






MySQL作为当下最流行的RDBMS(Relational Database Management System)之一,因其性能高、成本低、成熟稳定、易维护等特点被广泛应用于互联网业务系统,是大多数公司的首选关系型数据库。而在业务系统中涉及DB SQL性能的问题,百分之九十是因为慢查询引起的,所以慢查询的优化成为了DBA一项必须掌握的重要技能。
本文试图从索引原理、索引使用、执行计划三个方面介绍慢查询优化的必要技能。
记一次新增索引需求
前几天接到这样的一个需求,开发反馈有一个SQL语句现在非常慢,提了一项加索引的需求:
ALTER TABLE resource ADD INDEX idx_comId(companyId)
ALTER TABLE resource ADD INDEX idx_cenId(centerid)
ALTER TABLE resource ADD INDEX idx_depId(departmentid)
ALTER TABLE resource ADD INDEX idx_groupId (groupid)
ALTER TABLE resource ADD INDEX idx_ctimed(createTime)
ALTER TABLE resource ADD INDEX idx_activeId(activityid)--Q:为什么要每个字段都加索引?对应的查询SQL语句是什么?
--A:查询字段都加上索引SQL查询就快了
SELECT activityName,
companyname,
companyId,
centerName
centerId,
departmentName
departmentId,
groupame.
groupId,
truename
FROM resource
WHERE createTime>'2020-01-22
11:55:18
AND companyId=13
AND
centerId = 4
AND departmentId = 17
AND groupId = 31
AND activityId='253673343079051008'--Q:表多大,各个字段的区分度是怎样的?为什么不考虑联合索引?
--A:不知所云,各种搜索中……(这个时候大多数开发同学已经蒙圈了)
这是一个真实的,并且不止一次发生在我身边的故事,同时引起了我的思考,思考怎样给大家通俗易懂的讲明白索引原理,并且通过本文告诉大家,我们该如何正确的使用索引,提高查询速度,怎样通过查看执行计划指导优化我们的SQL语句。
索引浅析
MySQL官方对索引的定义是这样的:索引(Index)是帮助MySQL高效获取数据的数据结构。
如果仅仅看索引定义的话,对于常人来讲,简直不知所云,除了知道是一种数据结构外。
为了告诉大家什么是索引,我并没有去罗列各种难懂的概念,这里,我建一张表,插入6条记录,然后通过一张图来说明什么是索引。
新建表:

插入记录,数据如下:
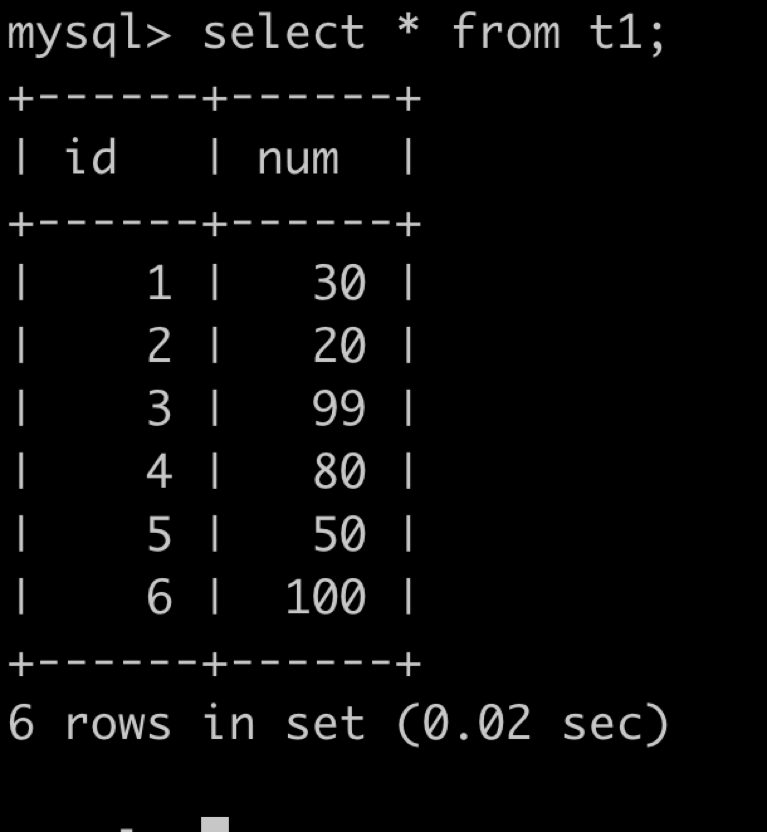
如果num字段有索引的话,那么下图右侧的圈圈就是这个索引了,一棵二叉树,索引记录指向了表中的数据。

