






本篇主要是对Neon Intrinsic庞杂的乘法算子(26页啊!!!26页!!!)的归纳总结
虽说数量非常多,但掌握规律后其实信息量并不大,使用时举一反三即可
Neon指令集的算子命名方式为 V + 算子及其各种乱七八糟的前缀后缀 + _数据类型 组成(注意最后这个下划线)
D.4.1~2 VMUL && VUMLQ
平平无奇也是最简单的乘法, Vector1_t * Vector2_t = Result_t,输入与输出位宽一致,Q后缀代表使用Q寄存器,也就是每次可以乘的变量的数量翻倍,Q版本的索引表就不贴了,数量翻倍即可,例:int8x8_t -> int8x16_t
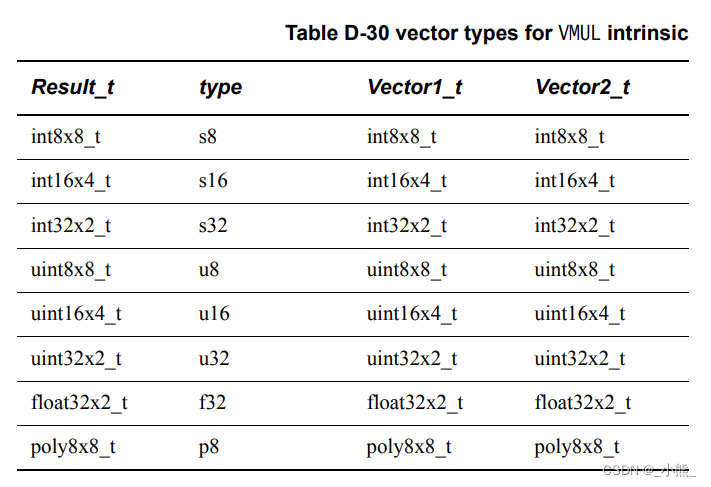
D.4.3~4 VMLA && VMLAQ
乘加组合的一个算子,Vector_1 + Vector_2 * Vector_3
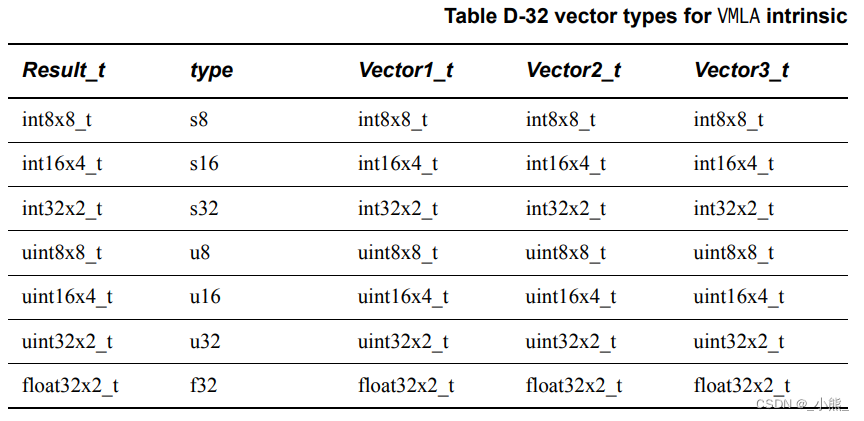
D.4.3 VMLAL
这个跟 VMLA 一样是乘加组合算子,但是输出和加数的位宽是输入乘数的两倍,所以L表示Large,也就是能加的数更大了,此时128位寄存器被占满 因此没有Q版本
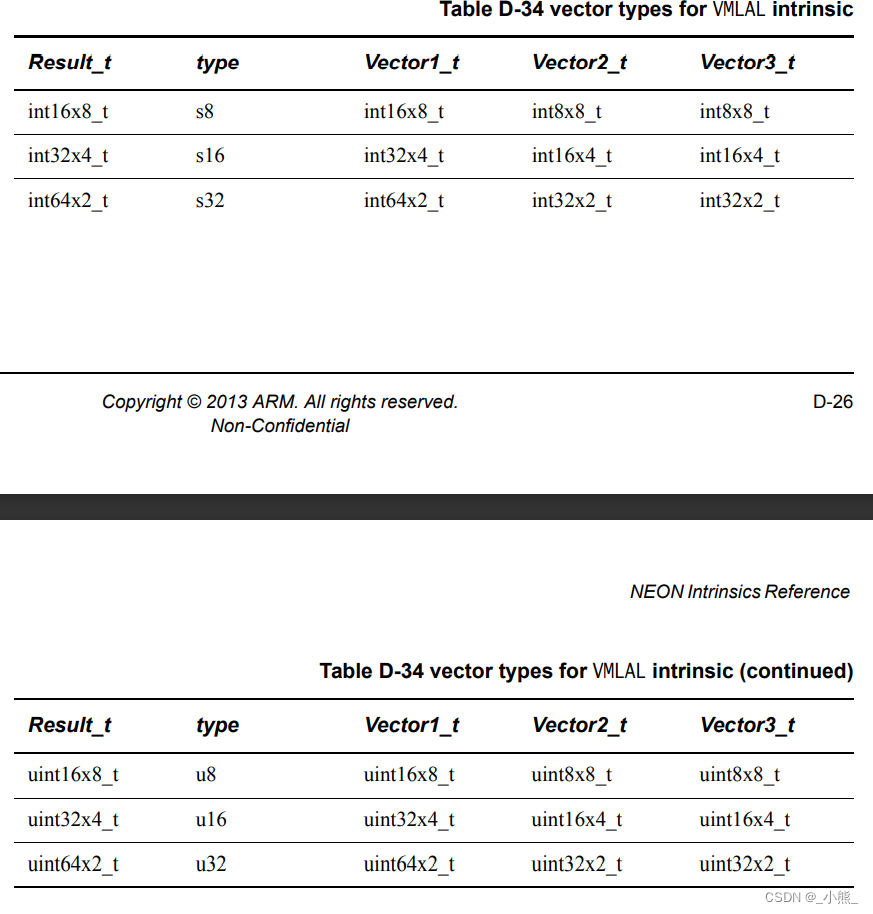
D.4.4~5 VMLS && VMLSL
