






一、Hadoop概念
hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。hadoop充分利用了集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System),HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;HDFS提供了高吞吐量来访问应用程序的数据,适用于那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,可以以流的形式访问文件系统中的数据。Hadoop最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
二、Hadoop发展起源
Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一。2004年,Google在“操作系统设计与实现”(Operating System Design and Implementation,OSDI)会议上公开发表了题为MapReduce:Simplfifed Data Processing on Large Clusters (Mapreduce:简化大规模集群上的数据处理)的论文之后,收到启发的Doug cutting(Hadoop创始人)等人开始尝试实现MapReduce计算框架,并将它与NDFS(Nutch Distributed File System)结合,用以支持Nutch引擎的主要算法。由于NDFS和MapReduce在Nutch引擎中有着良好的应用,所有在2006年2月份被分离出来,成为一套完整而独立的软件,并被命名为Hadoop。到了2008年年初,hadoop已经成为Apache的顶级项目,包含众多子项目,被应用到包括Yahoo在内的很多互联网公司。
三、Hadoop的优势及组成
1、Hadoop的优势:
(1)高可靠行:Hadoop底层维护了多个数据副本,所以即使Hadoop集群中的某个节点当计算元素或者存储出现了故障时也不会导致数据的丢失。
(2)高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇3可以方便的扩展到数以千计的节点中。
(3)高效性:Hadoop能够在节点之间动态的移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
(4)高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
(5)低成本:与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低
2、Hadoop组成:
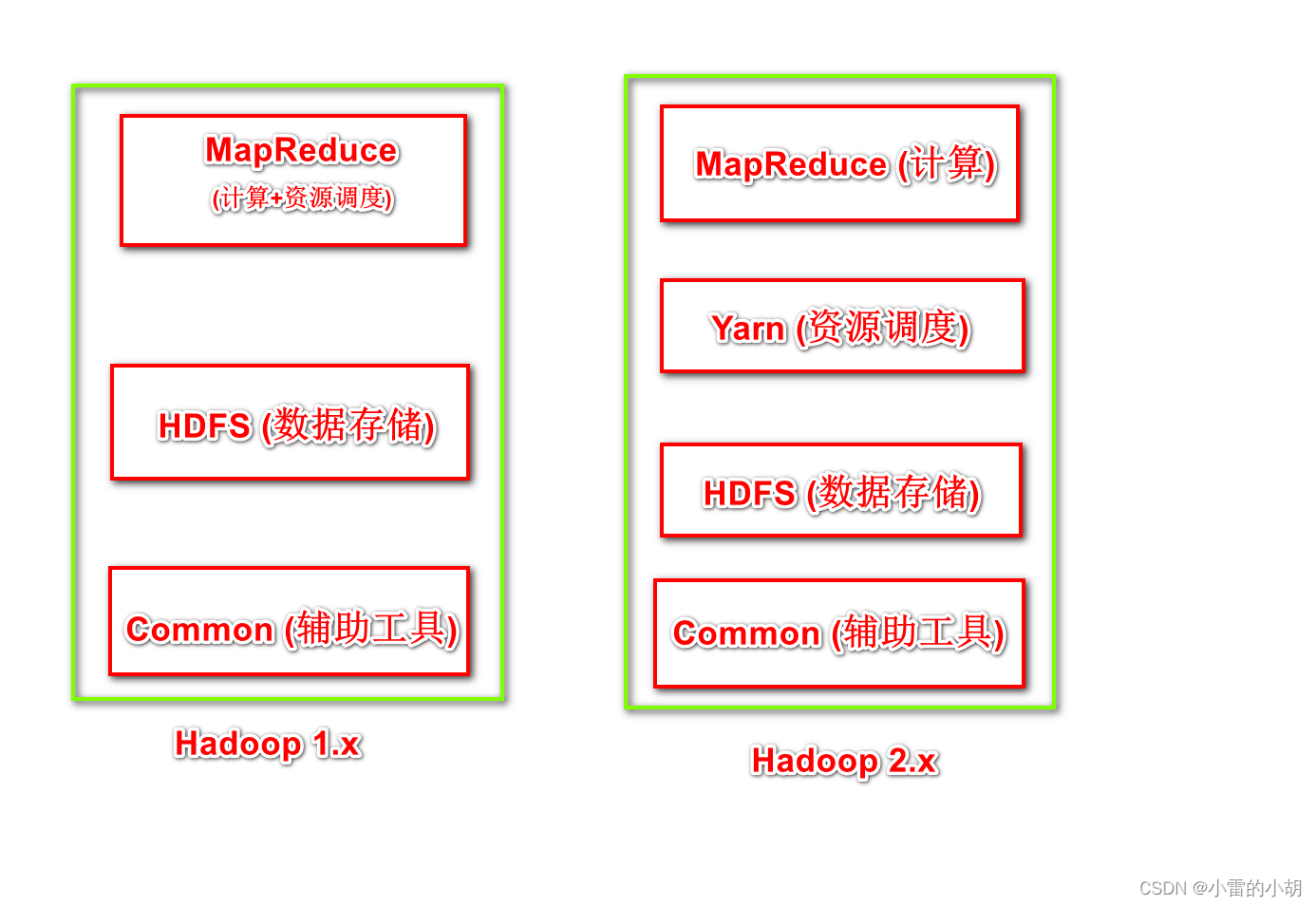
在Hadoop 1.x 时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性比较大。在Hadoop 2.x时代,新增Yarn。至此,MapReduce只负责计算,Yarn只负责资源调度。Hadoop 3.x时代在组成上没有变化,继续沿用Hadoop 2.x时代的组成。
3、HDFS详解
HDFS是Hadoop分布式文件系统,GFS的java开源实现,运行于大型商用机器集群,可实现分布式存储。
HDFS拥有超大型的数据量,为了存储这些庞大的数据,这些文件都存储在多台机器。这些文件的存储以冗余的方式来拯救系统免受可能的数据丢失,在发生故障时,HDFS也使得可用于并行处理的应用程序。
3.1、HDFS的特点:

HDFS适用于分布式存储和处理
hadoop提供的命令接口与HDFS进行交互
名称节点和数据节点使得用户内置的服务器能够比较轻松的检查集群的状态
流式访问文件系统数据
HDFS提供了文件的权限和验证
3.2、HDFS架构:
HDFS遵循主从架构,它具有一下元素:
(1)namenode - 名称节点:
名称节点是包含GNU/Linux操作系统和软件名称节点的普通硬件。它是一个可以在商品硬件上运行的软件。具有名称节点的系统作为主服务器,执行以下任务:
- 管理文件系统命名空间,规范客户端对文件的访问。
- 它也执行文件系统操作,如重命名、关闭和打开文件和目录等
(2)datanode - 数据节点
datanode具有GNU/Linux操作系统和软件Datanode的普通软件,对于集群中的每个节点(普通硬件/系统),有一个数据节点,这些节点管理数据存储在他们的系统。
数据节点上的文件系统执行的读写操作,根据客户的请求。
还根据名称节点的指令执行操作,如块的创建、删除和复制。
(3)块 - block
一般用户数据存储在HDFS文件。在一个文件系统中的文件将被划分为一个或多个段、或存储在个人数据的节点。这些文件段被称为块。简单来说,数据的HDFS可以读取或写入的最小量被称为一个块。缺省的块大小为64MB,但它可以增加,按需要在HDFS配置来改变。
3.3、HDFS的目标
故障检测和恢复:由于HDFS包括大量的普通硬件,部件故障频繁,因此HDFS具有快速自动故障检测和恢复机制。
巨大的数据集:HDFS有数百个集群节点来管理其庞大的数据集的应用程序。
数据硬件:请求的任务,当计算发生不久的数据可以高效的完成。涉及巨大的数据集,特别是它减少了网络通信量,并增加了吞吐量。
DataNode (DN):在本地文件系统存储文件块数据以及块数据的校验和
Secondary NameNode (2NN):每隔一段时间对NameNode元数据备份。
4、MapReduce
MapReduce是一种处理技术和程序模型基于java 的分布式计算。MapReduce算法包含了两项重要的任务,即Map 和 Reduce 。Map采用了一组数据,并将其转换为另一组数据,其中,各个元件被分解成元组(键/值对)。其次,减少任务,这需要从Map作为输入并组合那些数据元组成的一组小的元组输出。作为MapReduce暗示的名称的序列在Map作业之后执行reduce任务。
MapReduce主要优点是:它很容易大规模数据处理在多个计算节点。这个附上一张图:

在上面的MapReduce模型中,数据处理的原语称为 映射器 和 减速器。分解数据处理应用到映射器 和减速器有时是普通的,但是编写MapReduce形式的应用,扩展应用程序运行在几百,几千,甚至上万的集群中仅仅只需要一个配置的更改。
MapReduce将计算过程分为连个阶段:Map 和 Reduce
Map阶段并行处理输入数据
Reduce阶段对Map结果进行汇总
5、Yarn
Yarn是Yet Another Resource Negotiator 的简称,是一种资源协调者,是Hadoop的资源管理器。
(1)ResourceManager (RM):整个集群资源(内存、cpu等)的老大
(2)NodeManager (NM):单个节点服务器资源老大
(3)ApplicationMaster (AM):单个任务运行的老大
(4)Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、cpu、磁盘、网络等。
四、Hadoop集群搭建
在搭建集群之前,需要安装好vmware环境,我这里使用的是Vmware Workstation 16 和 CentOS8,同时再后续中还会使用jdk,hadoop,安装包如下:
百度网盘链接:https://pan.baidu.com/s/1FxIThCPQ-zsirXyn4IipTA
提取码:uu3y
vm环境和centos8环境安装好之后,接下来进入正题
1、修改VMnet 的IP配置
找到自己电脑的VMnet8,手动配置IPv4的ip:192.168.63.1,IP可根据自己的情况去设置

