






目录
第一部分:面向对象
1.1、基本概念
1、面向对象的基本概念:
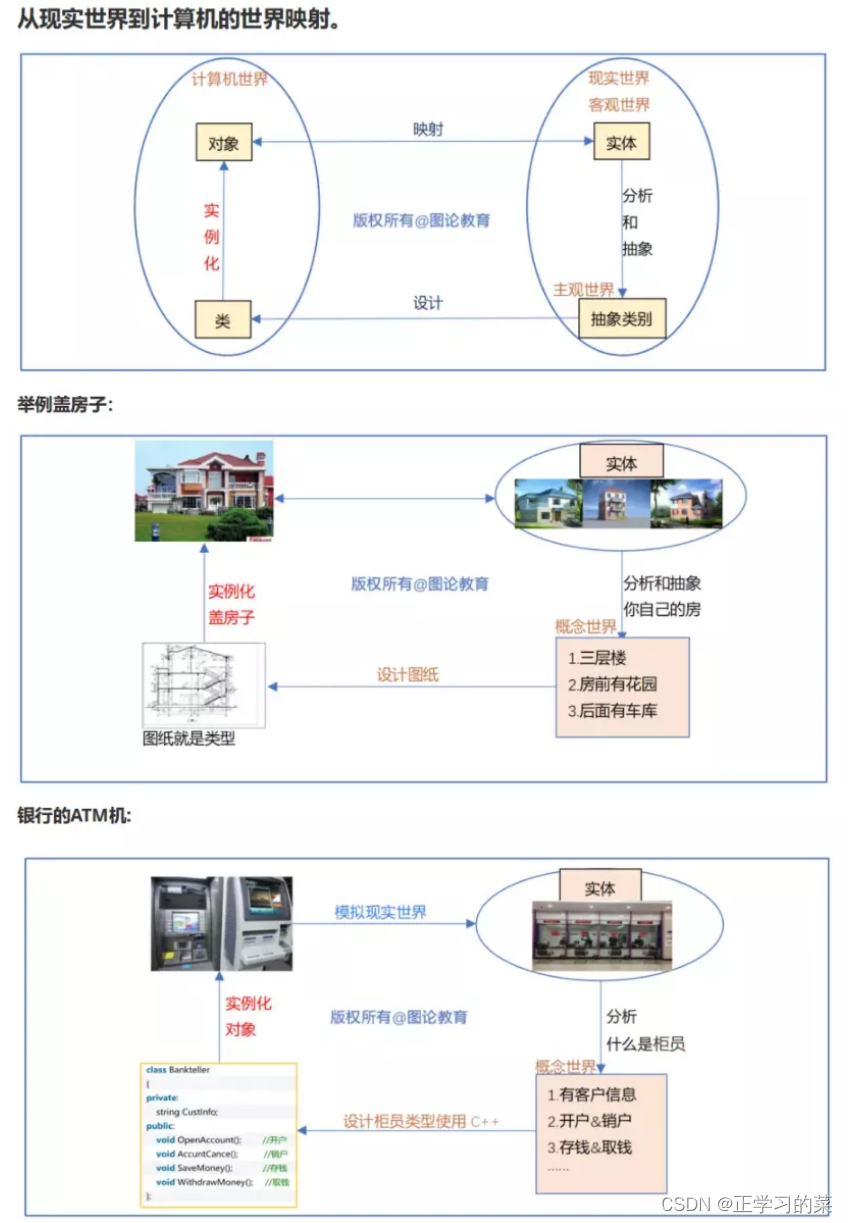
对象的概念是面向对象技术的核心所在。
面向对象技术中的对象就是现实世界中,某个具体的物理实体在计算机世界(逻辑)中的映射和体现。也就说计算机中的对象,是模拟现实世界中的实体。
我们可以通过设计类,然后再实例化产生一个对象。
举个例子:int是一个类型,我们可以去设计一个类型,通过这个类型,我们可以实例化产生一个具体的实例,比如int 一个变量a,我们可以对变量a进行赋值。那我们面向对象设计程序就是要设计、实例化产生一个具体的实例来供我们进行操作
2、总结:
抽象类别:是由实体通过抽象、分析而得到的
类:是由主观、概念世界设计而来
对象:是由类的实例化产生而来
3、状态和行为是对象的主要属性
1.对象的状态又称为对象的静态属性,主要指对象内部所包含的各种信息,也就是变量。每个对象个体都有自己专有的内部变量,这些变量的值标明了对象所处的状态。
2.对象的方法(行为)一方面把对象的内部变量包裹,封装,保护起来,使得只有对象自己的方法才能操作对象内部变量,另一方面,对象的方法还是对象与外部环境和其他对象交互、通信的接口,其他对象或外部环境可以通过这个接口来调用对象的方法,操纵对象的行为和改变对象的状态。
成员变量是对象的属性(可以是变量,指针,数组等),属性的值确定对象的状态。(比如我们的对象张磊同学:他有100块钱,我们将钱借出来之后,他的财富值就是0,他的状态就会从有钱人变成穷人)
成员函数是对象的方法,确定对象的行为。(借钱的时候,他有数钱、取钱等等方法、行为)
1.2、类型设计和实例化对象:
1、c++类的设计

2、访问性说的是对象。我们能从外部访问这个类所产生的对象的公有成员(public),不能从外部访问私有和保护行成员(private、protected)
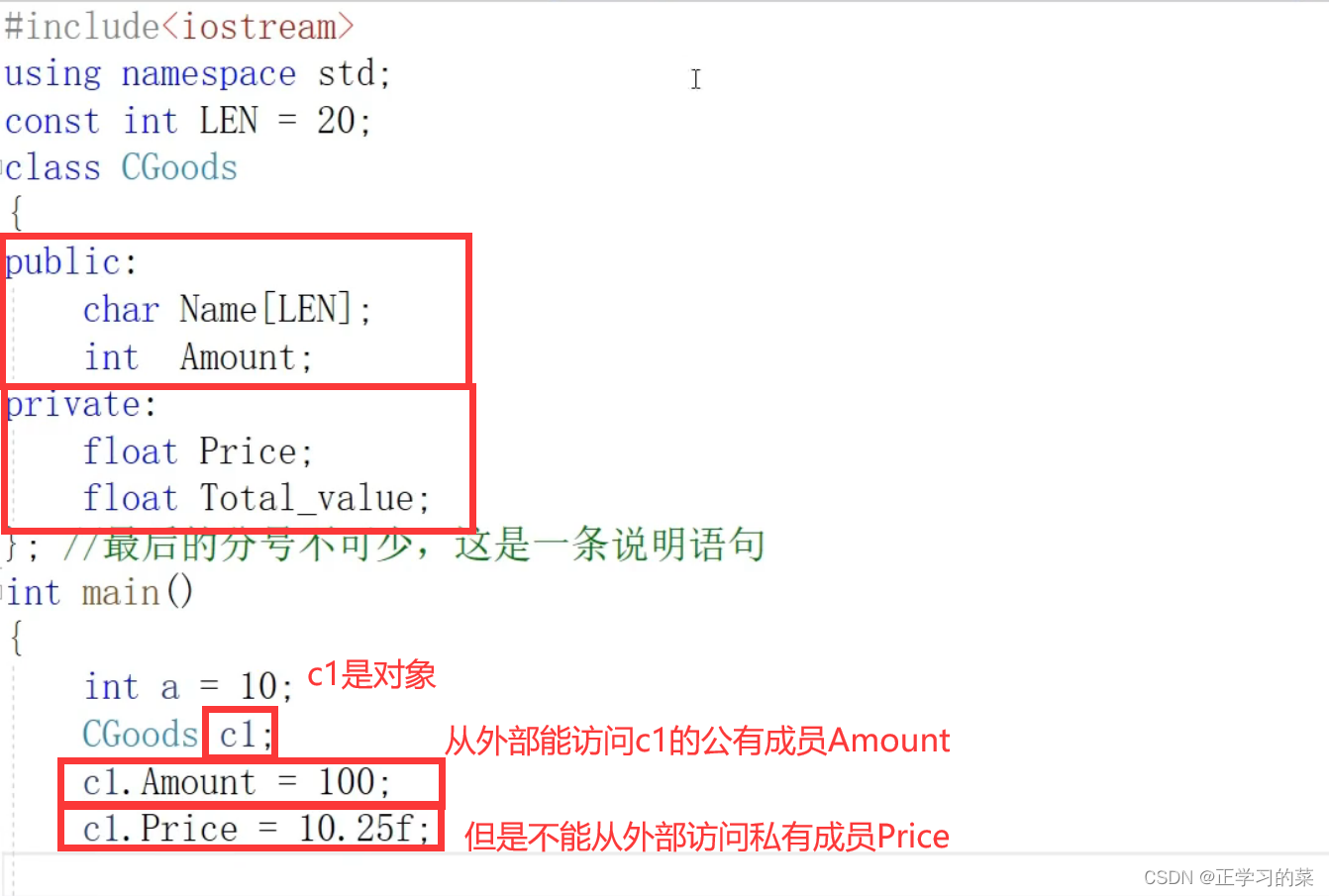
3、一般情况,将我们的方法都设计成公有,将属性设计成私有。类就是属性和方法的集合,最终我们可以通过调用公有的方法来改变对象私有的属性。公有函数集定义了类的接口

——————————————————————————————————————————————————————————————————————————————————————
第二部分:this指针
2.1、this指针特点
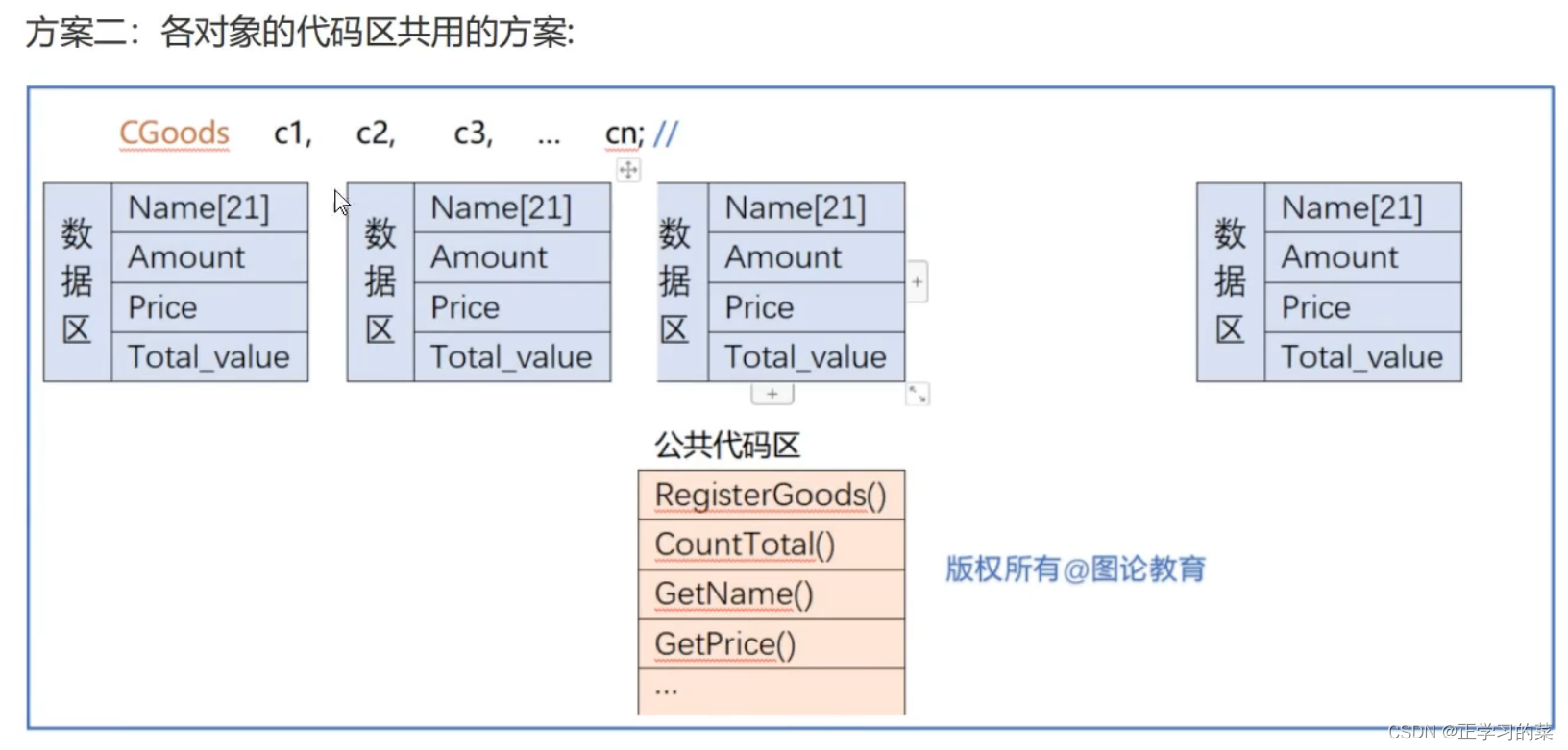
引入this的根本目的:节省空间(时间换空间),因为各对象独立的安排内存的时候,他们有各自的数据区(属性)和代码区(方法),这样类产生多个对象的时候,就会占用很大的内存空间。但是我们知道,同类型的对象,它们的属性各不相同,但是方法都是一样的,所以可以采用各对象代码区共用的方案,这个时候就用到this指针
2.2、编译器针对程序员自己设计的类型分三次编译
1、扫描属性(属性的类型、名称、可访问性【对象】),放入描述表
2、识别和记录类体中函数原型(返回类型+函数名+参数列表),形参的默认值,访问限定。不识别函数体
3、改写类的成员函数,每一个都要改写,加入this指针(识别函数体)。(具体如何改写参考p26this指针讲解)C++从入门到精通_哔哩哔哩_bilibili
只在函数调用的过程中存在,函数调用结束,this指针就不再存在了
形参 Cgood * const this,this指针自身为常性
——————————————————————————————————————————————————————————————————————————————————————
第三部分:构造函数和析构函数
小点注意:sizeof()是一个关键字,不是一个函数,他是在编译的时候确定类型、或者是对象的大小
3.1、构造函数定义
数据成员多为私有的,要对它们进行初始化,必须用一个公有函数来进行。同时这个函数应该在,且仅在定义对象时自动执行一次。称为构造函数(constructor)
3.2、构造函数用途
1、创建对象;
2、初始化对象中的属性;
3、类型转换。
3.3、C/C++最大的区别
对于C语言,有内存空间即可操作。比如定义了一个char类型数组,申请了一块连续内存,但是我们在内存的首地址去给他保存一个整型,这个时候是可以保存的,系统会将4个单元格作为一个整块来保存一个整型数值(高地址存数值高位,低地址存数值低位)

C++中,有空间不一定可以操作,需要构造函数创建对象。C++的函数中,有空间,不一定有对象;但是有对象,一定有空间。
即使是空类型对象,也要占一个字节存在地址,比如:

3.4、构造函数的定义与使用
构造函数是特殊的公有成员函数(在特殊用途中构造函数的访问限定可以定义成私有或保护),其特征如下:
1、函数名与类名相同。
2、构造函数无函数返回类型说明。注意是没有而不是void,即什么也不写,也不可写void。实际上构造函数有返回值,返回的就是构造函数所创建的对象。
3、在程序运行时,当新的对象被建立,该对象所属的类构造函数自动被调用,在该对象生存期中也只调用这一次。
4、构造函数可以重载。严格地讲,类中可以定义多个构造函数,它们由不同的参数表区分,系统在自动调用时按─般函数重载的规则选一个执行。

5、构造函数可以在类中定义,也可以在类中声明,在类外定义。
6、如果类说明中没有给出构造函数,则C++编译器自动给出一个缺省的构造函数(也是无参的构造函数):类名(void){ }。
但只要我们定义了一个构造函数,系统就不会自动生成缺省的构造函数。只要构造函数是无参的或者只要各参数均有缺省值的,C++编译器都认为是缺省的构造函数,并且缺省的构造函数只能有一个。
3.5、构造函数有没有this指针?
构造函数是有this指针的,比如在构造一个c1对象的时候,肯定是已经申请好了c1这个对象的内存,我们将这块内存的地址传给构造函数内部,然后在构造函数体内对c1对象的属性值进行初始化
3.6、为什么需要多个构造函数?
生而不同(无参、有参),死了都一样(析构函数只有一个)。
我们区分同类型对象的时候,它们的属性都一样,但是属性值都不同,所以可以通过有参、无参、以及参数个数来进行区分。
小点注意(不大理解、需要继续回看课程):
在所有属性都是公有(public)的情况下,我们的类才会设计一种特殊的构造函数,就是有几个属性,就带有几个缺省参数的构造函数,并且还有缺省值

3.7、成员初始化列表
对对象中的属性成员进行初始化列表的时候,注意顺序一定要一致


问题:成员函数,为什么用this指针,而不是用引用?????
3.8、析构函数
析构函数的定义
当定义一个对象时,C++自动调用构造函数建立该对象并进行初始化,那么当一个对象的生命周期结束时,C++也会自动调用一个函数注销该对象并进行善后工作,这个特殊的成员函数即析构函数(destructor) :
1、构函数名与类名相同,但在前面加上字符 ~,如: ~CGoods ()。
2、析构函数无函数返回类型,与构造函数在这方面是一样的。但析构函数不带任何参数。
3、一个类有一个也只有一个析构函数,这与构造函数不同。
4、对象注销时,系统自动调用析构函数。
5、如果类说明中没有给出析构函数,则C++编译器自动给出一个缺省的析构函数。
如:~类型名称(){ }
构造函数不能调用,析构函数可以调用进行自杀
构造函数用于获取资源,析构函数要释放资源、还给系统
——————————————————————————————————————————————————————————————————————————————————————
第四部分:生存期
4.1、局部对象
4.2、全局对象
4.3、静态对象
静态的对象、数组、变量,它们的生存期都是存在于整个主函数中,在 . data区
静态对象在第一次调用时进行构建,主函数结束之后,静态对象会被析构掉
局部对象会在作用区间内调用的时候进行构建,作用区间结束,就会被析构掉,直到下一次在作用区间内被调用的时候再次会进行构建,结束被析构。
定义静态、局部的对象的时候,依然是第一次调用的时候进行构建,主函数结束之后才会析构掉
对全局定义的对象,当程序进入入口函数main之前对象就已经定义,这时要调用构造函数,整个程序结束时调用析构函数,然后按照出栈的方式先析构主函数内部的对象,再按照出栈的方式析构所有的全局对象。
全局对象在整个工程中都可见,静态全局对象只在本文件中可见
4.4、动态创建对象
注意new一个对象的时候,可以申请空间,并且调动构造函数,构造一个对象;但是malloc只能够申请对象空间,并不能构造函数
4.4.1、申请单个对象
new的时候,对内置类型(比如int)先申请类型空间、再赋值;对于对象类型是先申请空间、再调动构造函数创建对象
delete的时候,对于对象类型也是两步,先调动析构函数,然后再释放空间,也就是将占用的堆区空间还给堆区

4.4.2、申请一组对象
此处new也是两步,先申请数组大小的空间,然后再依次构建每一个对象。那系统怎么知道要构建几个呢?其实这里在堆区进行申请空间的时候,在连续空间的头部会有一个“ 头部信息 ”,这个“ 头部信息 ”保存的就是我们这个数组空间的大小,所以在构建对象、以及进行析构的时候,都是会查看这里的“ 头部信息 ”
申请一组对象,在delete的时候,注意一定要加 [ ],这样系统才能知道释放的是一组对象空间,否则不加 [ ] ,系统就会崩溃,因为你只释放了一个对象空间

在以上这种申请一组对象空间的情况下,我们调动的是默认的构造函数;如果要给一组对象进行初始化,也可以用大的{ },内部包含{ } 的方式进行对一组对象进行初始化

malloc只能申请空间,不能构建对象

——————————————————————————————————————————————————————————————————————————————————————
第五部分:对象的成员方法的使用
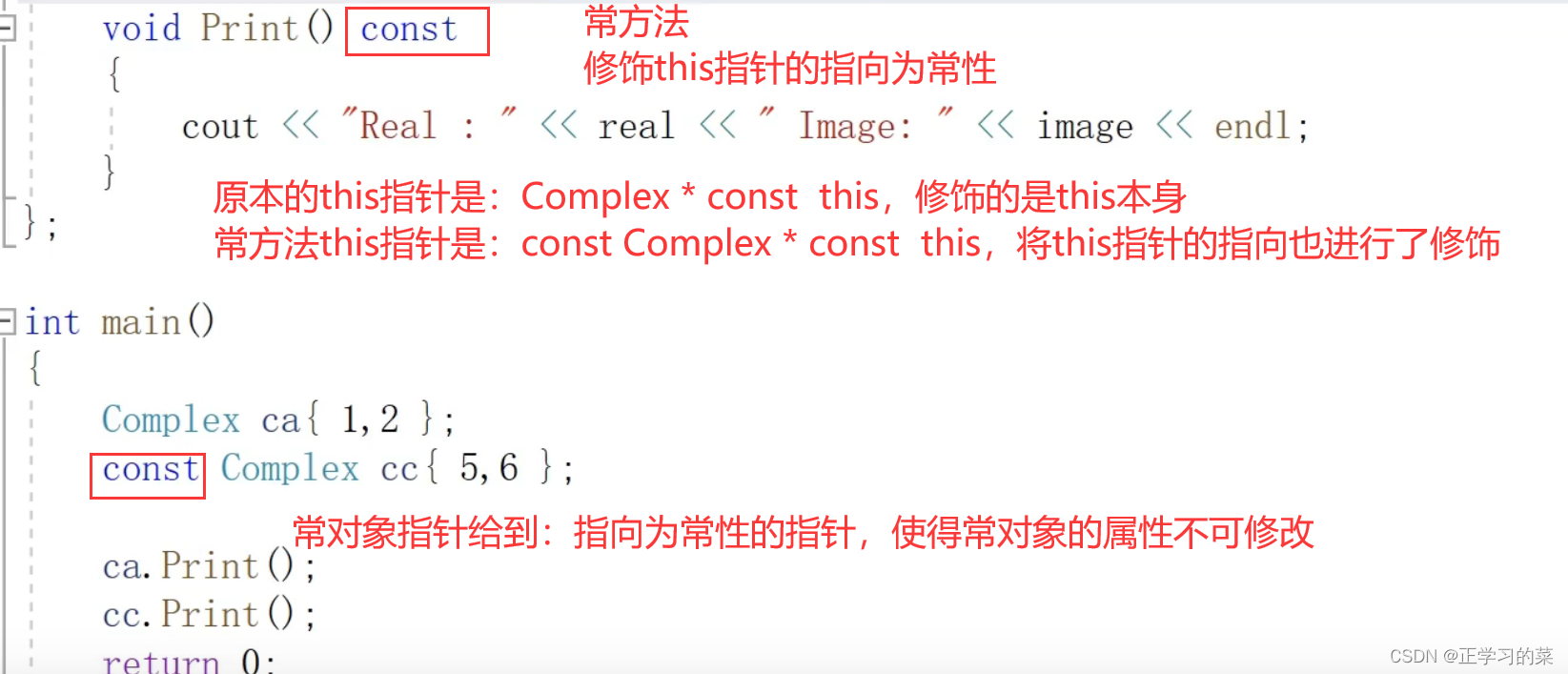
5.1、普通对象和常对象
普通对象c1可以给到普通指针pthis1,也可以给到指向为常性的指针pthis2

常对象的属性是不可更改的,所以只能给到指向为常性的指针

5.2、常方法函数
常方法函数既可以被普通对象使用,也可以被常对象使用,还可以被常引用使用。
总结:
常对象只能调动常方法;
普通对象优先调用普通方法,要是没有普通方法,也可以调动常方法;
所以常方法可以作为函数重载的依据
另外:
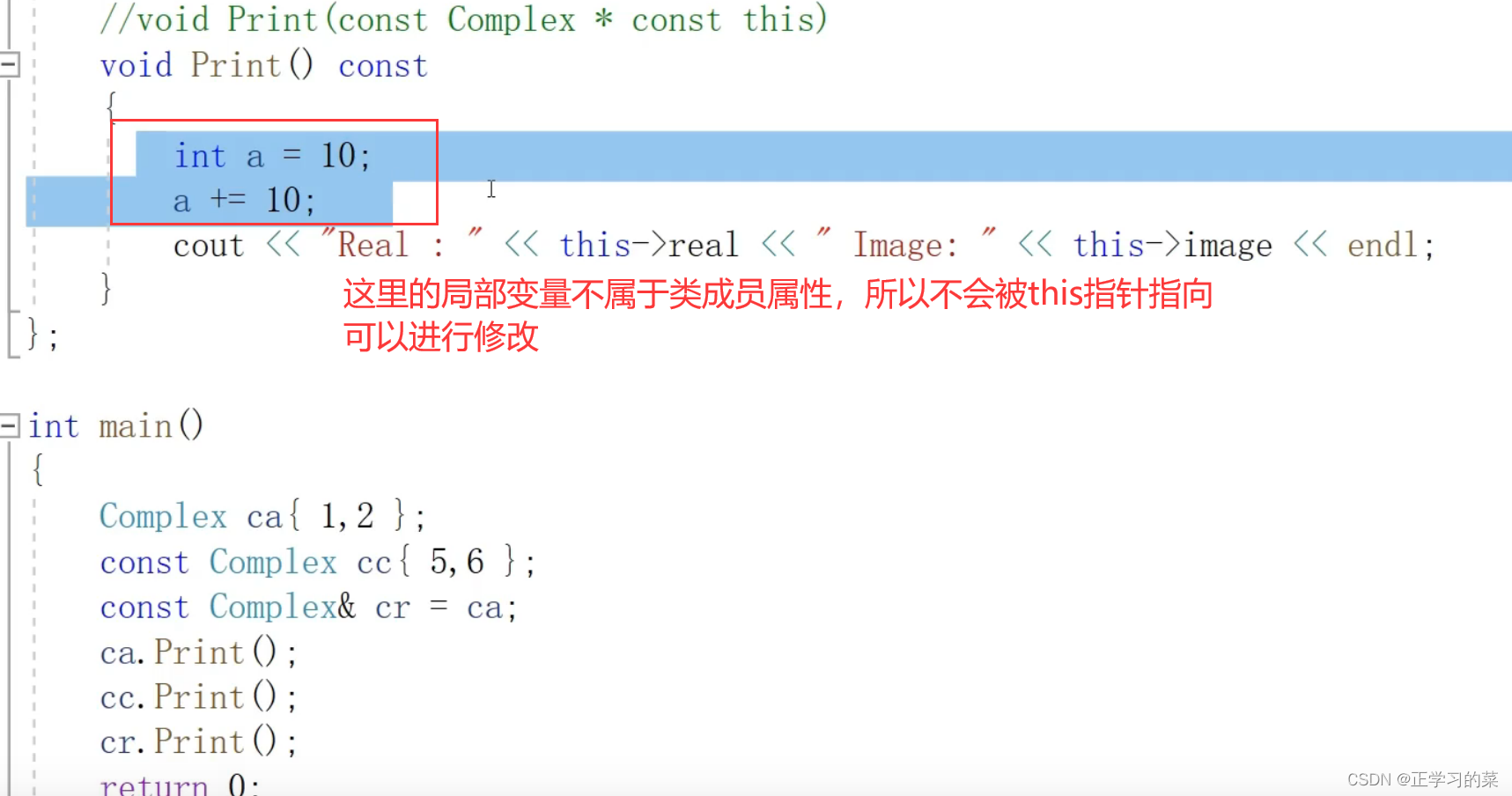
常方法的函数体中,只能调动常方法,不能调用普通方法
但是普通方法的函数体内,可以调用常方法,也可以调用普通方法

