







决策树
Cart 分类树
采用 基 尼 系 数 基尼系数 基尼系数 的指标选择最佳划分特征及决策值
基尼系数
对一个数据集 S (X,y),假如有K个类别,任意一个样本
x
i
x_i
xi属于第k类的概率
p
k
p_k
pk,则数据集S的基尼指数表示为
G
i
n
i
(
S
)
=
∑
k
=
1
K
p
k
(
1
−
p
k
)
=
1
−
∑
k
=
1
K
p
k
2
Gini(S) = \sum_{k=1}^K p_k(1-p_k)=1-\sum_{k=1}^Kp_k^2
Gini(S)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
使用
F
F
F特征的
f
f
f决策值,二分数据集S,得到
S
1
S_1
S1,
S
2
S_2
S2,则划分后的基尼指数:
G
i
n
i
(
S
,
F
f
)
=
∣
S
1
∣
∣
S
∣
∗
G
i
n
i
(
S
1
)
+
∣
S
2
∣
∣
S
∣
∗
G
i
n
i
(
S
2
)
Gini(S,F_f) = \frac {|S_1|} {|S|}*Gini(S_1)+\frac {|S_2|} {|S|}*Gini(S_2)
Gini(S,Ff)=∣S∣∣S1∣∗Gini(S1)+∣S∣∣S2∣∗Gini(S2)
其中:
∣
S
1
∣
|S1|
∣S1∣、
∣
S
2
∣
|S2|
∣S2∣为划分的左右子集样本数
Cart分类树的算法过程
传入一个数据集S,指定数据集划分最小样本数min_samples_split,基尼指数缩减阈值min_impurity_decrease
-
若S中样本数小于min_samples_split,则建立叶子节点,类别为最多的那一类,算法结束
-
若S中的样本数大于等于min_samples_split,计算S的基尼指数 G i n i o l d Gini_{old} Giniold,遍历所有的特征(遍历每个特征的决策值)进行二分数据集S,计算划分后的基尼指数 G i n i n e w Gini_{new} Gininew ,选择基尼指数减少最多的划分特征及其决策值。
-
若使用当前最优的特征及决策值划分后, G i n i o l d − G i n i n e w < m i n _ i m p u r i t y _ d e c r e a s e Gini_{old}-Gini_{new}<min\_impurity\_decrease Giniold−Gininew<min_impurity_decrease,则对数据集S建立叶节点,类别为当前最多的那一类,算法结束;
否则,使用当前最优特征及决策值,二分数据集S,得到左右子集 S 1 , S 2 S_1,S_2 S1,S2 -
递归的解决左右子集
sklearn中的API
#决策树分类
from sklearn.tree import DecisionTreeClassifier
#随机森林分类
from sklearn.ensemble import RandomForestClassifier
#正向激励分类
from sklearn.ensemble import AdaBoostClassifier
#梯度提升
from sklearn.ensemble import GradientBoostingClassifier
Cart 回归树
使用 方 差 ( 均 方 误 差 m s e ) 方差(均方误差mse) 方差(均方误差mse) 指标选择最佳划分特征及决策值
方差指标
对于一个数据集
S
(
X
,
y
)
S(X,y)
S(X,y),样本数为m,其标记均值
m
e
a
n
=
∑
i
m
y
i
m
mean =\frac {\sum_i^my_i}{m}
mean=m∑imyi
σ
2
=
∑
i
m
(
y
i
−
m
e
a
n
)
2
m
\sigma^2 = \frac {\sum_i^m(y_i-mean)^2}{m}
σ2=m∑im(yi−mean)2
回归问题中,叶子节点的预测值即为该节点所有样本的标记值的平均值,方差也即均方误差
Cart回归树算法的过程
传入一个数据集S,此时max_depth = 0
-
计算数据集S 的标记 方 差 方差 方差,若 σ 2 = 0 \sigma^2 = 0 σ2=0,则算法结束,建立叶子节点,预测值取所有样本标记的均值
-