打开,VM虚拟机,编辑->虚拟网络编辑器进行如下设置:

2、克隆虚拟机,在搭建hadoop集群时,我们用到了三台虚拟机,所以要克隆三台虚拟机出来。
选中已经安装好的centos8虚拟环境,【右键】->【管理】->【克隆】
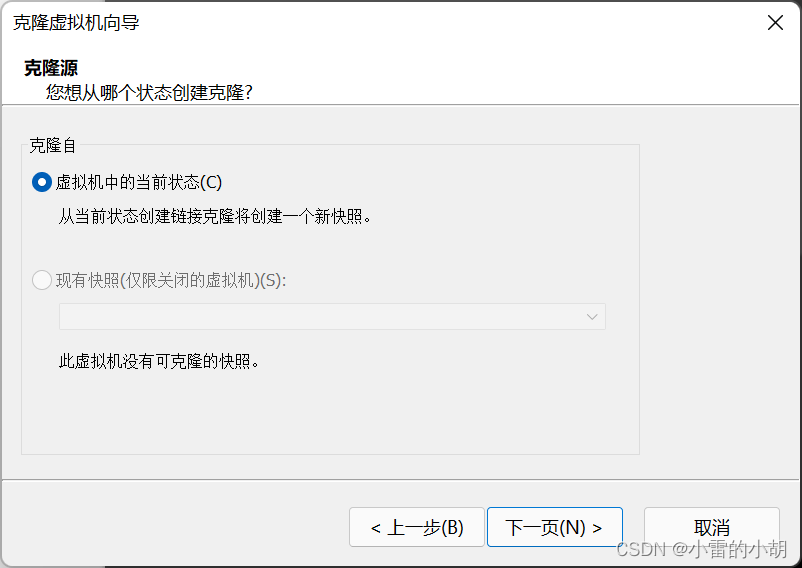
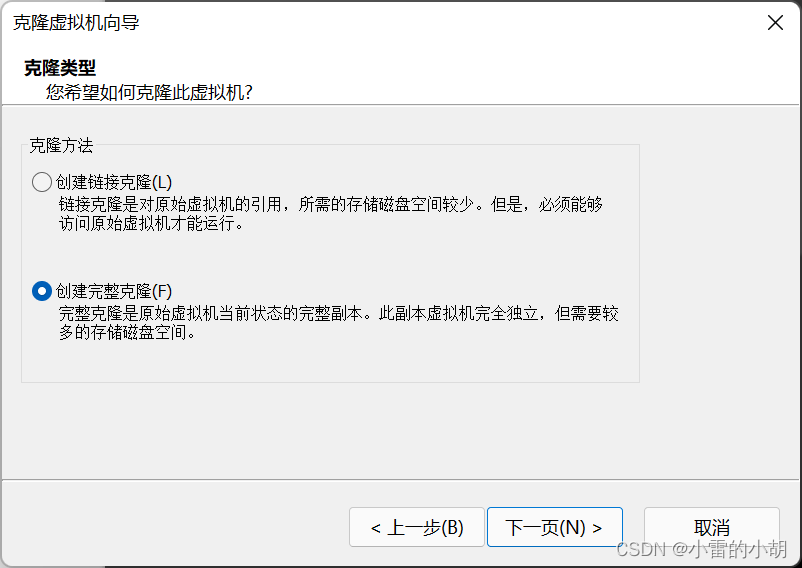
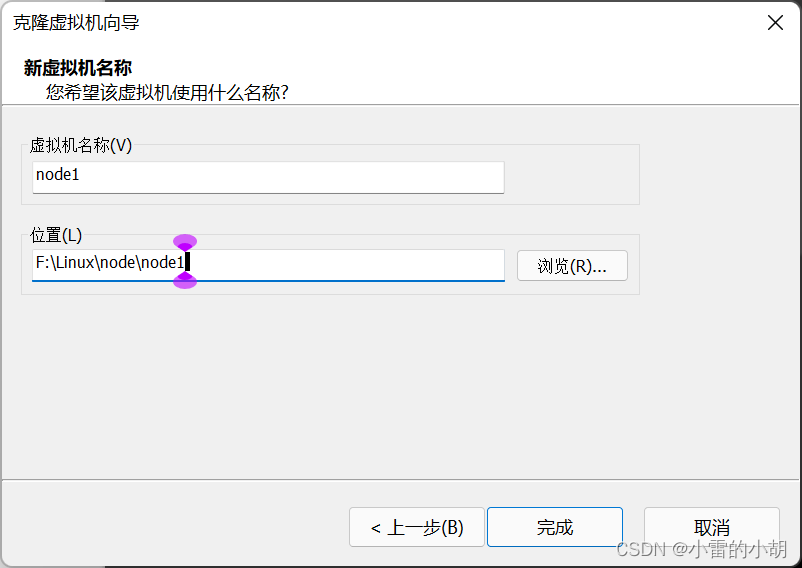
点击【完成】等待克隆完成,然后按照同样的步骤克隆另外两台虚拟机
3、修改虚拟机IP
三台虚拟机克隆完成后,进行IP修改,可根据自己情况自由选择
| 主机名 | IP |
| node1 | 192.168.63.11 |
| node2 | 192.168.63.22 |
| node3 | 192.168.63.33 |
方式一:使用命令进行IP修改
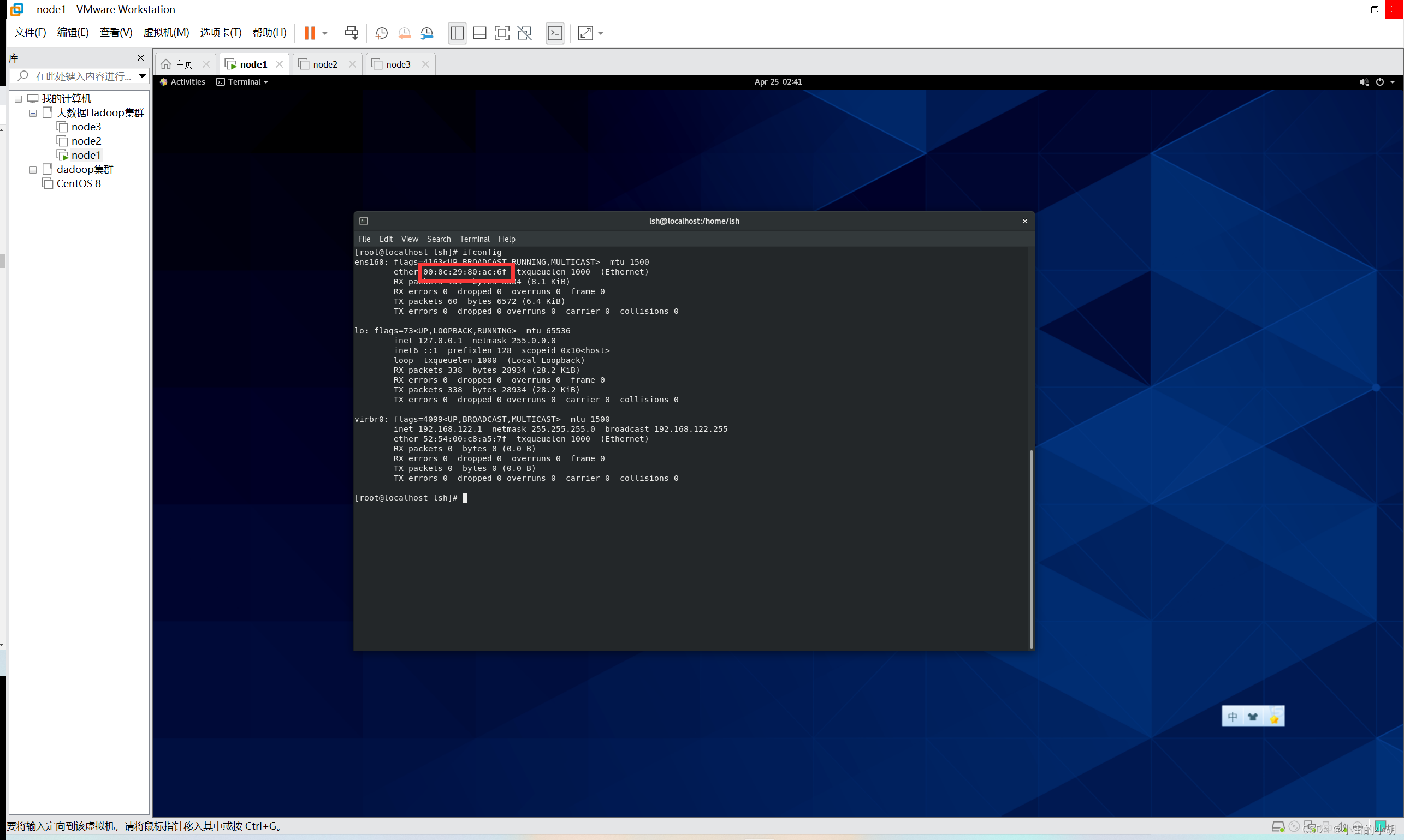
下面以node1为例,打开虚拟机,进入终端,
使用命令:
ifconfig
查看IP详情,然后复制mac地址,mac地址在修改ip时需要用到。
如果不是root账号,使用
su root命令,输入密码切换到root用户
然后输入以下命令修改IP设置
vim /etc/sysconfig/network-scripts/ifcfg-ens160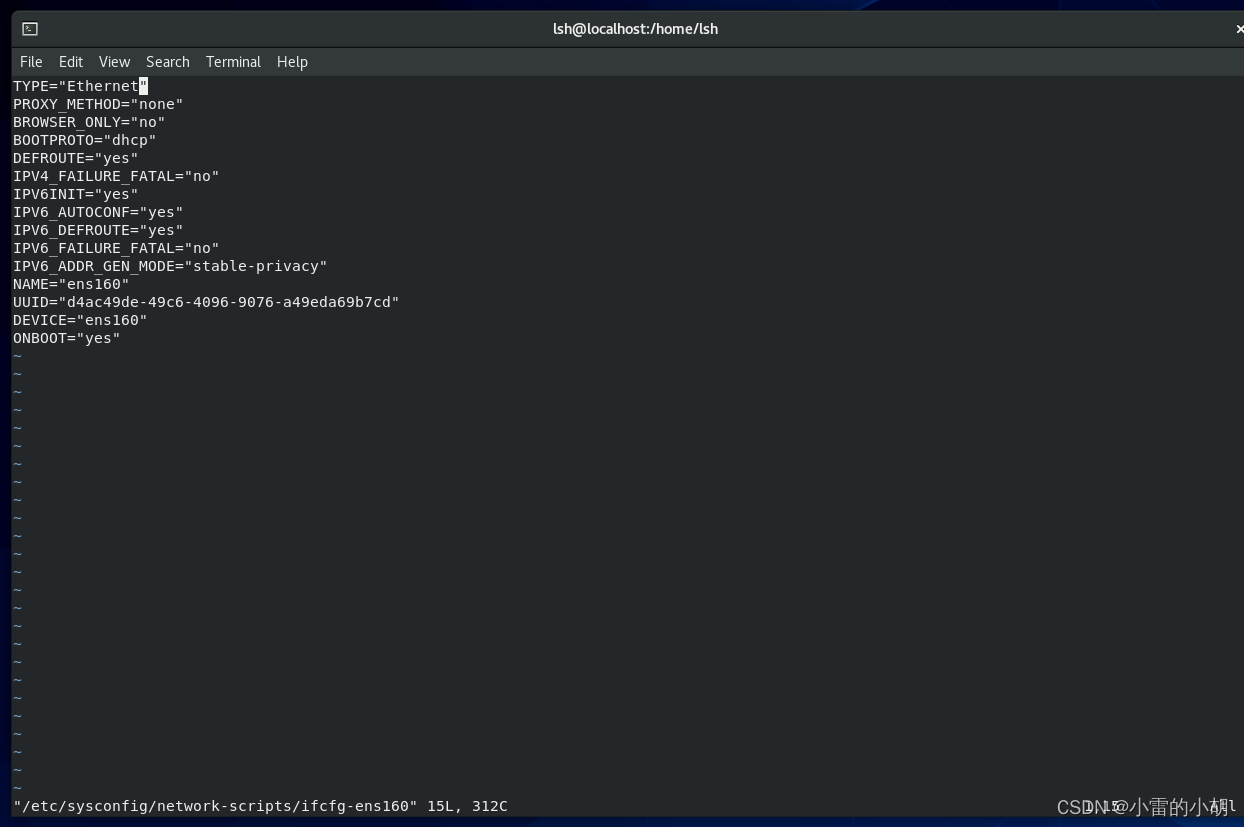
按 i 进入编辑模式,然后修改或增加以下内容
#修改
BOOTPROTO="none"
