







pip install xlrd

pip install xlwt

读取Excel
import xlrd #读
import xlwt #写
from xlrd import xldate_as_tuple
import datetime
# 1.打开excel文件并创建对象存储
data = xlrd.open_workbook("D:/aaa.xls")
# 2.获取文件中所有工作表的名称
result1 = data.sheet_names()
print("获取文件中所有工作表的名称:",result1)
# 3.根据工作表的名称获取里面的行列内容
table = data.sheet_by_name("aaa")
print("根据工作表的名称获取里面的行列内容:",table)
# 4.获取工作表的名称,行数,列数
name = table.name
print("获取工作表的名称:",name)
rowNum = table.nrows
print("获取工作表的行数:",rowNum)
colNum = table.ncols
print("获取工作表的列数:",colNum)
# 5.获取单元格内容的三种方式
result2 = table.cell(0,1).value
print("获取单元格内容",result2)
result3 = table.cell_value(0,1)
print("获取单元格内容",result3)
result4 = table.row(0)[1].value
print("获取单元格内容",result4)
# 6.获取单元格数据类型
result5 = table.cell(1,2).ctype
print("获取单元格数据类型:",result5)
# type(table.cell_value((0,1)))
xlrd的数据类型有:
0 empty
1 string
2 number
3 datetime
4 date
5 boolean
6 error
# 默认从excel中取出的数据打印出来会有问题:
# 数字一律按浮点型输出,日期输出成一串小数,布尔型输出0或1,所以我们必须在程序中做判断处理转换成我们想要的数据类型
# 7.获取工作表第一行的所有字段列表
result6 = table.row_values(0)
print("获取工作表第一行的所有字段列表:",result6)
封装读取函数
import xlrd
from xlrd import xldate_as_tuple
import datetime
'''
xlrd中单元格的数据类型
数字一律按浮点型输出,日期输出成一串小数,布尔型输出0或1,所以我们必须在程序中做判断处理转换
成我们想要的数据类型
0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
'''
class ExcelData():
# 初始化方法
def __init__(self, data_path, sheetname):
#定义一个属性接收文件路径
self.data_path = data_path
# 定义一个属性接收工作表名称
self.sheetname = sheetname
# 使用xlrd模块打开excel表读取数据
self.data = xlrd.open_workbook(self.data_path)
# 根据工作表的名称获取工作表中的内容(方式①)
self.table = self.data.sheet_by_name(self.sheetname)
# 根据工作表的索引获取工作表的内容(方式②)
# self.table = self.data.sheet_by_name(0)
# 获取第一行所有内容,如果括号中1就是第二行,这点跟列表索引类似
self.keys = self.table.row_values(0)
# 获取工作表的有效行数
self.rowNum = self.table.nrows
# 获取工作表的有效列数
self.colNum = self.table.ncols
# 定义一个读取excel表的方法
def readExcel(self):
# 定义一个空列表
datas = []
for i in range(1, self.rowNum): #行是从1开始
# 定义一个空字典
sheet_data = {}
for j in range(self.colNum): #列是从0开始
# 获取单元格数据类型
c_type = self.table.cell(i,j).ctype
# 获取单元格数据
c_cell = self.table.cell_value(i, j)
if c_type == 2 and c_cell % 1 == 0: # 如果是整形
c_cell = int(c_cell)
elif c_type == 3:
# 转成datetime对象
date = datetime.datetime(*xldate_as_tuple(c_cell,0))
c_cell = date.strftime('%Y/%d/%m %H:%M:%S')
elif c_type == 4:
c_cell = True if c_cell == 1 else False
sheet_data[self.keys[j]] = c_cell
# 循环每一个有效的单元格,将字段与值对应存储到字典中
# 字典的key就是excel表中每列第一行的字段
# sheet_data[self.keys[j]] = self.table.row_values(i)[j]
# 再将字典追加到列表中
datas.append(sheet_data)
# 返回从excel中获取到的数据:以列表存字典的形式返回
return datas
if __name__ == "__main__":
data_path = "D:/aaa.xls"
sheetname = "aaa"
get_data = ExcelData(data_path, sheetname)
datas = get_data.readExcel()
print(datas)
输出结果:
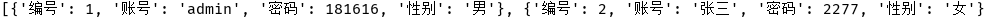
读取CSV
import csv
# with open('D://user.csv','r') as file:
# 获取每一行
print("获取每一行:")
file = open("D:/user.csv","r")
read = csv.reader(file)
for i in read:
print(i)
print("获取第一行:")
# 获取一行
file = open("D:/user.csv","r")
read = csv.reader(file)
result = list(read)
print(result[0])
print("获取第一列:",)
# 获取一列
file = open("D:/user.csv","r")
read = csv.reader(file)
for i2 in read:
print(i2[0])
输出结果:

读取XML
import xml.dom.minidom
def readXML():
dom = xml.dom.minidom.parse("./cons.xml")
rootNode = dom.documentElement #获取根目录名
# print(rootNode.nodeName)
customers = rootNode.getElementsByTagName("customer")
print("所有顾客信息:")
for customer in customers:
if customer.hasAttribute("ID"):
print("ID:",customer.getAttribute("ID"))
#name元素
name = customer.getElementsByTagName("name")[0]
print(name.nodeName,":",name.childNodes[0].data)
# phone元素
phone = customer.getElementsByTagName("phone")[0]
print(phone.nodeName, ":", phone.childNodes[0].data)
if __name__ == '__main__':
readXML()
输出结果:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