5.3、构造函数用途之一:类型转换
1、创建对象;2、初始化对象中的属性;3、类型转换
类型转换的过程解释:
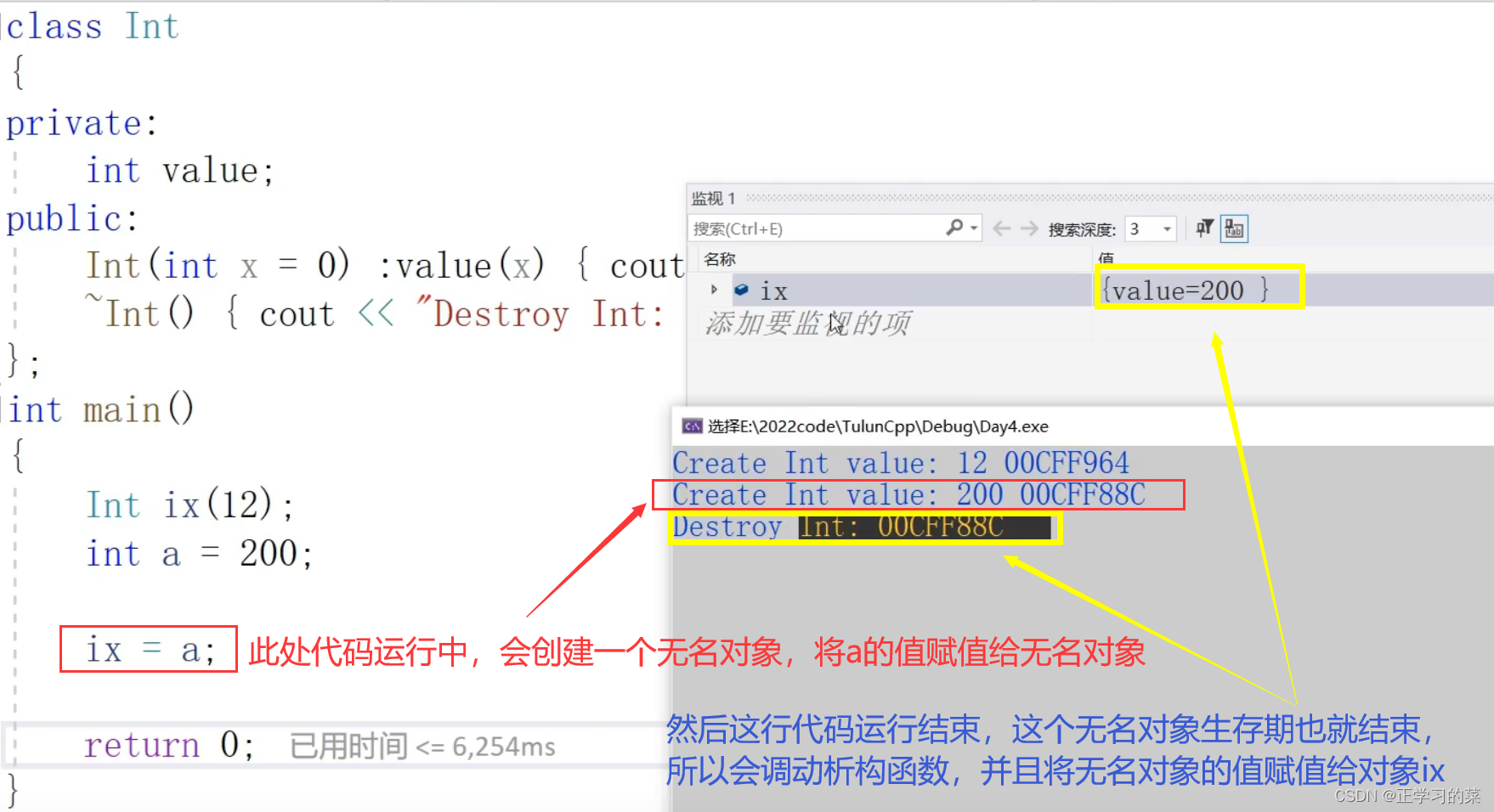
一个对象ix,一个int变量a,我们要将a的值赋值给ix本身是没法赋值的,因为内置类型没办法赋值给对象。
这个时候,赋值过程中就会调动构造函数,产生一个无名对象。
这里赋值的实际过程中会调动构造函数,产生一个无名对象(临时对象),将无名对象的属性值赋值为变量a值:200,在赋值结束之后,这个无名对象的生存期也就会结束,这个无名对象就是【将亡值】(是c11中的概念,它只存在于这个赋值过程中)。
最后再将这个无名对象的属性value值200,赋值给对象ix的属性value。
以上的过程就是构造函数类型转换的作用。
explicit关键字:

5.4、当类的属性成员是一个对象的时候:
以下各个情况主要是搞清楚:初始化列表方案这里会进行调动构造函数,创建对象
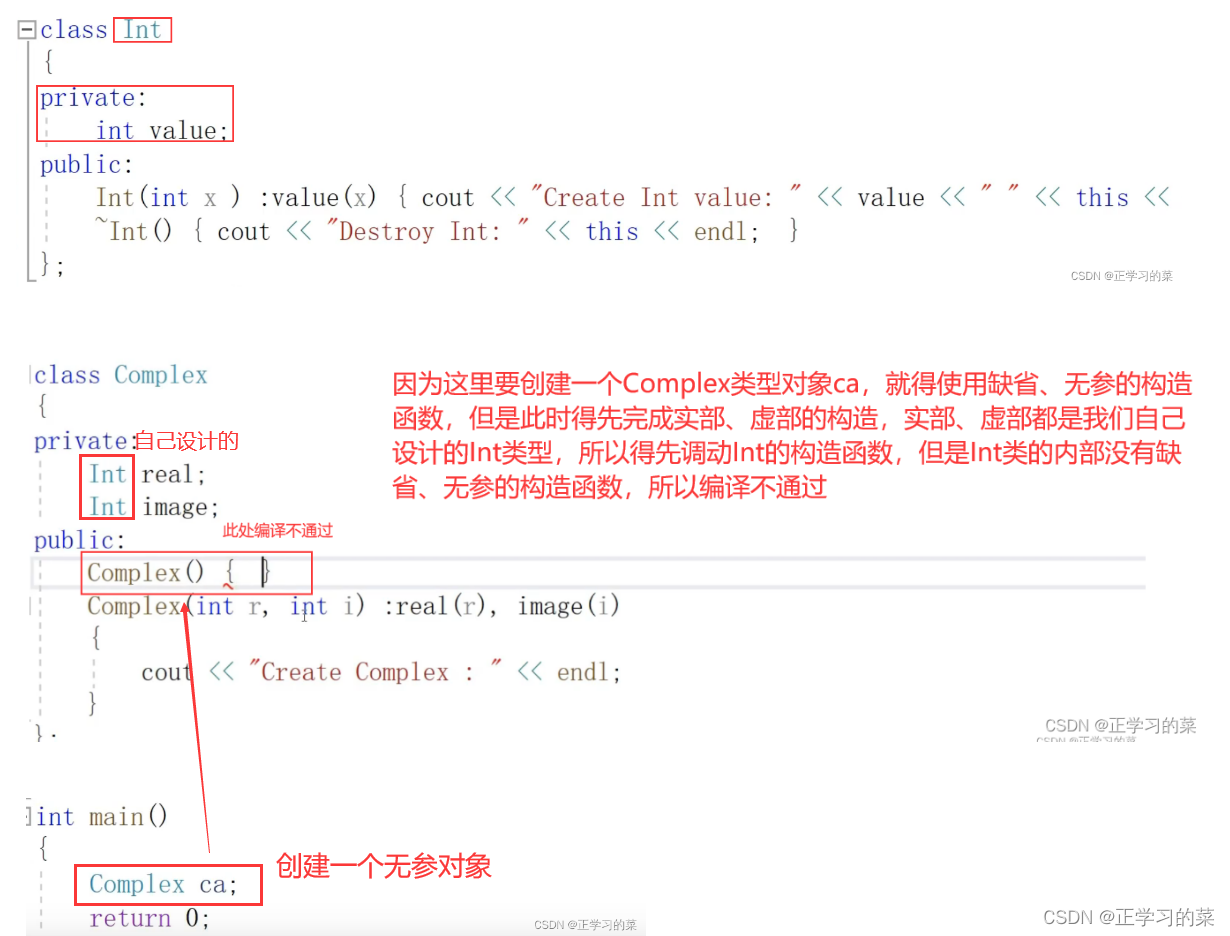
情况一:创建一个无参对象Complex ca
解决方式:
如果需要创建一个无参的Complex对象ca,想要编译通过,可以在原本缺省的构造函数这里给上初始化列表,就可以编译通过

解决方式2:
给Int类的构造函数这里给上缺省值,这样 Complex ca在调动Complex缺省构造函数的时候会先去调动Int的缺省构造函数,Int的缺省构造函数有缺省值,就可以进行创建对象ca,并且会将对象real、image分别初始化为0
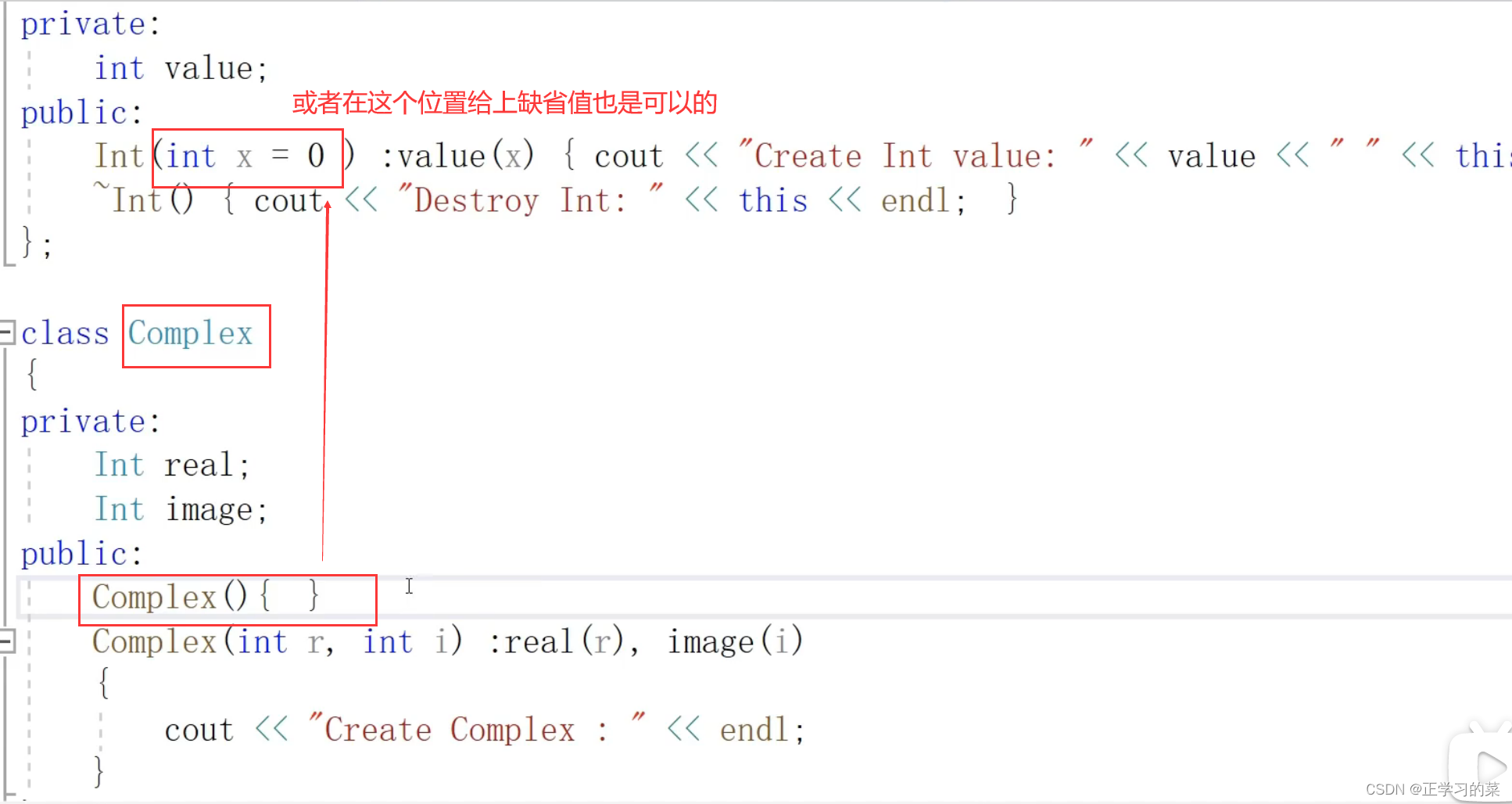
情况二:创建对象 Complex ca{ 1,2 };
进入Complex构造函数之前,会先对实部、虚部这两个属性成员(Int类型对象成员)会先进行构建,构建完属性成员,再进入构造函数内部执行其他操作


情况三:在Complex构造函数的函数体内部对实部、虚部进行赋值,依然是会在进入构造函数之前,先构造好实部、虚部,并且初始化为0;在Complex函数体内部仅仅只是对实部、虚部进行赋值操作


总结:
进入构造函数内部之前,我们一定是会先将【成员对象】(属性成员)先构建好,然后进入到构造体函数内部之后,就仅仅只是给成员对象进行赋值。内置类型也是同样的道理。
比如:
创建对象Complex ca{1, 2}; 这里会调动Complex(int r, int i){ ... };
但是此处的实部、虚部都是我们自己设计的 Int 类型,所以此时会先去调动 Int 的构造函数,构造好实部和虚部;
构建完成,然后再进入Complex的构造函数内部,再进行赋值动作
问题1:在定义一个对象的时候,调动构造函数创建对象,我们可以使用初始化列表方式对属性成员进行初始化,那其他公有方法可不可以使用初始化列表方案?
答案:
在进入构造函数之前,属性部分就初始化完成。构造函数使用初始化列表,初始化列表这里就会调动属性成员的构造函数来构造属性成员。即使没有使用初始化列表,也会在进入当前构造函数前完成属性成员的构造
因此如果在公有方法这里使用初始化列表的时候,就会对属性成员进行二次构造,这个是不允许编译通过的。
对于内置类型来说,也是一样的,不能在公有方法这里使用初始化列表方案来对属性成员进行二次构建
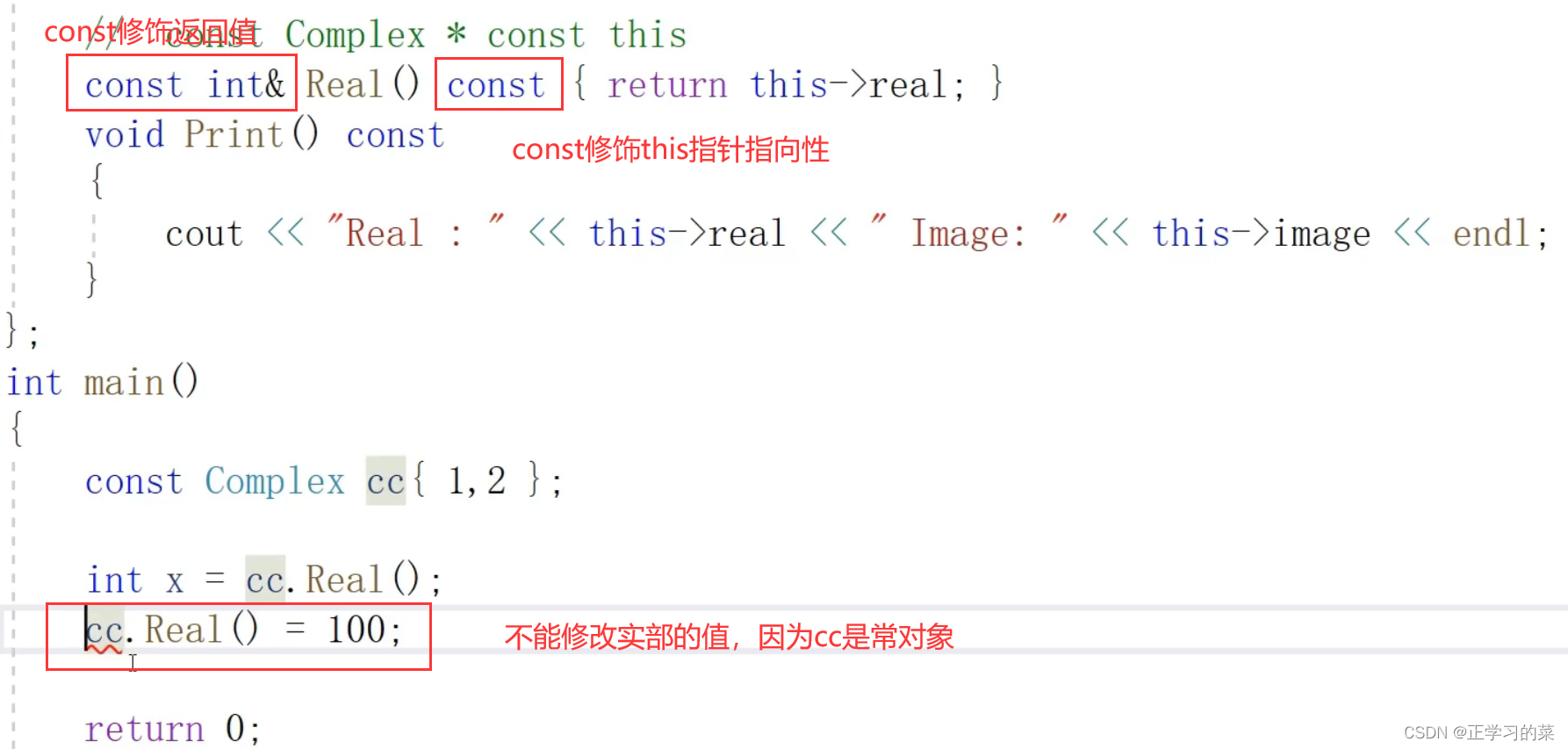
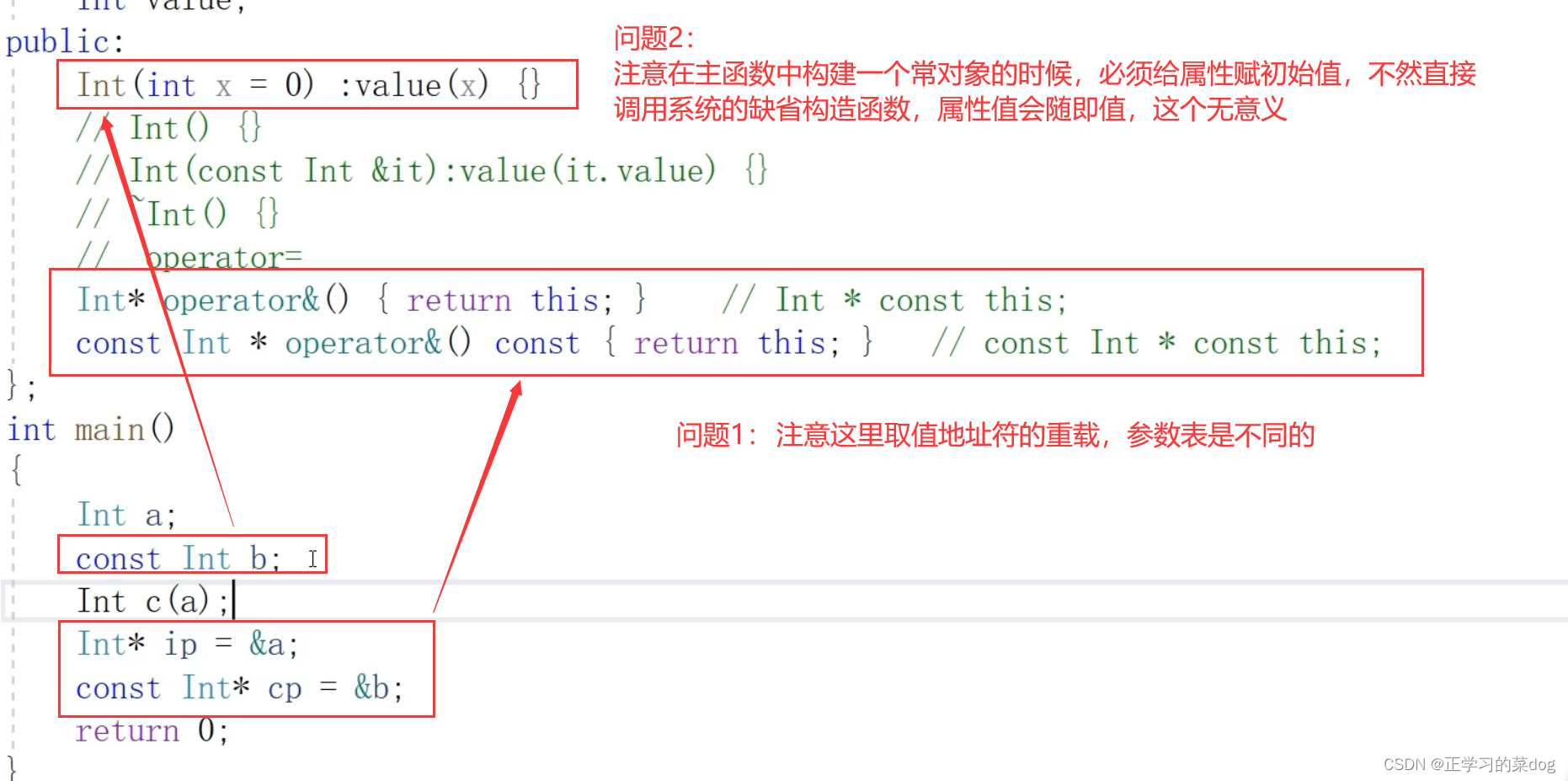
问题2:在类的公有方法中可不可以使用“引用”方式返回?
答案:
首先,如果函数要以指针或者引用的方式返回的时候,这里要返回的变量不能受函数作用域的影响,比如要返回局部变量的值就是不允许的
当变量的生存期不受函数影响的时候,就可以用指针或者是引用的方式返回;
或者是以引用进、以引用出的时候,变量生存期也是不受函数应用的;

注意(不好理解):
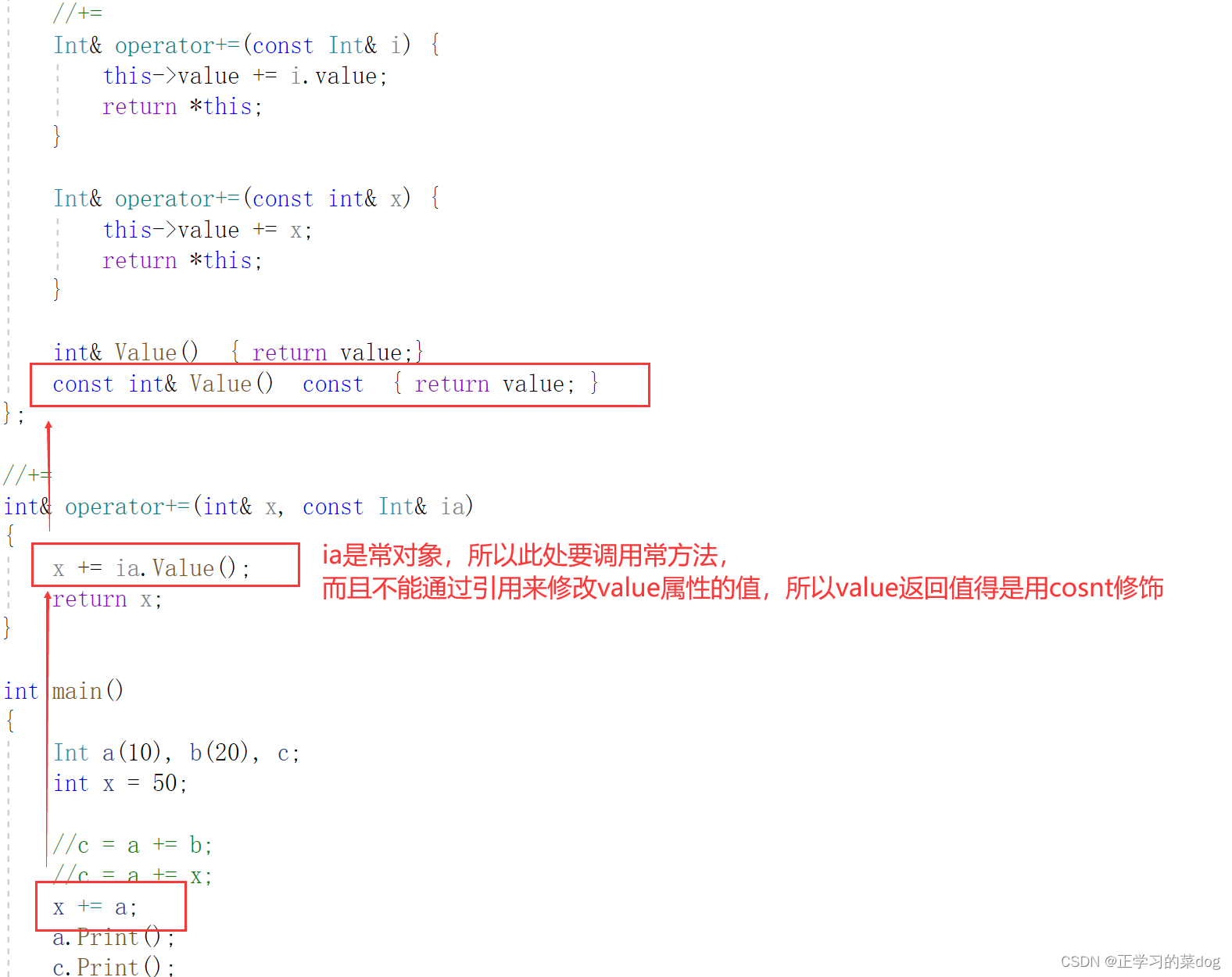
上方使用引用方式返回的时候,既可以对实部、虚部进行取值读,也可以对实部虚部进行改写;
如果是常对象cc的话,注意this指针的指向性用const修饰(这里修饰后表示实部、虚部值不可改写);但是存在一个问题,返回值是以引用方式返回,引用cc.Real()= 100 是可以来改变实部的值,所以返回值这里也需要使用const来修饰返回值
第六部分:面向对象思想实现栈
第七部分:拷贝构造函数
1、什么是拷贝构造函数
同一个类的对象在内存中有完全相同的结构,如果作为一个整体进行复制或拷贝是完全可行的。这个拷贝过程只需要拷贝数据成员,而函数成员是共用的(只有一份拷贝)。在建立对象时可用同一类的另一个对象来初始化该对象的存储空间,这时所用的构造函数称为拷贝构造函数(Copy
Constructor) 。
2、 问题:为什么拷贝构造函数不能使用值传递,而使用引用方式传递参数?
答案:首先语法规则上是错误的,值传递会形成无穷递归调动的情况