ONBOOT="yes"
#新增
HWADDR=00:0c:29:80:ac:6f #mac地址
IPADDR=192.168.63.11 #IP地址
PREFIX=24
GATEWAY=192.168.63.2 #网关
DNS1=114.114.114.114
DNS2=8.8.8.8内容修改完毕后,先按ESC键,再按英文冒号,输入 wq!(英文叹号),强制写入并保存,然后再终端输入 reboot 重启
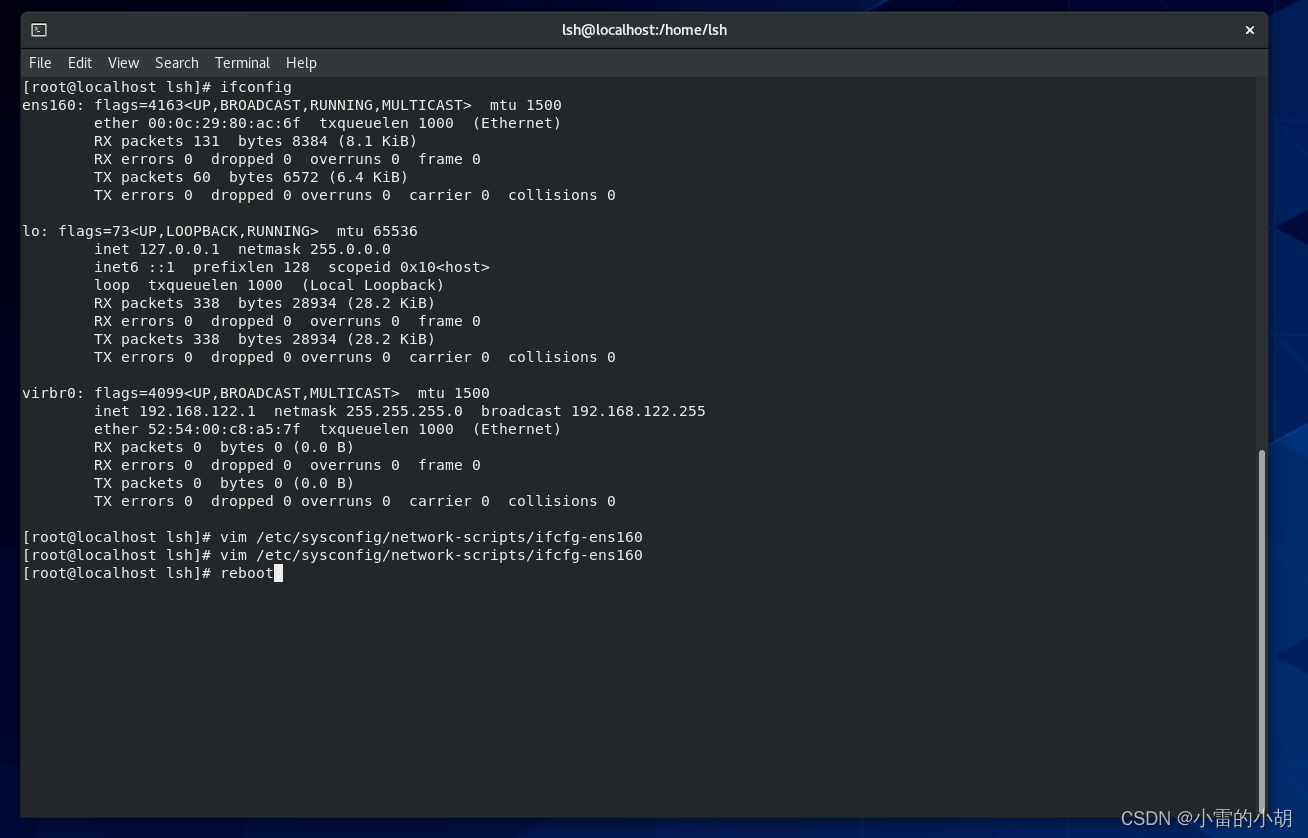
测试IP是否修改成功,重启后,打开终端,输入命令:ifconfig进行查看是否和我们配置的一样
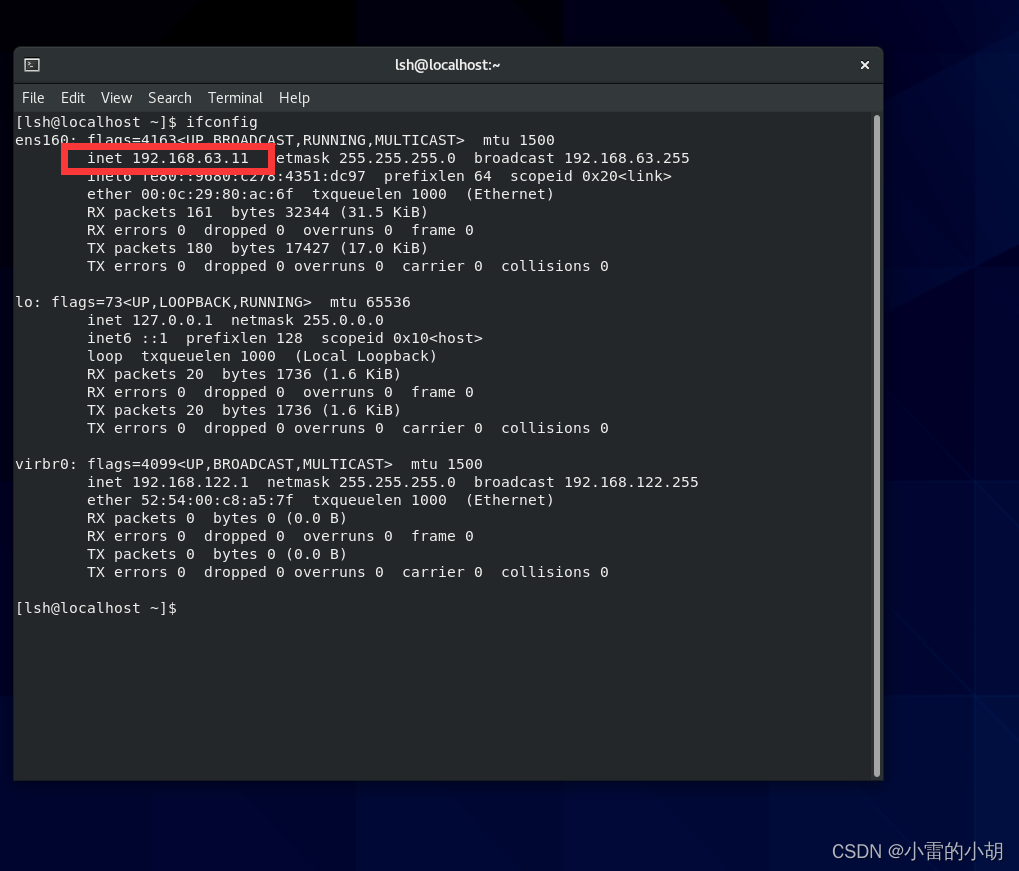
对 另外两台虚拟机进行相同的操作
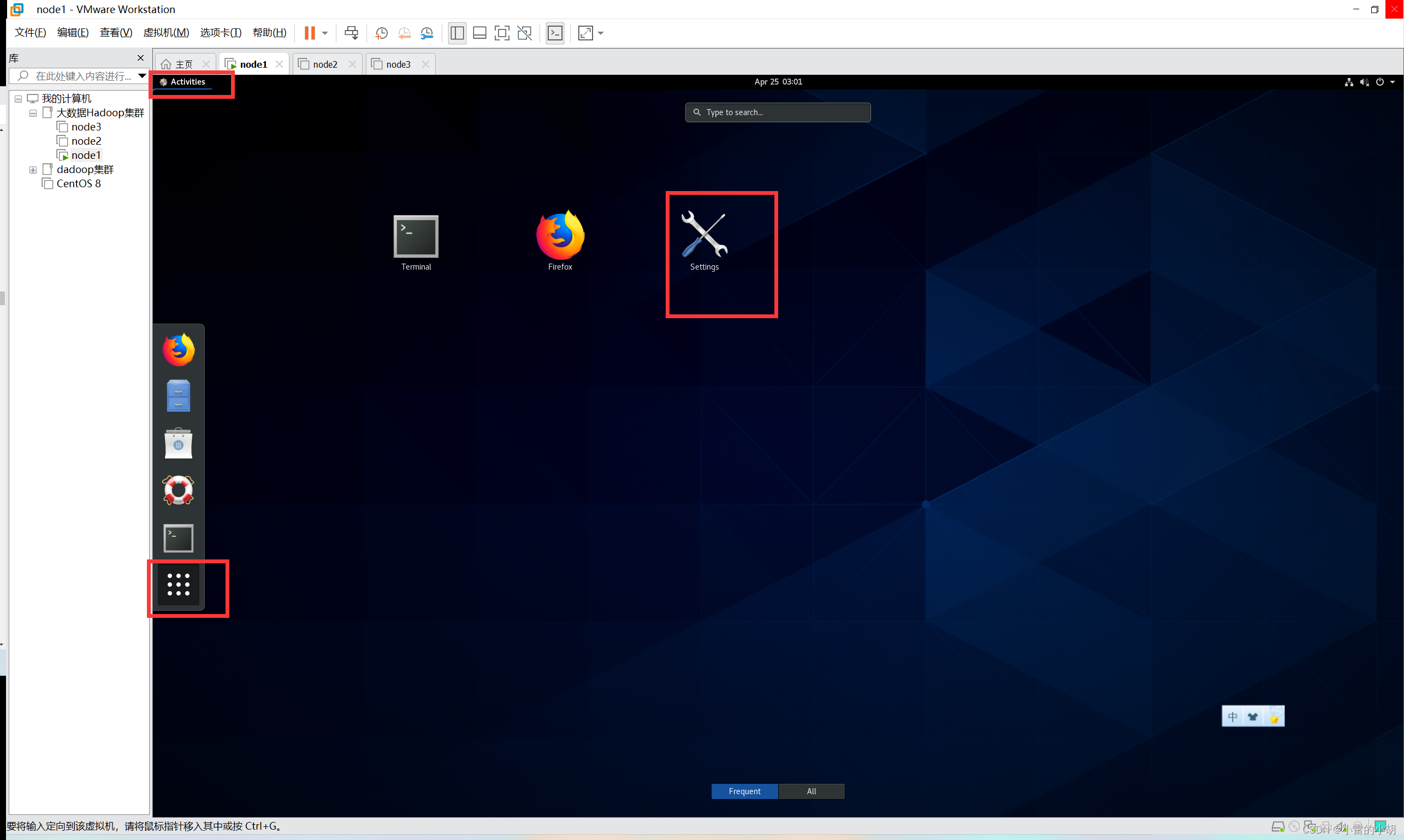
方式二:使用图形化界面进行IP修改
打开虚拟机,进入设置
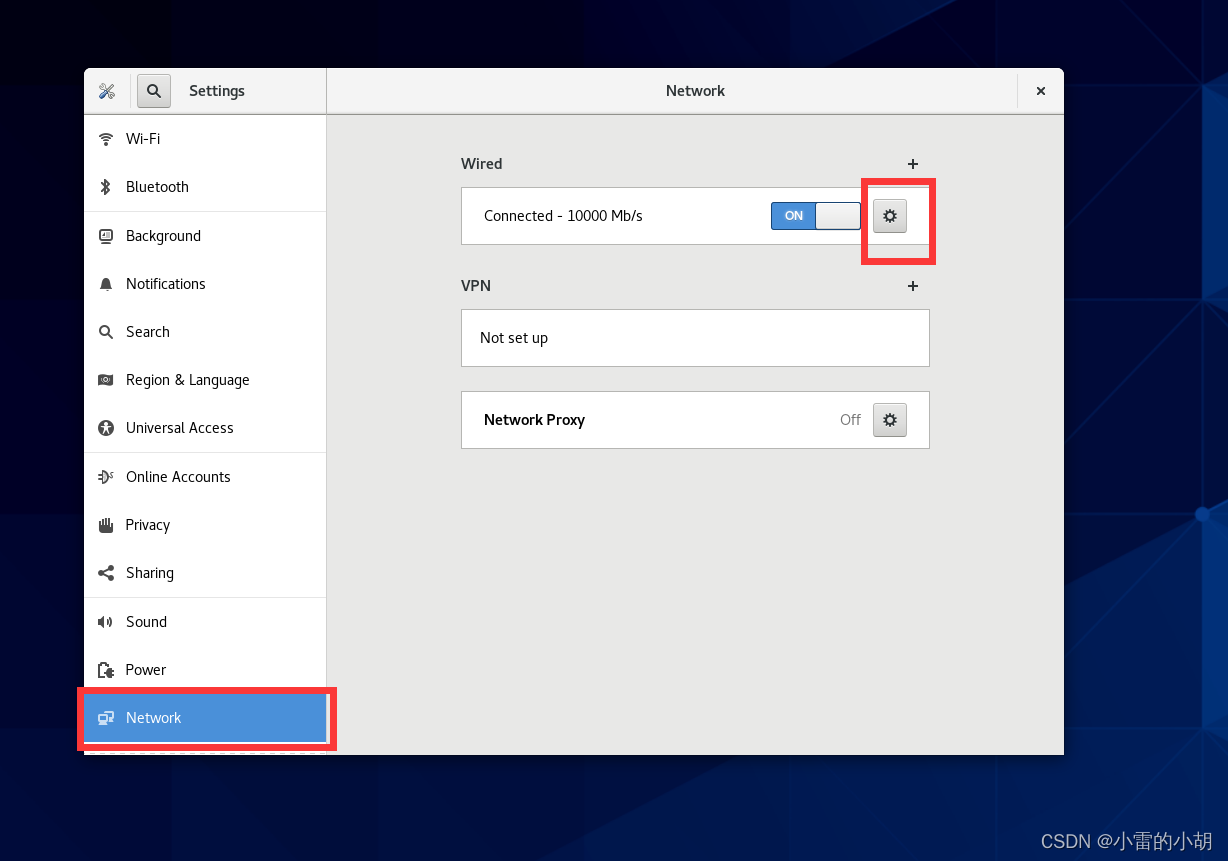
找到Network
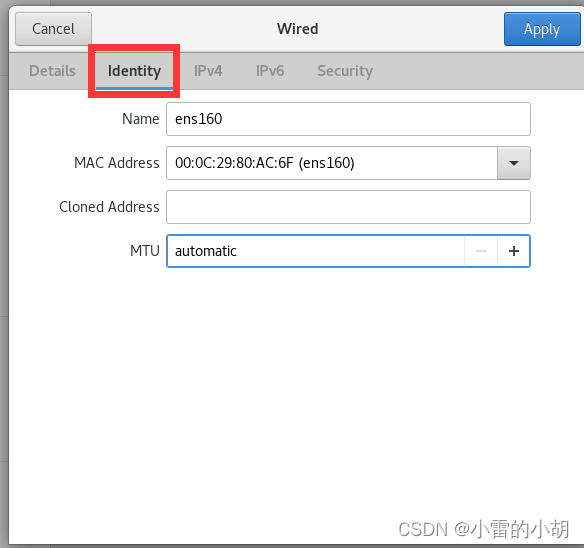
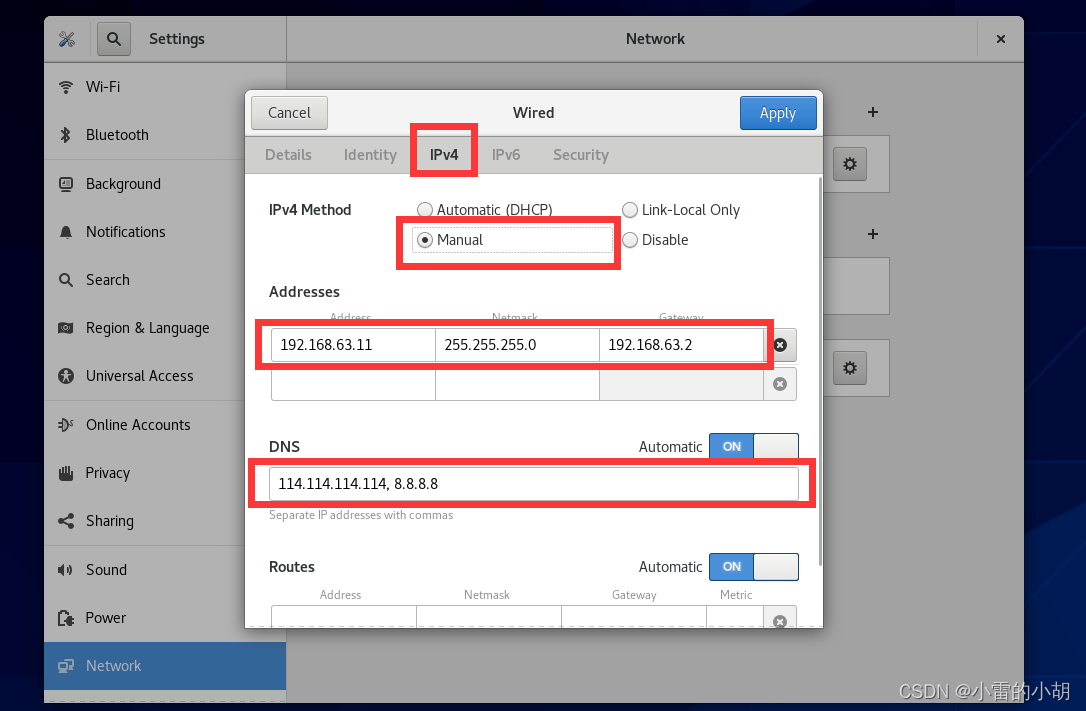
配置完成之后,重启虚拟机,打开终端,输入命令:ifconfig 进行查看是否配置成功。
对另外两台虚拟机进行同样的操作
这两种方式都可以修改虚拟机的IP信息,可自由选择。
4、设置虚拟机的主机名及hosts映射(三台虚拟机都需要设置)
4.1、设置主机名
以node1为例,查看当前主机名,打开终端输入:
hostname