![]() 以上是从二叉树数据结构角度描述的索引,但是实际上MySQL用的是B-Tree,那么实际的索引应该是下面这样的(假设一个数据页最多存储2条记录的话):
以上是从二叉树数据结构角度描述的索引,但是实际上MySQL用的是B-Tree,那么实际的索引应该是下面这样的(假设一个数据页最多存储2条记录的话):

通过以上内容,什么是索引应该已经比较清晰了。索引是一种数据结构,它是用有序的数据目录,快速锁定我们需要的数据,来提高查询效率的,对于一本书而言索引就是目录,对于数据库来讲,它是字段值的有序组合,并且指向了不同记录的数据结构。
SQL优化
01索引使用原则
1、优先使用覆盖索引
通过上面的内容我们知道了表数据其实就是存储在一个B-Tree上,但是这个B-Tree是根据主键组织的。那么二级索引,其实也是一棵B-Tree,不同的是叶子节点存储的不再是整条记录,而是索引数据以及主键信息,所以当使用二级索引查询数据时,是需要根据二级索引叶子节点存储的主键信息回到表里查询数据的,这个操作叫“回表”。但是如果查询的数据就是该二级索引本身,就不需要回表,所以覆盖索引的查询效率要高很多。
举个例子:
select 字段1 from 表 where 字段1='xxx';字段1是索引字段,即查询列表包含索引列
2、尽量使用全值匹配
对应所有的索引列都有具体值,快速匹配索引,索引是按顺序排列的。
3、选择数据区分度高的字段创建索引
区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。
4、索引失效几个场景
1)索引计算失效
比如ctime字段,year(ctime)>2000, 原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成ctime > ‘1999-12-31’。
2)like语句索引失效
name like '%abcd%' 全表扫描
name like 'abcd%' 索引有效
3) != 或 <> 操作符索引失效
全表扫描
4)or连接条件索引失效
5、最左匹配原则
MySQL会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如“a = 1 and b = 2 and c > 3 and d = 4”,如果建立 (a,b,c,d) 顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
6、设计索引要考虑复用性
比如索引,第二个索引就是冗余的,可以删掉
index(‘name,age’)
index(‘name’)
7、索引不是越多越好,索引维护会降低写入效率
02执行计划
讲了很多索引原则,那么对于慢SQL优化,还有一个我们离不开的利器explain。explain字段含义,如下:



在MySQL比较新的版本中,还有一个重要的字段:filetered。
filetered是优化器预测扫描行数满足条件的一个百分比,在关联查询中可使用filetered和rows综合分析SQL概况。
总结
了解了索引使用原则,明细了执行计划含义,在不考虑机器资源等外界因素影响下,那么SQL基本优化的步骤如下:
1、确定表结构,表大小,SQL实际执行时间等信息。
2、根据索引使用原则,逐一排查,按照字段区分度、最左原则、等值匹配的顺序,新增合适的索引。
3、order by limit 形式的sql语句让排序的表优先查,优先使用主键排序。
4、查看执行计划,根据explain结果是否和预期一致。
5、了解并分析业务场景,1-4可解决多数优化场景,但有时需要了解业务,修改SQL方式去解决。
6、观察结果,不符合预期继续从头分析。
大多数情况下,我们可以通过索引优化解决,少数情况我们也可以改变SQL书写方式改进,这就需要我们对索引优化原则、SQL执行计划有比较深入的理解。但是数据库层面的优化很多时候是杯水车薪的,架构层面的优化才是王道。比如加缓存、DB拆分、使用分布式数据库、关系型DB不做统计类需求、业务不做join操作等等。















 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