3、拷贝构造函数是构造函数的一种重载
这里要清楚const是放在()内,而不是()外,放在()修饰的是引用,表示形参对应的实参(原对象)是不可修改的。
如果放在()外,那就是修饰this指针的指向了。这里this指针是我们要拷贝产生的新对象的this指针,所以要是用const修饰新对象的this指针的指向性,那肯定是不行的,因为我们本来就行要对新对象的内容进行拷贝赋值
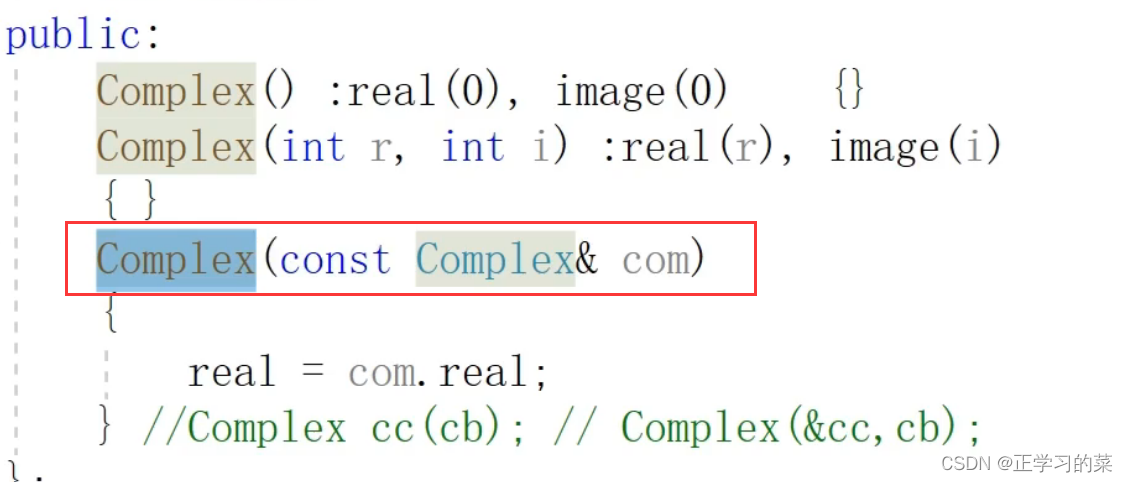
4、拷贝构造函数的形参必须是一个引用(同2问题)
为了防止拷贝构造过程中,修改原对象,那就加上const
5、使用初始化列表方案对属性成员进行初始化
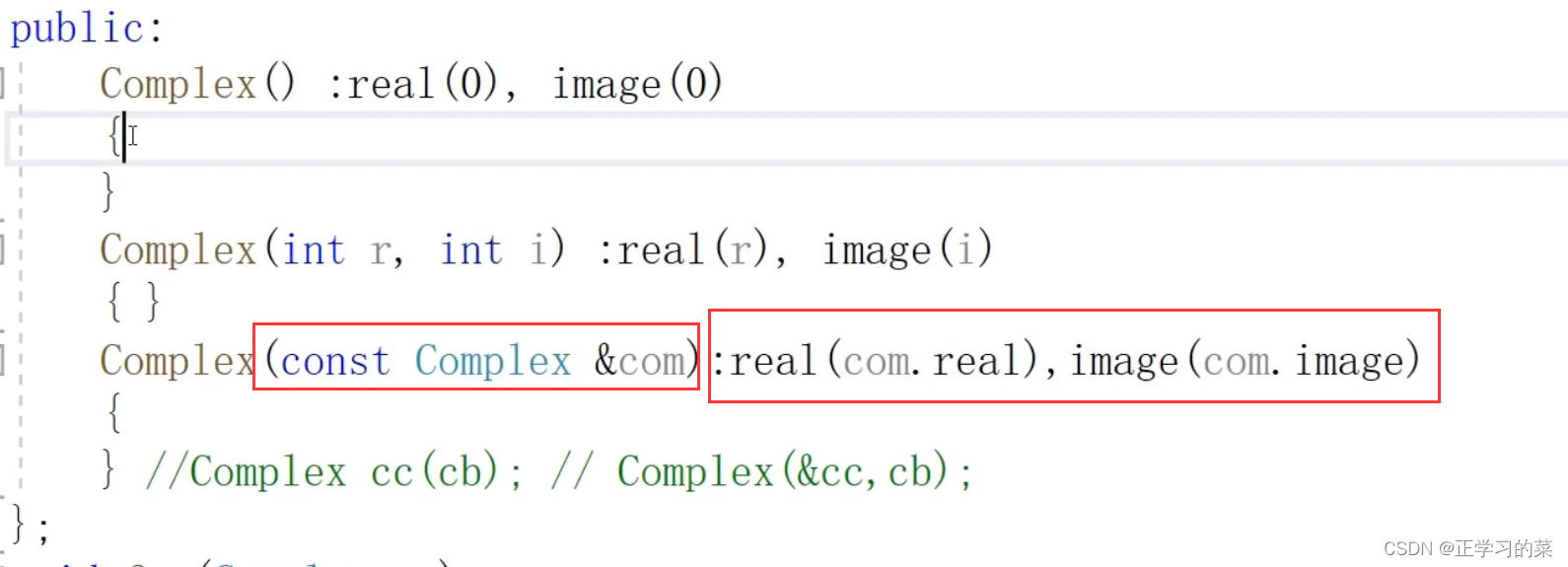
6、按位拷贝
将原对象的属性成员依次拷贝给新的对象,这种方式就是按位拷贝
此处是一个数据量(属性值)、一个数据量依次拷贝
系统缺省的拷贝构造函数是一个字节、一个字节去进行拷贝的
以下就是用cb拷贝获得cc
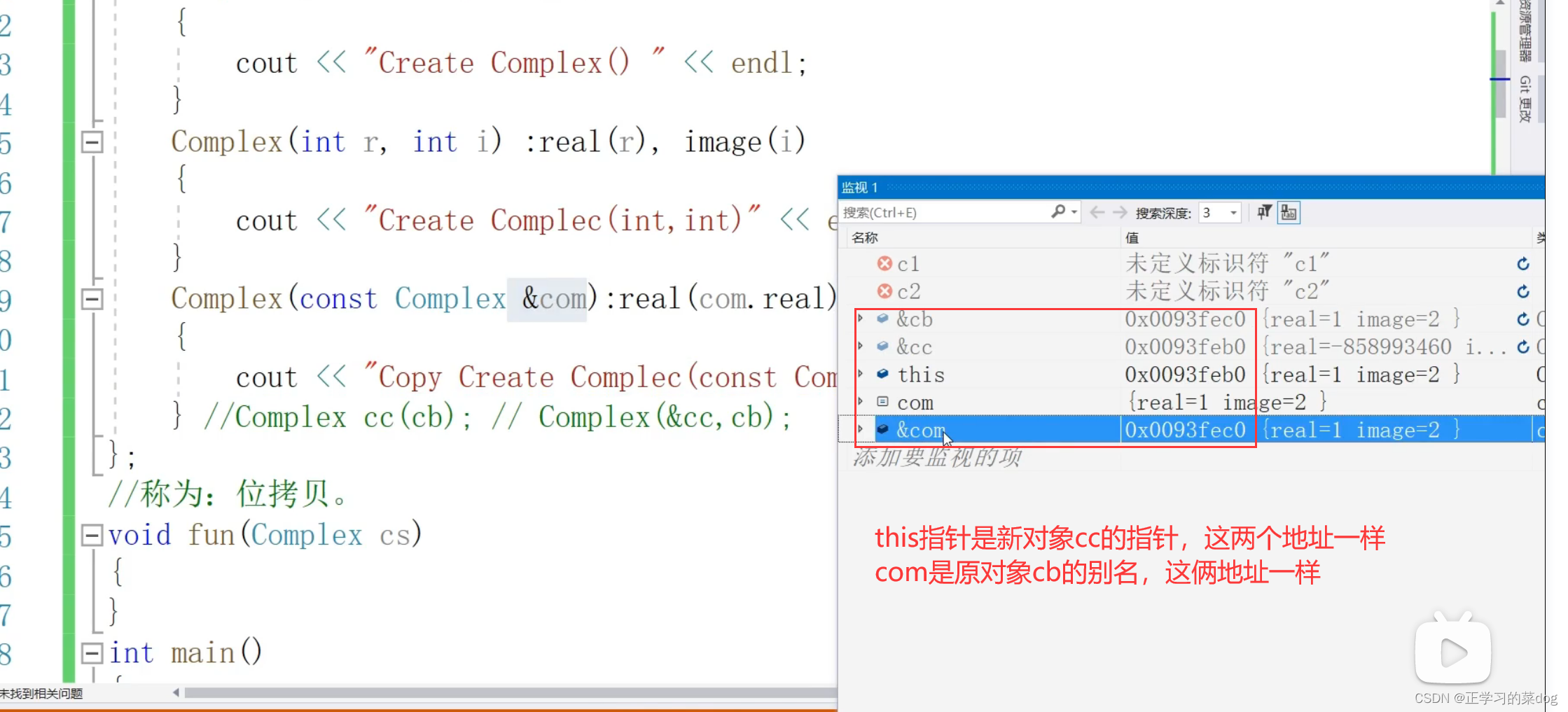
7、系统缺省拷贝构造函数
按位拷贝
系统抓住cb和cc的地址,然后一个字节、一个字节复制。我们写的拷贝构造函数就模仿这个模式
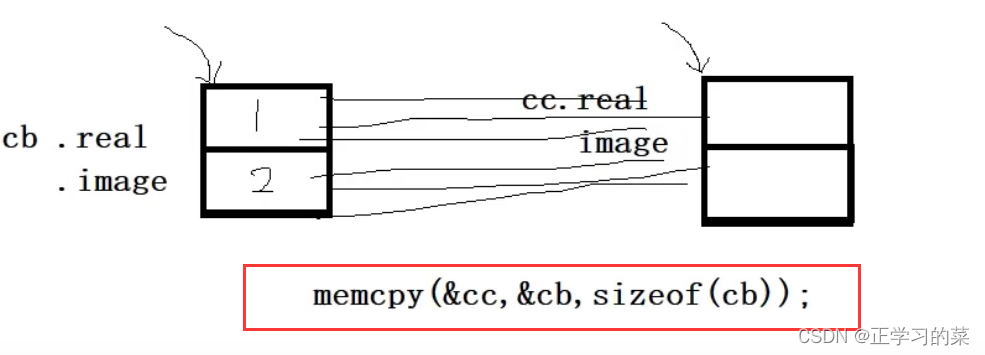
8、浅拷贝
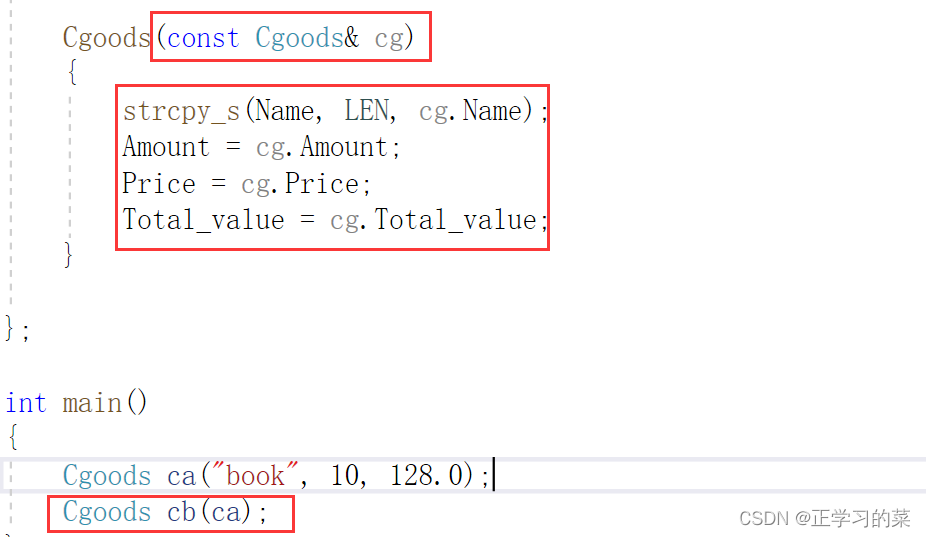
不得在构造函数中使用memset()。如果有虚表,会存在很大问题
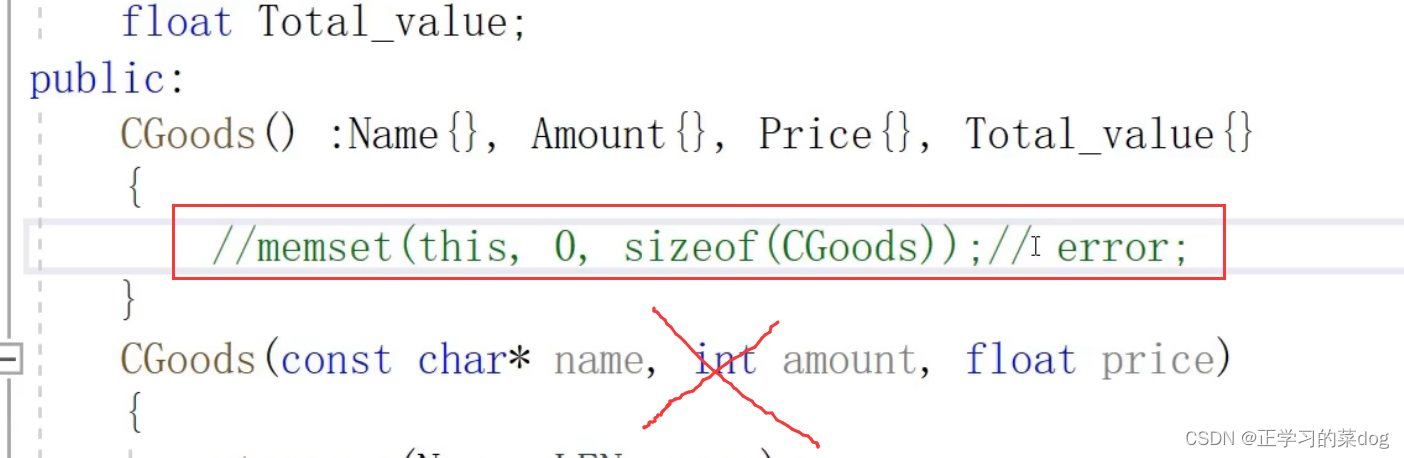
拷贝构造中使用memcpy()

9、(类)类型作为函数的形参
对于自己设计的类型,在作为函数的形参进行传递的时候,有以下三种方式(引用比指针更加安全,引用是指针的语法糖,指针使用需要判空)
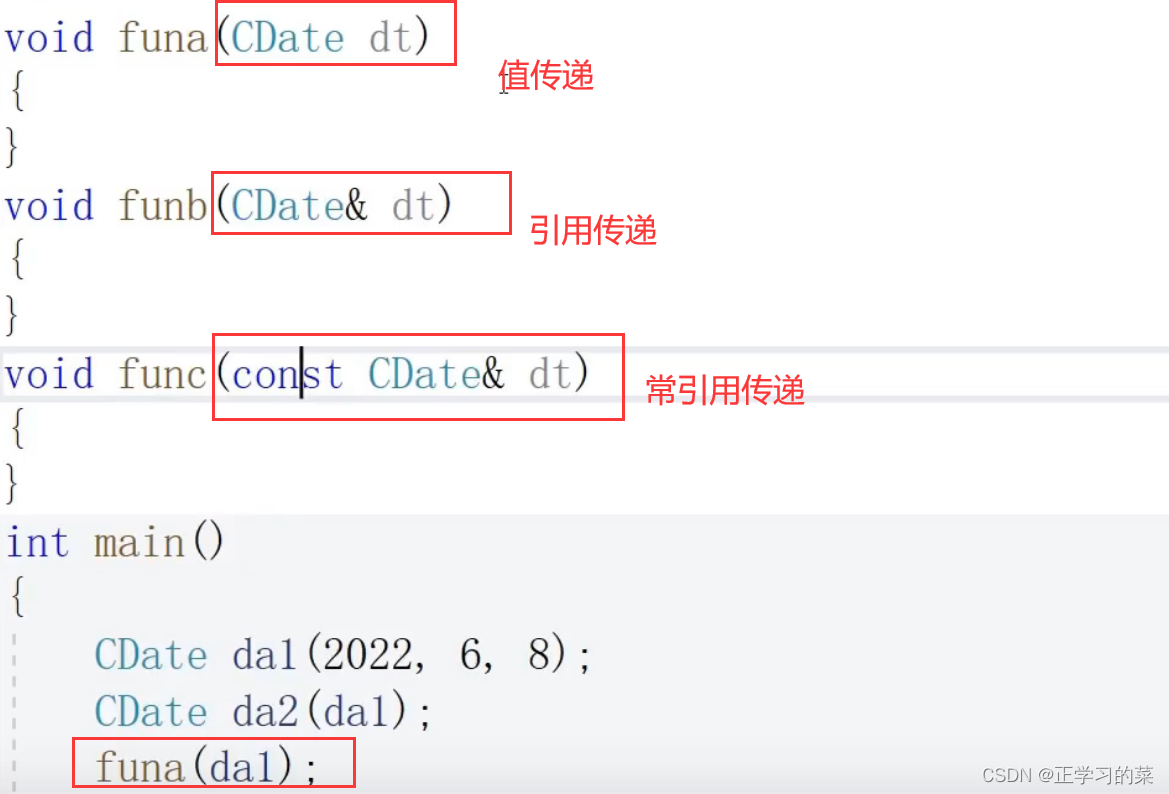
每一种形参都代表不同的意图:
值传递:创建副本,副本修改,原本的值是不会修改的。形参修改并不影响实参。但是如果属性部分存在一个很大的数组,那就会对时间和空间存在浪费
引用传递:通过形参值改变实参
常引用传递:不能通过形参值改变实参的值。对形参、实参都有限定,都不能修改
10、(类)类型作为函数的返回值(理解难度大)
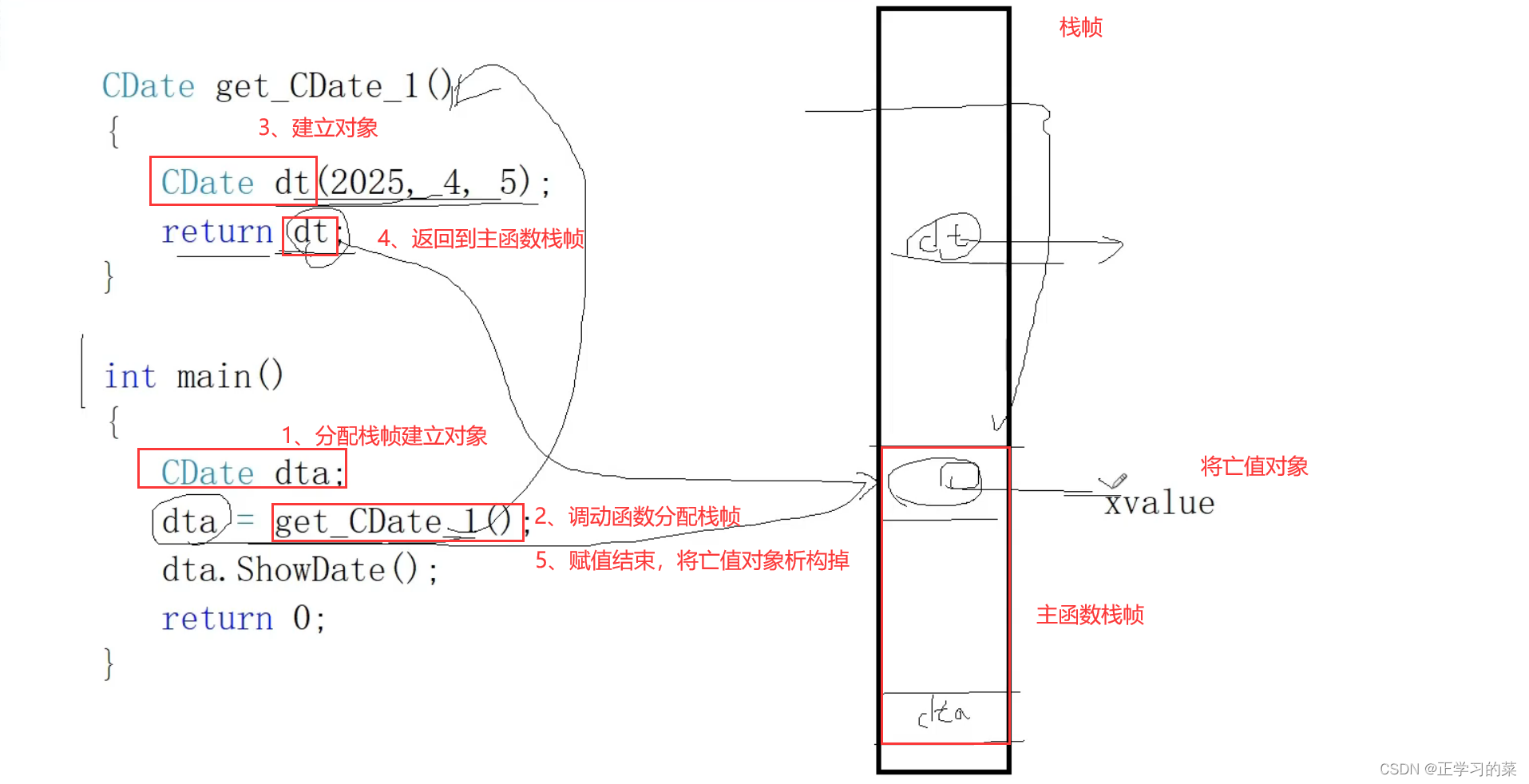
10.1、以值返回
1、dta在主函数的栈帧空间中调动构造函数创建dta对象;
2、调动get_CDate_1()函数,这个函数中,dt这里也会调动构造函数创建dt对象
3、返回局部对象dt的时候会产生将亡值对象dt(存在于主函数栈帧位置),这里是调动拷贝构造函数,创建将亡值对象dt
4、函数调用结束,dt会被析构掉
5、将亡值对象dt赋值给dta之后,将亡值对象dt会析构掉
6、主函数结束,最后dta再析构
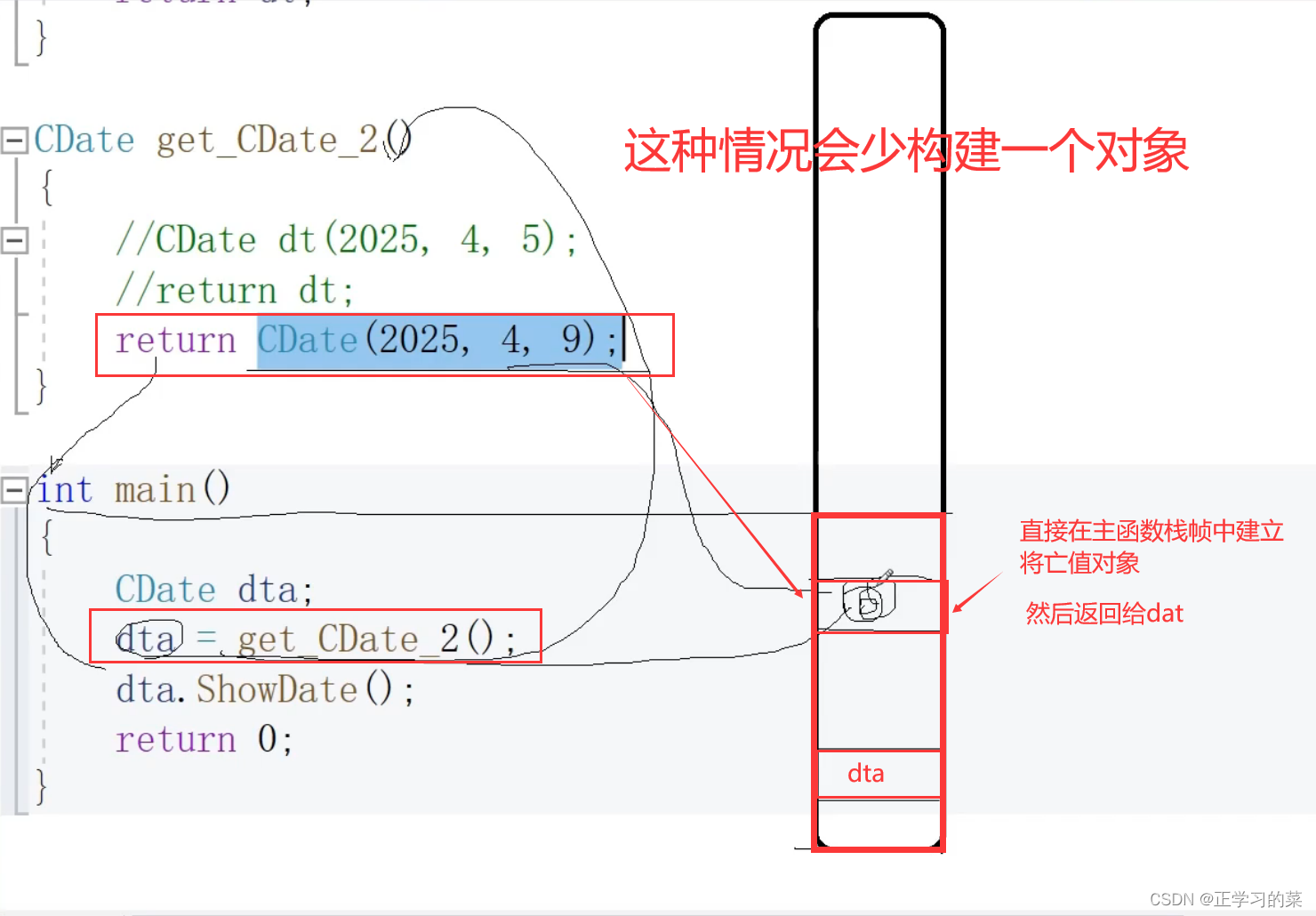
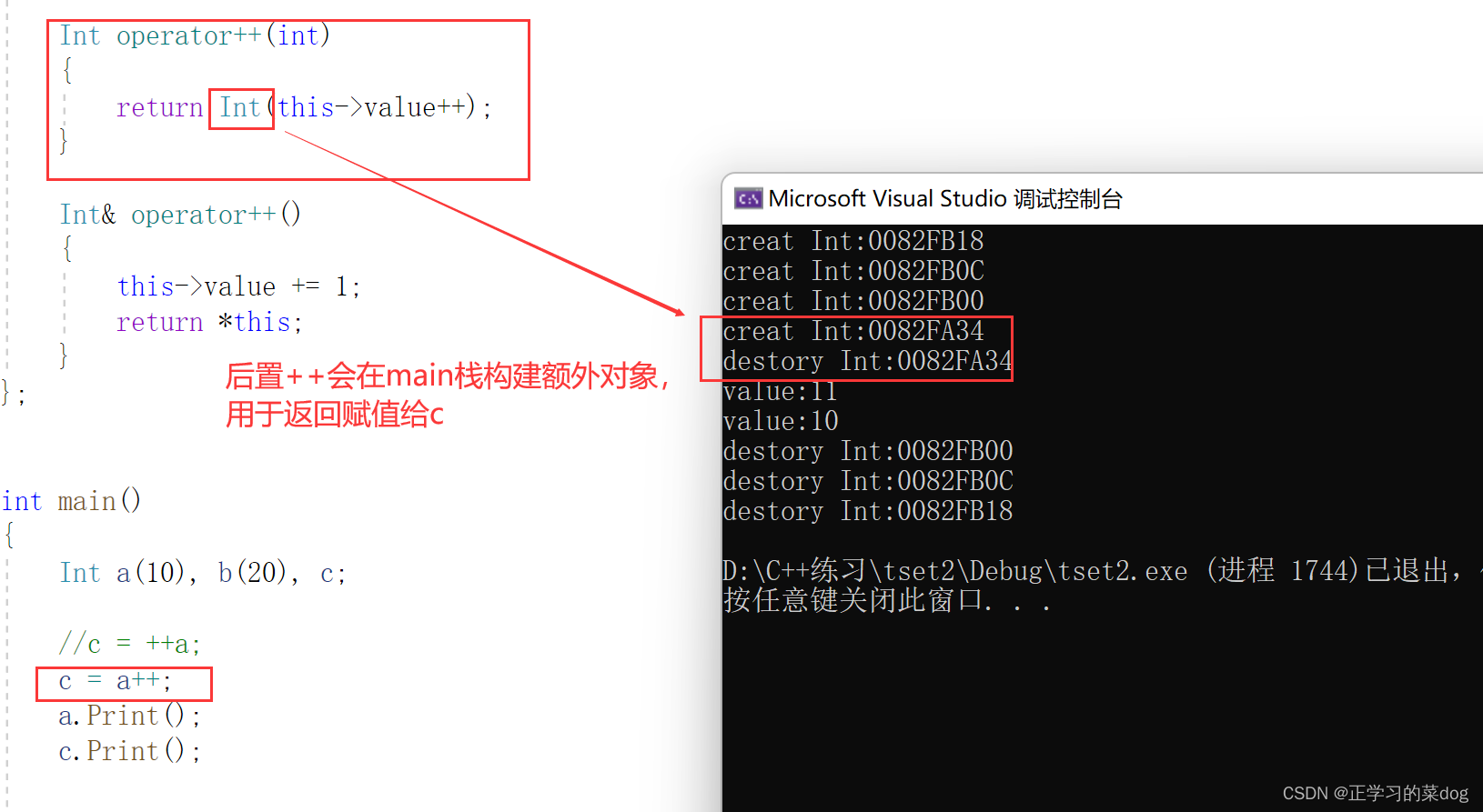
注意:如果以下方这种情况【类名+()】的话,在函数中会直接返回构造的将亡值对象,因此会少构造一个对象
10.2、以引用返回
此处绝不允许以引用或者右值引用的方式返回局部对象,因为引用在底层就是地址,这里的局部对象dt在函数调用结束就会被析构掉。我们将从返回的地址上去取值,也就是要从已经死亡的对象上去取值,这个是不合适的