如果不是超级用户root,建议先切换到超级用户:su root
然后,在终端直接输入 :vim /etc/hostname
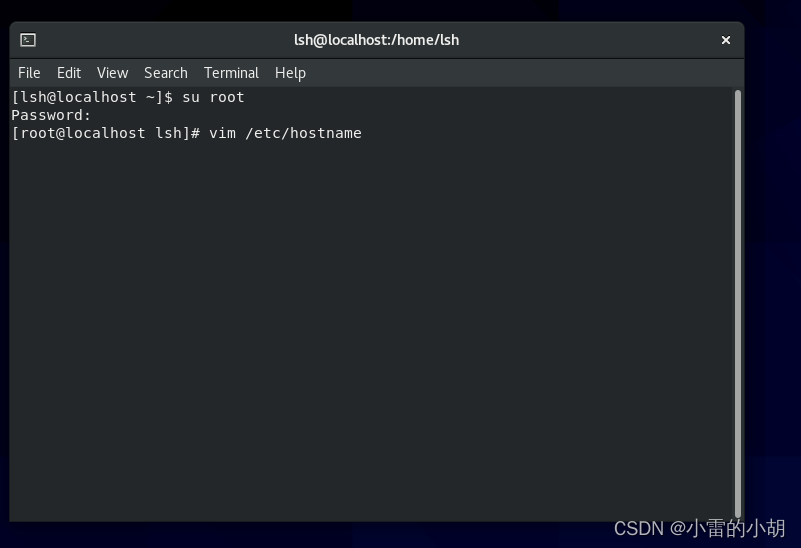
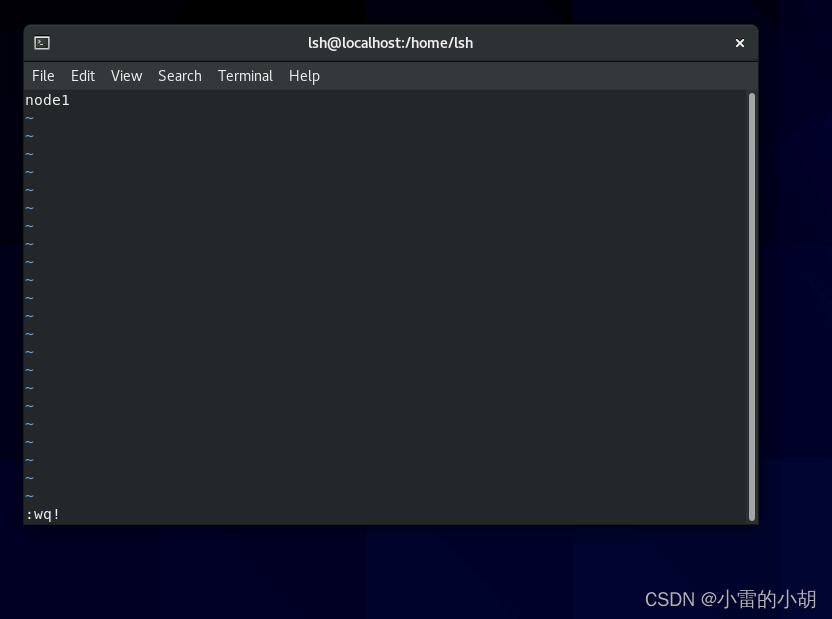
然后按 i 进入编辑模式 将原来的内容替换为新的主机名node1,然后按ESC键,再按英文冒号,输入 wq!,按下回车键Enter,强制保存并退出,重启虚拟机生效
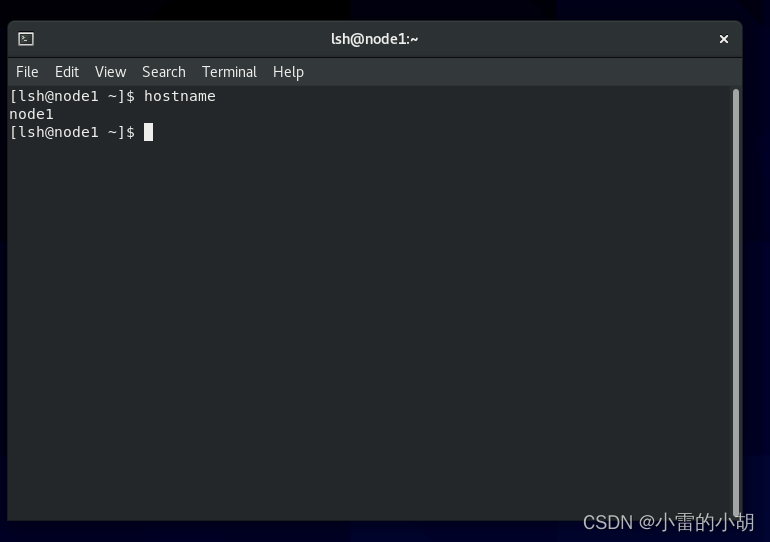
重启虚拟机后,打开终端,输入:hostname 查看主机名是否设置成功
4.2、设置hosts映射
以node1为例,同样的需要在root用户下面操作
打开终端输入命令:vim /etc/hosts

