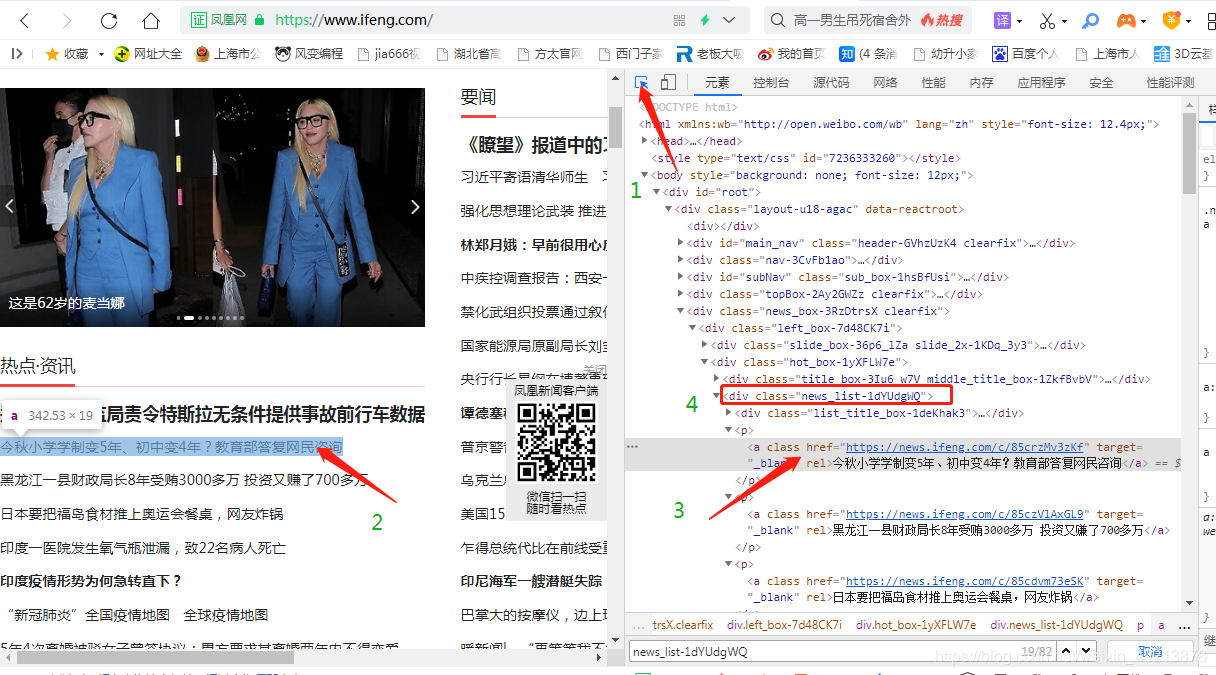
人生苦短,我用Python 前面写了一个爬取小说的,想想用Python爬小说好像low了点(不够高大上啊(逼格不够啊)),今天给大家整个高端点的,我们来爬一下凤凰网的首页新闻,这下逼格应该够了。 爬取网页嘛,大家都知道request,beautifsoup,今天我们整点不一样的,今天使用的是pyquery,这也是一个第三方库,需要使用pip install 来安装的,安装方法想必大家都知道的,我这里就不赘述了,至于使用方法,可以看一下这个pyquery,我们就直接开始操作了。 打开凤凰网我们按F12,先观察一下,








 本文介绍了如何使用Python的PyQuery库爬取凤凰网首页的新闻标题和内容。通过分析网页结构,提取class为news_list-1dYUdgWQ下的元素,获取标题和链接,再找到content类下的文本内容,实现新闻信息的抓取和保存。
本文介绍了如何使用Python的PyQuery库爬取凤凰网首页的新闻标题和内容。通过分析网页结构,提取class为news_list-1dYUdgWQ下的元素,获取标题和链接,再找到content类下的文本内容,实现新闻信息的抓取和保存。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