还有以下情况:不具有名字的对象,我们称为右值
在c98中,以引用方式返回,以下方式中,还是会最终返回这个将亡值对象的地址,但是仅仅是之抓住了地址,而这个将亡值对象会被析构掉,然后只是把地址给到了dta
在c11中,没有名字的对象,我们称为右值。存在的问题是:我们以左值引用返回,这个是不可以的


11、深拷贝和浅拷贝
当对象属性成员中有指向堆区的指针域的时候,这时就不能用浅拷贝,只能用深拷贝。因为浅拷贝之后,这两个对象指向堆区的空间是同一块空间,当析构掉一个对象之后,堆区的这一块共享空间也就会被释放,下一次析构另外一个对象,就会对堆区空间进行二次释放,则系统崩溃
因此在属性成员有指针指向堆区的时候,就得自己写拷贝构造函数,并且写深拷贝;或者在设计类型的时候,当有socket、网络、或者是文件操作的时候,也就是说指向系统内核对象的时候,得自己写深拷贝
浅拷贝:
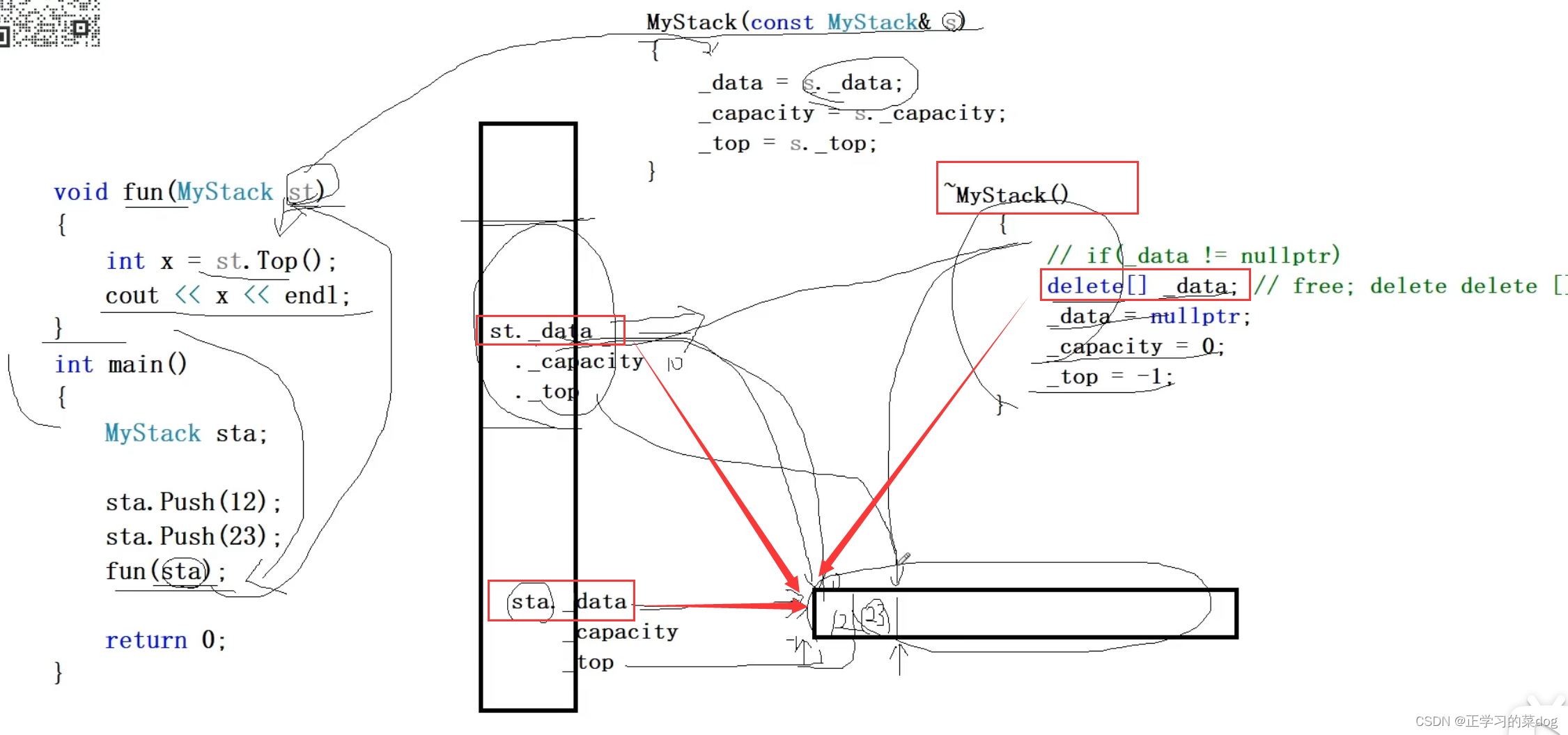
如下,我们在对MyStack类进行拷贝的时候,
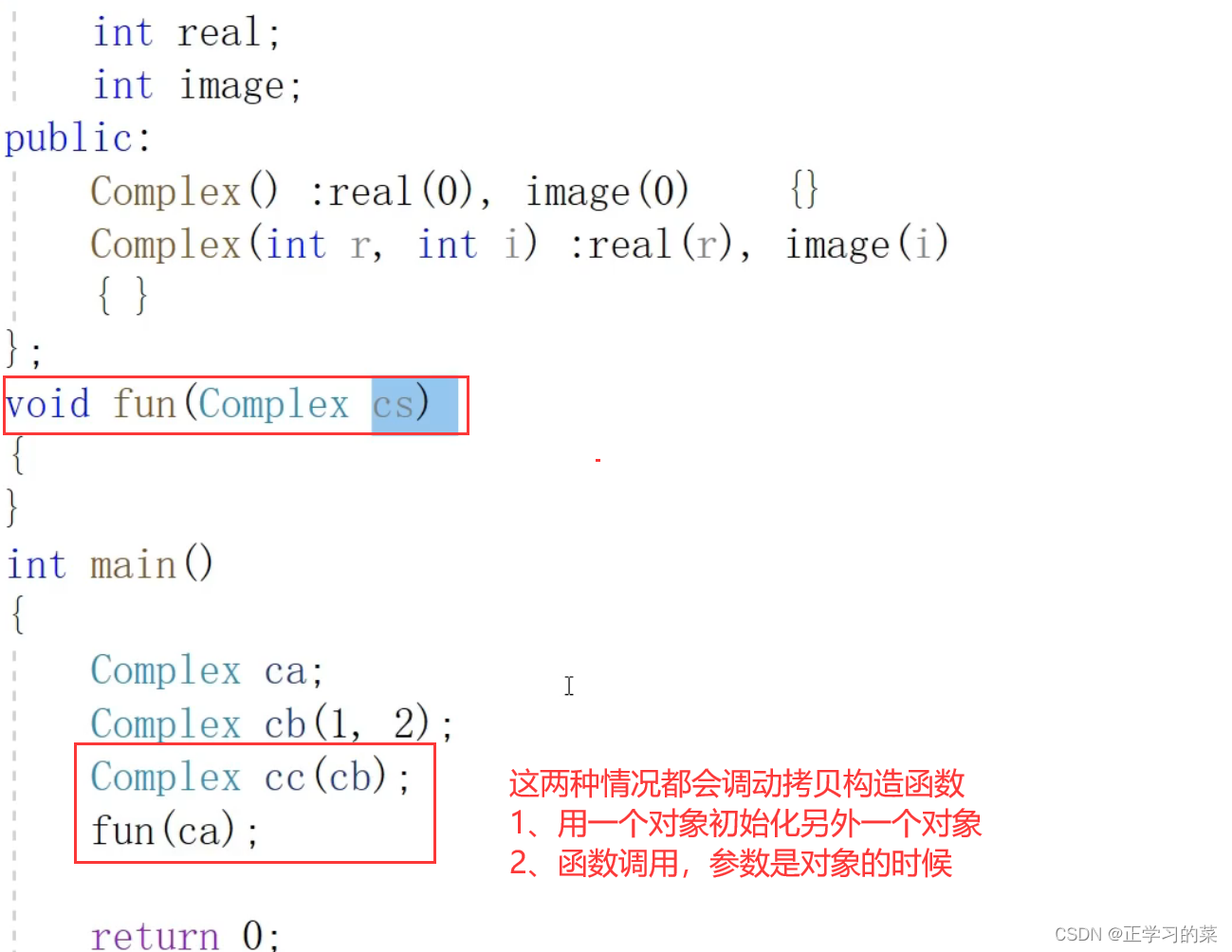
首先我们创建了sta对象,然后分别入栈数据12、23;
然后通过函数调用,将类作为参数进行传递,因此在fun函数中,拷贝构建一个对象st;
注意:这里拷贝的时候,是按位拷贝,所以sta.data指向的堆区的一串连续空间也会拷贝给st.data。也就是sta和st的data域都指向了同一块堆区空间的首地址。此处为浅拷贝
接着,拷贝完成后,fun函数调用结束,会析构掉st对象,那对应的,原本的data域指向堆区的连续空间也会被删除
最后主函数结束,sta也会被析构掉,然后会对data域指向的堆区空间进行二次释放,此时就会出错
深拷贝
拷贝的时候,涉及到堆区空间的时候,需要重新再new一块内存
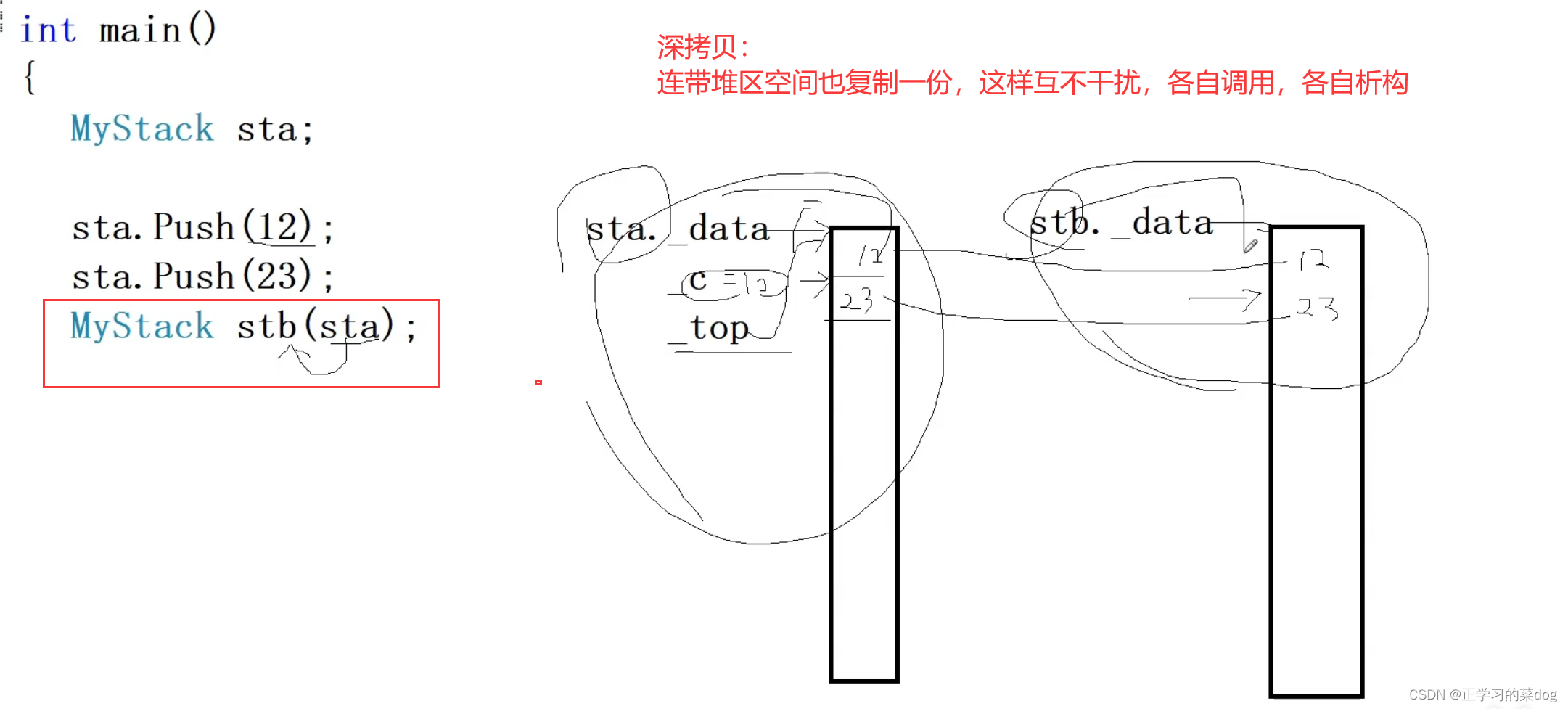

MyString类型的的深拷贝和浅拷贝
浅拷贝代码:

深拷贝代码:

第八部分 运算符的重载
完成Add函数,实现ca、cb两个对象相加
在加减法过程中,我们不会改变两个相加或者相减的对象ca、cb的属性值,只是将两个相加、相减的结果给到一个临时的、将亡值对象,然后由将亡值对象赋值给我们的cc

1、运算符重载的概念:
运算符的重载实际是一种特殊的函数重载,必须定义一个函数,并告诉C++编译器,当遇到该重载的运算符时调用此函数。
这个函数叫做运算符重载函数,通常为类的成员函数。
定义运算符重载函数的一般格式:
返回值类型 类名 : : operator重载的运算符(参数表)
{.......}
operator是关键字,它与重载的运算符一起构成函数名。因函数名的特殊性,C++编译器可以将这类函数识别出来。
1.1、实现+、- 操作:

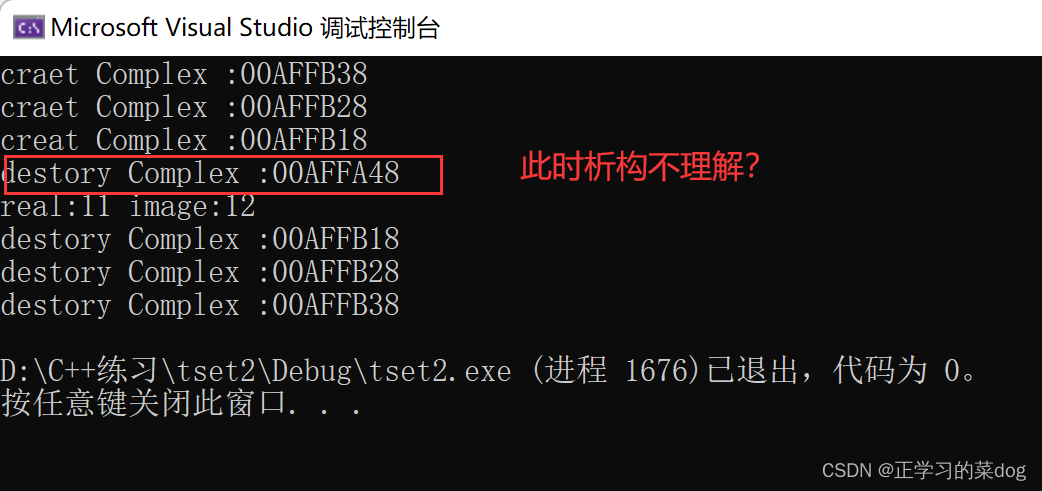
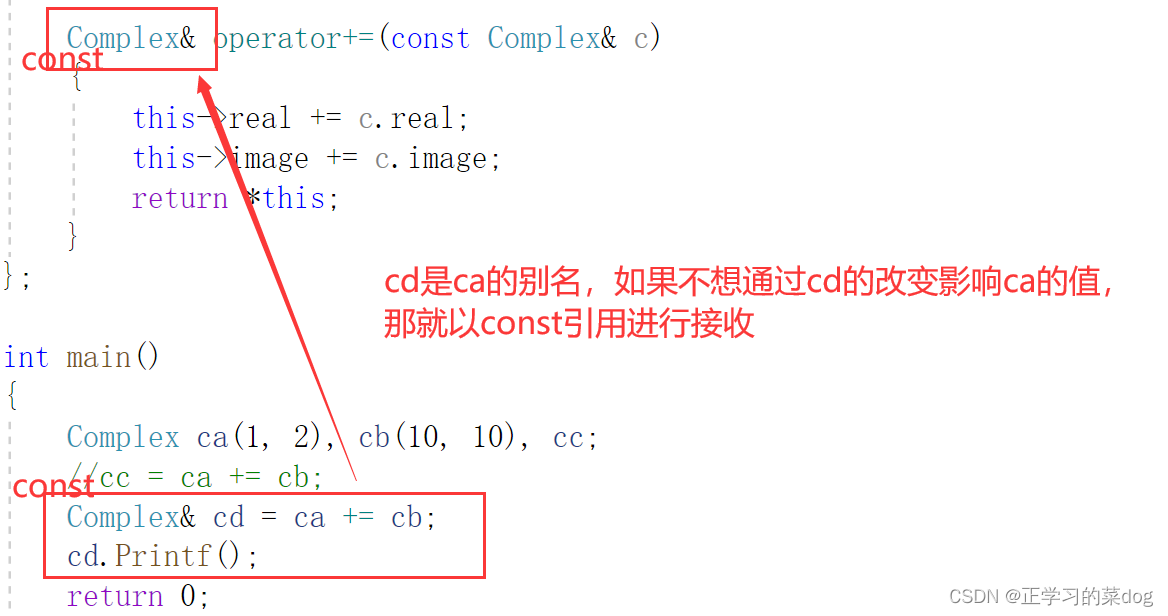
1.2、实现+=操作:
以值形式返回

结果:
以引用形式返回
注意ca的生存期不再+=函数内部,所以不受函数影响,可以以引用形式返回
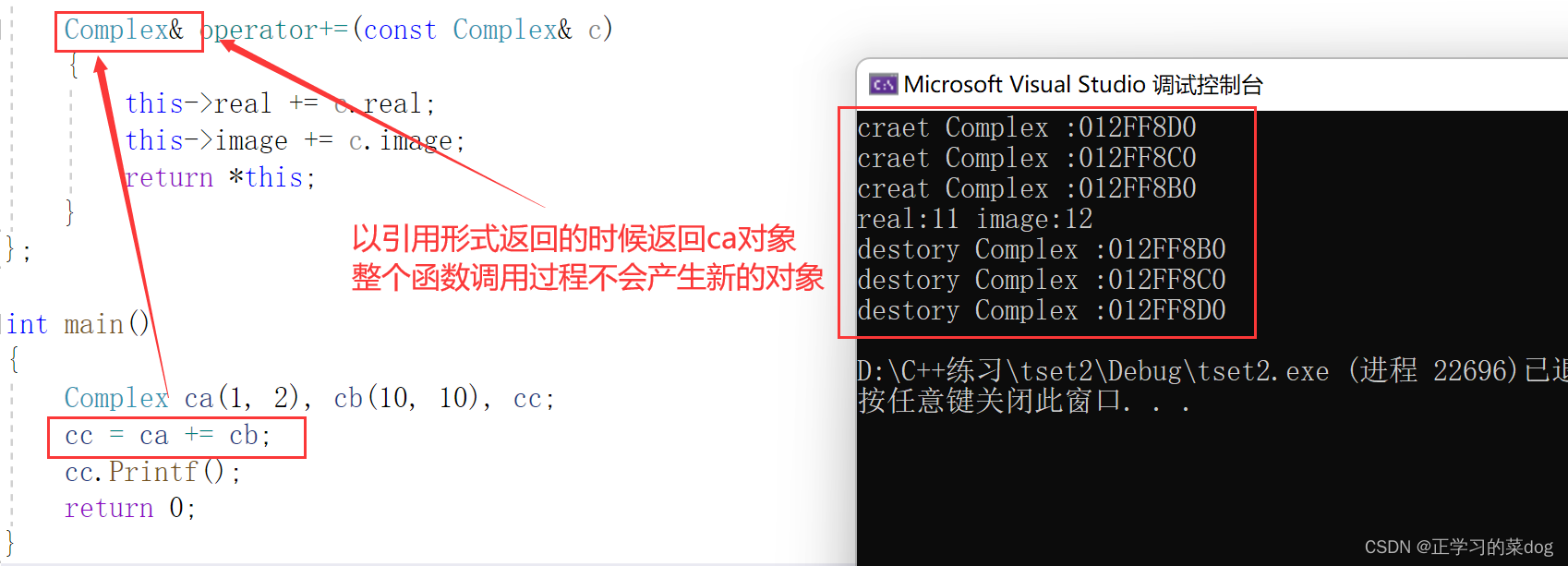
如果以引用返回,不希望以引用接收,那就只能用值方式接收,或者以常引用方式接收
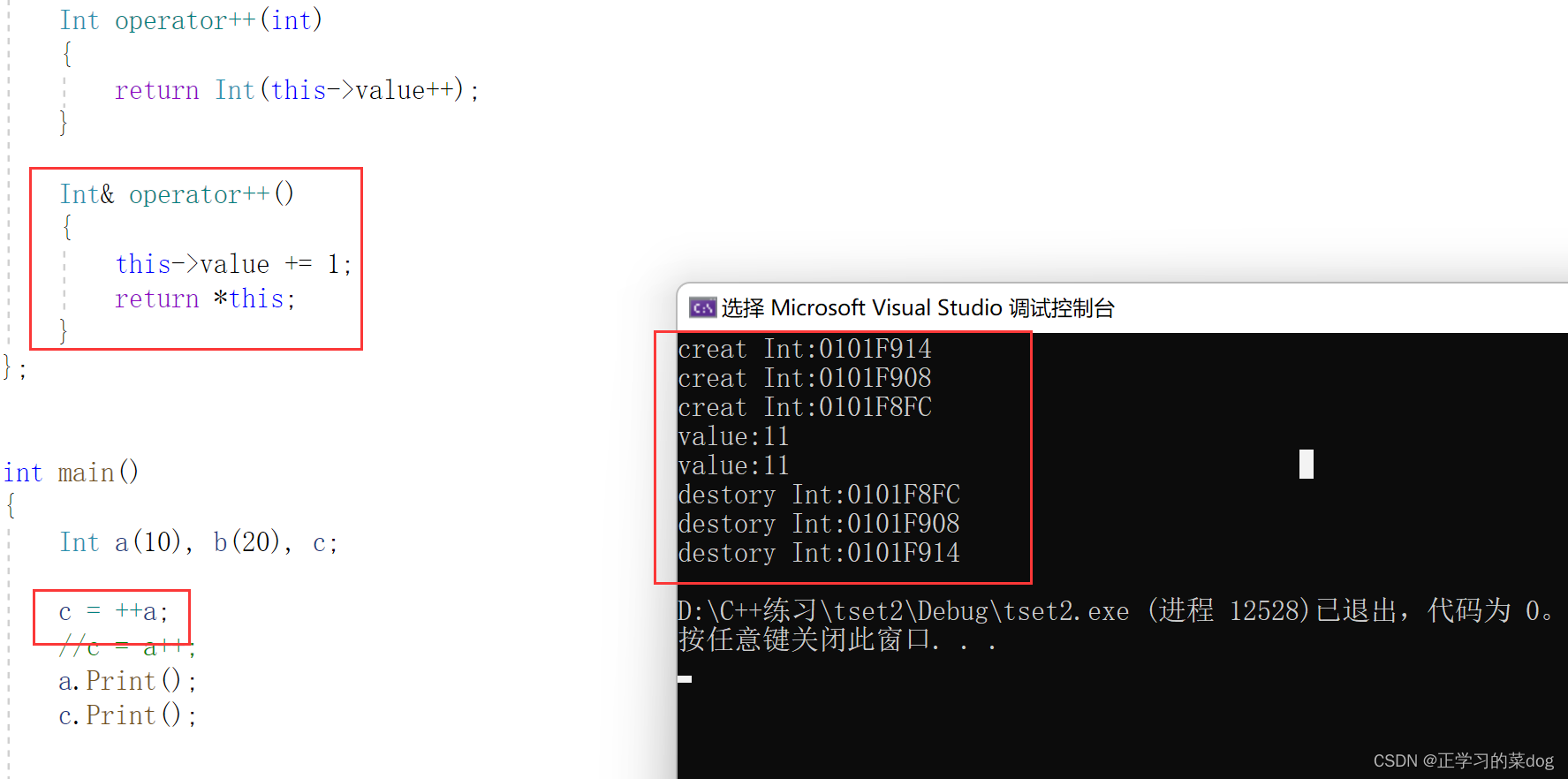
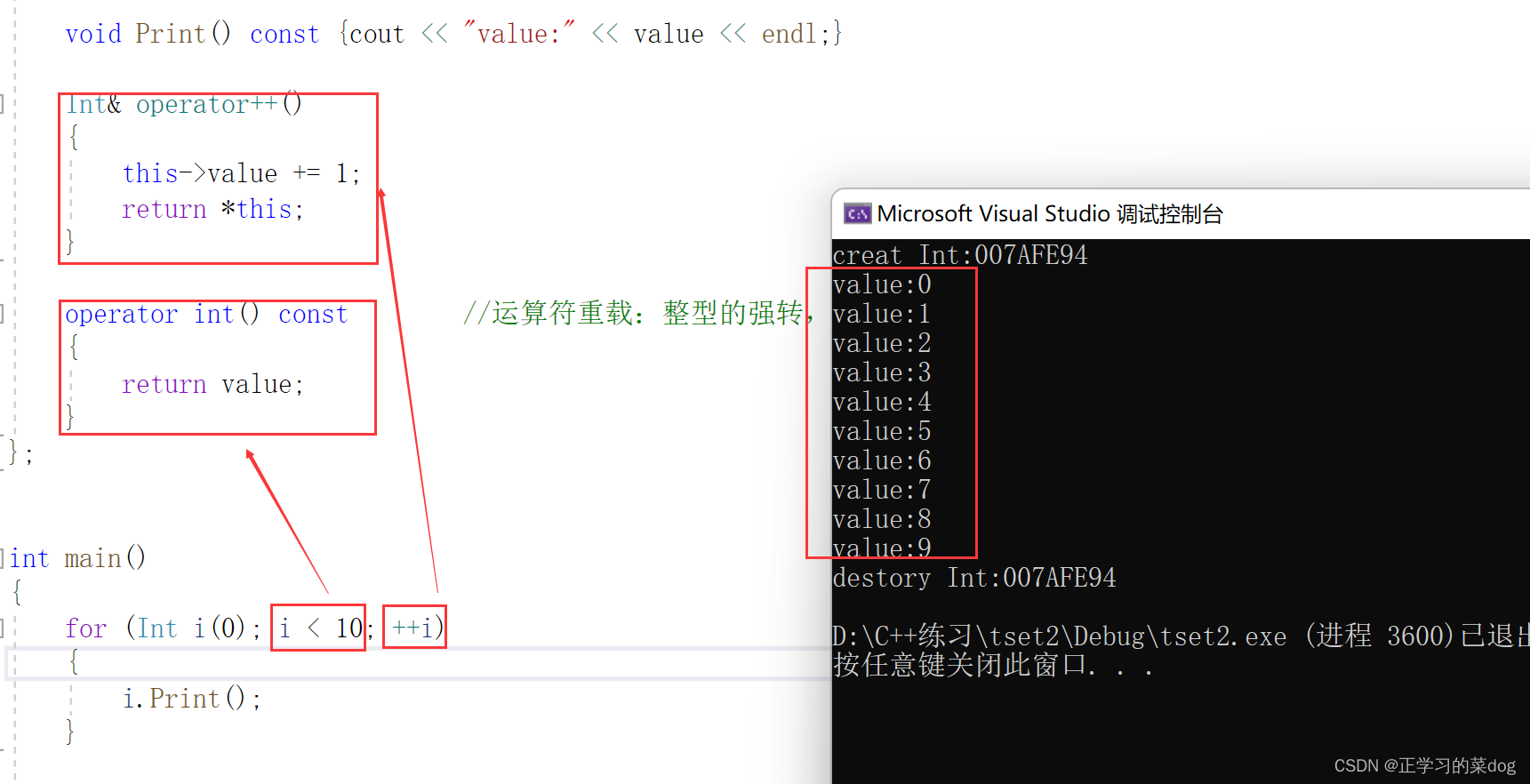
1.3、实现前置++、后置++
前置++:
后置++:
2、c语言也存在运算符的重载:
比如:整型之间可以相加、浮点型之间也可以相加

