







基于 HTTP 的功能追加协议
1. HTTP 协议的瓶颈
HTTP 虽然简单快捷,但是有一些问题。在建立 HTTP 标准规范时,制订者主要想把 HTTP 当作传输 HTML 文档的协议。随着时代的发展,Web 的用途更具多样性。
若想在现有 Web 实现所需的功能,以下这些 HTTP 标准就会成为瓶颈。
- 一条连接上只可发送一个请求。
- 请求只能从客户端开始。客户端不可以接收除响应以以外的指令。
- 请求/响应首部未经压缩就发送。首部信息越多延迟越大。
- 发送冗长的首部。每次互相发送相同的首部造成的浪费较多。
- 可任意选择数据压缩格式。非强制压缩发送。
HTTP 功能上的不足可通过创建一套全新的协议来弥补。可是目前基于 HTTP 的 Web 浏览器的使用环境已遍布全球, 因此无法完全抛弃 HTTP。有一些新协议的规则是基于 HTTP 的, 并在此基础上添加了新的功能。
2. 双工通信的 WebSocket
以前的方式
HTTP 的弊端是在于被动性,只能客户端主动发出请求。
- Ajax 轮询,每隔一段时间客户端发送 Ajax 询问有没有消息更新。
- Long Pool,使用阻塞的模型,客户端发送请求后一直等待,直到等到服务器发出 response 为止。
上面的两种方法可以看出,给服务器造成压力。
一旦 Web 服务器与客户端之间建立起 WebSocket 协议的通信连接,之后所有的通信都依靠这个专用协议进行。 通信过程中可互相发送 JSON、XML、HTML 或图片等任意格式的数据。
由于是建立在 HTTP 基础上的协议, 因此连接的发起方仍是客户端,而一旦确立 WebSocket 通信连接,不论服务器还是客户端,任意一方都可直接向对方发送报文。
WebSocket 特点:
-
推送功能
支持由服务器向客户端推送数据的推送功能。这样,服务器可直接发送数据,而不必等待客户端的请求。
-
减少通信量
只要建立起 WebSocket 连接,就希望一直保持连接状态。和 HTTP 相比,不但每次连接时的总开销减少,而且由于 WebSocket 的首部信息很小,通信量也相应减少了。
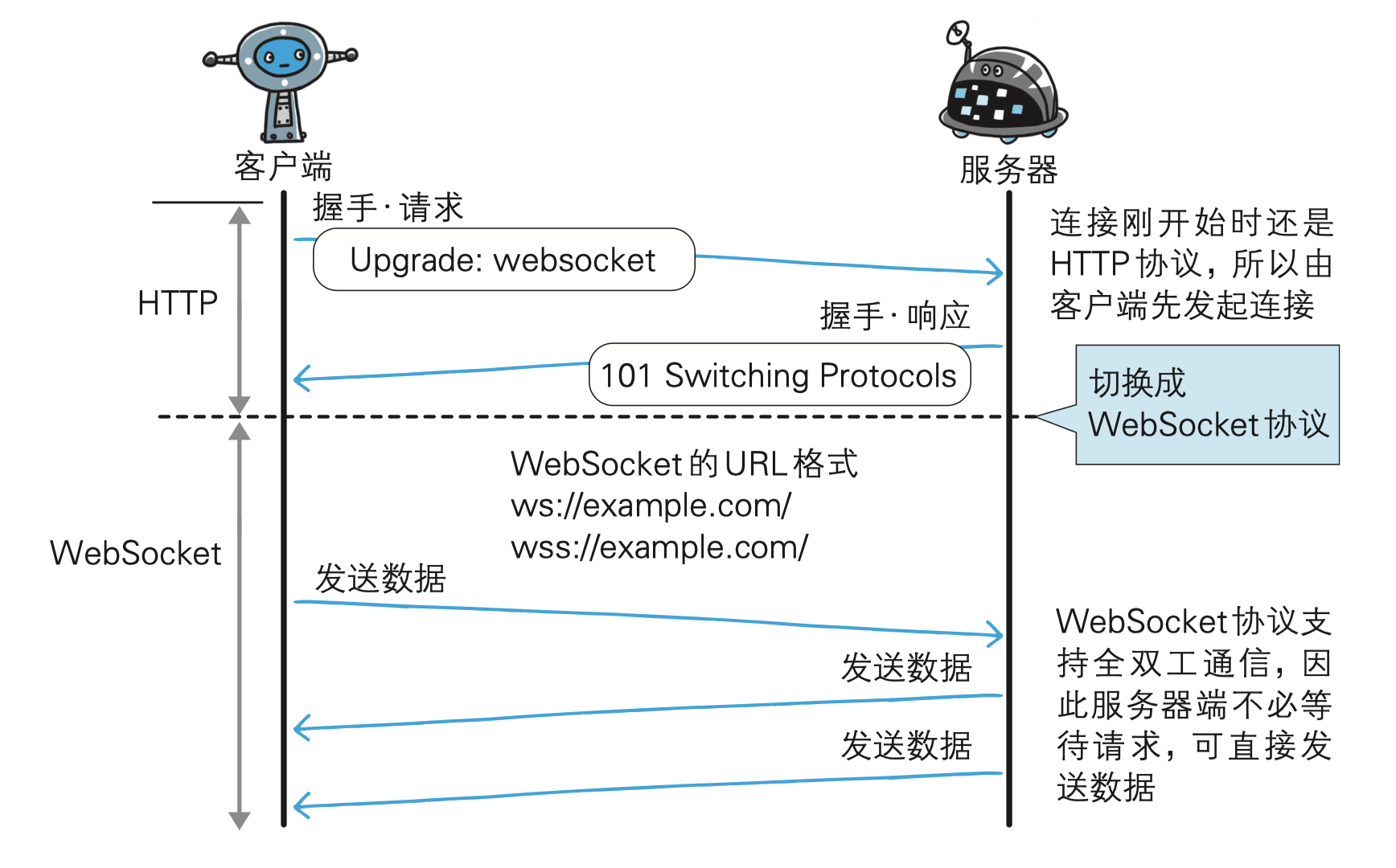