乘减混合,Vector_1 - Vector_2 * Vector_3 ,数据类型跟 VMLA 系列算子一致,在这就不贴图了
需要注意的是如果结果小于0的话,结果会变成 变量值域上限+结果(负数)
D.4.6~7 VQDMULH && VQRDMULH
这个就厉害了,Vector_1 * Vector_2 >> 变量类型位数,比如选s16的话这个位数就是15(去掉1个符号位)

为什么这个做呢,因为相乘的结果超过变量值域上限是会溢出寄存器的,所以就把溢出的结果进行移位操作
带R版本表示饱和计算
D.4.8 VQDMLAL
从上一个算子开始,算子命名就开始跟简洁易懂一词分道扬镳了:D
乘加,变量长度翻倍,有空再详细测试,老板催着呢
D.4.9 VQDMLSL
乘减,如上
D.4.10~11 VMULL && VQDMULL
输出比输入的值域翻倍,避免了乘积溢出值域
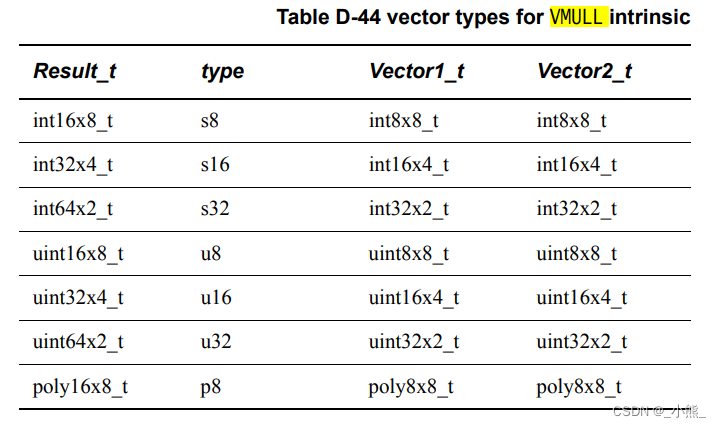

D.4.12~14 VMLA_LANE && VMLAQ_LANE && VMLAL_LANE && VQDMLAL_LANE
支持下标的乘加
即 Vector1 + Vector2 * Vector3[n]
L版本输出比输入乘数变量值域翻倍
QD版本变量长度翻倍
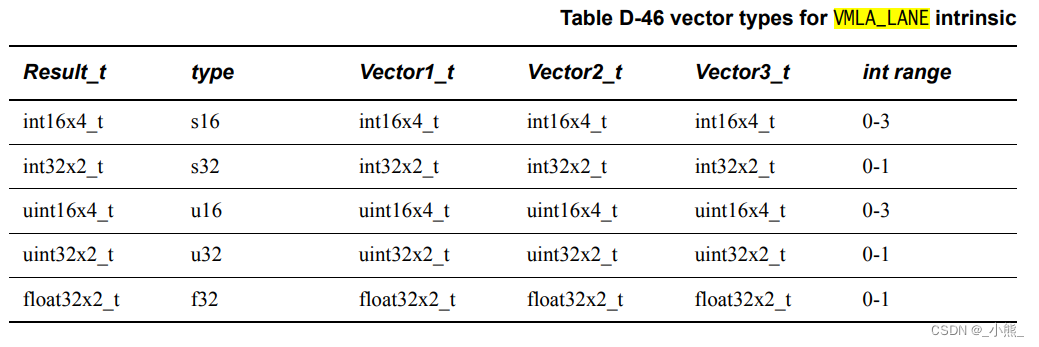