3、C++中一共存在6中缺省构造函数

4、赋值语句的运算符重载
默认的缺省赋值函数,是按位赋值,即下方方式是按位赋值
4.1、防止自己给自己赋值
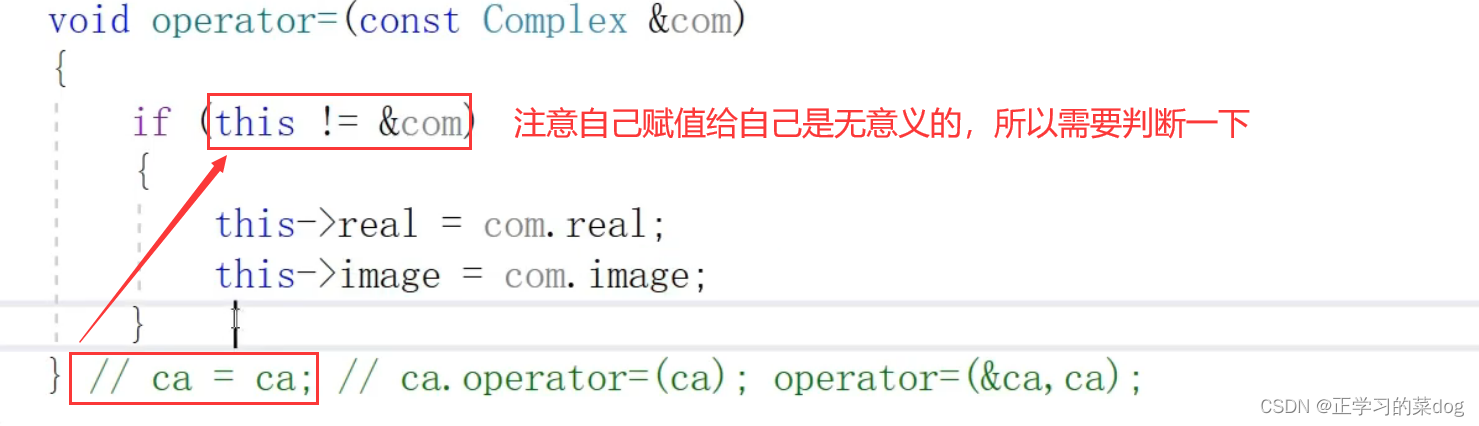
4.2、连续赋值

4.3、函数调用中,不能以引用方式返回局部对象
函数调用中存在局部对象,以值形式返回是正确的,不能以引用形式返回局部对象。
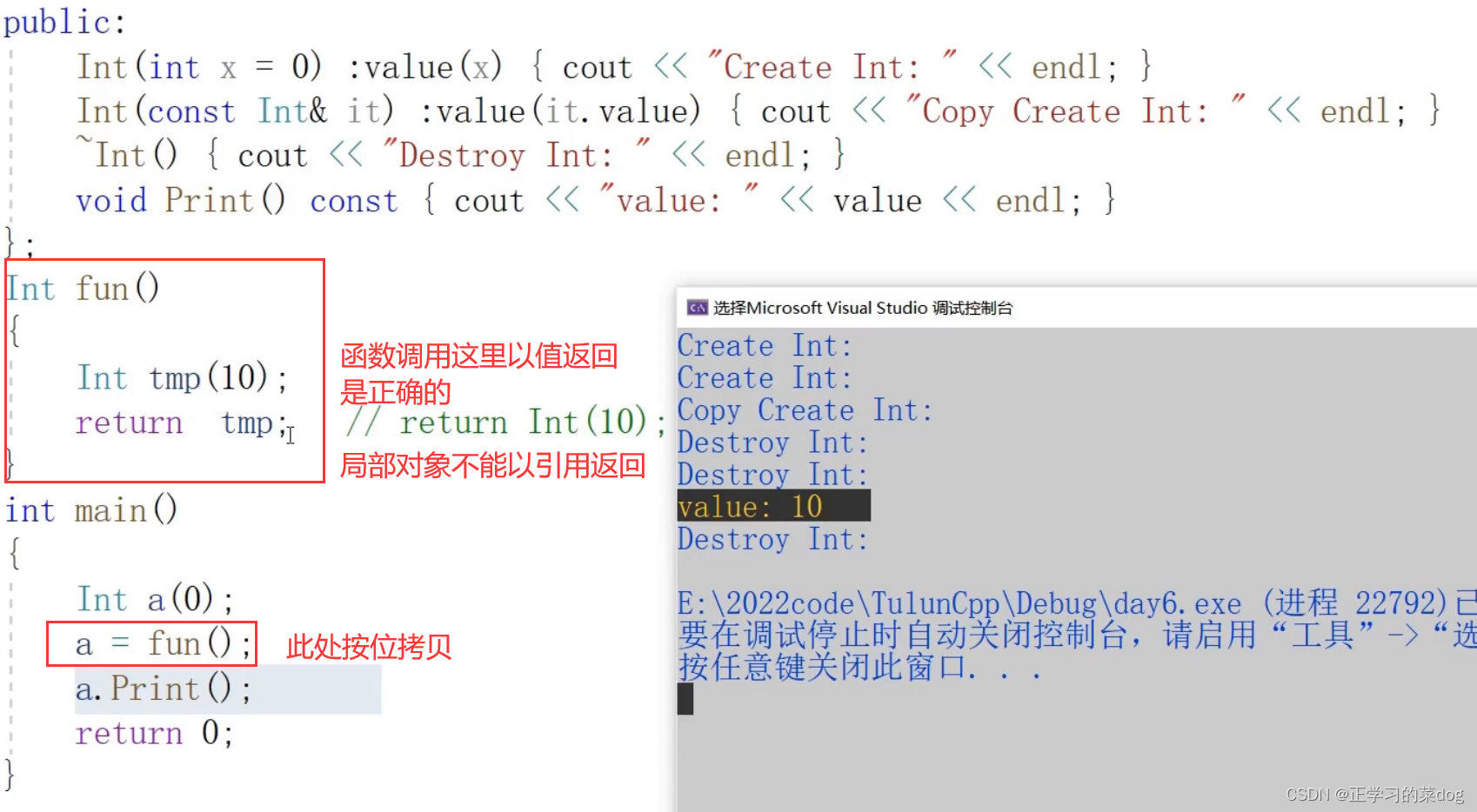
如果是以引用形式返回这里的局部对象tmp,那么在a = fun()这个赋值过程中,会取a和tmp这两个对象的地址,然后按位拷贝。这个赋值过程是非常简单的,由4步汇编代码构成
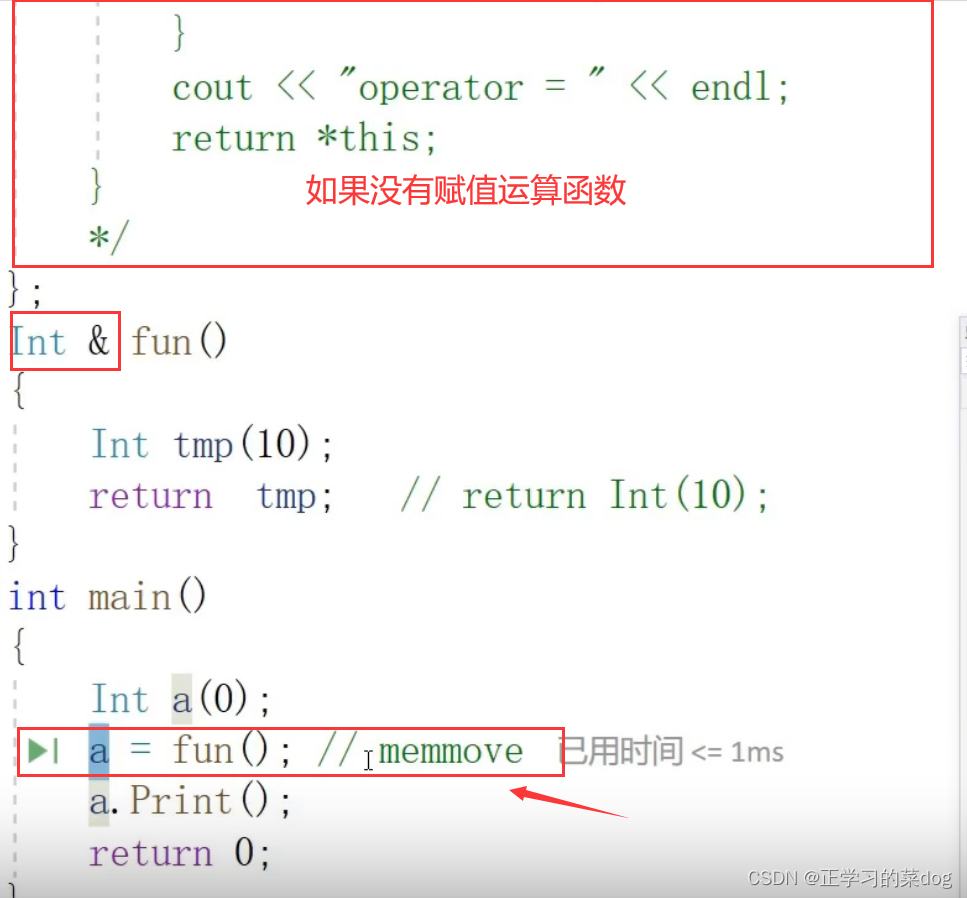
如果函数fun以引用形式返回,a = fun()这个赋值过程,也可以得到a为10,但是这个过程是不正确的。如果给出我们的赋值运算函数,这个时候就可以看到,a最终结果就是一个随机值,因为在函数fun()函数调用结束之后,fun()栈帧被回收,但是tmp的地址是存在的,这个地址所指向的值还没被系统清理;但是我们给了赋值运算函数的时候,就会在a = fun()这里调用赋值运算函数,这个时候就会对栈帧进行清理,原本tmp地址所残留的值10就会被清理掉,所以最后a的值就成了随机值
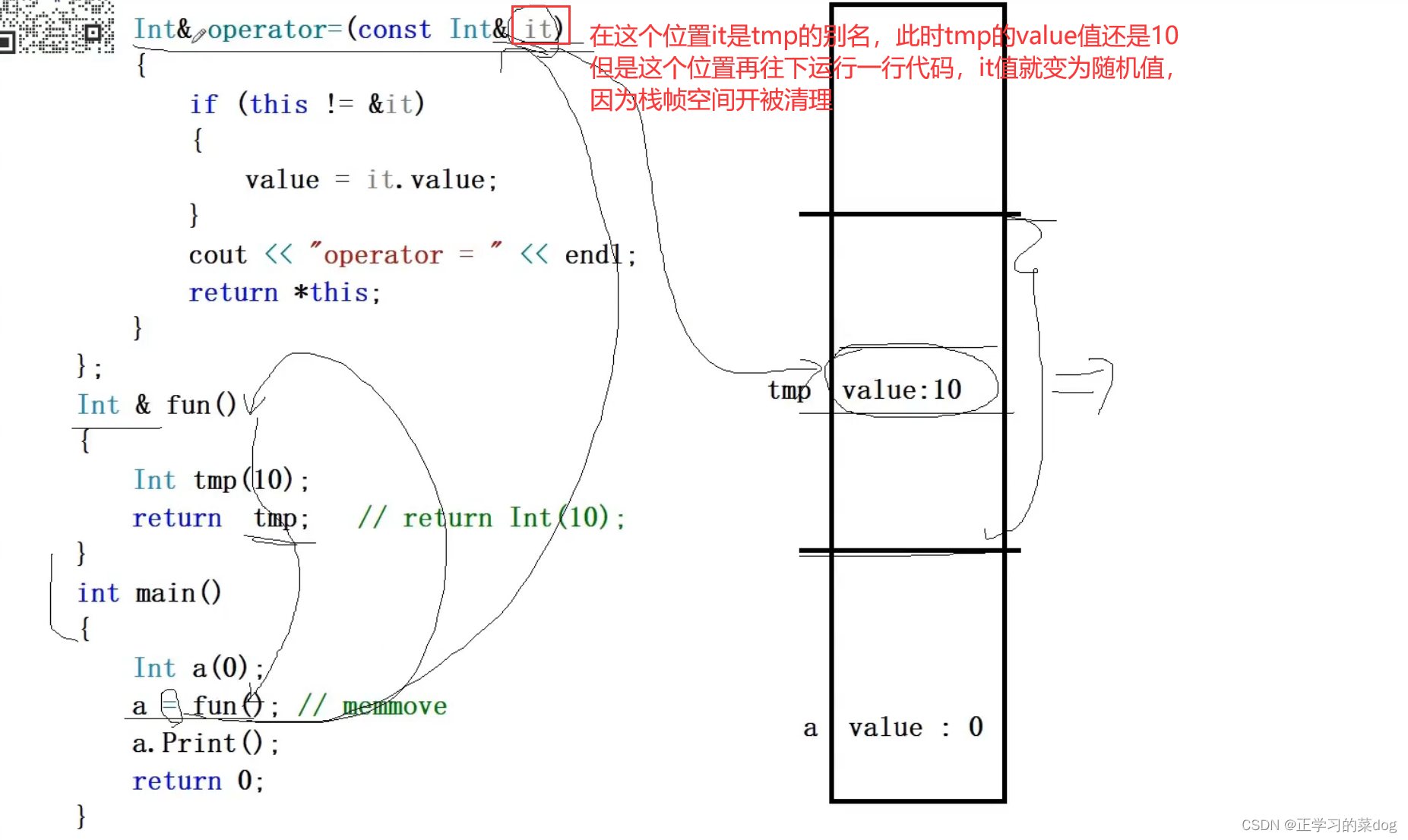
在Linux平台中,不论是有没有添加赋值运算函数,只要是以引用形式返回函数结果,都会发生段错误
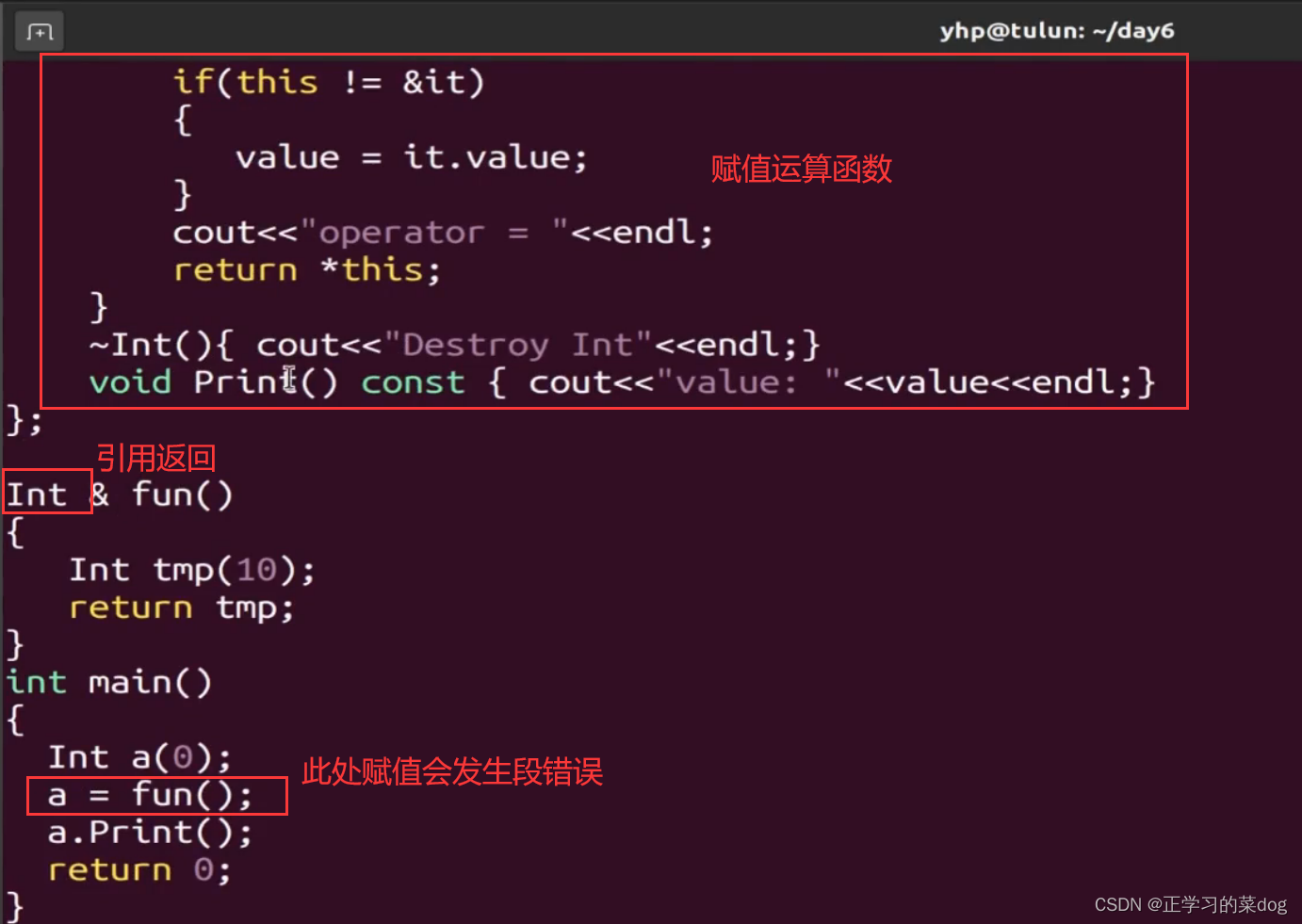
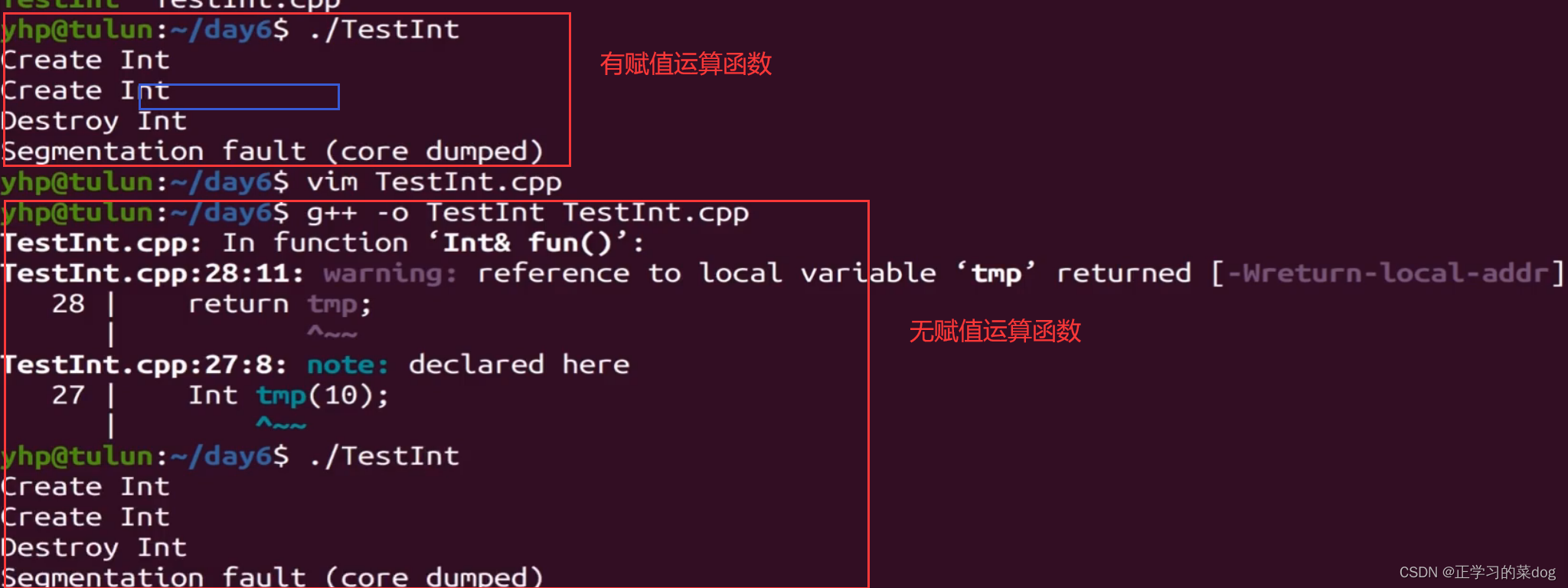
5、深赋值和浅赋值
没有写赋值语句的时候,系统默认的是浅赋值,当对象中的某个属性是指向堆区空间的指针的时候,就会出问题,所以需要深赋值

浅赋值:

深赋值:
先释放原本自己的空间,再把对方的空间拷贝进来,然后再new,memmov

6、拷贝构造与运算符重载的区别
拷贝构造函数可以构造一个新对象;但是赋值运算这里,只能是对象赋值给对象,不能是对象赋值给某个空间
因为在C++中对象和空间是分离的。有空间不一定有对象,必须调动构造函数创建对象,但是有对象了就一定有空间
举例:Int包装类
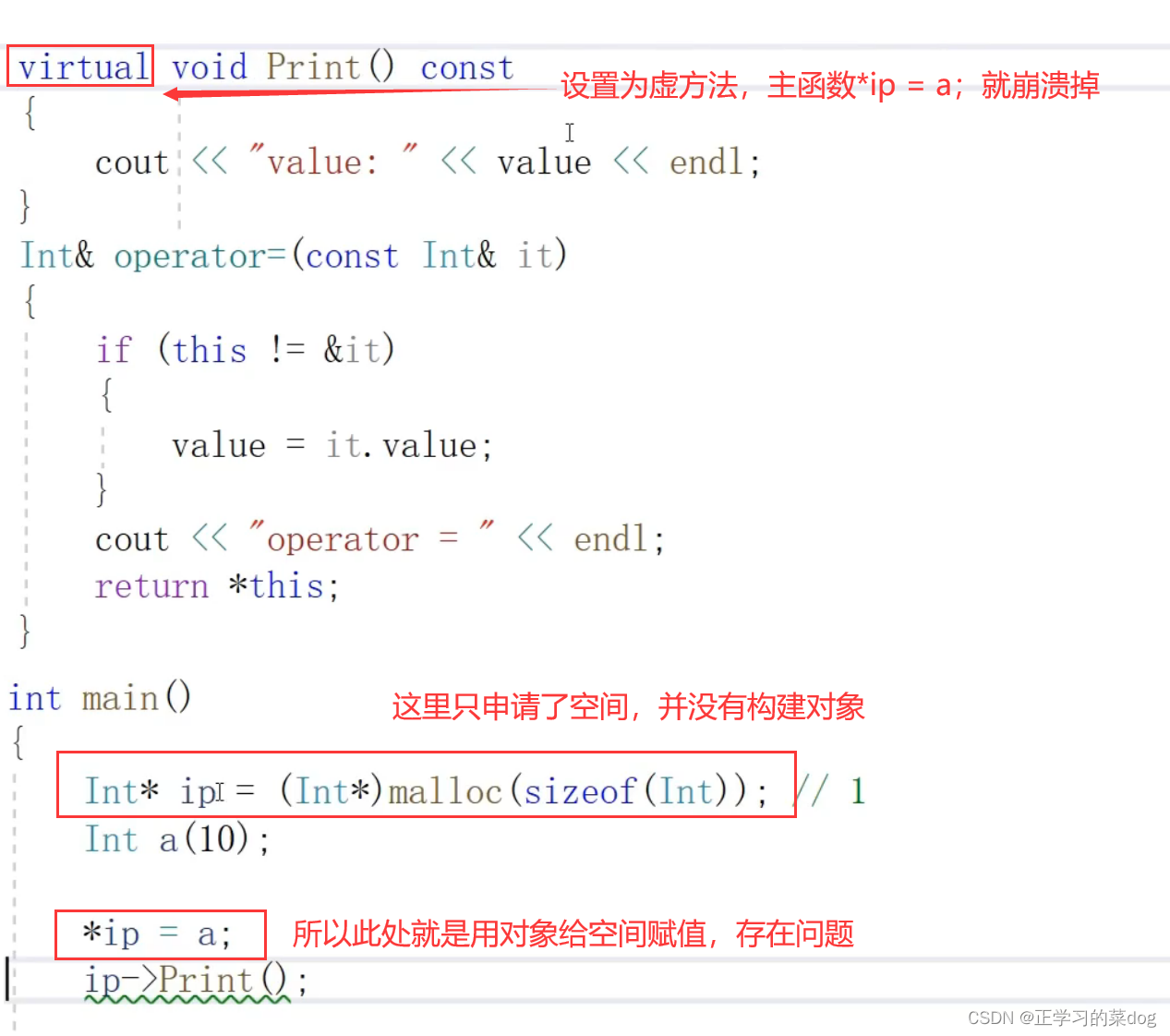
此处需要new一个对象

举例:MyStack

主程序:需要new一个对象
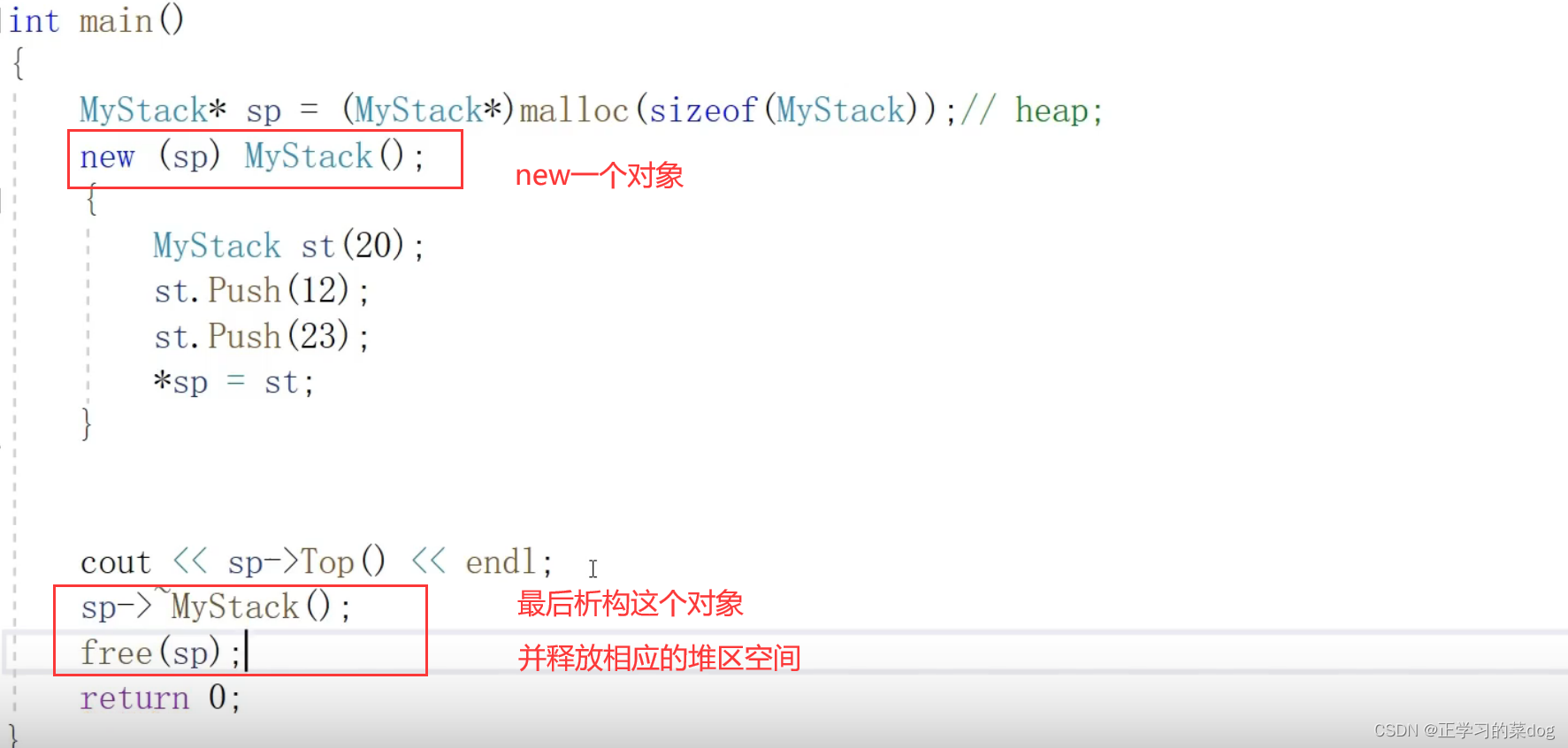
7、运算符重载总结
1、对象和内置类型数据实现相加(+):