若数据集S 标记 σ 2 > 0 \sigma^2 \gt 0 σ2>0,,遍历所有的特征(遍历每个特征的决策值)进行二分数据集S(left ≤ \le ≤ / right > \gt >),计算划分后的子集S1的标记 σ 1 2 \sigma_1^2 σ12、子集S2的标记若 σ 2 2 \sigma_2^2 σ22 ,选择使 σ 1 2 + σ 2 2 最 小 \sigma_1^2+\sigma_2^2 最小 σ12+σ22最小的特征及其决策值,优先划分数据集
-
使用当前最优的特征及决策值划分后max_depth+1,若子集中有 σ 2 = 0 \sigma^2 = 0 σ2=0,则对该子集建立叶节点,预测值为该节点所有样本标记的平均值,当然也可以指定方差阈值, σ 2 \sigma^2 σ2小于这个阈值时,可以认为子集已经纯净,建立叶子节点
-
递归的划分左右子集
算法终止条件
- 特征使用完
- 子集样本数为1,无法继续划分
- 指定max_depth,预剪枝,防止过拟合
- 指定min_samples_split ,预剪枝
sklearn中的回归树
from sklearn.tree import DecisionTreeRegressor
rg = DecisionTreeRegressor(max_depth=3,min_samples_split=2)
rg.fit(X_train,y_train)
y_pred = rg.predict(X_test)
使用回归树预测波士顿房价
from sklearn.datasets import load_boston
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
boston = load_boston()
X,y = boston.data,boston.target
print(X,y)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=3)
"""stratify=y 只用于分类"""
rg = DecisionTreeRegressor(max_depth=3)
rg.fit(X_train,y_train)
y_pred = rg.predict(X_test)
score = r2_score(y_test,y_pred)
print("模型评分:",score)
ID3算法
使用 信 息 增 益 信息增益 信息增益 作为指标,选择最佳的划分特征及决策值
熵
信
息
量
信息量
信息量,单个事件的不确定性
I
(
x
)
=
−
l
o
g
(
p
)
I(x) = -log(p)
I(x)=−log(p)
熵
熵
熵,所有事件的平均不确定性,即期望
H
(
x
)
=
−
∑
i
k
p
i
∗
l
o
g
(
p
i
)
H(x) =-\sum_i^kp_i*log(p_i)
H(x)=−i∑kpi∗log(pi)
有如下数据:计算数据集S的熵
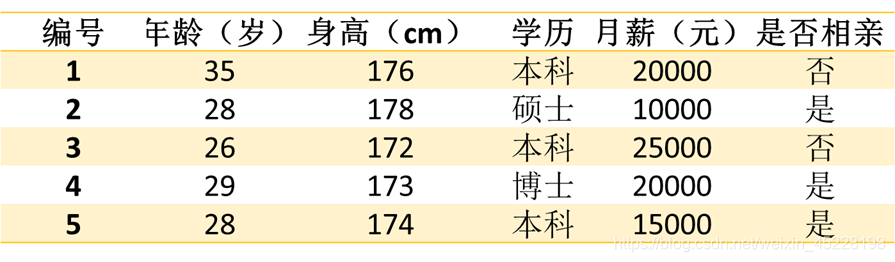
任意取一个样本,‘否’类的概率
p
(
否
)
=
2
5
p(否) = \frac{2}{5}
p(否)=52,‘是’类的概率
p
(
是
)
=
3
5
p(是) = \frac{3}{5}
p(是)=53
则熵 H ( S ) = − [ 2 5 ∗ l o g ( 2 5 ) + 3 5 ∗ l o g ( 3 5 ) ] H(S) = -[\frac{2}{5}*log(\frac{2}{5})+\frac{3}{5}*log(\frac{3}{5})] H(S)=−[52∗log(52)+53∗log(53)]
信息增益
数据集S的熵:
H
(
S
)
=
−
∑
i
k
p
i
∗
l
o
g
(
p
i
)
H(S) =-\sum_i^kp_i*log(p_i)
H(S)=−i∑kpi∗log(pi)
数据集S经过最佳特征F及决策值f,划分后的熵
H
(
S
,
F
f
)
=
∣
S
1
∣
∣
S
∣
∗
H
(
S
1
)
+
∣
S
2
∣
∣
S
∣
∗
H
(
S
2
)
H(S,F_f) = \frac {|S_1|}{|S|} *H(S_1)+\frac {|S_2|}{|S|} *H(S_2)
H(S,Ff)=∣S∣∣S1∣∗H(S1)+∣S∣∣S2∣∗H(S2)
信 息 增 益 G a i n ( S , F f ) = H ( S ) − H ( S , F f ) 信息增益Gain(S,F_f) = H(S) - H(S,F_f) 信息增益Gain(S,Ff)=H(S)−H(S,Ff)