为了实现 WebSocket 通信,在 HTTP 连接建立之后,需要完成一次“握手”(Handshaking)的步骤。
握手请求
为了实现 WebSocket 通信, 需要用到 HTTP 的 Upgrade 首部字段,告知服务器通信协议发生改变,以达到握手的目的。
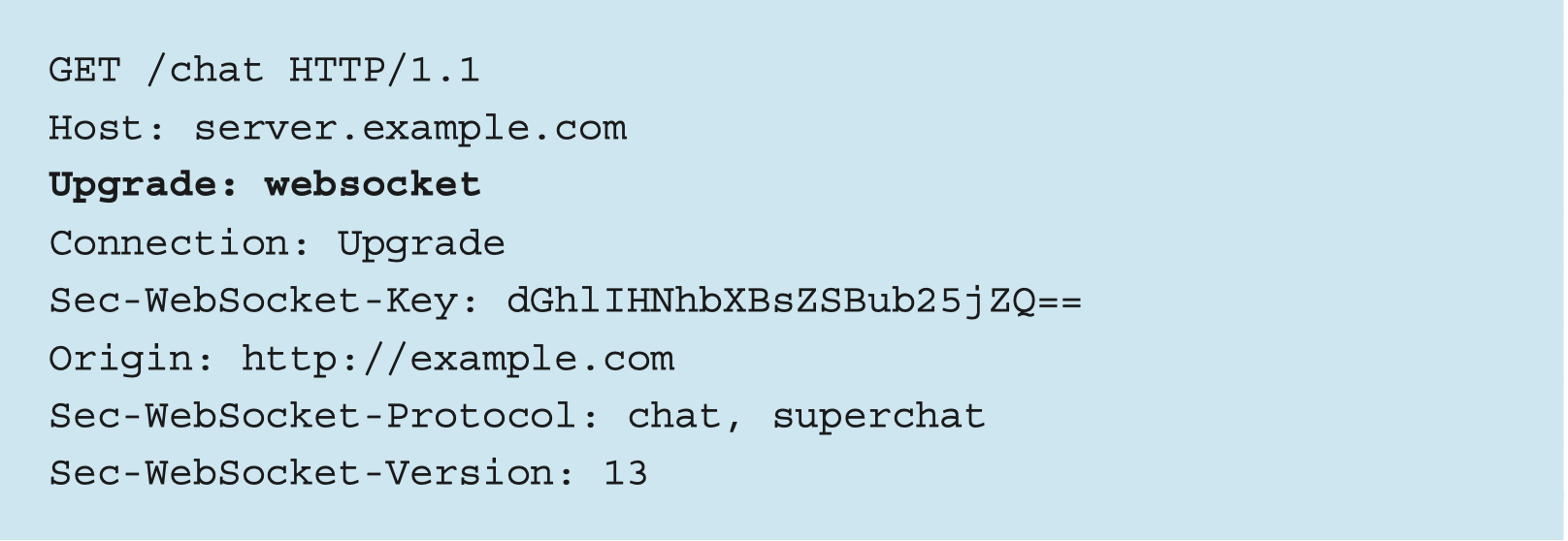
Sec-WebSocket-Key 字段内记录着握手过程中必不可少的键值。 Sec-WebSocket-Protocol 字段内记录使用的子协议。
握手响应
对于之前的请求,返回状态码 101 Switching Protocols 的响应。告诉浏览器已经切换了协议。


Sec-WebSocket-Accept 的字段值是由握手请求中的 Sec-WebSocket-Key 的字段值生成的。
成功握手确立 WebSocket 连接之后,通信时不再使用 HTTP 的数据帧,而采用 WebSocket 独立的数据帧。
3. 消除 HTTP 瓶颈的 SPDY
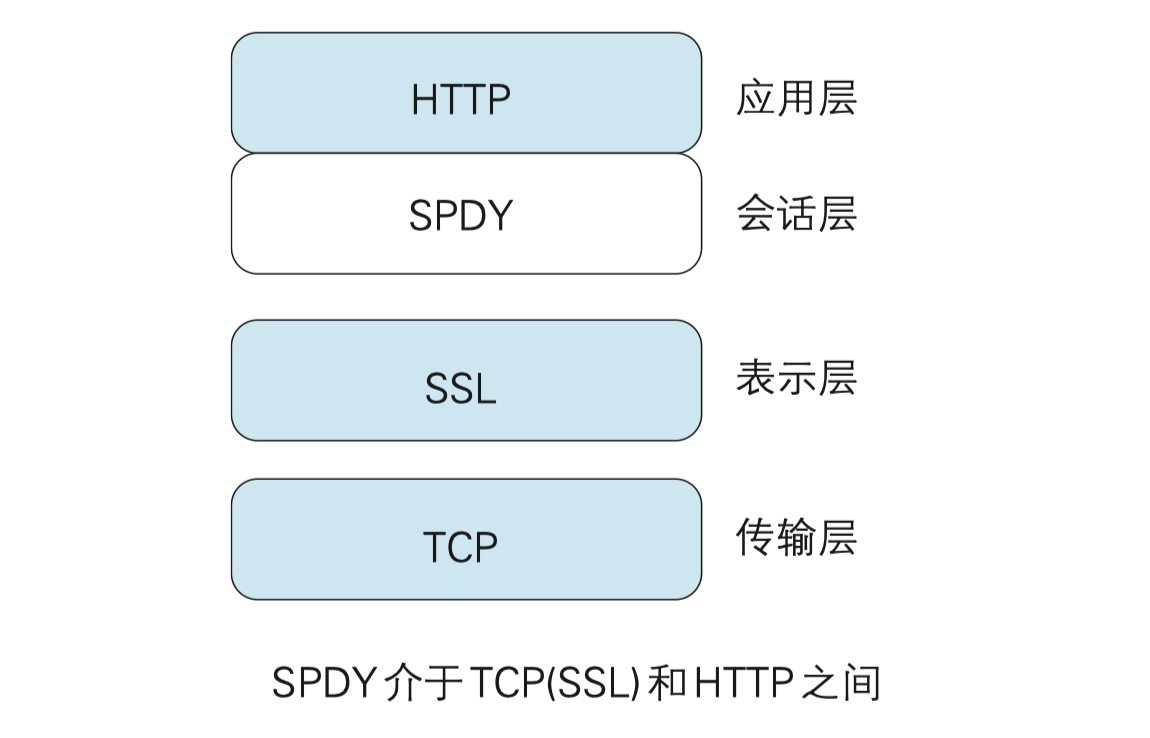
SPDY 没有完全改写 HTTP 协议, 而是在 TCP/IP 的应用层与运输层之间通过新加会话层的形式运作。同时,考虑到安全性问题,SPDY 规定通信中使用 SSL。
SPDY 以会话层的形式加入, 控制对数据的流动, 但还是采用 HTTP 建立通信连接。 因此, 可照常使用 HTTP 的 GET 和 POST 等方法、Cookie 以及 HTTP 报文等。
HTTP 缺陷
- 单路连接,请求低效
- HTTP 只允许由客户端主动发起请求
- HTTP 头部冗余
SPDY 的改进
-
多路复用流
通过单一的 TCP 连接, 可以无限制处理多个 HTTP 请求。 所有请求的处理都在一条 TCP 连接上完成,因此 TCP 的处理效率得到提高。
-
赋予请求优先级
SPDY 不仅可以无限制地并发处理请求,还可以给请求逐个分配优先级顺序。
可以选择性地先传输关键的资源。
这样主要是为了在发送多个请求时,解决因带宽低而导致响应变慢的问题。
-
推送功能