2、对象和内置类型数据实现加等(+=):
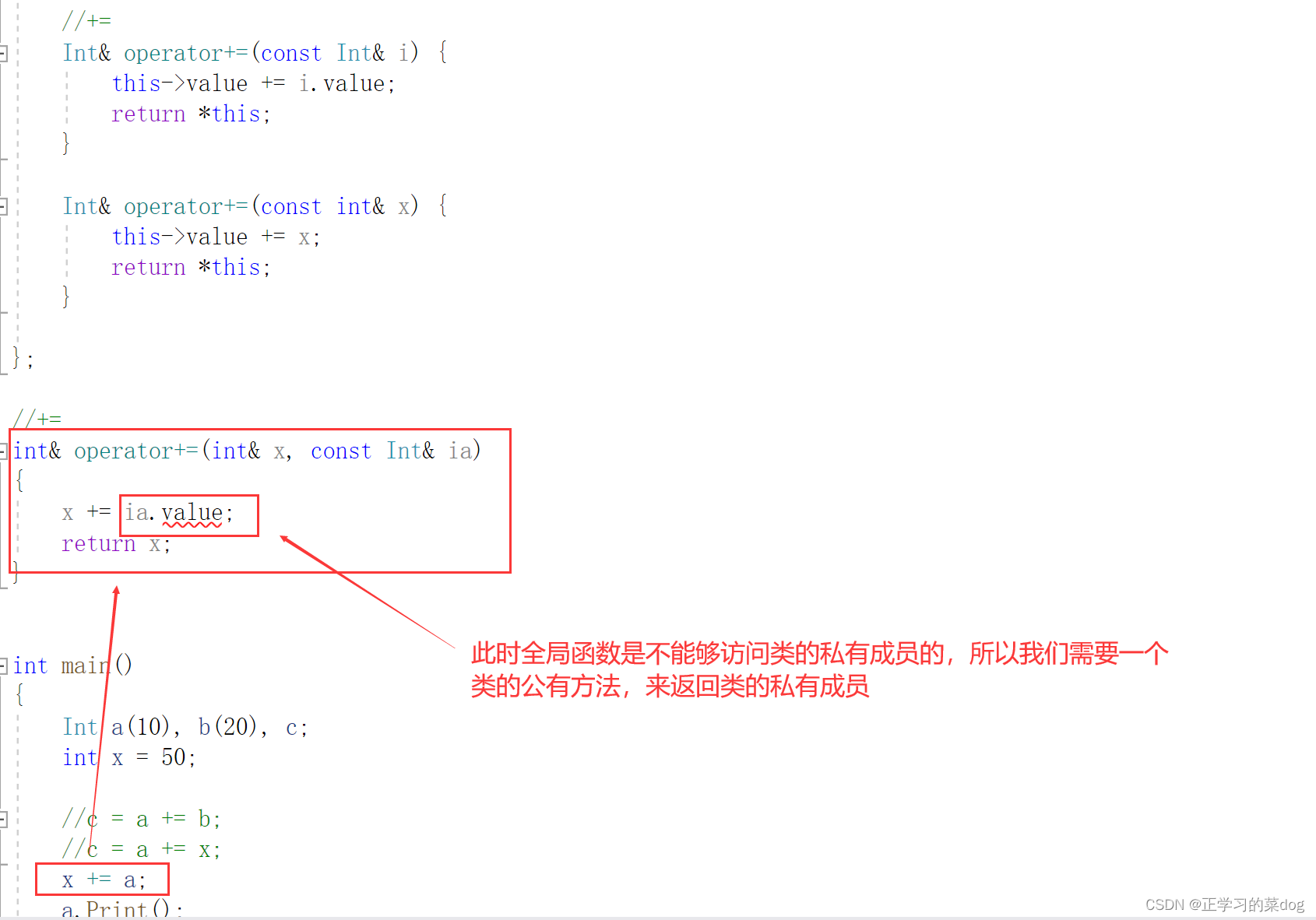
解决办法:(参考5.4问题2)
3、对象强转为整型

for循环举例观察前置++,和对象转换为整型(每次比较i都转为int类型和10比较)
第九部分 项目:My_String
1、柔性数组:
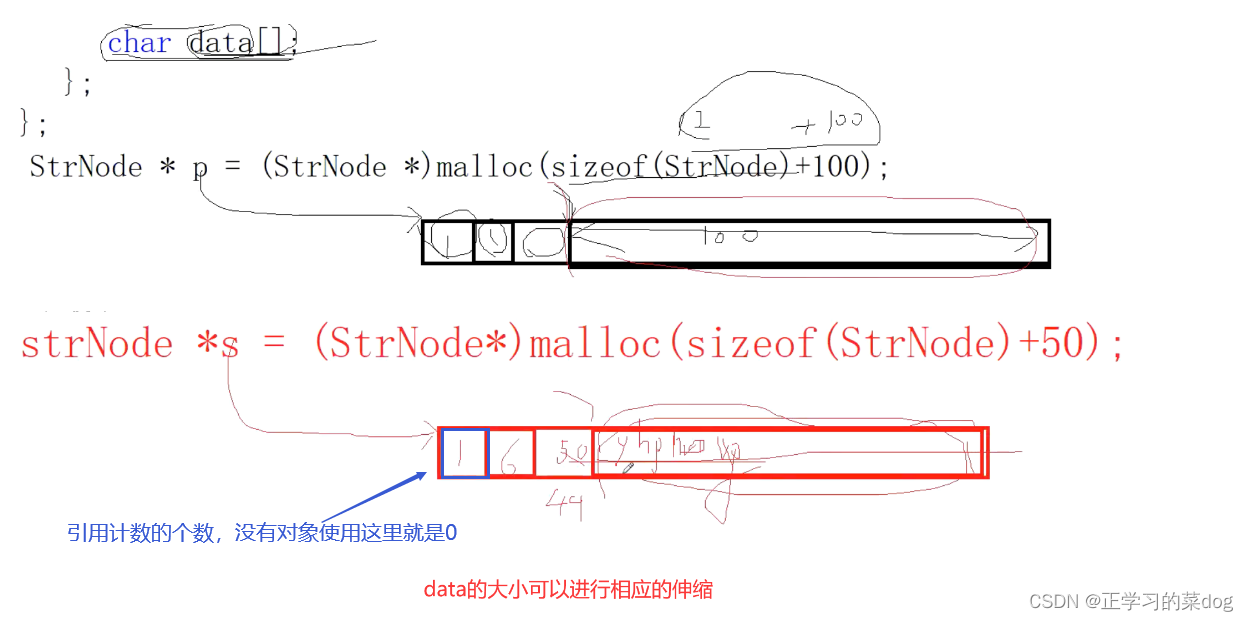
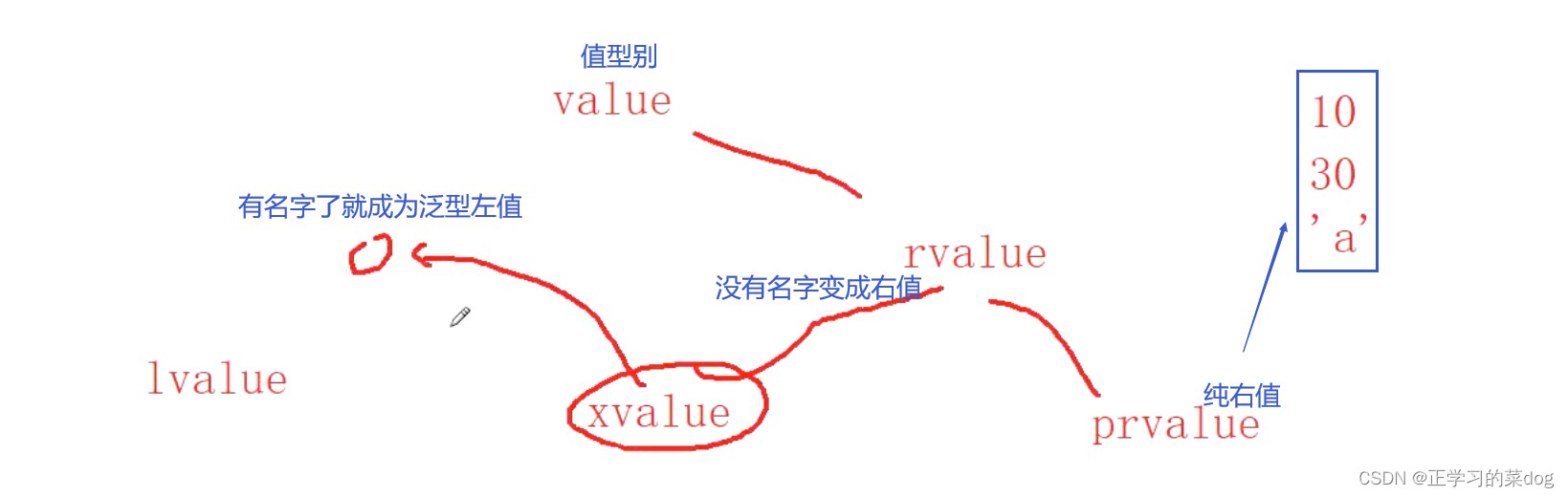
值型别概念:

第十部分 友元函数
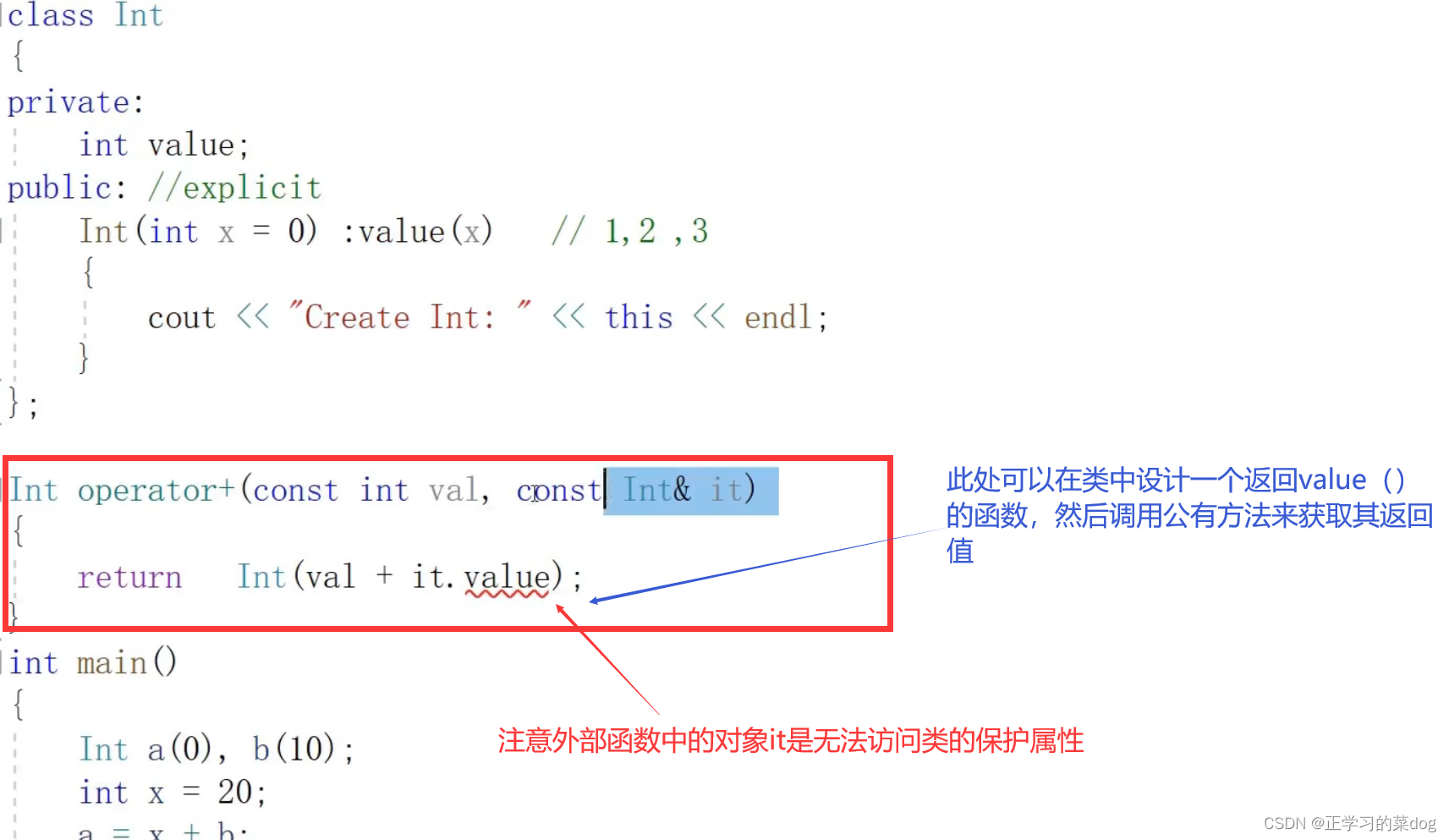
友元friend机制允许一个类授权其他的函数访问类所产生对象的非公有成员
首先,要明确全局函数(类外函数)不能够访问类的私有、保护属性,只能访问类产生对象的公有方法、公有属性。
1、友元的特点:
1.不具有对称性:A是B的友元,并不意味着B是A的友元。
2.不具有传递性:A是B的友元,B是C的友元,但A不是C的友元。
3.不具有继承性:Base类型继承Object类型,如果Object类型是A的友元,但Base类型不是A友元。
2、友元分为:
外部函数友元,成员函数友元,类友元。
2.1、外部函数友元
此处Int operator+()是一个外部函数,不属于类的成员函数。它是这个类的友元函数,它没有this指针,也没有所谓的cosnt常方法,它也不分公有、私有
友元函数可以访问这个类的公有、私有、保护属性

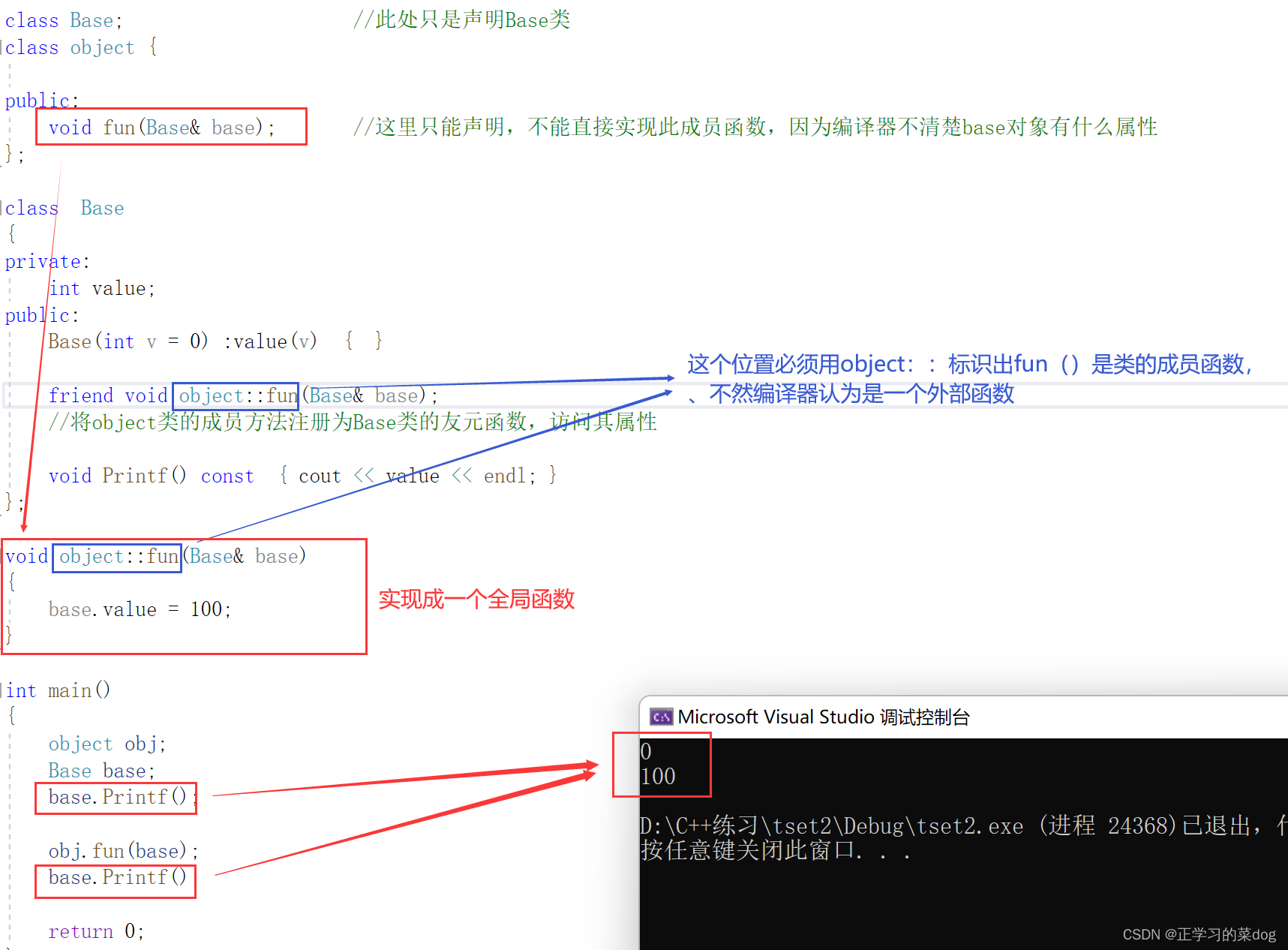
2.2、成员函数友元(用的少)
知识点:类的声明;外部函数和类的成员函数的区分;
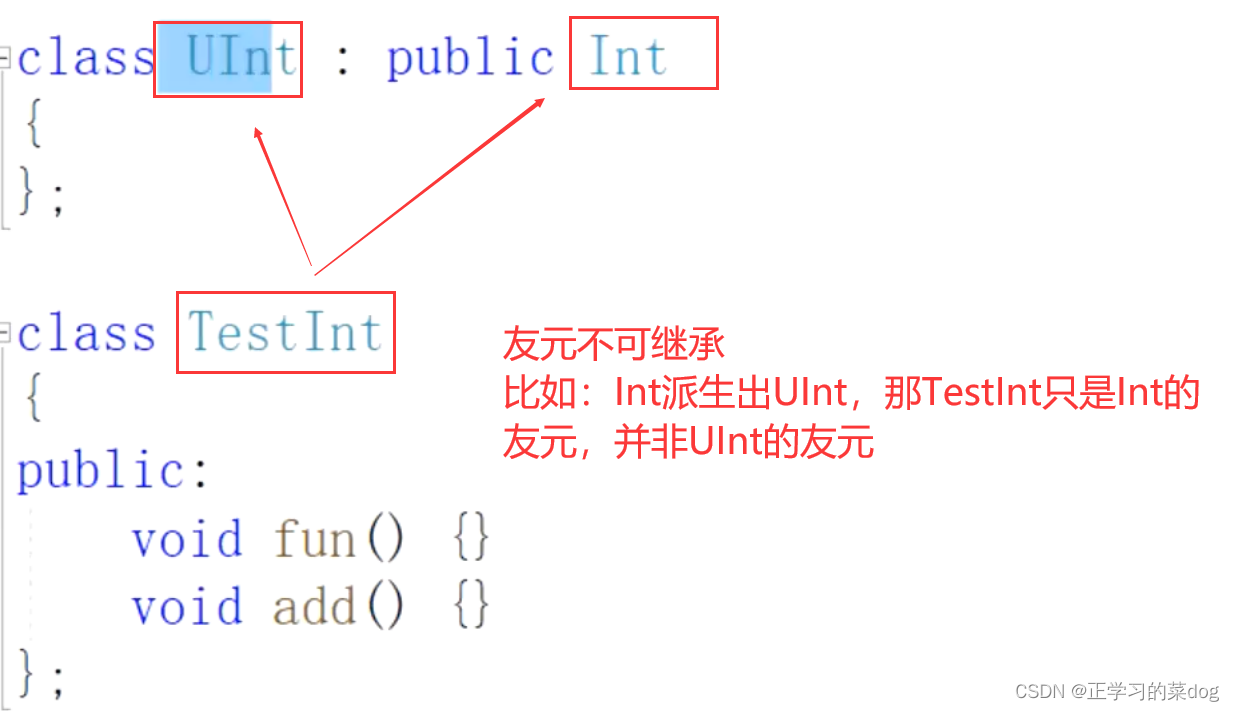
2.3、类友元(用的多)
我是你的友元,我可以访问你的属性,反之不可

友元不可继承
3、总结:
1、友元函数不是类的成员函数,在函数体中访问对象的成员,必须用对象名加运算符“::”加对象成员名。但友元函数可以访问类中的所有成员,一般函数只能访问类中的公有成员。
2、友元函数不受类中的访问权限关键字限制,可以把它放在类的公有、私有、保护部分,但结果一样。
3、某类的友元函数的作用域并非该类作用域。如果该友元函数是另一类的成员函数
则其作用域为另一类的作用域,否则与一般函数相同。
第十一部分 静态成员
1、static关键字
在函数中,局部变量(栈区)添加static关键字后,其可见性没有改变,生存期发生改变(.data区),函数死亡,此局部变量依然存在,只有程序结束才死亡;
在C语言中,main.c文件中的全局变量(.data区)添加static关键字后,生存期没有改变(.data区),但是可见性发生改变,原本是在多文件中可用,添加后只在当前文件中可用,同一工程中的其他文件不可用;
给函数添加static关键字后,可见性发生改变,只在当前文件中有效
2、知识小点

3、静态属性
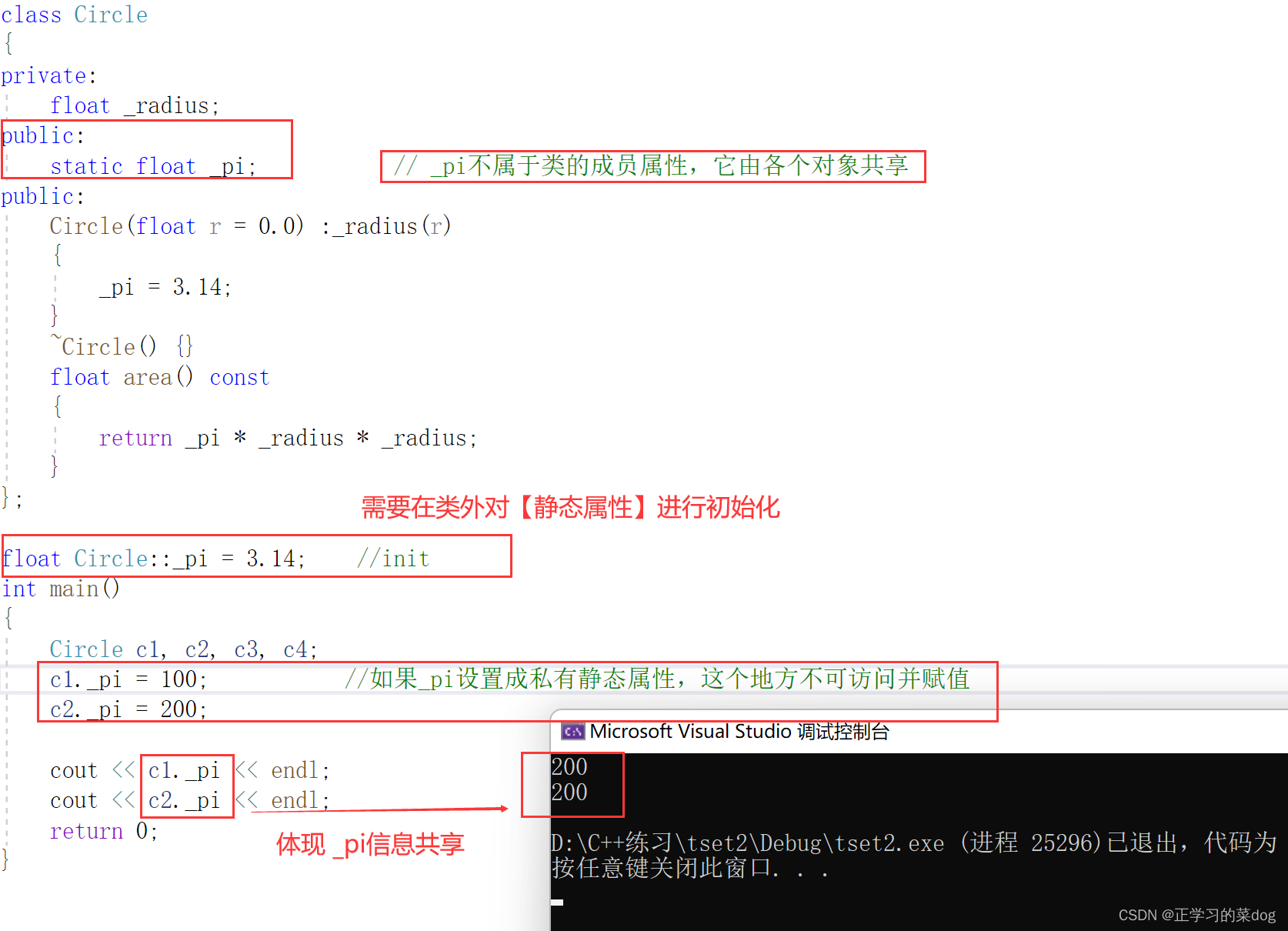
设计静态数据成员目的是信息共享。【其不属于类的成员属性】,由同类的所有对象共享
3.1、_pi不存在this指针