选择信息增益最大的特征及其决策值,优先划分数据集
缺点:偏向于取值多的特征
解决:采用信息增益比
C4.5算法
采用 信 息 增 益 比 信息增益比 信息增益比 作为指标,选择最佳划分特征及决策值
G
a
i
n
r
a
t
i
o
=
G
a
i
n
(
S
,
F
f
)
s
p
l
i
t
I
n
f
o
Gain_{ratio} = \frac{Gain(S,F_f)}{splitInfo}
Gainratio=splitInfoGain(S,Ff)
s
p
l
i
t
I
n
f
o
=
−
∑
i
k
∣
S
i
∣
∣
S
∣
∗
l
o
g
(
∣
S
i
∣
∣
S
∣
)
splitInfo = -\sum_i^k\frac{|S_i|}{|S|}*log(\frac{|S_i|}{|S|})
splitInfo=−i∑k∣S∣∣Si∣∗log(∣S∣∣Si∣)
策略:先选择信息增益高于平均水平的特征,再从中选择信息增益比 最大的特征,优先划分数据集
项目案例
小汽车评级分类
部分数据及特征:
汽车价格,维修费用,车门数,载客数,后备箱大小,安全性,规格
vhigh,vhigh,2,2,small,low,unacc
vhigh,vhigh,2,2,small,med,unacc
vhigh,vhigh,2,2,small,high,unacc
vhigh,vhigh,2,2,med,low,unacc
- 加载数据
import numpy as np
import pandas as pd
df = pd.read_csv("car.txt",header=None,dtype="object")
- 简单数据分析
df.head()
df[0].value_counts()
df[1].value_counts()
...
df[6].value_counts()
#是否有缺失值
df.info()
df.isnull().sum()
- 对字符串的数据编码
from sklearn.preprocessing import LabelEncoder
temp_df = pd.DataFrame()
encoders = {}
for k,v in df.items():
encoder = LabelEncoder()
temp_df[k] = encoder.fit_transform(v)
encoders[k] = encoder
#获取数据集
X,y = temp_df.iloc[:,:-1],temp_df[6]
- 交叉验证模型
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=200,max_depth=7,random_state=7)
cv_scores = cross_val_score(rf,X,y,cv=5,scoring="f1_weighted")
print("平均准确率:",cv_scores.mean())
- 实际的训练
rf.fit(X,y)
#加载测试数据
rf.fit(X,y)
test_df = pd.read_csv("test_car.txt",header=None,dtype="object")
temp_df = pd.DataFrame()
print("测试数据:\n",test_df)
#对测试数据编码
for k,v in test_df.items():
#使用存储的编码器
try:
temp_df[k] = encoders[k].transform(v)
except ValueError:
print("\n")
print(k,"\n",v)
print("编码后的测试数据:\n",temp_df)
#预测类别
X = temp_df.iloc[:,:-1]
y_pred = rf.predict(X)
print("预测标签:\n",y_pred)
print("等级:\n",encoders[6].inverse_transform(y_pred))
print("不正确就调参")
预测结果:
[‘unacc’ ‘acc’ ‘good’ ‘vgood’]
全部正确
链接:项目整体代码
提取码:jqwu















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











