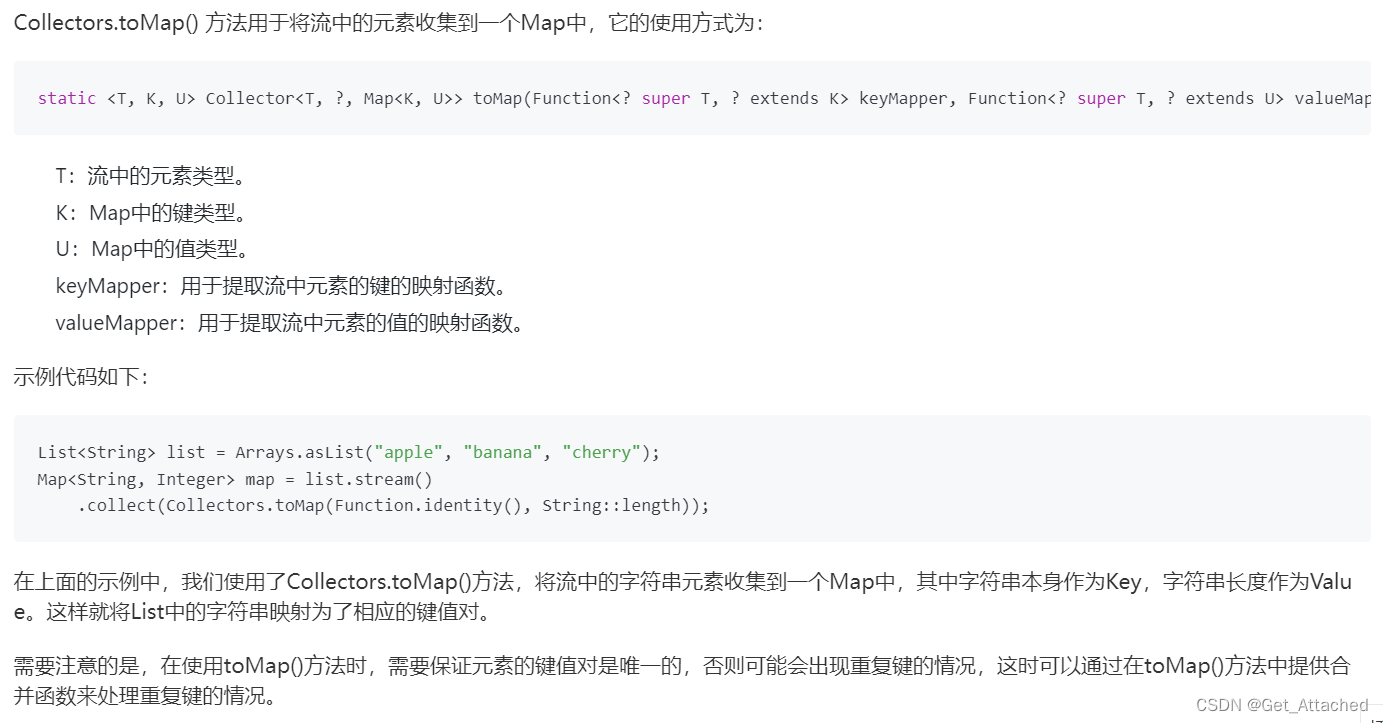
//list 转成 map
Map<Integer, User> map = users.stream()
.collect(Collectors.toMap(User::getAge, Function.identity()));

Collectors.toMap()方法:
// 按年龄分组
Map<Integer, List<User>> userMap = users.stream().collect(Collectors.groupingBy(User::getAge));
// 求平均年龄
Double ageAvg = users.stream().collect(Collectors.averagingInt(User::getAge)); // 输出 1.5
// 求年龄之和
Integer ageSum = users.stream().collect(Collectors.summingInt(User::getAge));
// 求年龄最大的用户
User user = users.stream().collect(Collectors.maxBy(Comparator.comparing(User::getAge))).orElse(null);
// 把用户姓名拼接成逗号分隔的字符串输出
String names = users.stream().map(User::getName).collect(Collectors.joining(",")); // 输出 Tom,Jerry















 4275
4275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









