









参考内容
简介
本质上来说高版本off by null的目的就是为了同时过掉size vs prevsize和bck-fd==P,fwd-bck==P这两个check,利用手法主要是靠合理申请与释放堆块,在堆块中写入large bins、unsorted bins指针以实现链表完整性。(旧版本仅仅检查被unlink的chunk size与自身尾部的prev size是否相等,故释放自身即可。新版额外检查这个chunk size与被free掉的chunk的prev size是否相等,chunk overlap必须要伪造后者,而前者不可控,故一般打法失效。)
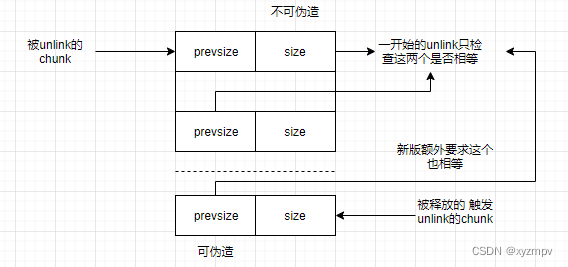
large bin打法
核心思想是利用large bins的fd nextsize、bk nextsize充当伪造chunk的fd、bk,从而实现在large chunk内伪造size过检查。手法如下(均为逻辑视图,非内存视图):
- 先申请三个在同一
large bins范围内但大小不同的chunk,中间和结尾用tcache阻拦防止合并,全部free掉之后再申请大chunk,通过大循环将这三个chunk全部放入同一个large bins。此时由于large bins机制,中间大小的chunk的fd、bk与fd next size\bk nextsize均相同,分别指向比自己小/大的chunk。
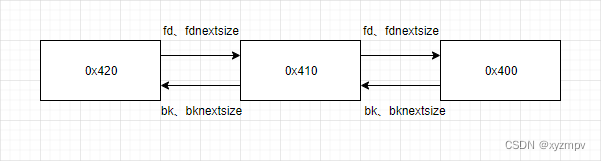
- 将
0x410 chunk(P)取下,并伪造好fake chunk的size。

此时large bin如下所示:

- 再将
0x410 chunk的bk(0x420 chunk)取下并写其fd为该chunk(伪造bck-fd==P)。此时large bins还剩下最后一个chunk(P-fd),残留指针为头节点libc指针。
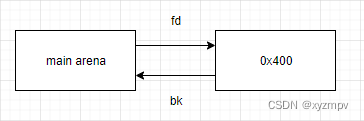
- 此时需要申请到
0x400 chunk,再申请一个unsorted bins范围的chunk(辅助堆块),先释放P-fd(0x400 chunk),再释放辅助堆块,这样二者都进入了unsorted bins,且P-fd-bk指向辅助堆块,可以覆盖为P的地址。
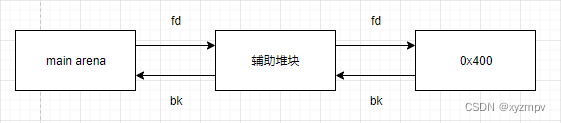
- 最后通过对
P下面的tcache chunk释放后申请进行off by null,再释放P实现unlink与chunk overlap。由于覆盖链表指针时需要覆盖两个字节,而后一个字节的高4位随机化,所以该方法只能实现1/16爆破。
由于off by null覆盖的最后一字节为0x00,所以需要在一开始加入padding chunk使被unlink的chunk本身地址形如
0x xxxx0xx
unsorted bin打法(非爆破)
不涉及large bins。核心是通过释放与堆块合并来保留与获取所需的指针。
1.类似lagre bin打法,先申请五个large bin范围的chunk,同样需要预先申请padding chunk使目标chunk地址形如0x xxxxxx00。布局如下(tcache堆块可根据leak与attack需求在图中位置上下随意增加,不影响指针关系):
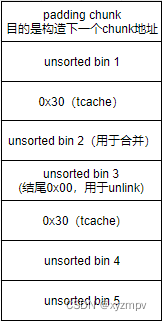
再按顺序释放unsorted bin 1、3、5,指针如下所示:

2.释放unsorted bin 2,合并unsorted bin 3(目的是为了保留其内部指针),此时经过unlink后unsorted bin 2+3被插入链表头