支持服务器主动向客户端推送数据的功能。这样,服务器可直接发送数据,而不必等待客户端的请求。
-
压缩 HTTP 首部
压缩 HTTP 请求和响应的首部。这样一来,通信产生的数据包数量和发送的字节数就更少了。
-
服务器提示功能
客户端给服务器发送请求时,一般就是要获取资源了。
服务器可以主动提示客户端请求所需的资源。由于在客户端发现资源之前就可以获知资源的存在,因此在资源已缓存等情况下,可以避免发送不必要的请求。
-
强制使用 SSL 传输协议
web 发展方向是安全的网络连接
SPDY 的意义
普通用户:访问速度变快,提高安全性保密性
前端人员:请求顺序根据优先级重新编排,避免图片请求带来的问题
运维人员:降低连接数目,服务器占用资源减少,从而释放出更多内存和 CPU,提升浏览速度
但是还没推广开来,就被 HTTP2.0 给取代了。但是 HTTP2.0 和 SPDY 有很多的相似之处。
4. 期盼已久的 HTTP/2.0
4.1 HTTP2.0 性能增强的核心:二进制分帧
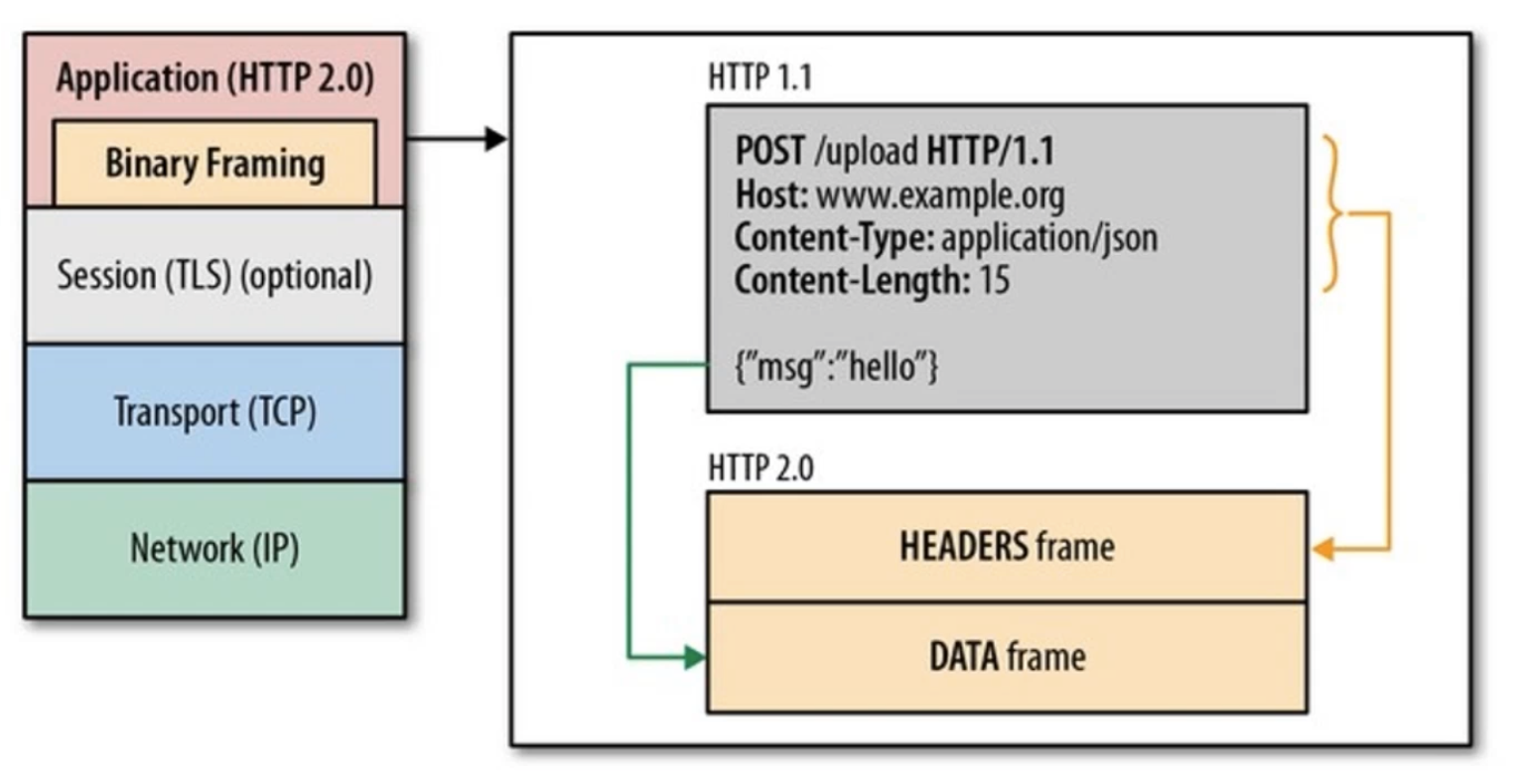
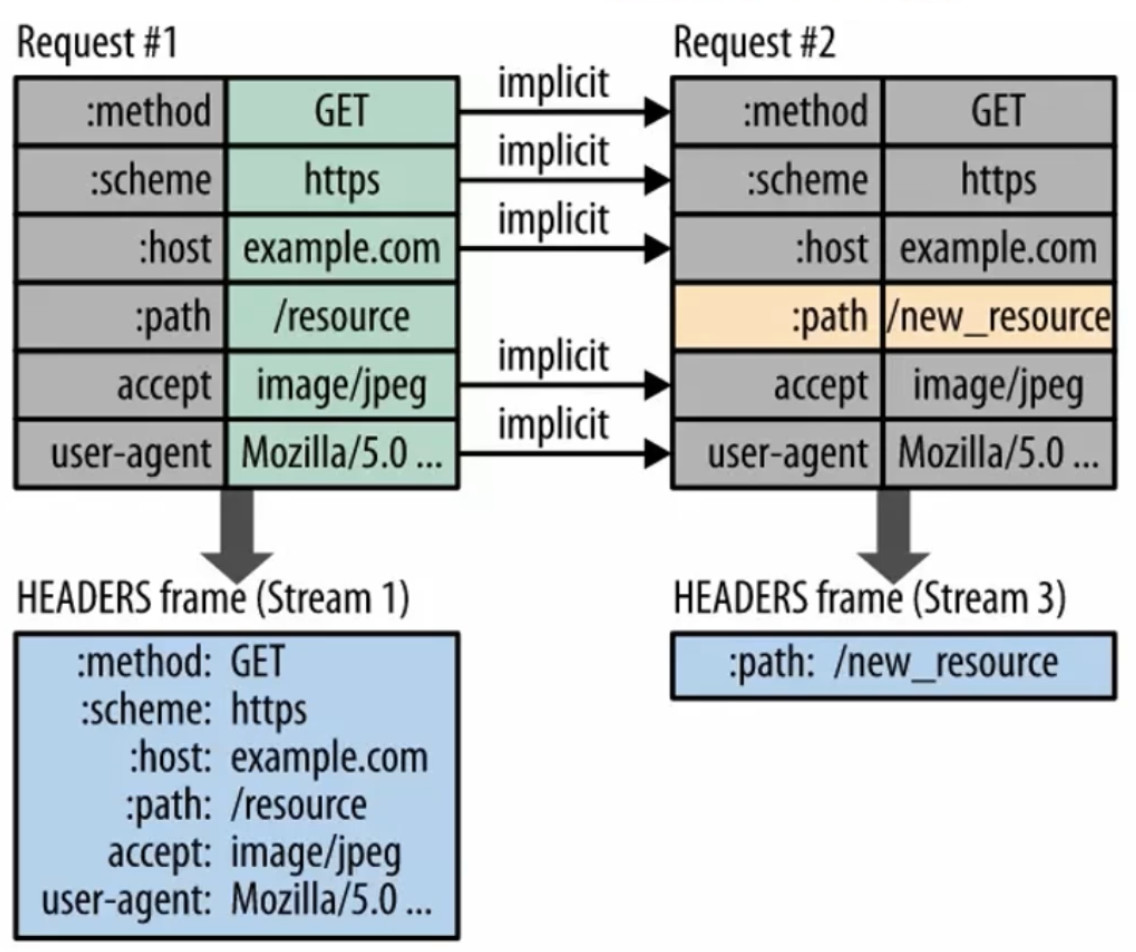
HTTP/2 厉害的地⽅在于将 HTTP/1 的⽂本格式改成⼆进制格式传输数据,极⼤提⾼了 HTTP 传输效率,⽽且⼆进制数据使⽤位运算能⾼效解析。
HTTP/2 把响应报⽂划分成了两个帧(Frame),图中的 HEADERS(⾸部)和 DATA(消息负载) 是帧的类型,也就是说⼀条 HTTP 响应,划分成了两个帧来传输,并且采⽤⼆进制来编码。
4.2 HTTP2.0 首部压缩
HTTP 协议的报⽂是由「Header + Body」构成的,对于 Body 部分,HTTP/1.1 协议可以使⽤头字段 「Content Encoding」指定 Body 的压缩⽅式,⽐如⽤ gzip 压缩,这样可以节约带宽,但报⽂中的另外⼀部分 Header,是没有针对它的优化⼿段。
HTTP/1.1 报⽂中 Header 部分存在的问题:
- 含很多固定的字段,⽐如Cookie、User Agent、Accept 等,这些字段加起来也⾼达⼏百字节甚⾄上千字节,所以有必要压缩;