自己验证:
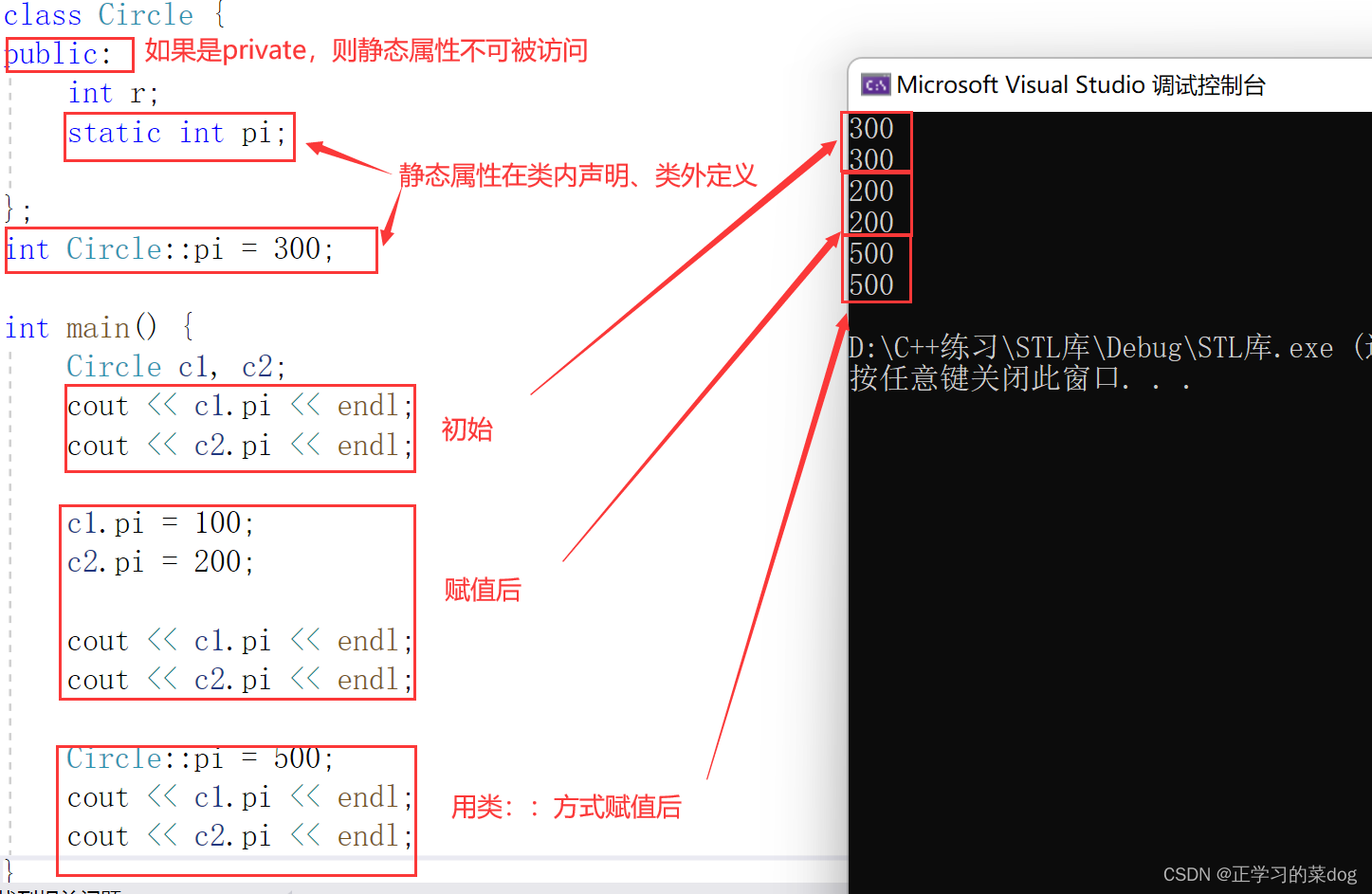
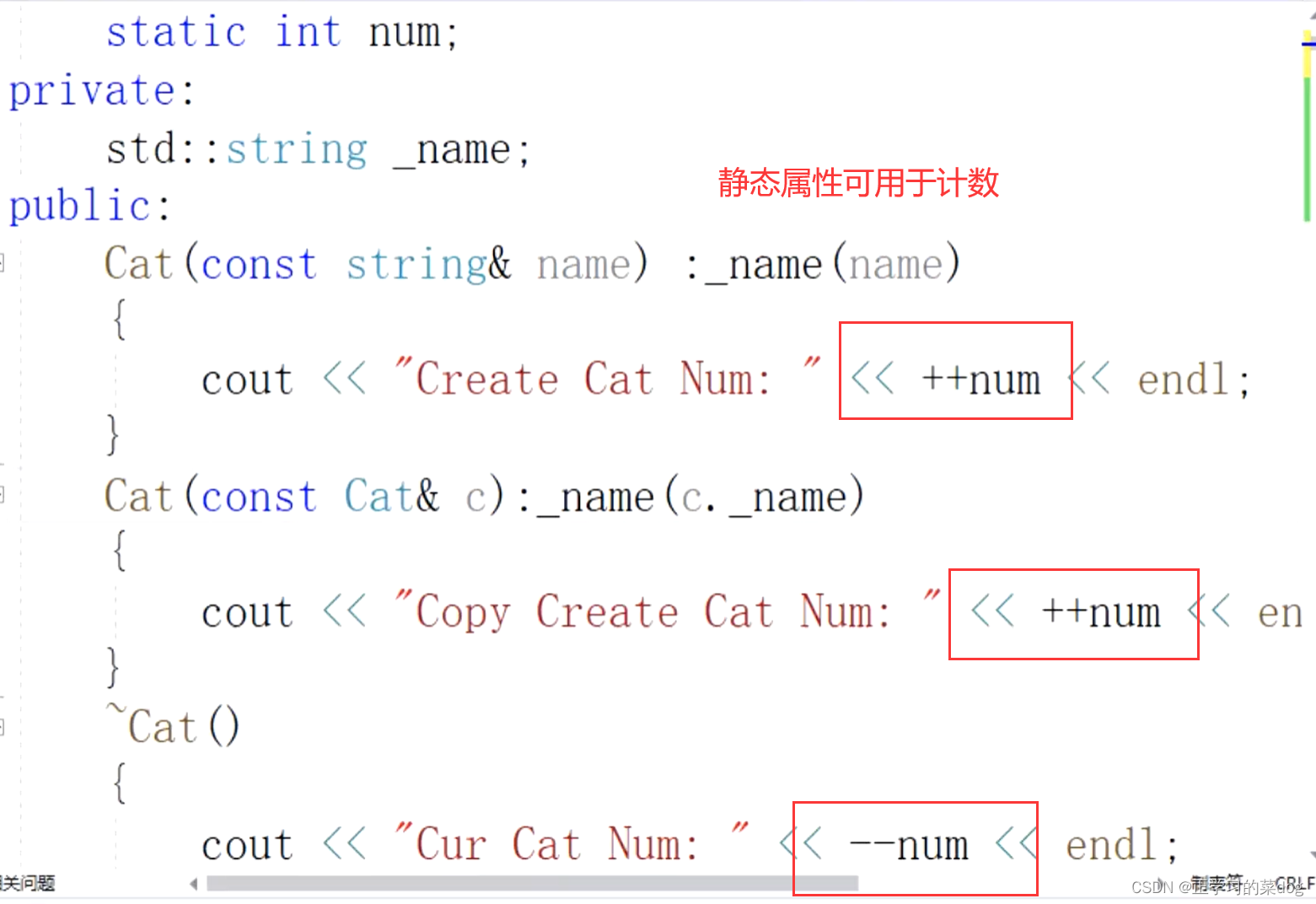
3.2、静态属性可用于计数:
3.3、特殊静态属性:
只有是const常性、整型类型的静态属性,在定义的时候可以在类内赋值

4、面试多问:
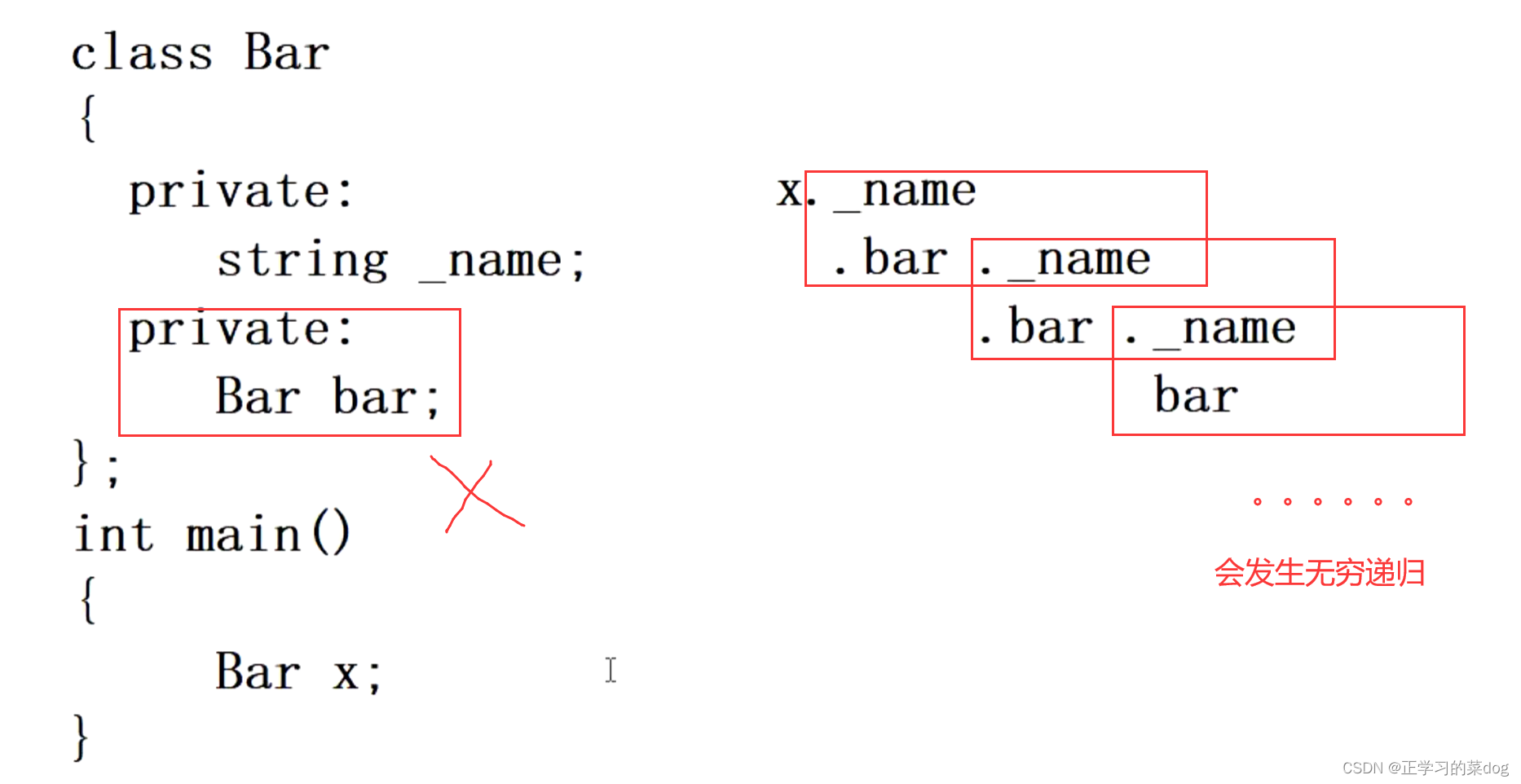
在设计类型的时候,对于自身类:类里面的属性成员只能包含指针属性、或者是静态属性,不能是值属性、引用属性
4.1、设计类型时候,不要在属性中使用自身的类型对象,会发生无穷递归
4.2、指针可以不用构建一个对象实体,此处是可以编译通过的

4.3、【静态属性】对象(看不大懂)


4.4、当类的属性中有【引用类型对象】,会发生无穷递归

5、总结:
1、设计静态数据成员目的是信息共享,和信息交流
2、类的静态数据成员为同类所有对象所共享,不属于某个具体的实例对象。
3、类的静态数据成员必须在类外定义,定义时不添加static关键字;不能在构造函数的初始化列表中创建。
4、类的静态数据成员类型是int,short, char,long long ,并且是const ,可以在类中直接初始化,也可以在类外初始化
5、在类的成员函数中使用静态数据成员,静态数据成员之前没有this
6、当类的静态数据成员为公有时,可以在外部函数使用:类 :: 静态数据成员名 或 对象 . 静态数据成员名,可以在类体中定义自身的静态类型对象;当为私有时,只能在类内调用。
6、静态方法
函数成员说明为静态,将与该类的不同对象无关。静态函数成员的调用,在对象之外可以采用下面的方式:
类名::函数名【或】对象名.函数名
与静态数据成员相反,为使用方便,静态函数成员多为公有。
6.1、静态方法没有this指针,它对所有对象共享
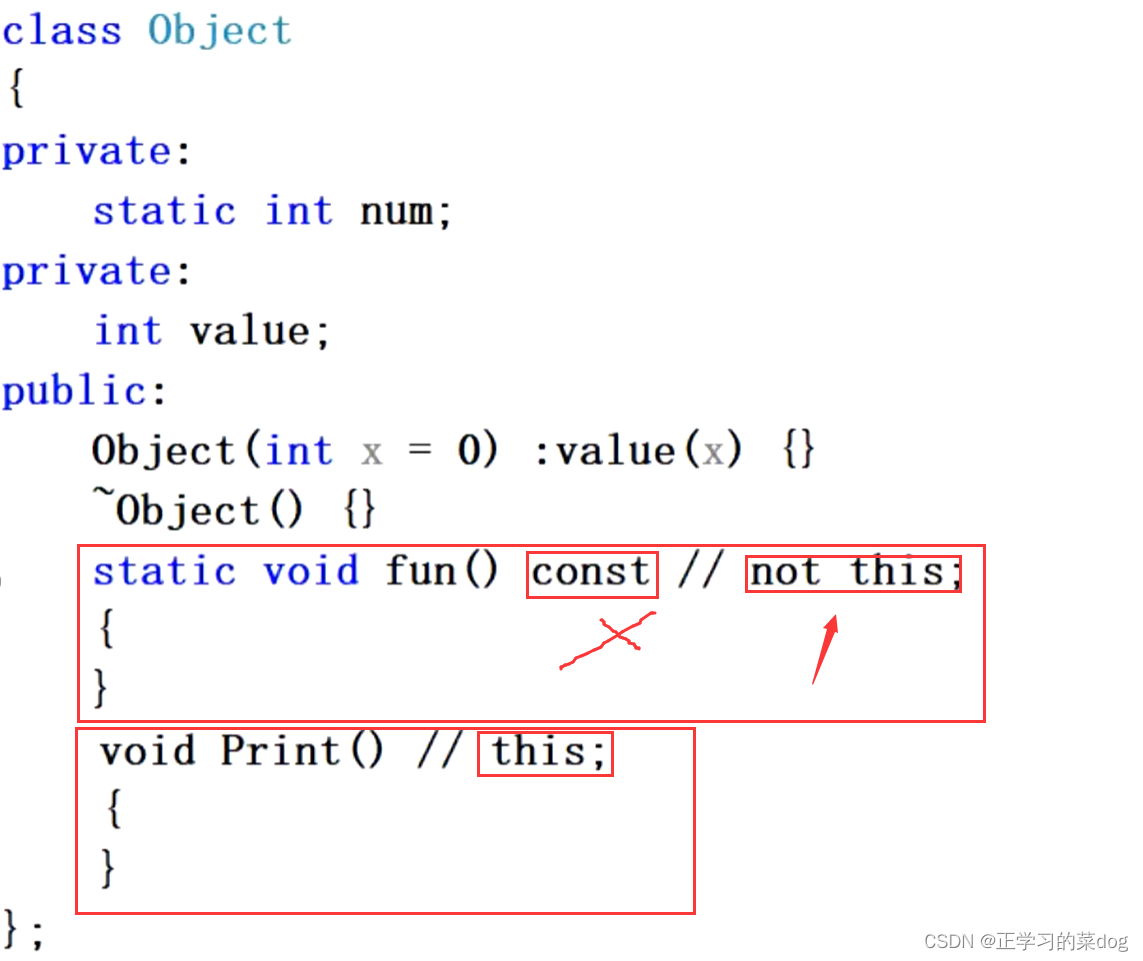
6.2、静态方法可以访问类产生对象的私有、公有和保护;全局函数是不可以访问私有、保护的,比如main主程序就不能访问
静态函数需要传入外部对象,或者定义一个局部对象然后访问其属性方法;成员函数因为有this指针指向对象的地址,所以不用传入

6.3、成员方法和静态方法之间相互调动

7、总结(重要):
一个常规的【成员函数】声明描述了三件在逻辑上相互不同的事情:
1、该类的成员函数能访问类声明的私有、公有和保护。
2、该类的成员函数位于类的作用域之中。
3、该类的成员函数必须经由一个对象去激活(有一个this指针)。
将一个函数声明为友元【友元函数】(外部函数)可以使它只具有第一种性质。
将一个函数声明为static【静态函数】可以使它只具有第一种和第二种性质。(静态函数不是全局函数,是类的静态成员函数,作用域在类里面)
第十二部分 对象和对象的关系
在一个系统中,一个对象可能与不同的对象相关,以下是不同的关系。
依赖(Dependency)(使用一个)
关联(Association)(使用一个)
聚合(Aggregation)(有一个)
组合(Composition )(有一个,"用...来实现")
继承(Inheritance)(是一个)
类模板(Class template)
1、依赖:
依赖关系是用一个带箭头的虚线表示的;他描述一个对象在运行期间会使用到另一个对象的关系;
与关联关系不同的是,它是一种临时性的关系,通常在运行期间产生,并且随着运行时的变化;依赖关系也可能发生变化;
显然,依赖也有方向,单向依赖,双向依赖;
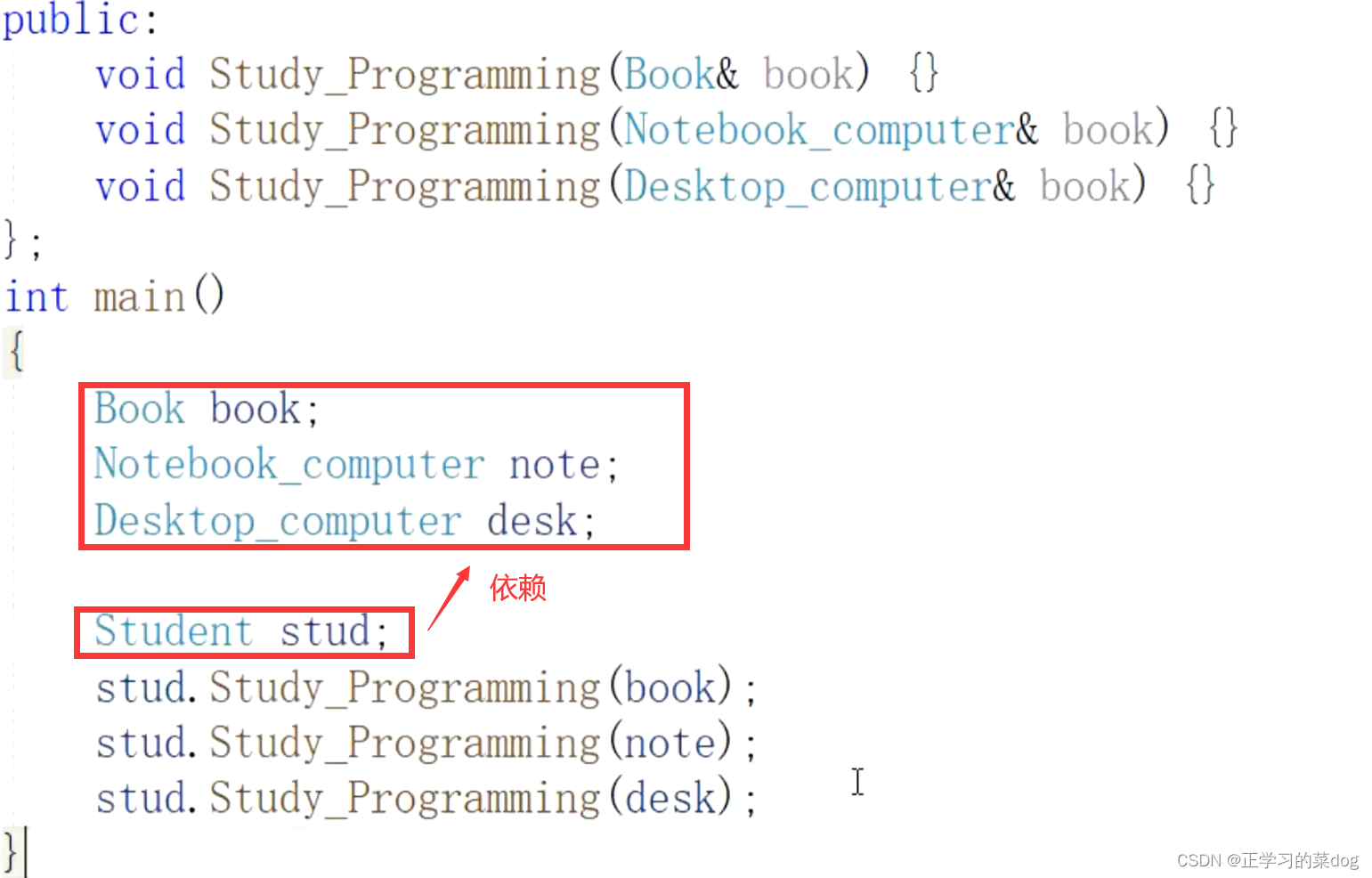
注意:在最终代码中,依赖关系体现为类构造方法及类方法的传入参数,箭头的指向为调用关系;依赖关系处理临时知道对方外,还是“使用”对方的方法和属性;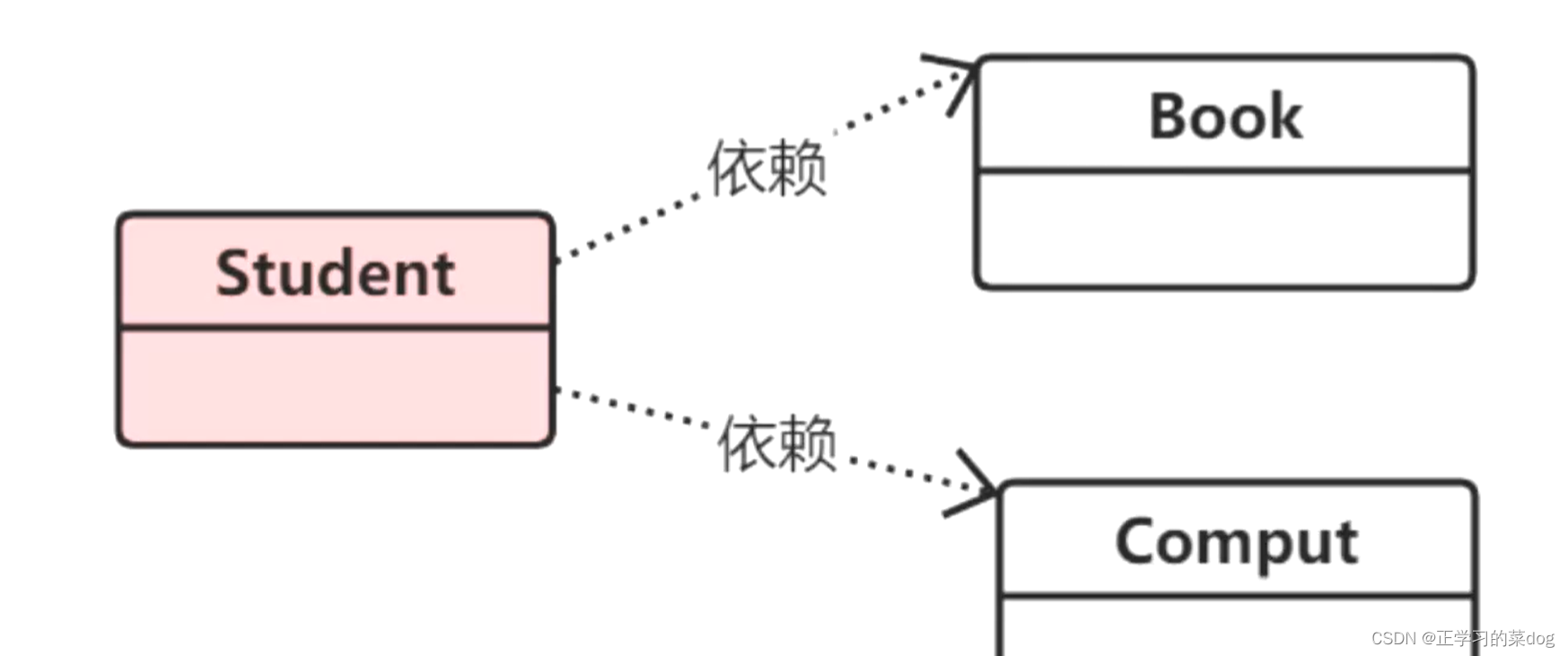
只在方法成员中传入其余对象,作为参数,而不在属性成员中使用。这种形式是依赖
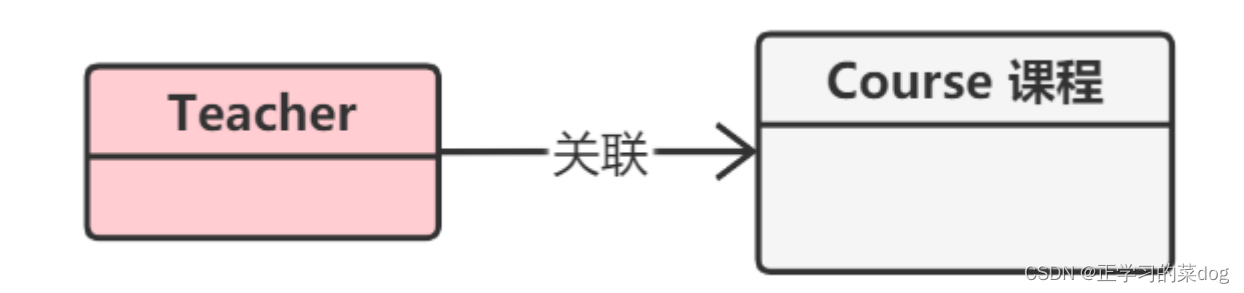
2、关联:
关联关系是用一条直线表示的;它描述不同类的对象之间的结构关系;它是一种静态关系(和一个对象关联后不能和其他对象关联),通常与运行状态无关,一般由常识等因素决定的;它一般用来定义对象之间静态的、天然的结构;所以,关联关系是一种“ 强依赖 ”的关系;
比如,教师和课程之间就是一种关联关系;学生和学校就是一种关联关系;
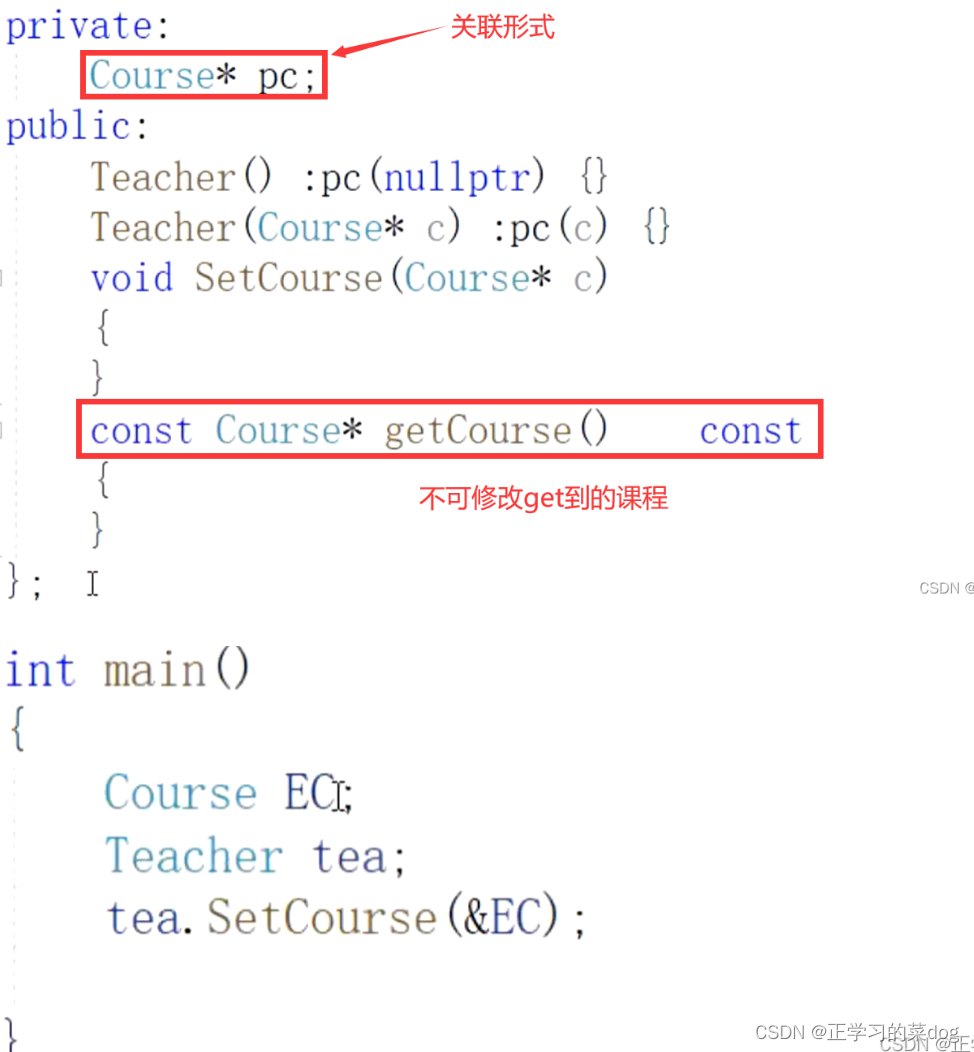
关联关系默认不强调方向,表示对象间相互知道;如果特别强调方向,如下图,表示Tearcher知道Course,但Course不知道Tearcher;
注:在最终代码中,关联对象通常是以成员属性(对象)或引用的形式实现;
在属性中用指针形式使用关联其他对象
弱关联(指针)
此处可以可以不断改变,老师可以教多门课程,这个是弱关联
强关联(引用)