按 i 进入编辑模式,在末尾添加三台虚拟机的ip与主机名,保存退出后,重启虚拟机生效。
192.168.63.11 node1
192.168.63.22 node2
192.168.63.33 node3

重启虚拟机后,打开终端,输入命令:
ping node1、ping node2、ping node3
如果都能ping通,则hosts映射成功。
5、关闭虚拟机防火墙
以node1为例,在进行下面命令的操作时,建议切换到root用户
关闭防火墙
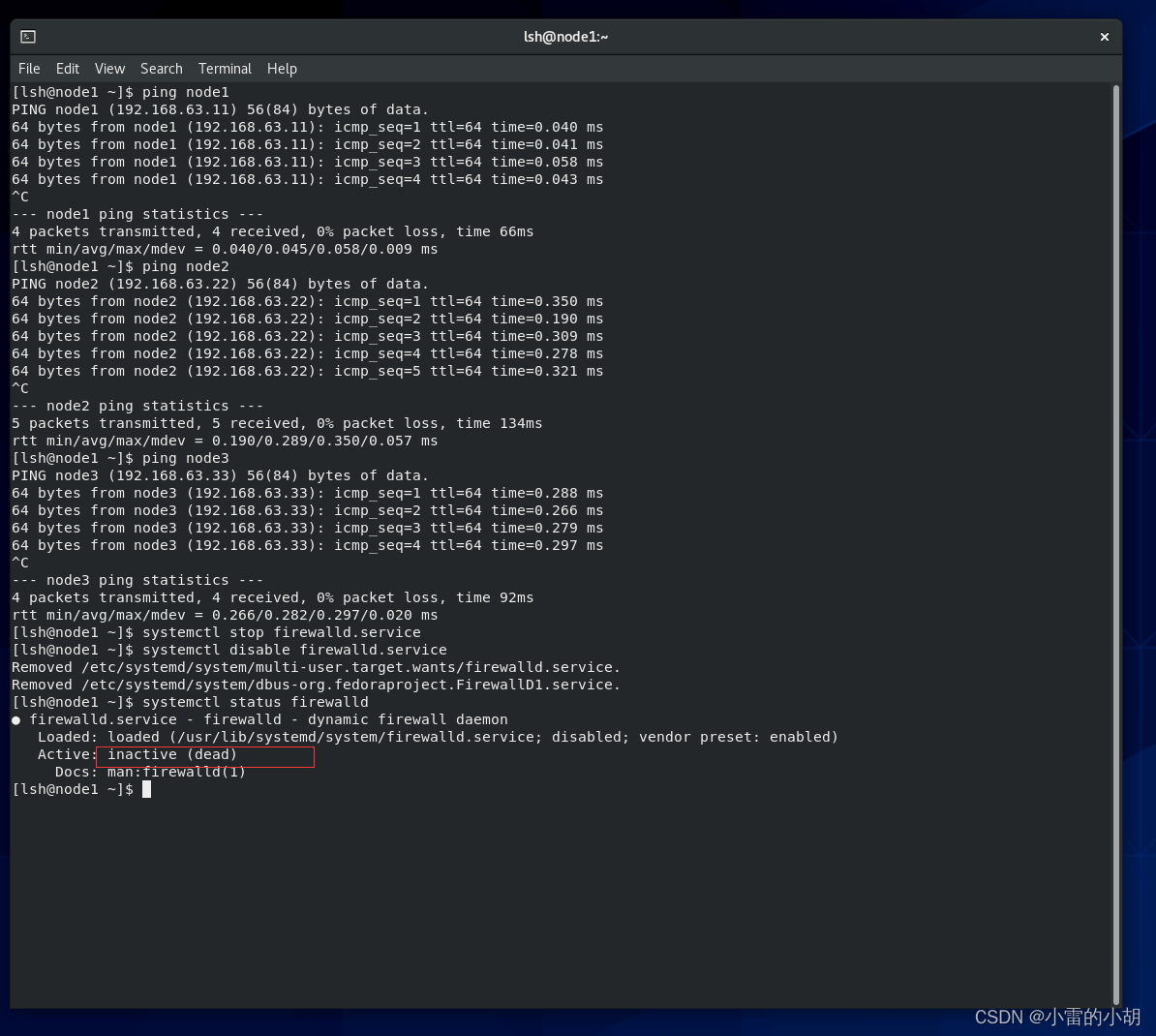
systemctl stop firewalld.service禁止防火墙开启自启
systemctl disable firewalld.service
查看防火墙状态
systemctl status firewalld
6、使用Xshell连接虚拟机
首页需要安装好Xshell这个软件并保证三台虚拟机都是出于开启状态,然后打开Xshell,新建会话,输入名称和主机