- 大量的请求和响应的报⽂⾥有很多字段值都是重复的,这样会使得大量带宽被这些冗余的数据占⽤了,所以有必须要避免重复性;
- 字段是 ASCII 编码的,虽然易于⼈类观察,但效率低,所以有必要改成⼆进制编码;
HTTP/2 对 Header 部分做了⼤改造,把以上的问题都解决了。
HTTP/2 没使⽤常⻅的 gzip 压缩⽅式来压缩头部,⽽是开发了 HPACK 算法,HPACK 算法主要包含三个组成部分:
- 静态字典;
- 动态字典;
- Huffman 编码(压缩算法);
客户端和服务器两端都会建⽴和维护「字典」,⽤⻓度较⼩的索引号表示重复的字符串,再⽤ Huffman 编码压缩数据,可达到 50%~90% 的⾼压缩率。
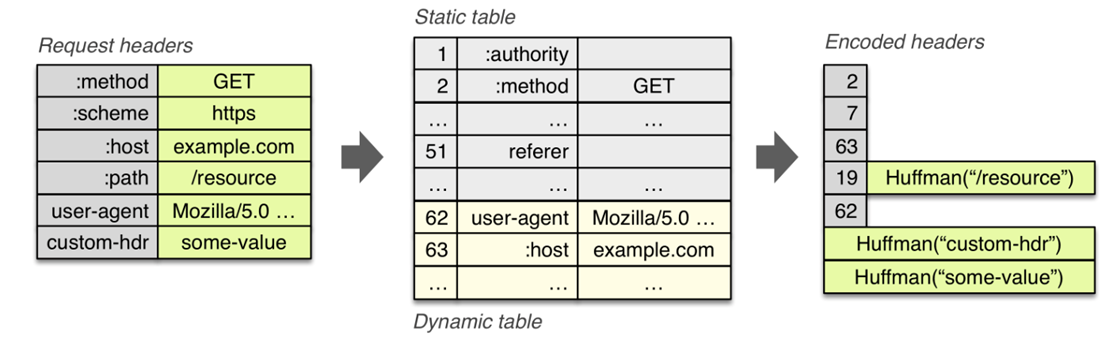
静态表编码
HTTP/2 为⾼频出现在头部的字符串和字段建⽴了⼀张静态表,它是写⼊到 HTTP/2 框架⾥的,不会发生改变;
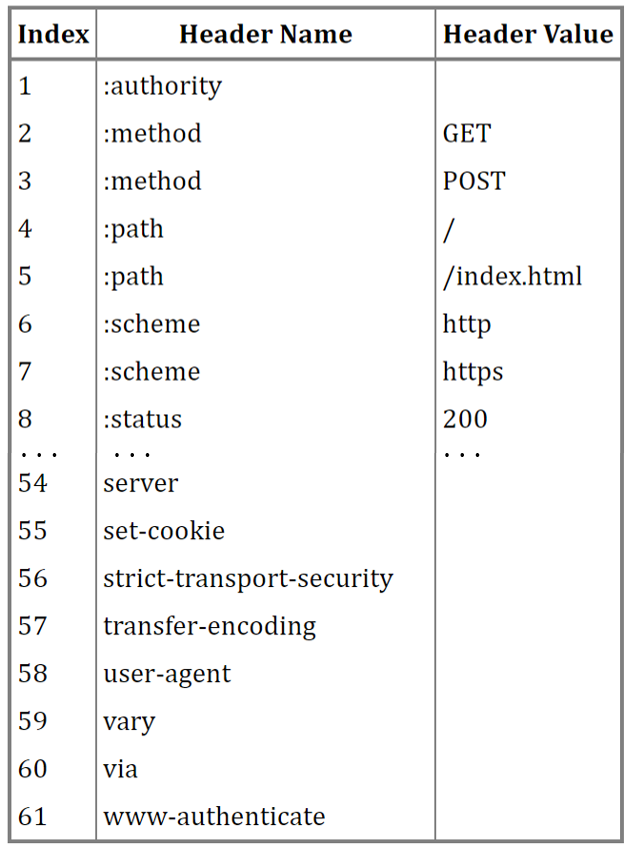
表中的 Index 表示索引(Key), Header Value 表示索引对应的 Value, Header Name 表示字段的名字,⽐如 Index 为 2 代表 GET,Index 为 8 代表状态码 200。
这样一来,加上规定里的,静态表里的 index 头部前两位为 01,表示响应头的 key 只要一个字节就能解决。
第二个字节,首个比特位表示 value 是否经过 Huffman 编码,剩下的比特位表示 value 所需要的字节长度。如 10000110,表示经过 Huffman 编码,并且编码后 value 的长度为 6 个字节。
HTTP/2 头部由于基于⼆进制编码,就不需要冒号空格和末尾的\r\n 作为分隔符,于是改⽤表示字符串⻓度(Value Length)来分割 Index 和 Value。
Huffman 编码的原理是将⾼频出现的信息⽤「较短」的编码表示,从⽽缩减字符串⻓度。静态 Huffman 表里有原字符所对应的 Huffman 编码。
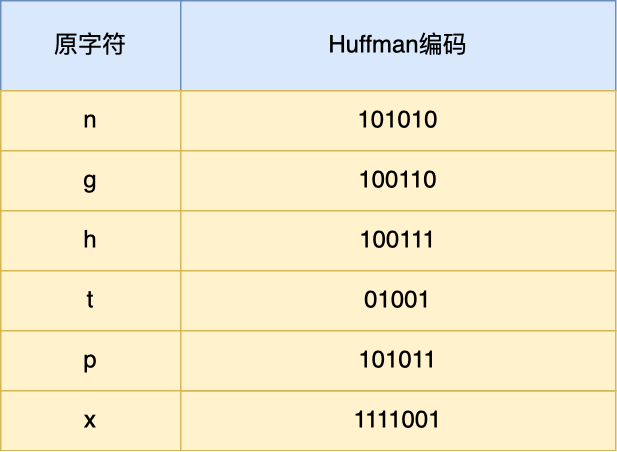