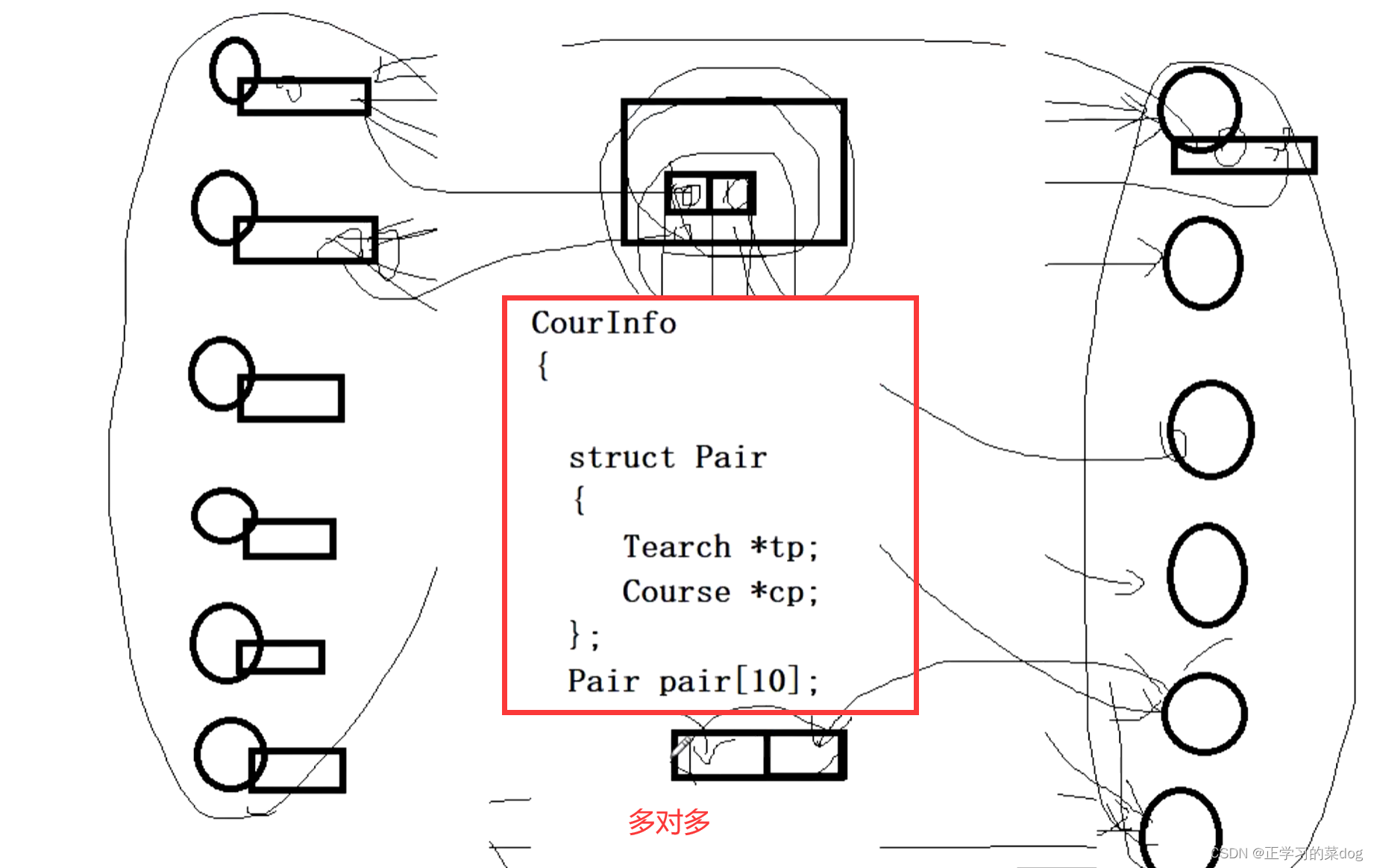
一对多:

多对多关联:
3、聚合(指针):
整体和部分的关系,...由什么构成
聚合关系用一条带空心菱形箭头的直线表示,如下图表示Point聚合到Circle上,或者说Circle由Point组成;
聚合关系用于表示实体对象之间的关系,表示整体由部分构成的语义;例如一个部门由多个员工组成;
与组合关系不同的是,整体和部分不是强依赖(生存期控制),即使整体不存在了,部分仍然存在;例如,部门撤销了,人员不会消失,他们依然存在;
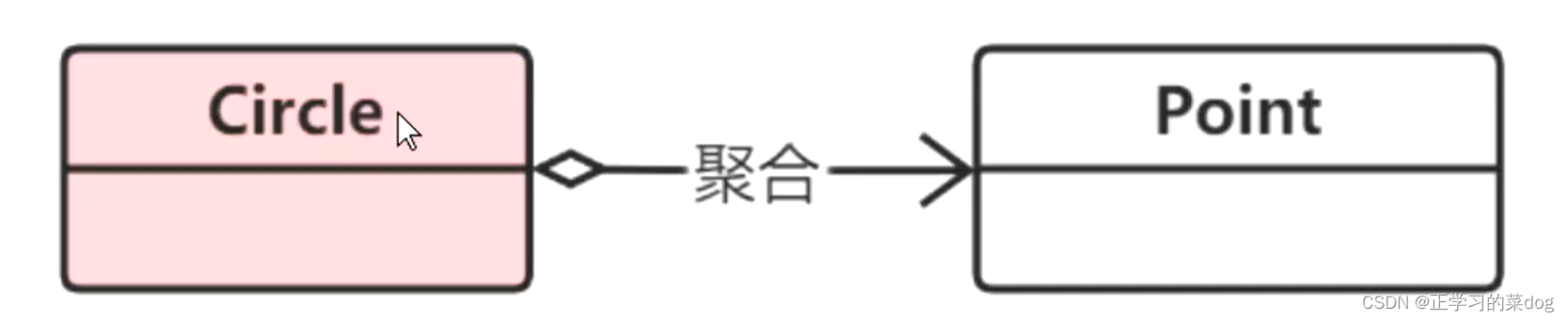
当圆消失的时候,点还存在,这个是聚合关系,用指针方式

点、圆关系:

在聚合关系中,当类的数据成员有“类类型”构成,如果自身有一个构造函数,没有写缺省的构造函数,那系统会调动“类类型数据成员”的缺省构造函数来合成当前的缺省构造函数;如果“类类型数据成员”没有缺省构造函数,那就无法给当前的类型合成缺省构造函数
如果当前的圆类型没有写拷贝构造函数,而类类型成员:点有一个拷贝构造函数,系统就会合成一个圆的缺省的拷贝构造函数
在类类型的包含关系中,圆包含点:如果园没有写构造函数,系统将会产生缺省的构造函数,缺省的构造函数会调动点的缺省构造函数;如果有写了构造函数,那必须在初始化列表处写点的构造函数的调用(好处是会很少去调用点的构造函数,放在{...}内进行初始化需要类型转换),否则就有可能无法创建(具体看点的构造函数怎么写,看是否写了点的缺省构造函数)
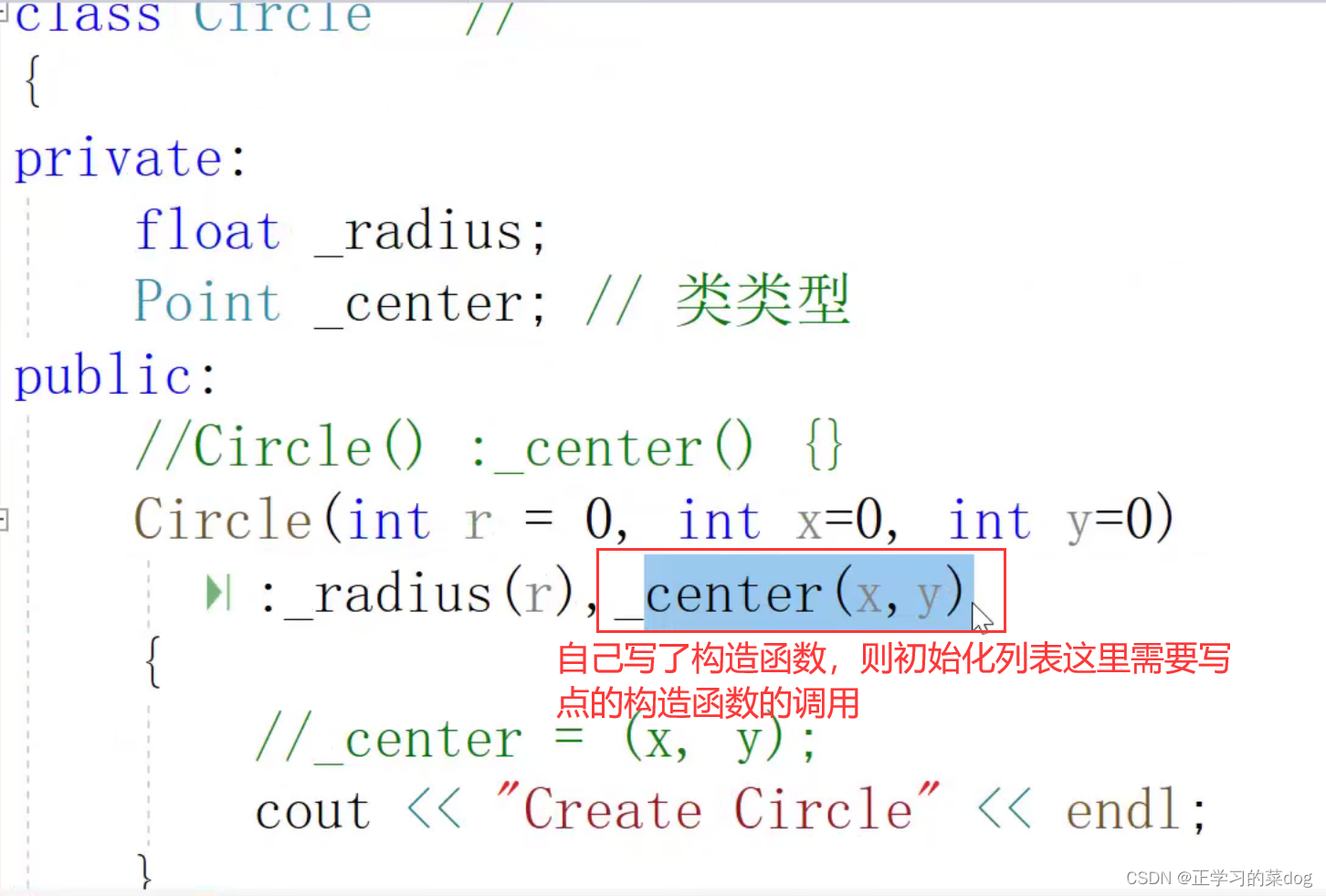
在拷贝构造这里,如果圆没有自己给出拷贝构造函数,则系统会调动点的拷贝构造来合成圆的拷贝构造函数;
如果自己写了圆的拷贝构造,但是在初始化列表处没有说明调用点的拷贝构造,那系统会调动点的构造函数,而不是点的拷贝构造函数
因此:我们要是需要完全拷贝,则使用系统合成的拷贝构造,自己不用写圆的拷贝构造;如果只需要拷贝一部分的内容,则在初始化位置写一部分,可以不写点的拷贝构造,然后让系统去调用构造函数
构造函数的作用之一:
类型转换的时候要注意:形参只能有一个,这个时候才可以进行类型转换

参数较多时候,需要给出默认值,转换成单参,才可以具有类型转换能力

4、组合(值类型):
从语义角度上,组合和聚合最大的区别是:组合关系中,整体的生存期会影响到个体的生存期,也就是整体消失的话,个体也就不存在。
人不存在,身体和意识也会消失;即:整体不存在了,部分也就都会消失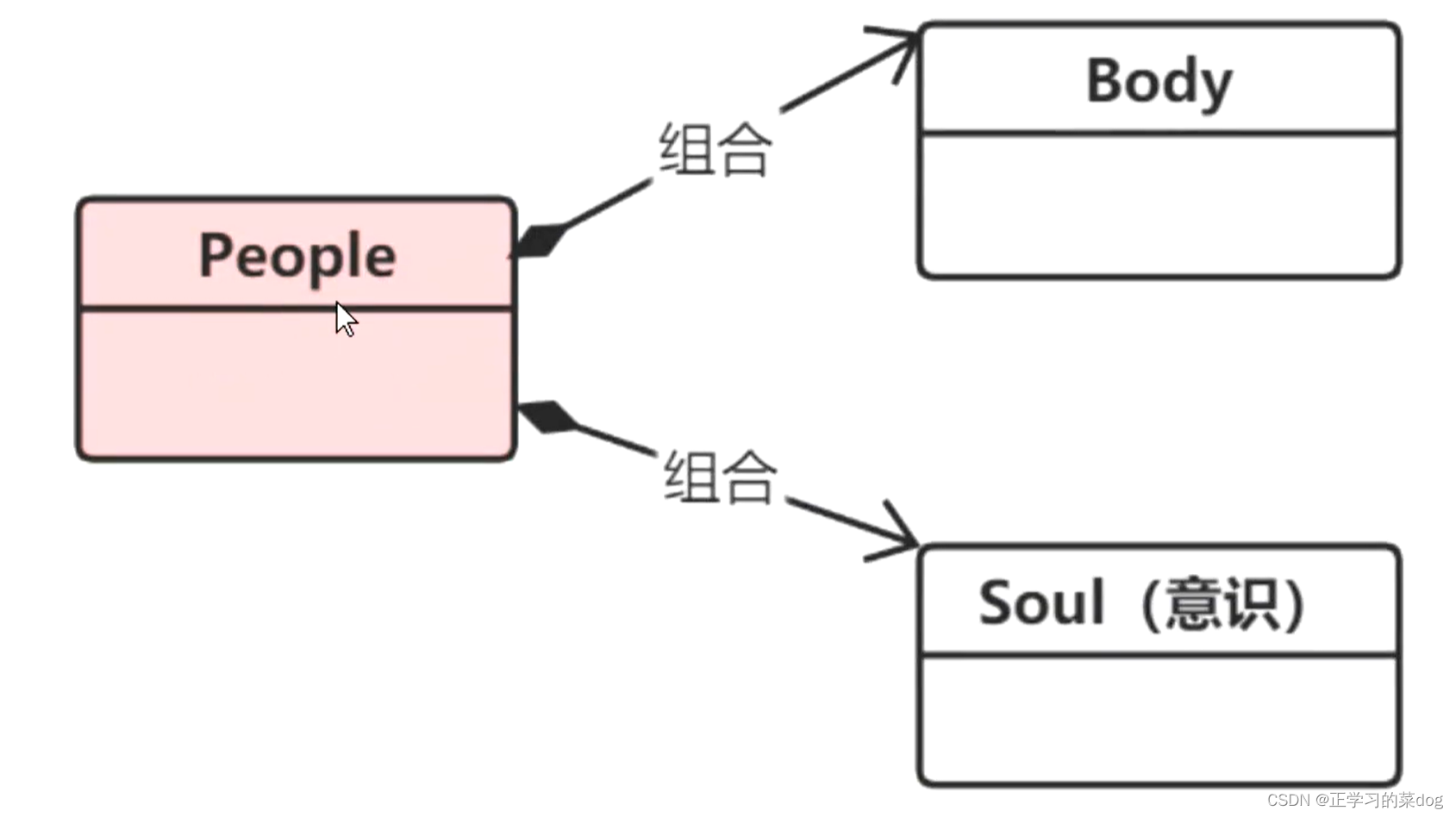

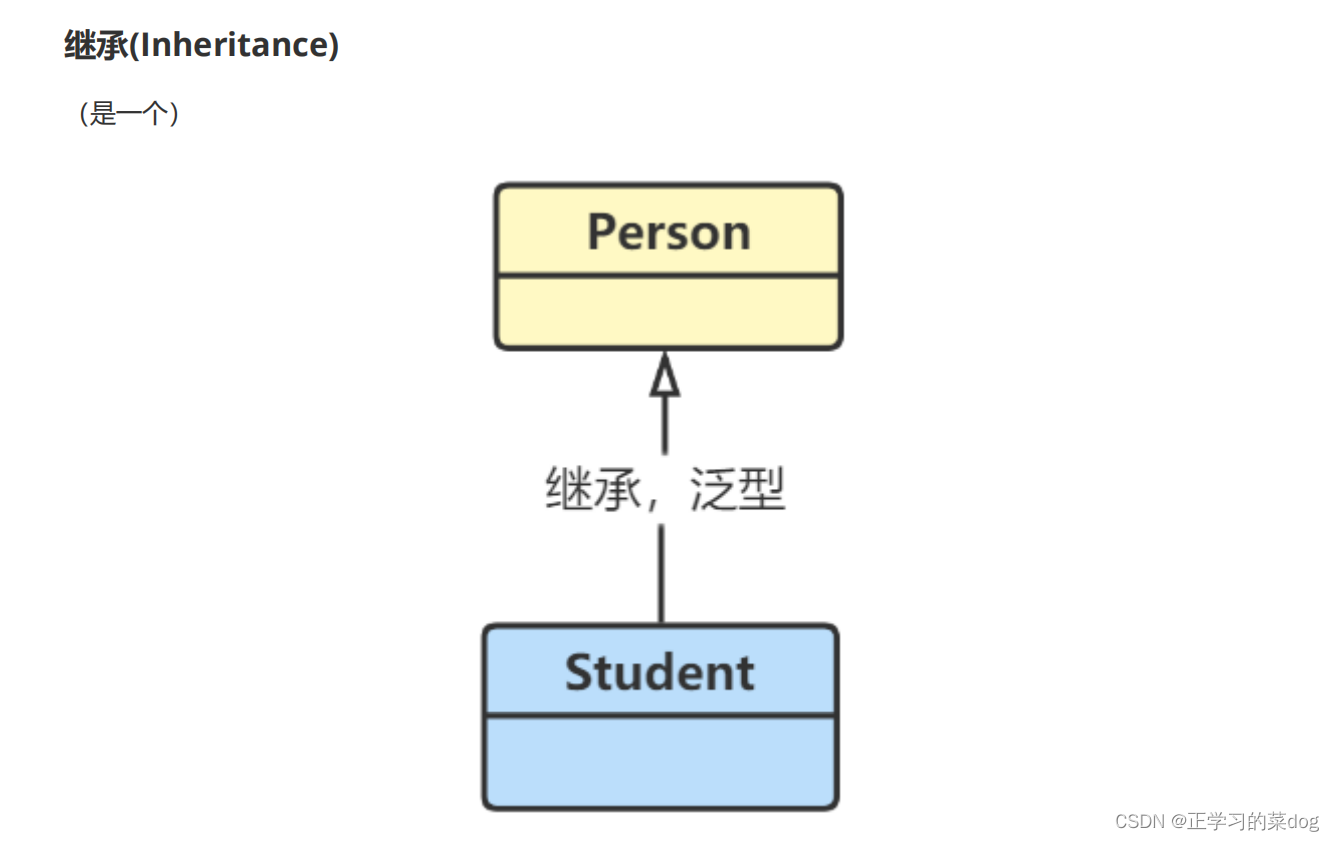
5、泛化关系(继承关系):
泛化关系用一条带空心箭头的直接表示;如下图表示(Student继承自Person ,或 Person
派生Student);
类的继承结构表现在UML中为:泛化(generallize)与实现(realize):
继承关系为 is-a 的关系;两个对象之间如果可以用 is-a 来表示,就是继承关系:(...是一个...);学生是人。
最终代码中,泛化关系表现为公有继承非抽象类
公有继承是 “ 是一个 ” 的关系
第十三部分 实现文件加密项目
代码:
#include<iostream>
#include<string> //FILE* //C
#include<fstream> //C++
//ofstream是从内存到硬盘,ifstream是从硬盘到内存,其实所谓的流缓冲就是内存空间;
#include<stdio.h>
using namespace std;
class ReadFile {
public:
string Read(const string &filename) //读文件,从硬盘读取到buff中
{
cout << "read file" << endl;
//1、C++方式读取txt文件
ifstream ifile; //ifstream是从硬盘读到内存空间
ifile.open(filename); //ifile.open(filename,ios::in) ios打开方式是以in(读)方式打开
if (!ifile.is_open())
{
cout << "open file failed" << endl;
exit(1);
}
string strbuff; //读到的字符给到strbuff中
while (!ifile.eof()) //只要没读到文件末尾,就一直读
{
char ch = ifile.get();
strbuff += ch;
}
ifile.close();
return strbuff;
//2、c语言和C++结合方式
/*
FILE* fp = nullptr;
fp = fopen(filename.c_str(), "r"); //txt //c_str()将文件名对应的地址返回
if (fp == nullptr)
{
cout << "open file failed" << endl;
exit(1);
}
string strbuff;
while (!feof(fp)) //判断是否到达文件末尾
{
char ch = fgetc(fp);
strbuff += ch; //strbuff.push_back(ch);
}
fclose(fp);
return strbuff;
*/
}
};
class Encryptor {
public:
string Encrypt(const string& plaintext) //将明文加密成密文返回
{
cout << "明文:" << plaintext << endl;
cout << "开始加密" << endl;
string es; //es是密文字符串
int key = 1; //设置一下密钥
for (auto& x : plaintext)
{
char ch = x;
if (isalpha(ch))
{
ch = (ch + key - 'a') % 26 + 'a'; //实现加密
}
es += ch;
}
cout << "密文:" << es << endl;
return es;
}
};
class WriteFile {
public:
void Write(const string& filename, const string& encry_str) //将密文写到硬盘的文件中
{
cout << "write file" << endl;
ofstream ofile; //ofstream是从内存写到硬盘
ofile.open(filename);
if (!ofile.is_open())
{
cout << "open file failed" << endl;
exit(1);
}
for (auto& x : encry_str) //范围for迭代密文文件str_txt
{
ofile.put(x); //将字符写入到文件
}
ofile.close();
return;
}
};
//加密工厂
class EncryFac {
private:
ReadFile RF;
Encryptor EF;
WriteFile WF;
public:
void FileEncry(const string &filename, const string &filenew) //将原文件加密后,给到新文件
{
string plainSTR = RF.Read(filename); //先读取原文件,获取明文
string encrySTR = EF.Encrypt(plainSTR); //对明文进行加密,获取密文
WF.Write(filenew, encrySTR); //将密文写入到新文件中
}
};
int main()
{
EncryFac fac;
fac.FileEncry("aaa.txt", "bbb.txt");
return 0;
}
实现效果:

模板:
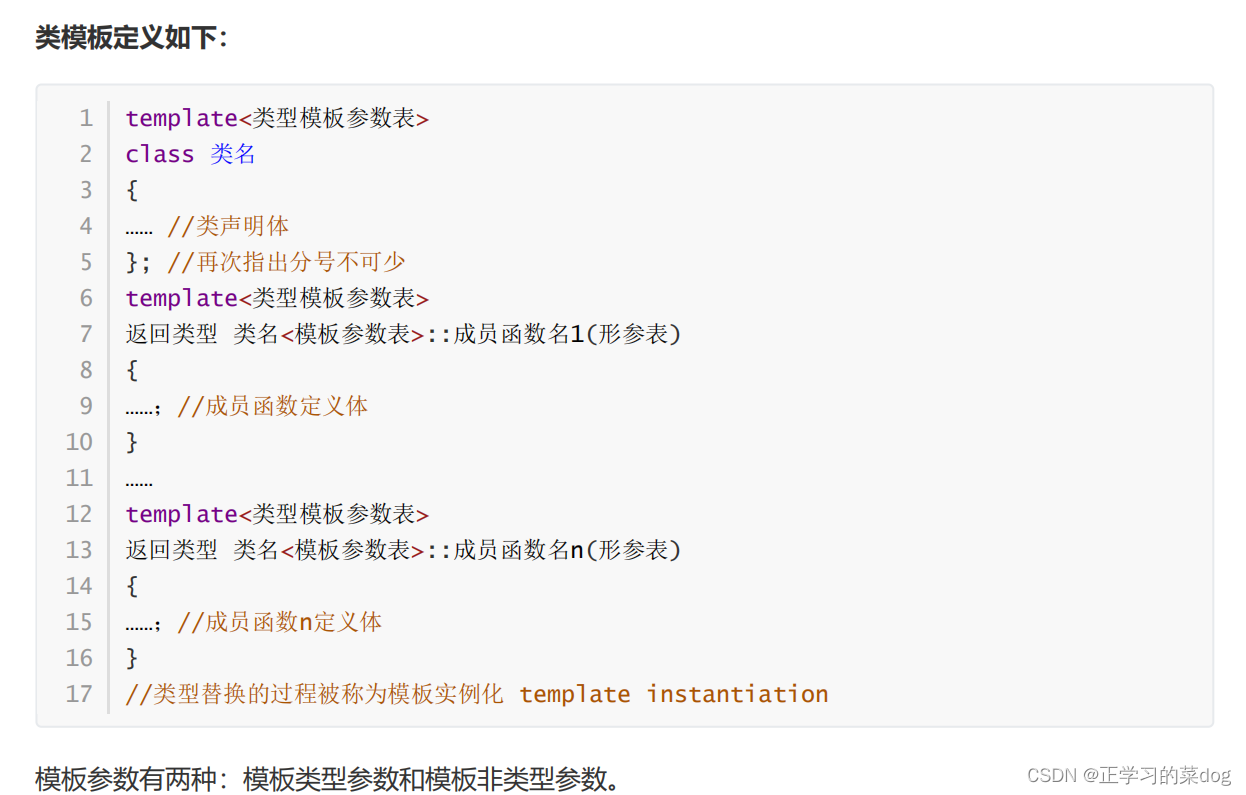
为了代码重用,代码就必须是通用的;通用的代码就必须不受数据类型的限制。那么我们可以把数据类型改为一个设计参数。这种类型的程序设计称为参数化(parameterize)程序设计。软件模板由模板构造
包括函数模板(function template)和类模板(class template)。















 3704
3704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