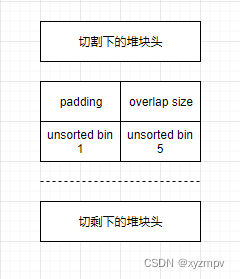
3.申请大小略大于unsorted bin 2 的chunk(这里需要提前控制好堆块大小unsorted bin 2>5>1),使unsorted bin 1、5被分入large bins,同时覆盖原unsorted bin 3处的size为更大值。
被切割的unsorted bin 2+3如图所示
large bin如图所示
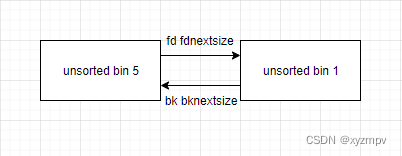
注意到一点:切剩下的堆块头与伪造的堆块头之间非常近,也就是说,它的地址与伪堆块头间的距离<0x100,二者的地址仅最后一个字节不同。
于是,我们可以申请回unsorted bin 1、5以及切剩下的堆块,分别释放(切剩下的+另一个堆块)到unsorted bins中,再申请,再释放,这样就可以在P-fd与P-bk中踩出来了与P的地址仅1字节之差的地址,bypass unlink检查。
最后off by null改unsorted bin 4的fd in use,再free即可。
unsorted bins威力加强版(fastbin + malloc consolidate)
利用malloc consolidate机制,可以在消耗堆块体积小得多的情况下完成类似攻击。
众所周知,malloc consolidate会遍历fastbin链表,并将链表中的free fastbin放入unsorted bins。如果有相邻的free fastbin,还会进行合并。考虑到fastbin本身体积很小,且可以很方便的申请-释放入tcache构造fd,因此可以考虑使用free fastbin通过malloc consolidate构造unsorted bins双链表,同时合并chunk以保留fd、bk并伪造chunk size,从而bypass检查。
2.31以上的glibc,其开头的tcache管理chunk大小为0x290。这就意味着我们若直接申请一个0x70大小的chunk,就会令下一个chunk地址为0x xxx300。接下来,我们在0x100的范围内申请8个chunk,每个大小均为0x20。申请一个0x4f0的chunk,用于结尾释放入unsorted bins并触发合并。再申请7个0x20的chunk填满tcache,申请7个0x60的chunk填满tcache。此时内存布局如下:

接下来,我们可以先后释放chunk 6-2-8,再释放chunk 1,这些都会进入fastbin中(这两步前后可以对调,但0x20 chunk的链表关系需要注意,即size内部的释放顺序需要在中间释放chunk 2)。
申请一个>0x400的chunk,直接free,触发malloc consolidate并合并这个chunk到top chunk。
malloc consolidate先会遍历0x20的链表,构造出chunk 8-2-6的0x20 unsorted bins,然后会将0x70的chunk释放进unsorted bins并合并chunk 2,制造出0x90的chunk。该chunk的内存布局如下:

而此时0x20的unsorted bins变为chunk 8-6。此时,可以申请0x90的chunk,获取到上述chunk后覆盖0x20这一size为0x1e0,以通过检查。
然后,申请0x20的chunk,得到chunk 6,改写残余的指向chunk 8的bk指向chunk 2。(伪造P-fd-bk)
再申请0x20的chunk,得到chunk 8,再释放chunk 5,释放chunk 8(此时tcache为chunk 8-5),拿到chunk 8,此时它的fd指向chunk 5,部分覆盖使其指向chunk 2。(伪造P-bk-fd)
释放并申请chunk 9来off by null,最后释放0x500的chunk即可实现unlink(unlink chunk 2)。
碎碎念
最后一个方法由我本人提出,个人认为其一个巧妙之处在于利用malloc consolidate在0x20的链表中踩出fd、bk,同时利用小chunk地址差异小和便于申请释放来构造fd。另一个巧妙之处在于利用malloc consolidate实现类似unsorted bins的堆块合并来保存指针,同时利用size差异导致的遍历顺序差异,实现先构造出完整的双链表再unlink的效果。
感谢师傅们的blog,头一次有机会提出自己的手法orz















 1857
1857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









