







HBase数模型
逻辑组织方式:表,大表存储
表,
列族
列标识
单元格
版本
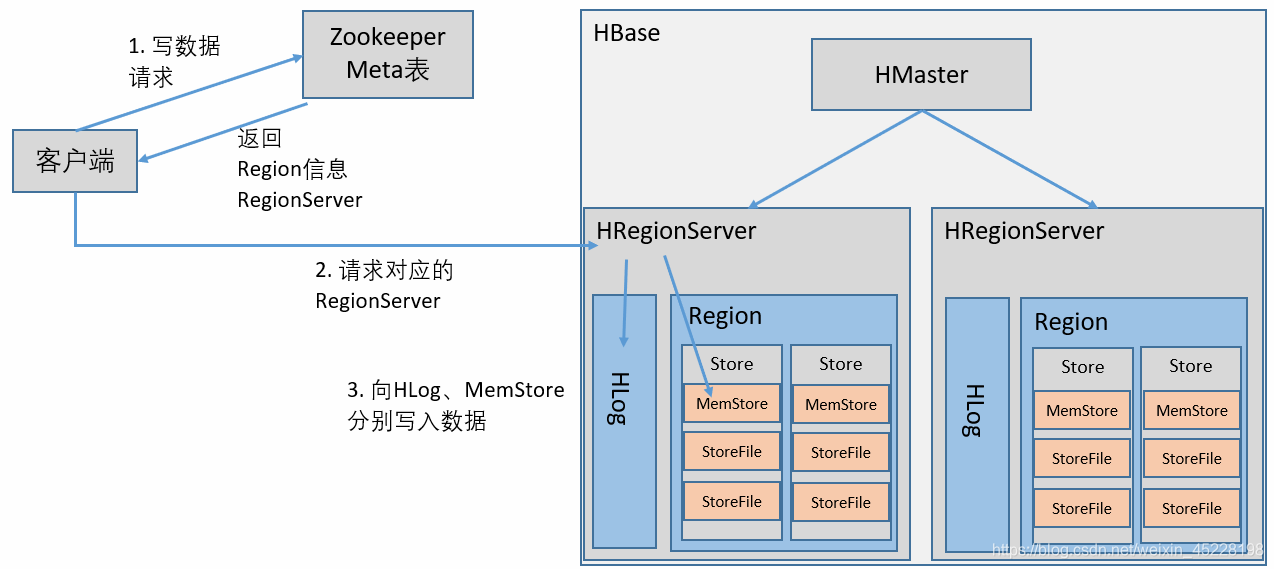
写入数据
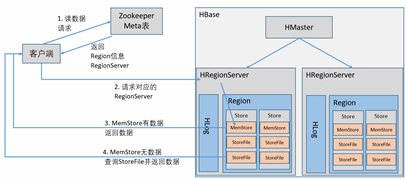
读取数据
Region合并

Region的管理
所有Region与RegionServer形成一张映射表,即Meta表,由ZooKeeper管理。
每个RegionServer又管理分配给自己的Region数据块
Region的拆分
Region下数据存储的核心:Store
当Region的最大Store下的StoreFile(最大)大于设定的阈值,即开始Region的拆分。
在拆分时,不同的策略,只是设定阈值的方式不同。
策略参数如下:
ConstantSizeRegionSplitPolicy;
Region中最大Store下的StoreFile大于配置项(hbase.hregion.max.filesize)时,触发拆分
IncreasingToUpperBoundRegionSplitPolicy;
阈值不断调整,与Region所属的表分布在该RegionServer上的Region的个数有关
SteppingSplitPolicy;
若只有一个Region,则阈值为flushsize*2;
否则,阈值为MaxRegionFileSize
DisabledRegionSplitPolicy;
关闭拆分策略,进行手动拆分
如下,创建表时指定拆分策略:
hbase(main):039:0> create 'day03',{NAME=>'StuInfo',VERSIONS=>'3'},{NAME=>'GRADES',VERSIONS=>'5',blockcache=>'true'},{SPLIT_POLICY=>'org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy'}
hbase(main):038:0> desc 'day03'
Table day03 is ENABLED
day03, {TABLE_ATTRIBUTES => {METADATA => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase
.regionserver.ConstantSizeRegionSplitPolicy'}}
COLUMN FAMILIES DESCRIPTION
{NAME => 'GRADES', BLOOMFILTER => 'ROW', VERSIONS => '5', IN_MEMORY => 'false', KEEP
_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESS
ION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPL
ICATION_SCOPE => '0'}
{NAME => 'StuInfo', BLOOMFILTER => 'ROW', VERSIONS => '3', IN_MEMORY => 'false', KEE
P_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRES
SION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REP
LICATION_SCOPE => '0'}
2 row(s) in 0.0110 seconds
拆分步骤:
RegionServer负责拆分;
- 待拆分的Region下线,并阻止其接收客户端请求;同时HMaster检测到该Region为splitting状态。
- 在该父Region目录下,创建两个引用文件,分别指向父Region的起始行、结束行;但此时并不拷贝父Region的数据。
- 在HDFS上建立两个子Region目录,并分别拷贝上一步的两个引用文件,然后各自拷贝父Region一半的数据,拷贝完成,则删除两个引用文件。
- 子Region创建完成,将其元数据更新到Meta表中,并删除父Region的元数据。
- 父Region的拆分信息更新到HMaster中,子Region开始提供服务。
Region的合并
-
为什么要合并?
随着表的增大、Region的不断拆分,Region的数量不断增多,过多的Region会导致如下问题:
1.1 memstore数量增多,在RegionServer的内存一定的情况下,每个memstore的大小会缩小,就会出现数据频繁地memstore刷新到storefile中,从而影响客户端的请求。
1.2 Region元数据增多,Meta表增大,增加zookeeper的负担。
所以RegionServer中的Region达到一定的阈值,就会进行Region的合并。 -
合并的步骤:
2.1 客户端发送Region合并的请求,给HMaster.
2.2 HMaster将需要合并的Region移到一起,然后发送Region合并请求给RegionServer。
2.3 RegionServer将需要合并的Region下线,然后进行合并。
2.4 更新Meta表,删除旧的Region元数据,更新新合并的Region的元数据。
2.5 Region合并的信息更新给HMaster,同时新Region上线提供服务。
负载均衡
分布式系统中,负载均衡是一个重要的功能。
HBase通过Region的分配,实现负载均衡。
负载均衡分为两步:
- 生成负载均衡计划表
- 按照计划表,分配Region
在HMaster内部有一套负载均衡评分算法,结合RegionServer上Region的数量、memstore的大小、storefile的大小、数据本地性等几个维度对集群进行评分,评分越低,集群负载越合理。
当确定需要负载均衡时,根据不同的均衡策略,选择Region,重新分配,然后再对整个表评分,若还没有达到标准,则继续循环进行负载均衡。
负载均衡策略:
RandomRegionPicker:
随机选择两个RegionServer上的Region进行交换
LoadPicker:
选择Region数量最多、最少的两个RegionServer,使他们更加的平均
LocalityBasedPicker:
选择本地行最强的Region
配置负载均衡:
hbase-site.xml>
hbase.balancer.period
300000
hbase(main):043:1>balance_switch true //开启
hbase(main):043:1> balancer //负载均衡
hbase(main):044:1> balance_switch false //关闭
















 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