然后进行连接


使用同样方法连接另外两台虚拟机。
7、ssh免密登录(node1 做即可)
在Xshell的node1会话中输入:ssh-keygen,一直敲击回车,知道出现如下图所示即可

然后继续输入:ssh-copy-id node1 ,确认后输入yes,接着输入密码。
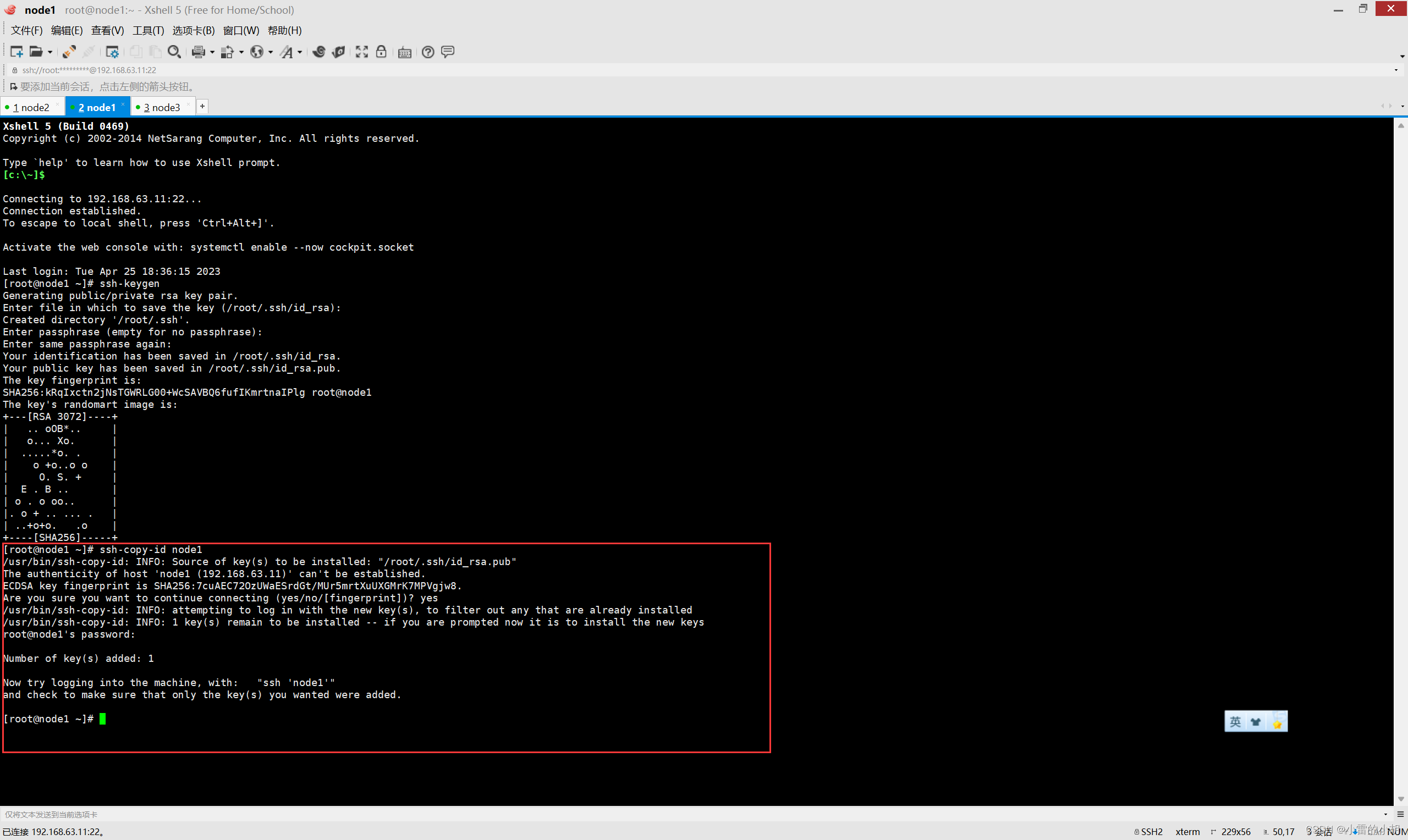
然后输入:ssh-copy-id node2、ssh-copy-id node3 执行上述操作
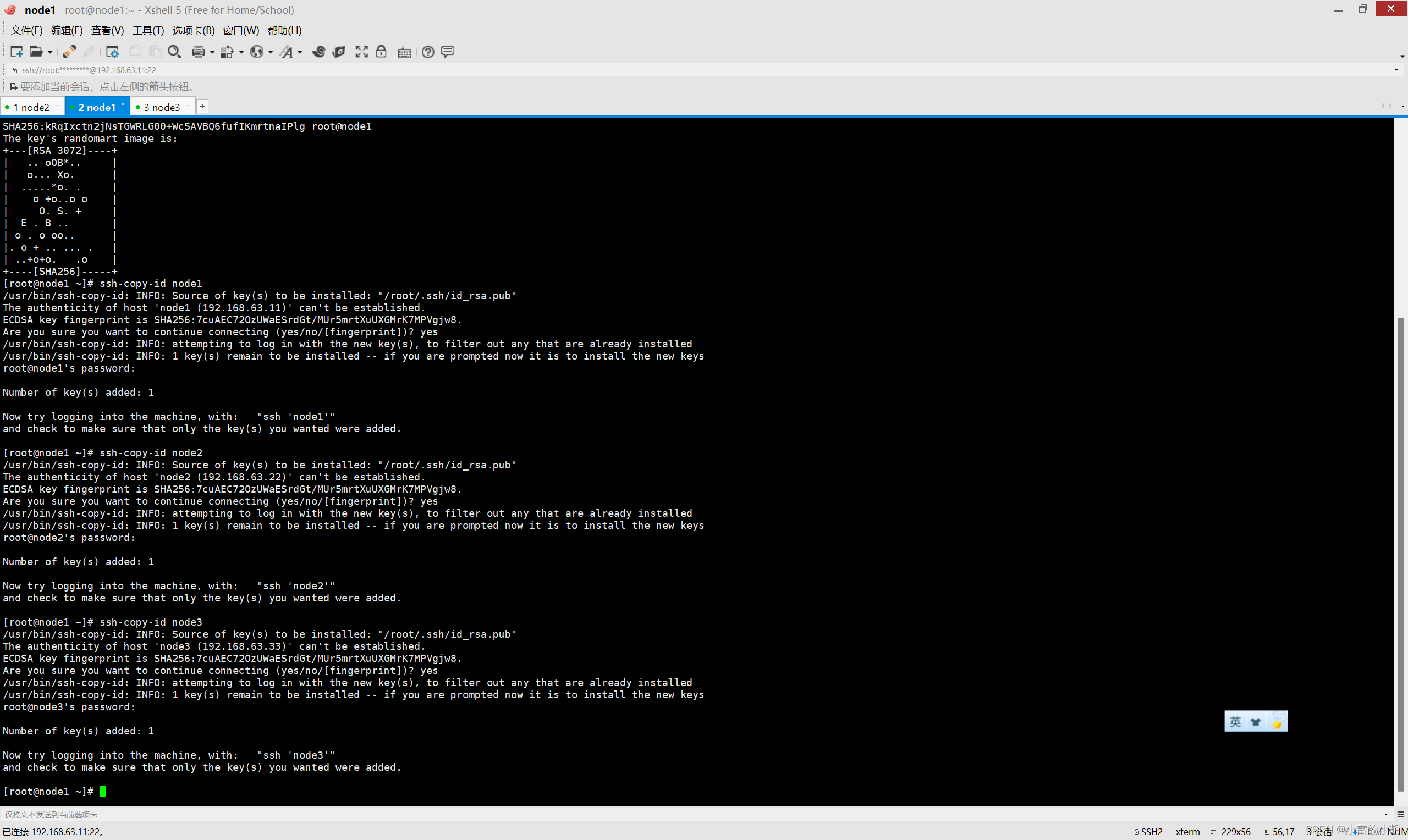
最后分别输入:ssh node1、ssh node2、ssh node3,进行测试,如果都能登录成功,则ssh免密登录设置成功。退出使用:exit。
有一些特别情况就是,第三次输入命令的时候,可能会再次出现要你输入yes以及密码的步骤,出现时,我们只需要输入yes和密码就行了。
8、时间同步(三台机器都做)
以node1为例,在node1会话里先后输入以下命令
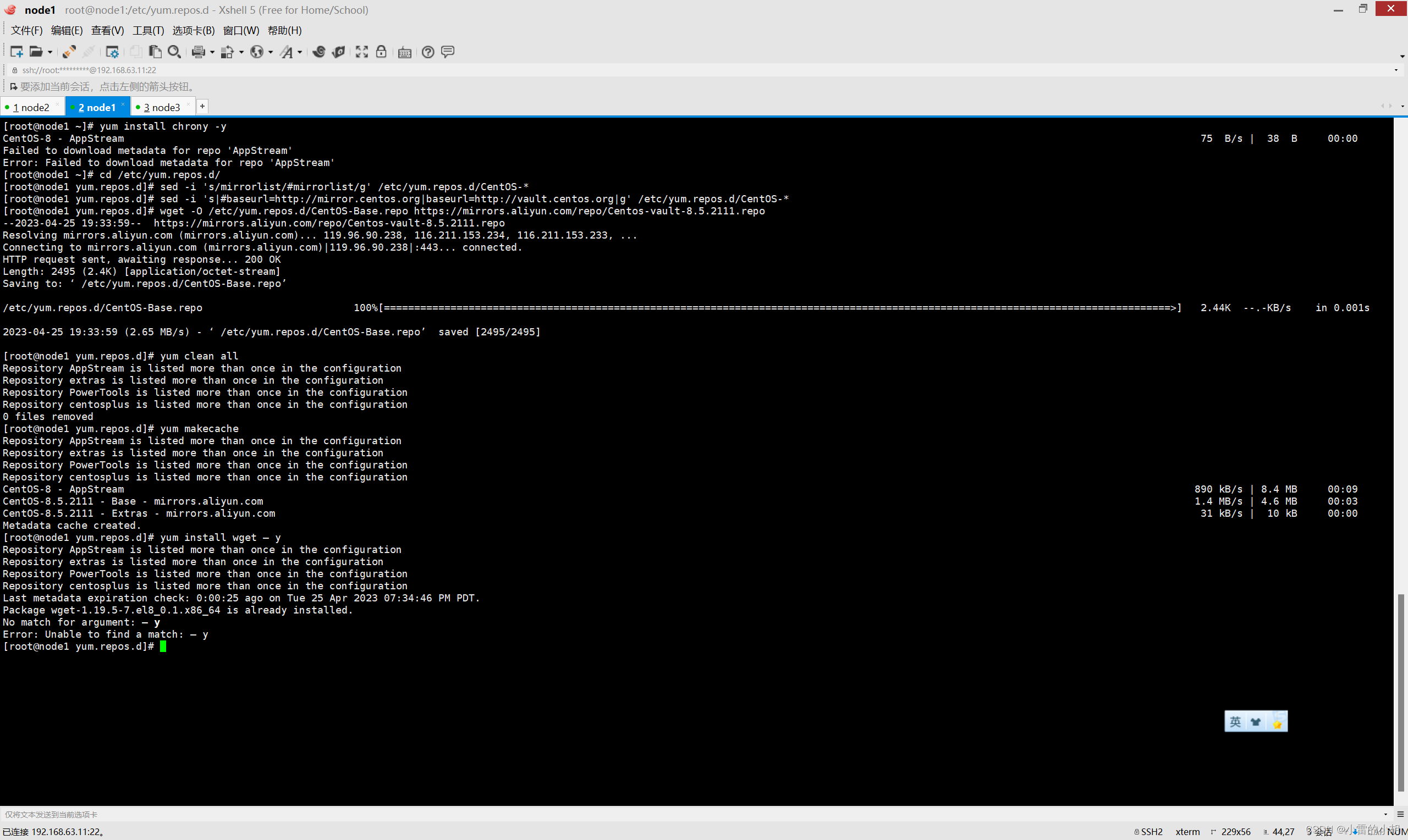
yum install chrony -y #安装chrony
timedatectl set-timezone Asia/Shanghai #修改时区
vim /etc/chrony.conf #修改chrony.conf文件
pool ntp.aliyun.com iburst #注释chrony.conf文件的第三行,在第四行添加该内容,保存退出如果在安装时出现以下报错,请自行百度或者查看我另一篇文章,有解决方案



