









数据库集群能够带来高可用,低风险等许多有些的特性,现在我就来给大家分享一下使用redis进行数据库集群的搭建
还是老样子,我们准备好两台虚拟机,我这里用的是ubantu的虚拟机,大家可以自行选择自己用的习惯的
打开第一台虚拟机,创建一个conf目录,然后在这个目录下创建3个配置文件,7000.conf , 7001.conf ,7002.conf
下图中我先新建一个7000.conf文件
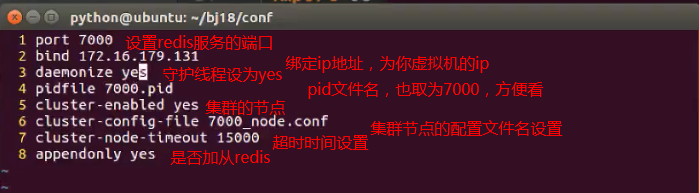
配置内容如下
然后再新建其他两个,名字就为7001.conf和7002.conf,配置内容与7000.conf差不多,就改一下端口号和以端口号命名的文件
那么这个虚拟机的redis集群的配置就弄好了
启动服务


不难看到,我们集群配置的redis服务的进程后面都有个cluster,代表节点的意思,至于图中其他端口的redis服务不用去管,是之前做主从留下的,端口并不冲突,不用理会
接下来启动另一台虚拟机,步骤与上面类似
我们再创建7003.conf ,7004.conf ,7005.conf ,创建好后按老样子进行配置

ip和端口改一下
按着这种样子把剩下两个也创建好,然后启动服务

启动好服务后回到第一台虚拟机,然后更换yum源,安装redis依赖

添加全局命令

安装ruby环境

然后通过redis-trib.rb启动集群服务

图中的 --replicas 1 指的是为节点创建从redis数据库,回车启动

他会弹出一个询问选项,输入yes就行了
然后就会弹出下面信息,就代表成功了

图中的slots:0-5460等这些表示,redis创建了三个节点,每个节点都有一个从redis,在每个主节点都会被平均分配槽值,在redis中槽值的范围在0-16383,当你插入数据时,redis会通过CRC(键)%16384这样的算法计算键所对应的槽值,然后将这条数据插入其槽值所在的数据库,读取数据时也是同理
简单介绍一下
Redis集群是一个由多个节点组成的分布式服务器群,它具有复制、高可用和分片特性;
Redis集群没有中心节点,并且带有复制和故障转移特性,这可以避免单个节点成为性能瓶颈,或者因为某个节点下线而导致整个集群下线;
集群中的主节点负责处理槽(存储数据),从节点则是主节点的复制品;
Redis集群将整个数据库分成16384个槽,数据库中的每个键都属于16384个槽中的其中一个;
集群中的每个主节点都可以负责0到16384个槽,当16384个槽都有节点在负责时,集群进入上线状态,可以执行客户端发送的数据命令;
主节点只会执行和自己负责的槽相关的命令,当节点接收到不属于自己处理的槽的命令时,它会将处理指定槽的节点的地址返回给客户端,而客户端会向正确的节点重新发送命令,这个过程称为“转向”;
Redis 集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
Redis 集群提供了以下两个好处:
将数据自动切分(split)到多个节点的能力。
当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力。

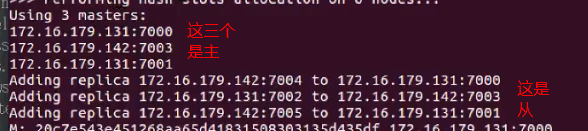

一共6个,刚刚好
集群服务启动了,接下来开始连接到集群


然后进行插入数据,取出数据的操作

上图中可以看出,他是通过键的槽值进行redis数据库选取操作的,好了,至此,redis集群的知识就给大家分享到这里了















 3797
3797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