D.4.15~17 VMLS_LANE && VMLSQ_LANE && VMLSL_LANE && VQDMLSL_LANE
支持下标的乘减
即 Vector1 - Vector2 * Vector3[n]
L版本输出比输入乘数变量值域翻倍
QD版本变量长度翻倍
表跟乘加一样,就不贴了
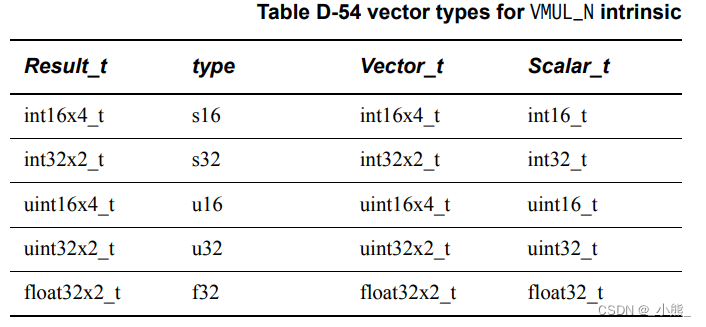
D.4.18~19 VMUL_N && VMULL_N
这回是向量乘标量,L版本输出值域翻倍
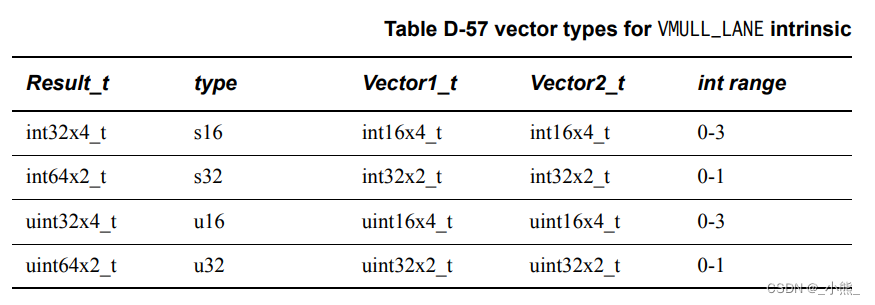
D.4.20~24 VMULL_LANE && VQDMULL_LANE && VQDMULL_N && VQDMULH_LANE
支持下标的乘 Vec1 * Vec2[n]
输出比输入值域翻倍
QD版本变量长度翻倍
H版本结果右移
虽然明白是无奈之举,但作者但凡念过这些算子名字舌头都会打结吧
D.4.29 VQDMLAL_N
这个有点意思,如果结果饱和的话会把FPSCR寄存器置1
中间一些乱七八糟的算子都是那几个前后缀排列组合的结果,就不再赘述了,该用到的时候还是得老老实实查表【Neon Programmer’s Guide】

















 1984
1984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