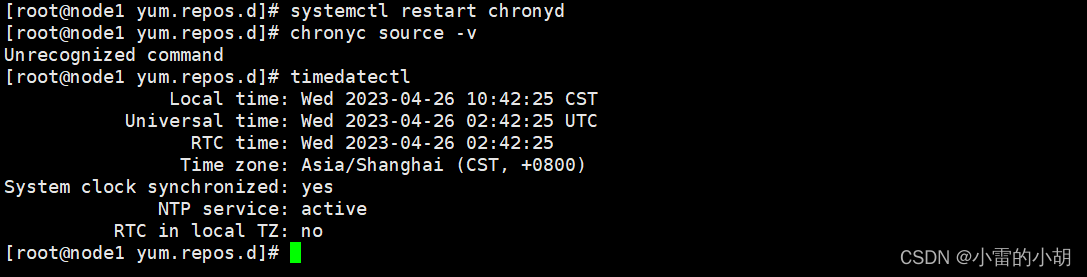
设置完成后,重启chrony服务:systemctl restart chronyd
时间同步:chronyc source -v
查看本机时间:timedatectl
9、上传并解压安装包
9.1、在Xshell的node1会话里面先后输入以下命令,创建相应的文件夹。
mkdir -p /hadoop/software #安装包存放路径
mkdir -p /hadoop/server #软件安装路径
9.2、上传下载好的jdk-8u51-linux-x64.tar.gz 和 hadoop-3.2.4.tar.gz。
上传时我使用的工具是:FileZilla,
打开 FileZilla,【文件】 -> 【站点管理器】,新建站点并连接

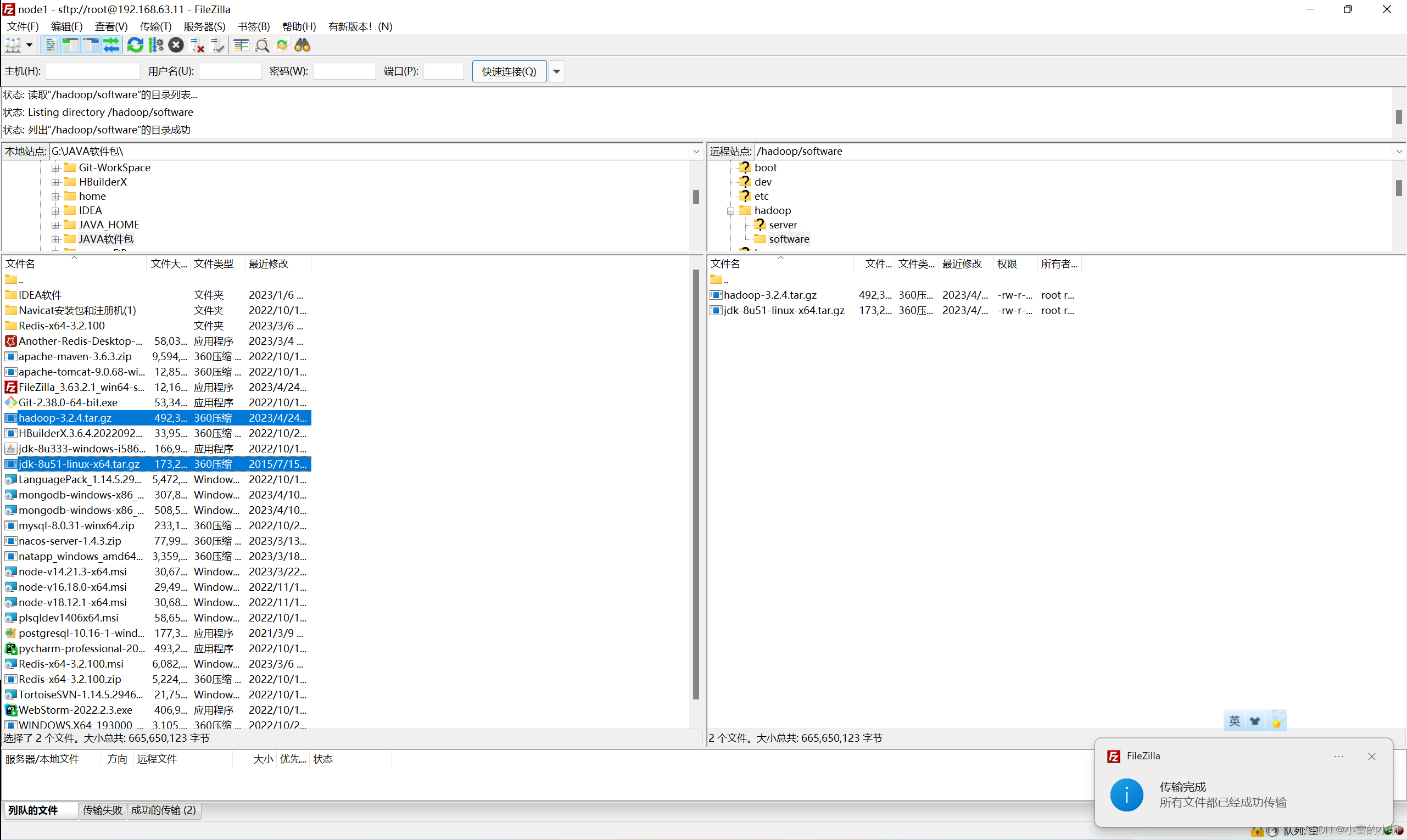
9.3、进入/hadoop/software/目录,查看上传的安装包。同时使用以下命令对安装包进行解压
tar zxvf jdk-8u51-linux-x64.tar.gz -C /hadoop/server/
tar zxvf hadoop-3.2.4.tar.gz -C /hadoop/server/进入目录 /hadoop/server/ 看是否解压成功

