






来源
原文链接:Learning to See in the Dark
代码地址:PyTorch实现,TensorFlow实现
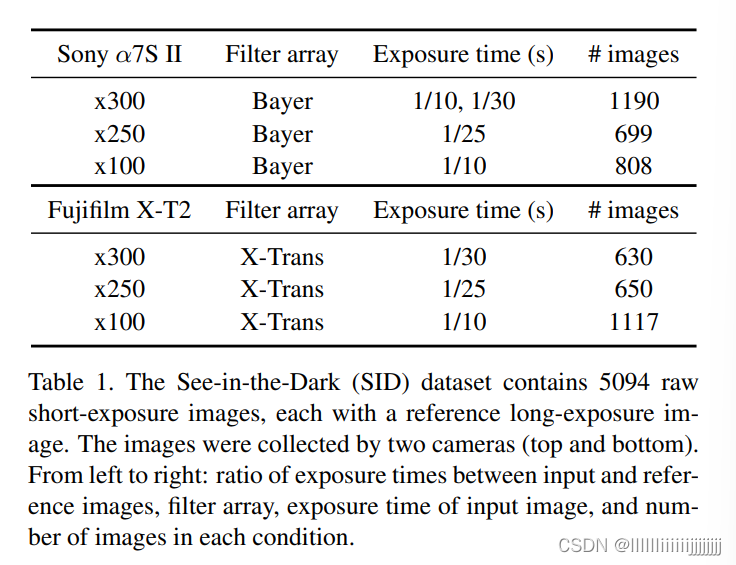
数据集:SID
1:概述
弱光成像面临着亮度低和信噪比小等问题。使用短曝光图像受到噪声的影响,而长曝光导致图像中出现模糊,在实际中不可用。在文章中,作者使用数据驱动的方式提出了一种新的图像处理pipeline。具体的,作者训练一个深度神经网络去学习颜色转换、去马赛克、噪声压制、图像增强等传统的RAW域图片的处理流程。作者首先构建了一个包含若干组短曝光RAW图和其对应长曝光图像的数据集,然后使用短曝光RAW图和对应的长曝光图像训练一个Unet网络来将弱光拍摄的RAW域图像映射到正常的RGB图像。通过端到端的训练获得的基于神经网络的处理链路能够避免噪声放大和误差积累等传统相机处理流程中存在的问题。