最终, server 头部的⼆进制数据对应的静态头部格式如下:
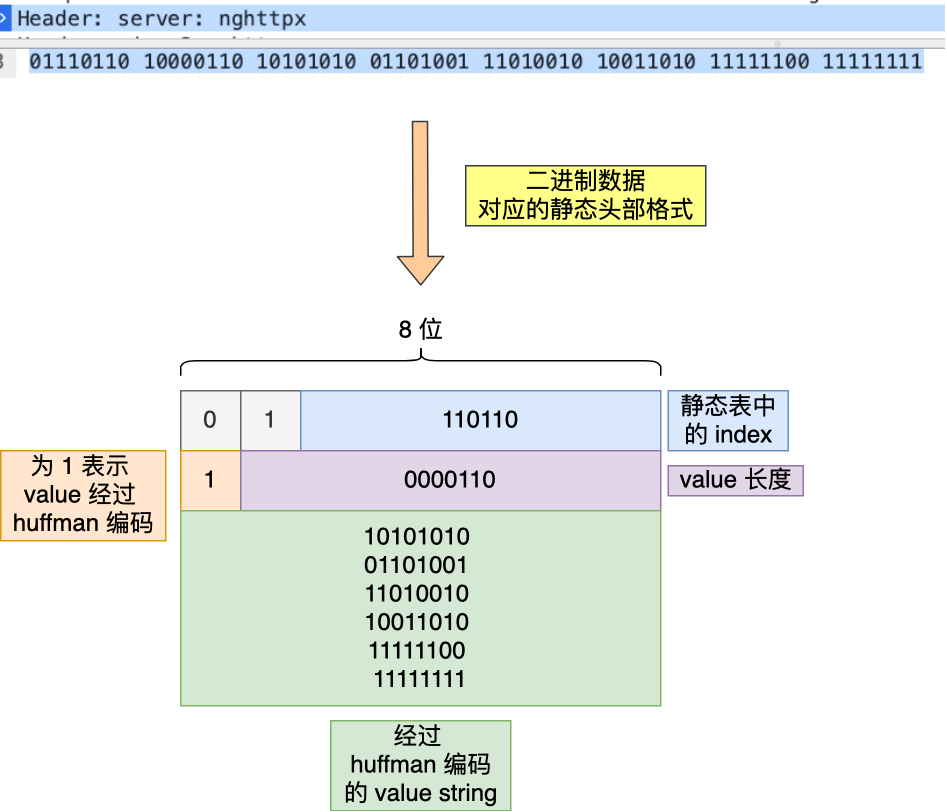
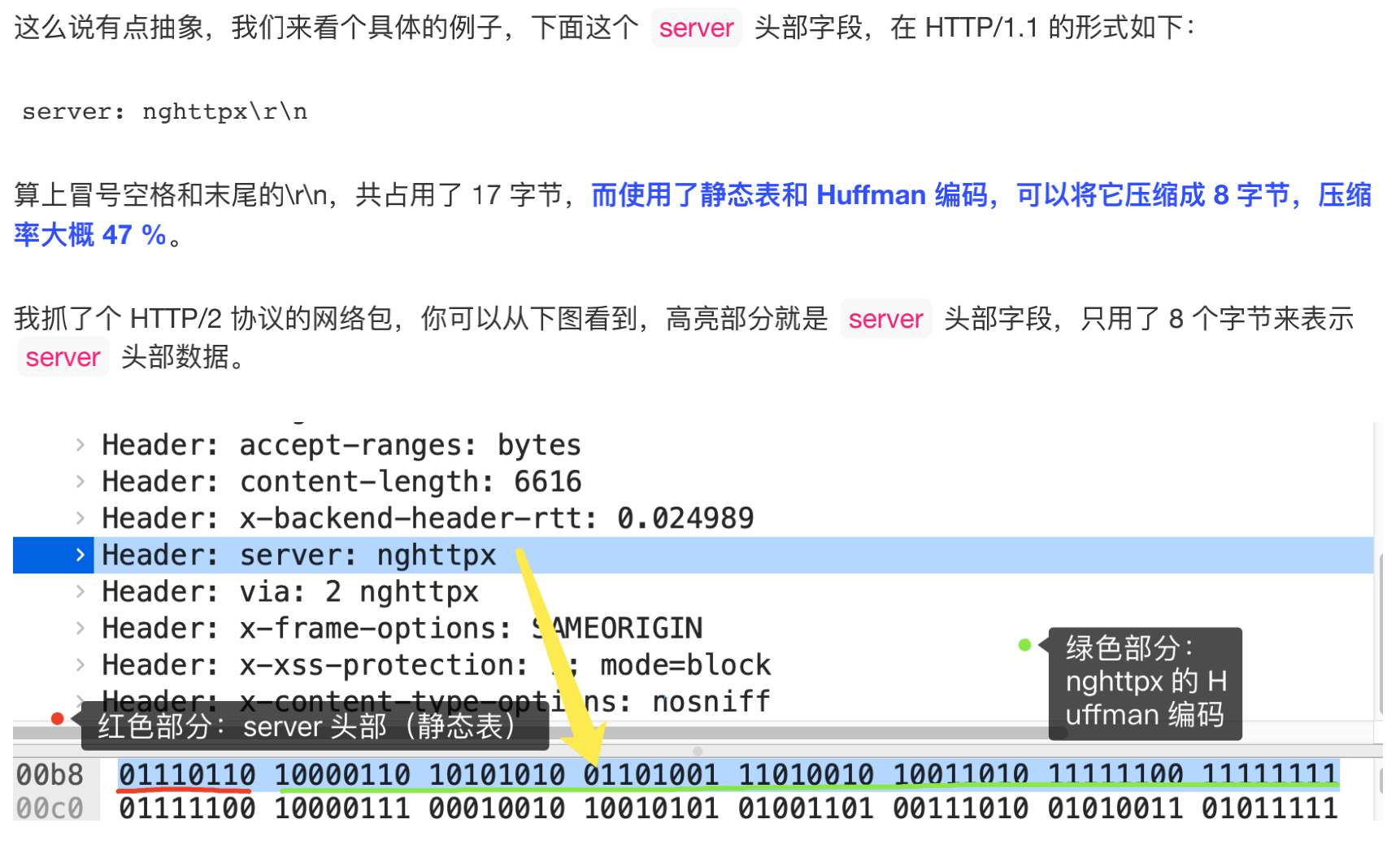
动态表编码
静态表只包含了 61 种⾼频出现在头部的字符串,不在静态表范围内的头部字符串就要⾃⾏构建动态表,它的 Index 从 62 起步,会在编码解码的时候随时更新。
⽐如,第⼀次发送时头部中的「 user-agent 」字段数据有上百个字节,经过 Huffman 编码发送出去后,客户端和服务器双⽅都会更新⾃⼰的动态表,添加⼀个新的 Index 号 62。那么在下⼀次发送的时候,就不⽤重复发这个字段的数据了,只⽤发 1 个字节的 Index 号就好了,因为双⽅都可以根据⾃⼰的动态表获取到字段的数据。
所以,使得动态表⽣效有⼀个前提:必须同⼀个连接上,重复传输完全相同的 HTTP 头部。如果消息字段在 1 个连接上只发送了 1 次,或者重复传输时,字段总是略有变化,动态表就⽆法被充分利⽤了。
因此,随着在同⼀ HTTP/2 连接上发送的报⽂越来越多,客户端和服务器双⽅的「字典」积累的越来越多,理论上最终每个头部字段都会变成 1 个字节的 Index,这样便避免了大量的冗余数据的传输,⼤⼤节约了带宽。
动态表越⼤,占⽤的内存也就越⼤,如果占⽤了太多内存,是会影响服务器性能的,因此 Web 服务器都会提供类似 http2_max_requests 的配置,⽤于限制⼀个连接上能够传输的请求数量,避免动态表⽆限增⼤,请求数量到达上限后,就会关闭 HTTP/2 连接来释放内存。
综上,HTTP/2 头部的编码通过「静态表、动态表、Huffman 编码」共同完成的。
4.3 并发传输
HTTP/1.1 的实现是基于请求-响应模型的。同⼀个连接中,HTTP 完成⼀个事务(请求与响应),才能处理下⼀个事务,也就是说在发出请求等待响应的过程中,是没办法做其他事情的,如果响应迟迟不来,那么后续的请求是⽆法发送的,也造成了队头阻塞的问题。