作者通过实验证明,提出的方法能够在完成噪声压制和色彩校正的基础上对弱光拍摄图片实现300倍的放大。作者将提出的方法与传统的isp链路处理的结果,burst处理的结果进行了对比,发现文中提出的方法具有很大的优势,而且作者使用神经网络直接将RAW域图像映射到了RGB图像,中间没有经过任何ISP处理链路,
2:原理
2.1:数据集构建
作者收集了5094个短曝光RAW图片,每一个都有对应的长曝光图片作为标签,其中多个短曝光图片可以对应同一个长曝光图片,能被用来做burst去噪测试。这个数据集包含indoor和outdoor两种类型,其中outdoor一般在夜晚月光或者街灯下拍摄。outdoor图片的亮度一般在0.2lux和5lux之间,而indoor图片一般在0.03lux到0.3lux之间。短曝光的曝光时间一般在1/30到1/10s之间,对应的参考图片一般在10到30s之间。数据集具体的信息如表1所示。在拍摄过程中用到了两类相机:Sony α7S II和Fujifilm X-T2。这两个相机具有不同的传感器:Sony相机是全帧bayer sensor,而Fuji相机则是APS-C X-Trans sensor。两个相机拍摄的图片的分辨率也不一样,Sony是42402832,而Fuji则是60004000。在拍摄过程中,光圈、ISO、对焦、焦距等都被调节来实现最好的参考图像质量。而且,作者使用手机在远程来控制相机的参数进而减少了相机的抖动。虽然采集到的长曝光图片中仍然有噪声,但其感官质量已经充分高,可以被用来作为标签数据。
2.2 弱光增强原理
从成像传感器中获得RAW图片后,传统的处理流程通过应用白平衡、去马赛克、去噪、锐化、颜色空间转换、伽马校正等一系列模块来对RAW图片进行处理,这些模块通常需要为特定的相机而进行调节。Jiang等人提出可以使用一些局部的线性可学习滤波器(L3)来近似这些在成像系统中广泛使用的非线性处理流程。但是由于无法处理极低的信噪比,无论是传统的方法还是L3都无法成功处理快速拍摄的弱光图片。Hasinoff等人介绍了一种用于智能手机的burst成像pipeline。这个方法通过对齐和融合多个图片能够得到很好的结果,但是实现流程较为复杂。
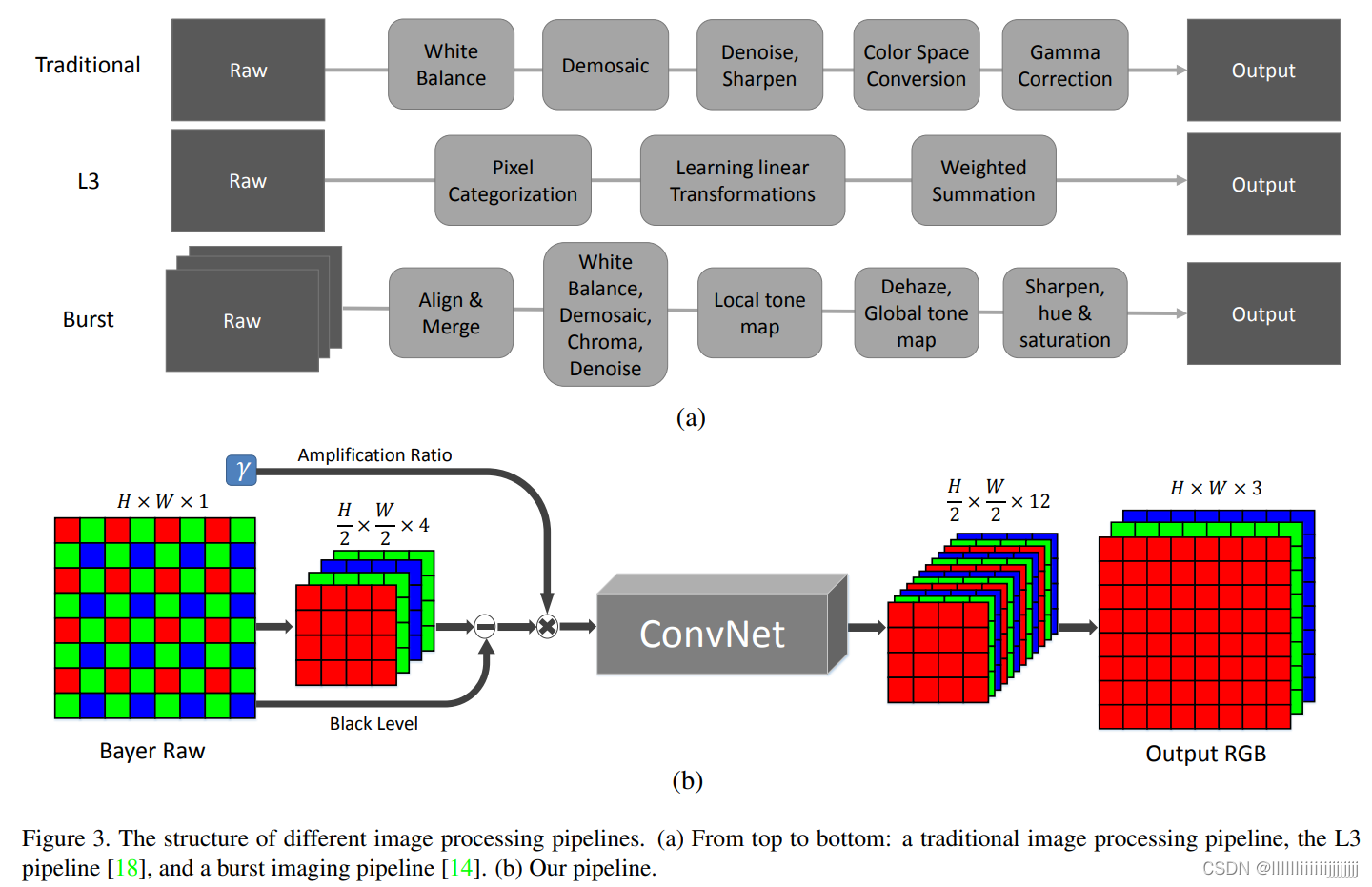
不少工作证明一个纯全卷积网络(FCNs)能够有效地完成许多图像处理算法,基于这一现象,作者提出了一个端到端学习的弱光照单图处理系统,该系统直接在RAW域进行处理,而非常规使用的sRGB域。如图3b所示,对于Bayer阵列,首先将输入的RAW数据划分为四个通道,对于X-Trans阵列,RAW数据通常被整理为6*6的block,然后继续整理为36通道大小的数据。本文中,作者通过合并相邻的单元将RAW图像整理为9通道的数据,然后进行处理。在送入网络前首先减去对应的黑电平值,再乘以期望放大的倍数后送入卷积网络进行处理,处理完成后得到一个输出大小为原来一半的12通道图片,使用一个子像素卷积层将数据变化到sRGB域。