⽽ HTTP/2 就很⽜逼了,通过 Stream 这个设计,多个 Stream 复⽤⼀条 TCP 连接,达到并发的效果,解决了HTTP/1.1 队头阻塞的问题,提⾼了 HTTP 传输的吞吐量。
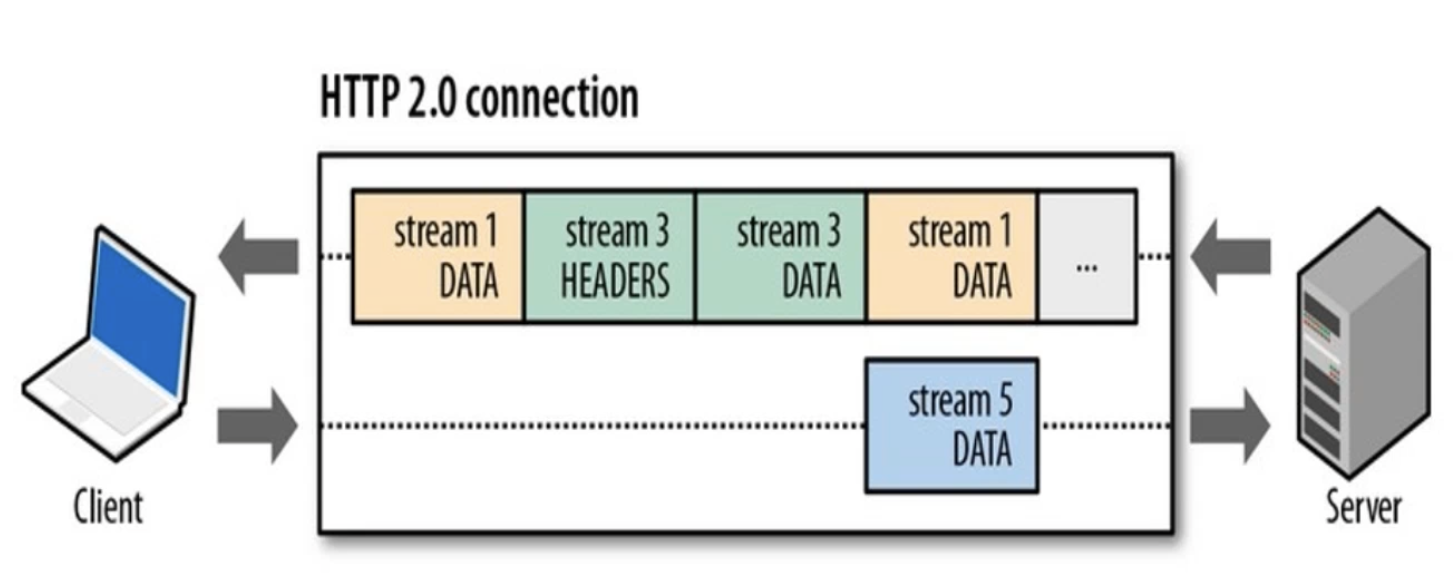
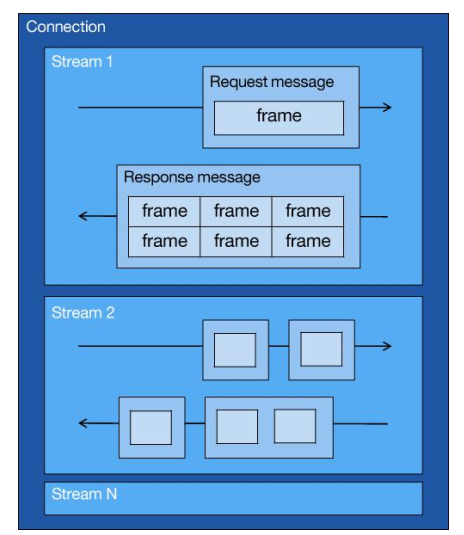
从上图中可以看到:
- 1 个 TCP 连接包含⼀个或者多个 Stream,Stream 是 HTTP/2 并发的关键技术;
- Stream ⾥可以包含 1 个或多个 Message,Message 对应 HTTP/1 中的请求或响应,由 HTTP 头部和包体构成;
- Message ⾥包含⼀条或者多个 Frame,Frame 是 HTTP/2 最⼩单位,以⼆进制压缩格式存放 HTTP/1 中的内容(头部和包体);
因此,我们可以得出 2 个结论:HTTP 消息可以由多个 Frame 构成,以及 1 个 Frame 可以由多个 TCP 报⽂构成。
在 HTTP/2 连接上,不同 Stream 的帧是可以乱序发送的(因此可以并发不同的 Stream ),因为每个帧的头部会
携带 Stream ID 信息,所以接收端可以通过 Stream ID 有序组装成 HTTP 消息,⽽同⼀ Stream 内部的帧必须是严格有序的。
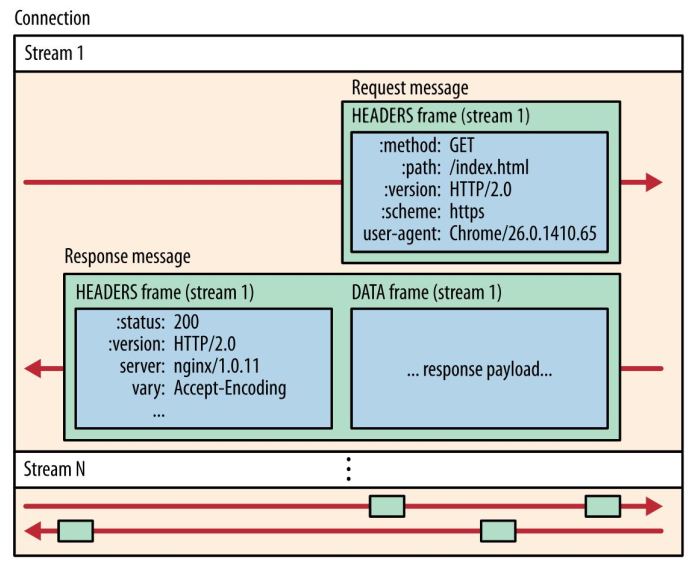
客户端和服务器双⽅都可以建⽴ Stream, Stream ID 也是有区别的,客户端建⽴的 Stream 必须是奇数号,⽽服务器建⽴的 Stream 必须是偶数号。
同⼀个连接中的 Stream ID 是不能复⽤的,只能顺序递增,所以当 Stream ID 耗尽时,需要发⼀个控制帧 GOAWAY ,⽤来关闭 TCP 连接。
在 Nginx 中,可以通过 http2_max_concurrent_streams 配置来设置 Stream 的上限,默认是 128 个。
HTTP/2 通过 Stream 实现的并发,⽐ HTTP/1.1 通过 TCP 连接实现并发要⽜逼的多,因为当 HTTP/2 实现 100 个并发 Stream 时,只需要建⽴⼀次 TCP 连接,⽽ HTTP/1.1 需要建⽴ 100 个 TCP 连接,每个 TCP 连接都要经过TCP 握⼿、慢启动以及 TLS 握⼿过程,这些都是很耗时的。