在该工作中,作者使用U-net网络来进行处理,该网络计算量较小,可以将整幅图片输入进行处理。
2.3:网络训练
作者使用L1损失和Adam优化器来从头训练网络。在训练时,网络的输入是短曝光的RAW数据,而groundtruth为使用libraw处理后得到的sRGB空间中的长曝光图片。放大倍数为输入和参考图片的曝光时间之比。在每次迭代中随机抠取一个512*512大小的图像块,然后随机使用翻转或旋转等进行数据增广。学习率在初始阶段被设置为 ,然后在迭代2000轮后被设置为 ,总共进行4000轮训练。
3:实验结果
3.1:量化对比和感知实验
作者首先对比了文中的算法与传统的ISP处理的流程所得到的结果,如图5所示,可以发现传统的ISP存在大量的噪声而且色彩偏差很大,而作者所提的方法具有较好的感知效果。为了验证所提算法在不同传感器获取到的数据之间具备一定的泛化能力,作者将本文模型用于处理IPhone 6s拍摄的数据,如图6所示,可以发现虽然没有直接在IPhone 6s使用的传感器上训练,但仍旧取得了很好的效果。


作者使用BM3D算法将传统流程获取的图片进行了去噪处理,由于BM3D算法需要指定噪声的强度而且实际噪声分布较为复杂,如图7所示,其处理效果没有本文进行盲去噪的效果好。

作者又将Burst去噪的结果进行了对比,并在Amazon Mechanical Turk platform 进行了试验,结果如表2所示。

可以发现在亮度放大倍数为300时,作者提出的方法效果最好。当处理100倍的放大时,与BM3D算法和Burst去噪具有类似的效果。
3.2:消融实验
作者对文网络中用到的模块进行了消融测试,结果如表3所示。将U-net替换为CAN后,性能出现下降,一个例子如图8所示。换到RGB域进行处理时Sony相机对应的结果大幅度下降。损失函数改变后的结果如表2中4、5所示。在对Bayer阵列对应的RAW数据进行处理时,一种策略时将不同颜色对应的单元整理到不同的通道,另一种是将单通道的RAW数据进行复制,然后再不同的通道使用掩码进行处理,表2中6展示了将Packed方法换为Masked方法的结果表现。对于X-Trans传感器,通道数为33和66时对应的结果如表2中7所示。
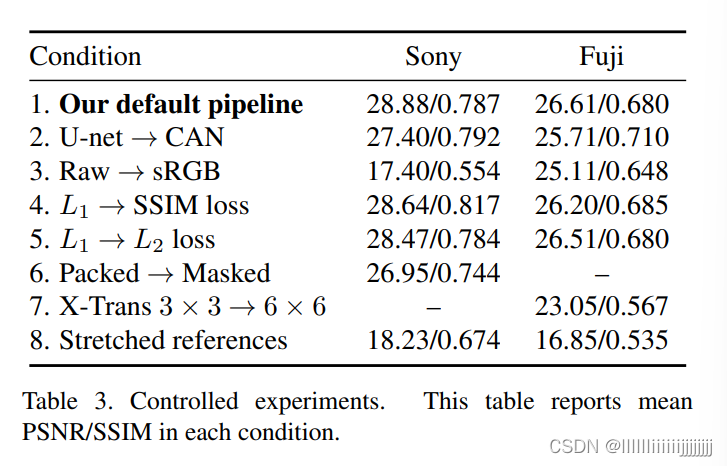
表7中第8行展示了用网络学习直方图拉伸的结果,当作者让网络学习直方图拉伸时,网络性能大幅下降。说明本文的网络不容易学会在整个图像上建模和操作全局直方图统计数据,因此作者将直方图拉伸用于后处理。

4:结论
作者设计了一个简单的管道,改进了传统的低光图像处理。所提出的管道是基于全卷积网络的端到端训练。实验结果表明,对SID数据进行了有效的噪声抑制和正确的颜色变换。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