HTTP/2 还可以对每个 Stream 设置不同优先级,帧头中的「标志位」可以设置优先级,⽐如客户端访问HTML/CSS 和图⽚资源时,希望服务器先传递 HTML/CSS,再传图⽚,那么就可以通过设置 Stream 的优先级来实现,以此提⾼⽤户体验。
总结:单链接多资源的优势
- 可以减少服务链接压力,内存占用少了,连接吞吐量大了。
- 由于 TCP 连接减少而使网络拥塞情况得以改观。
- 慢启动时间减少,拥塞和丢包恢复速度更快。
总结:并行双向字节流请求和响应
- 并行交错地发送请求,请求之间互不影响。
- 并行交错地发送响应,响应之间互不干扰。
- 只使用一个连接即可并行发送多个请求和响应。
总结:请求优先级
- 高优先级的流都应该优先发送。
- 优先级不是绝对的。
- 不同优先级混合也是必须的。
5. 管理 WEB 服务器文件的 WebDAV
WebDAV(Web-based Distributed Authoring and Versioning, 基于万维网的分布式创作和版本控制)是一个可对 Web 服务器上的内容直接进行文件复制、编辑等操作的分布式文件系统。
除了创建、删除文件等基本功能,它还具备文件创建者管理、文件编辑过程中禁止其他用户内容覆盖的加锁功能,以及对文件内容修改的版本控制功能。
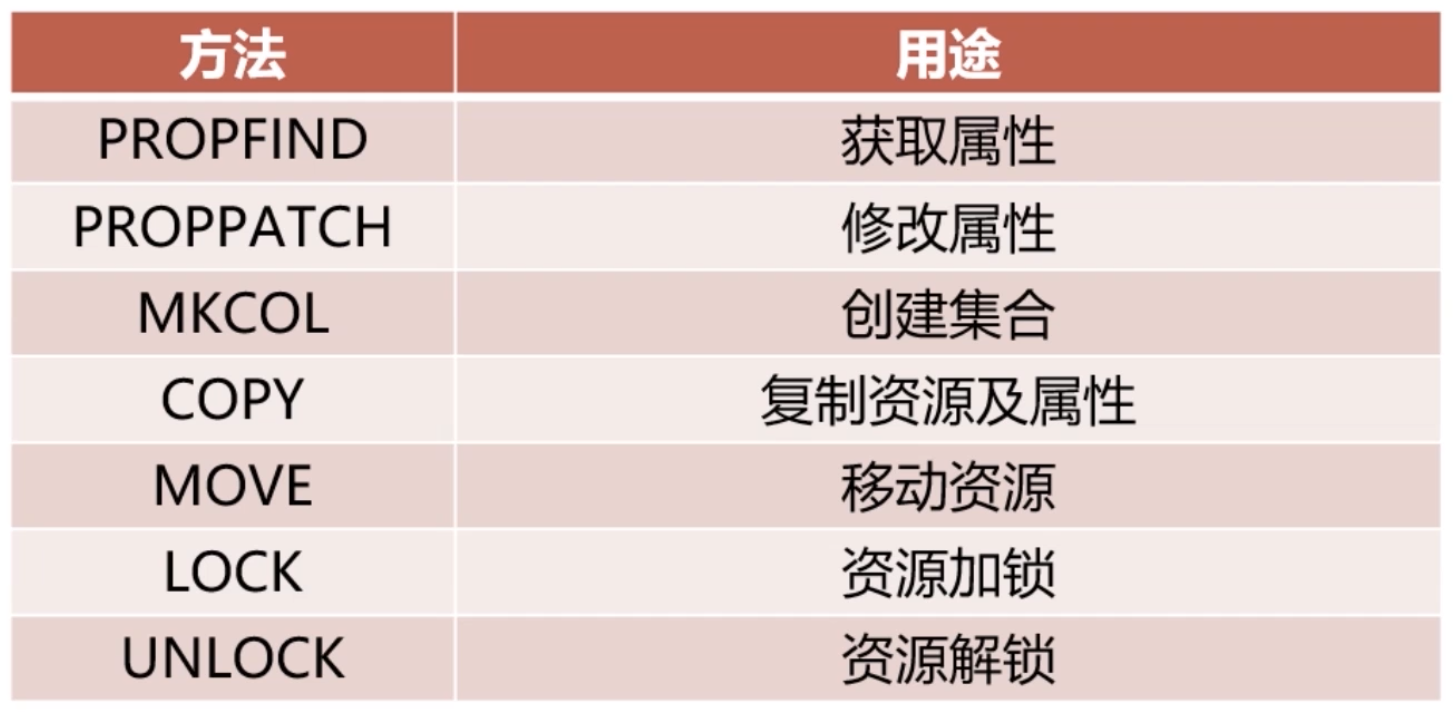
WebDAV 追加方法
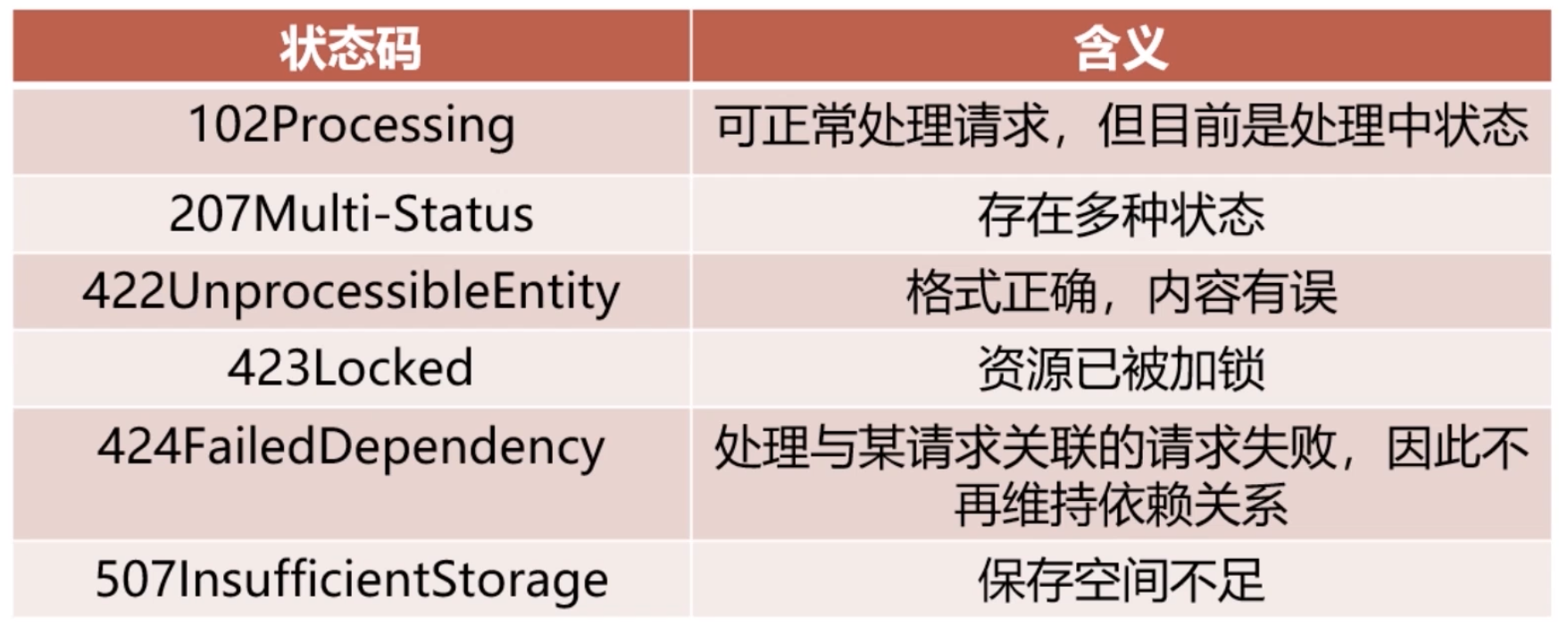
WebDAV 新增状态码
WebDAV 请求实例

xml 编码里使用 namespace 来设置属性,urn 来识别 namespace
WebDAV 响应实例
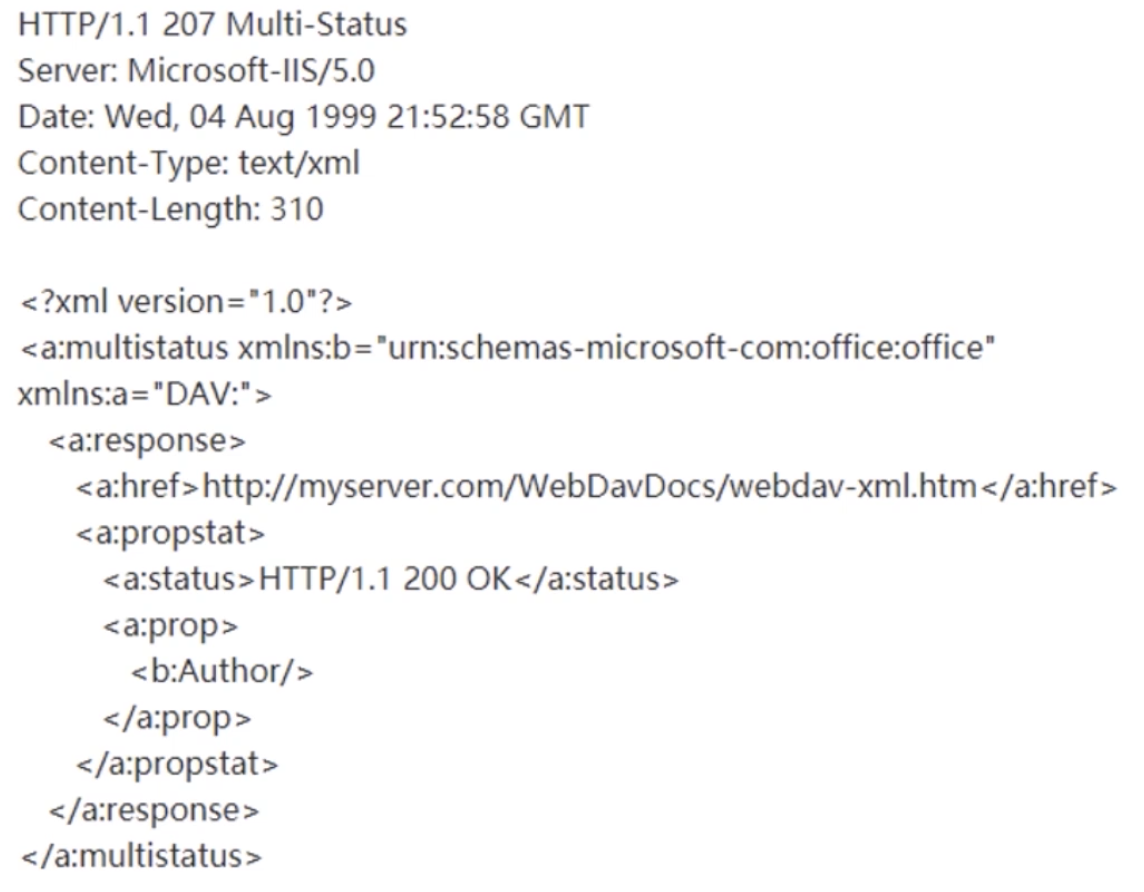
因为几乎可以被 FTP 给替代,因此使用 WebDAV 的需求并不强烈。
6. QUIC 与 HTTP/3.0
HTTP3.0 以 QUIC 为基础。针对移动互联网和 HTTP2.0 带来的历史遗留问题进行改进。
HTTP2.0 的问题
- 队头阻塞,多路复用的时候,可能出现丢包会导致整个 TCP 等待重传,反而效果比 HTTP/1 差。
- 建立连接的握手延迟大。TCP 握手后还得 TLS 四次握手。
QUIC 的特性
QUIC (Quick UDP Internet Connections) ,基于 UDP 连接,客户端发出 UDP 数据包后,只能“假设”这个数据包已经被服务端接收。这样的好处是在网络传输层无需对数据包进行确认,但存在的问题就是为了确保数据传输的可靠性,应用层协议需要自己完成包传输情况的确认。
-
利用缓存,显著减少连接建立时间;
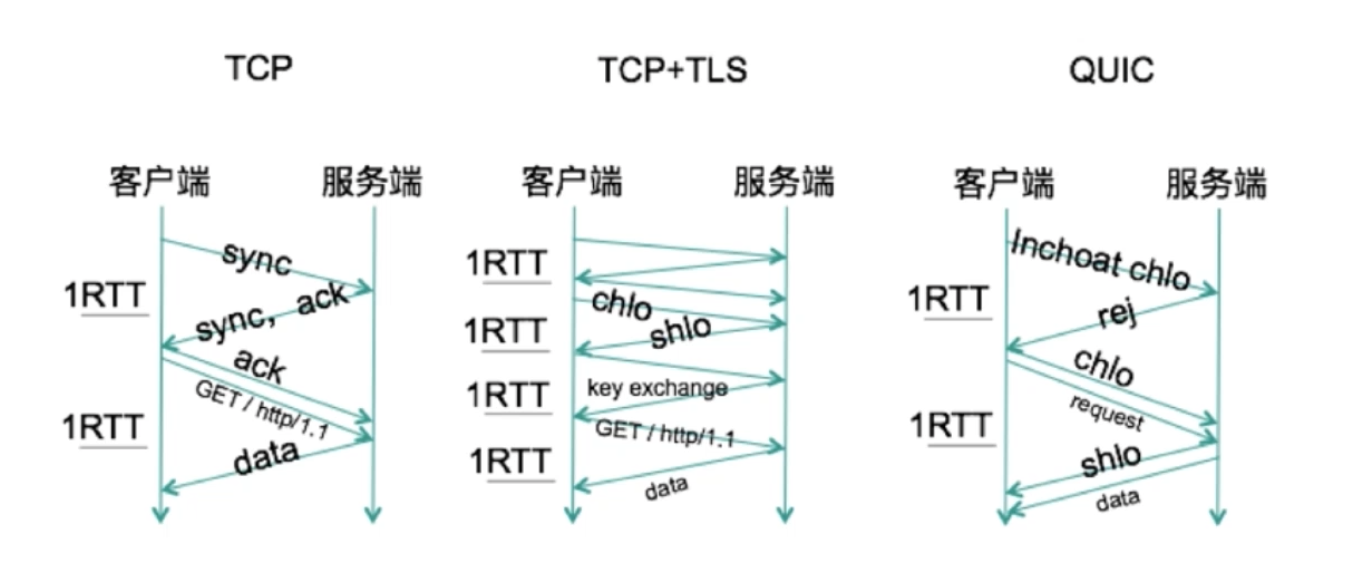
-
改善拥塞控制,拥塞控制从内核空间到用户空间;
-
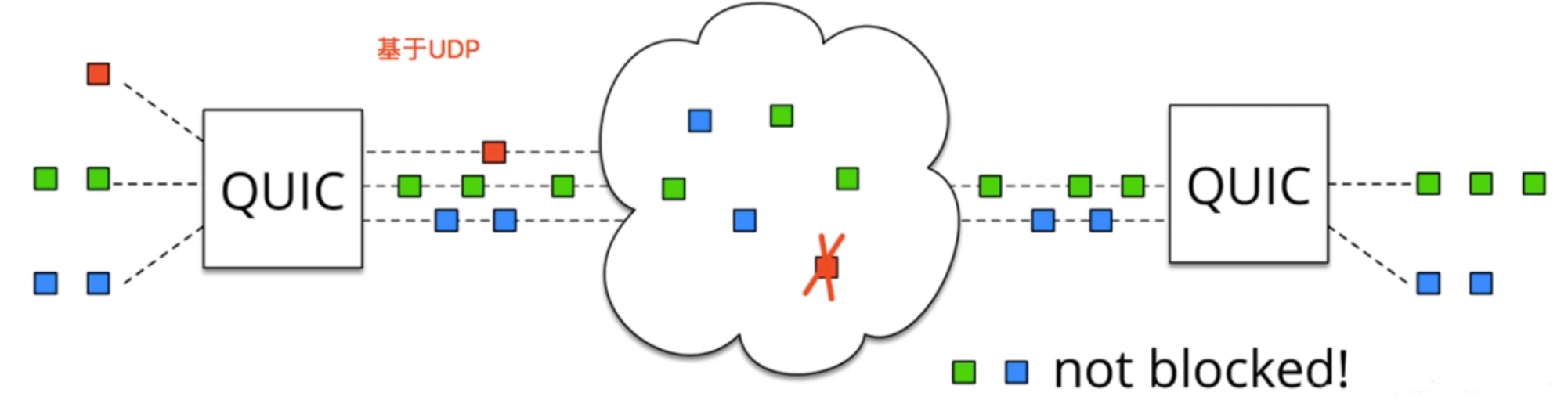
没有 head of line 阻塞的多路复用;
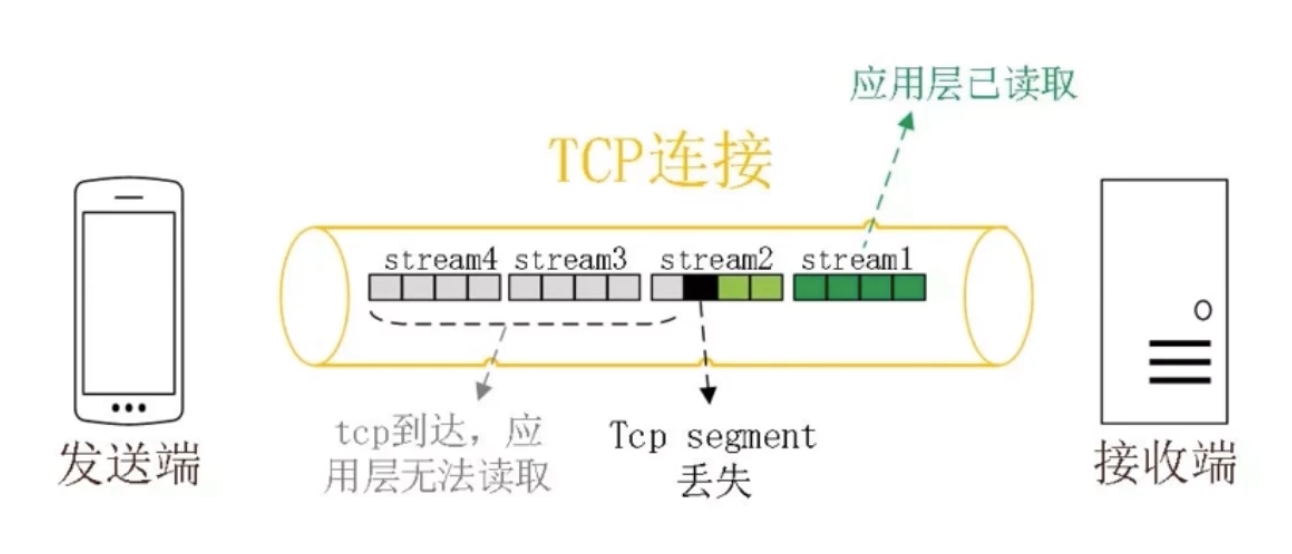
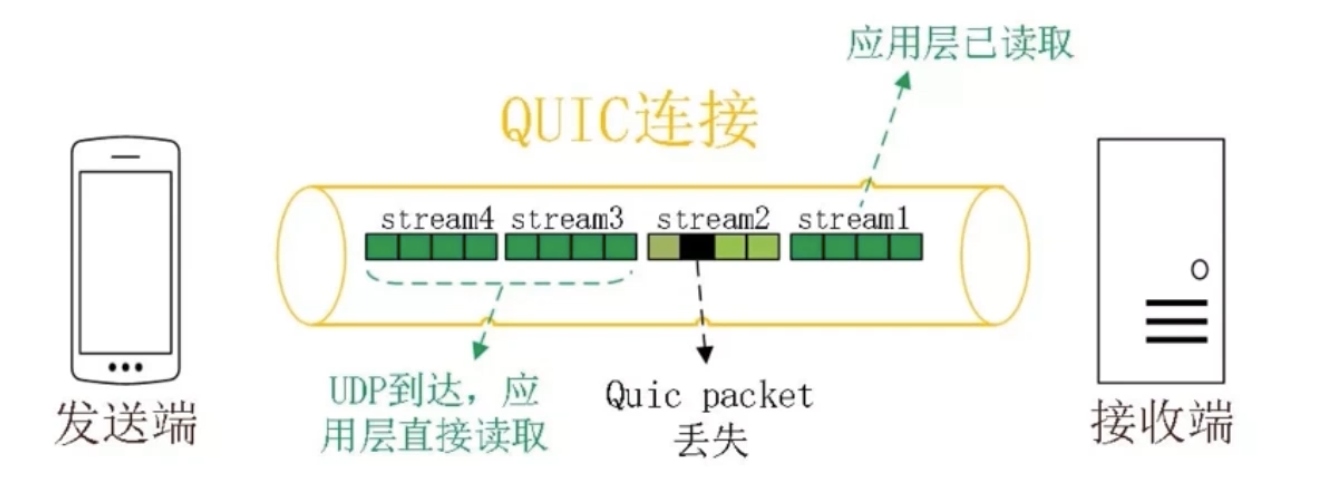
基于 UDP,就不会阻塞后面的数据传输。
-
前向纠错,减少重传;
每个包除了本身,还有部分其他包的内容,如果发生少量丢包可以通过其他包的冗余数据直接组装而不用重传。前提:只适用于丢失一个包的情况。
-
连接平滑迁移,网络状态的变更不会影响连接断线。
7. TCP与UDP的区别
TCP(Transmission Control Protocol,传输控制协议)是基于连接的协议,也就是说,在正式收发数据前,必须和对方建立可靠的连接。一个TCP连接必须要经过三次“对话”才能建立起来。
UDP(User Data Protocol,用户数据报协议)是与TCP相对应的协议。它是面向非连接的协议,它不与对方建立连接,而是直接就把数据包发送过去,UDP适用于一次只传送少量数据、对可靠性要求不高的应用环境。















 2468
2468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