10、安装JDK
如果原来安装过jdk的请先删除原装JDK,如果没有安装过则直接配置JDK环境变量
输入命令:vim /etc/profile

然后在最末尾添加代码:
export JAVA_HOME=/hadoop/server/jdk1.8.0_51
export PATH=:$JAVA_HOME/bin:$PATH保存并退出。

更新profile文件,使配置生效
source /etc/profile
然后输入以下命令进行验证
java -version
javac 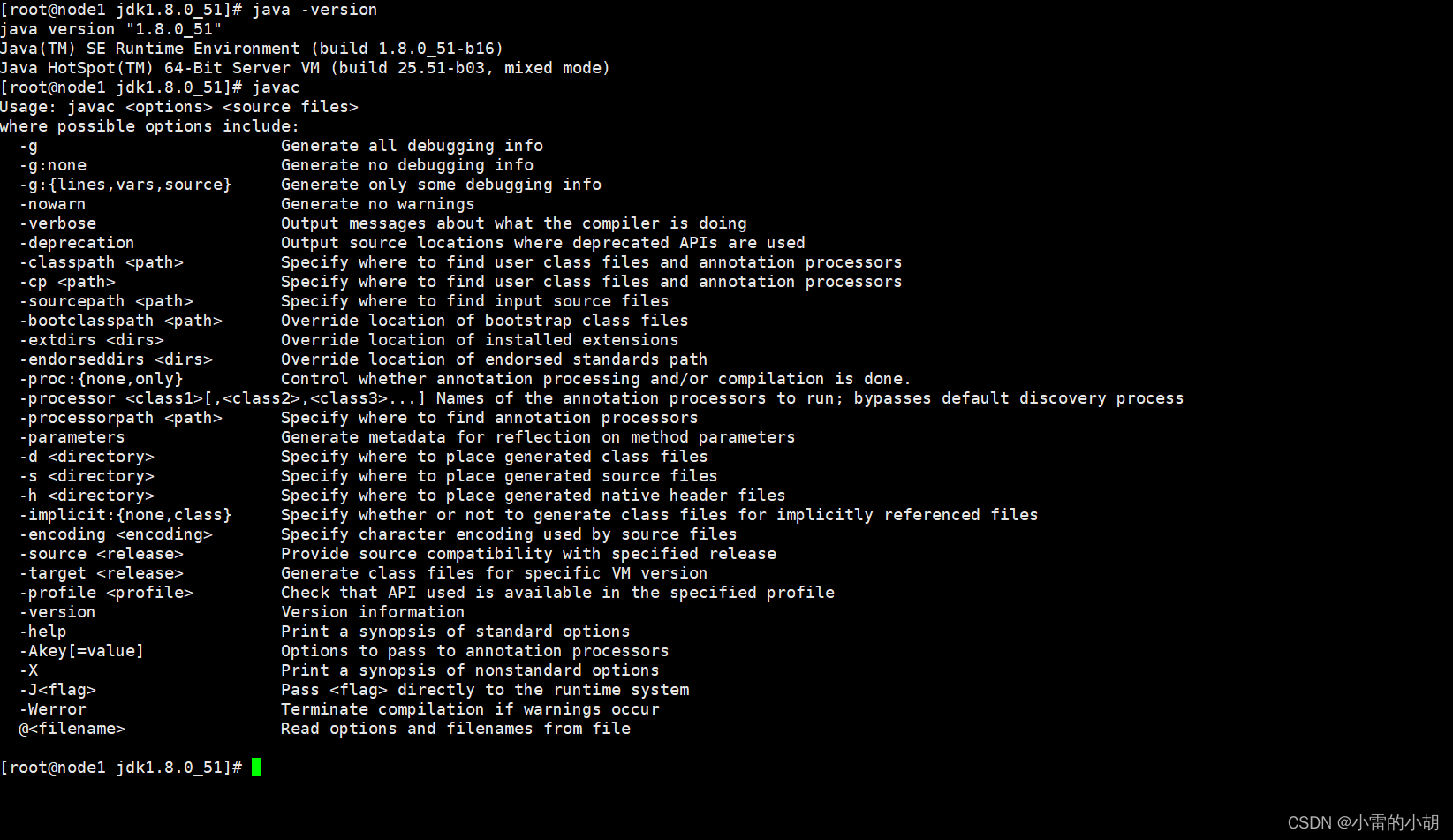
11、编辑Hadoop配置文件(node1 做即可)
11.1、Hadoop安装包目录结构解释
| 目录 | 说明 |
| bin | Hadoop最基本的管理脚本是使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop |
| etc | Hadoop配置文件所在的目录 |
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序 |
| lib | 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用 |
| libexec | 各个服务对应的shell配置文件所在的目录,可用于配置日志输出、启动参数(如JVM参数)等具体信息。 |
| sbin | Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。 |
| share | Hadoop各个模块编译后的jar包所在的目录 |
11.2、创建用于存放数据的data目录
mkdir -p /hadoop/server/hadoop/data/namenode #存放namenode数据
mkdir -p /hadoop/server/hadoop/data/datanode #存放datanode数据11.3、修改 hadoop-env.sh 文件 在第55行添加下列代码并保存
#配置JAVA_HOME
export JAVA_HOME=/export/server/jdk1.8.0_321
#设置用户以执行对应角色shell命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root


11.4、 修改core-site.xml文件(配置NameNode),在<configuration>中添加如下代码:
<!-- 默认文件系统的名称。通过URI中schema区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs文件系统访问地址:http://nn_host:8020。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
所有xml文件的编辑都可以利用 FileZilla 工具,将文件复制到本地,利用文本编辑器进行修改。
方式多样,自行选择编辑方式

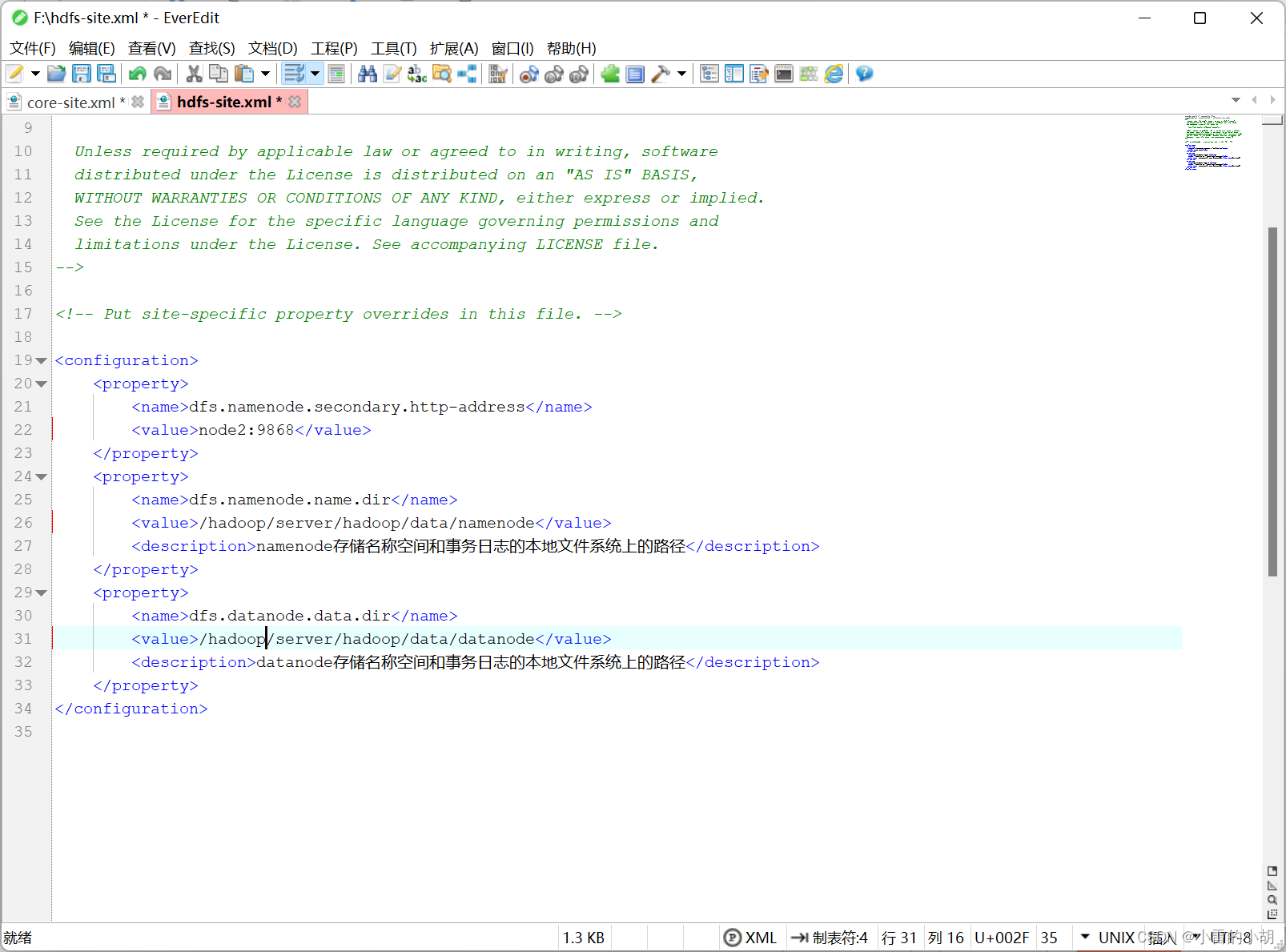
11.5、 修改hdfs-site.xml文件(配置HDFS路径),在<configuration>中添加如下代码:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/server/hadoop/data/namenode</value>
<description>namenode存储名称空间和事务日志的本地文件系统上的路径</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/server/hadoop/data/datanode</value>
<description>datanode存储名称空间和事务日志的本地文件系统上的路径</description>
</property>
11.6、修改mapred-site.xml文件(配置MapReduce),在<configuration>中添加如下代码:
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>

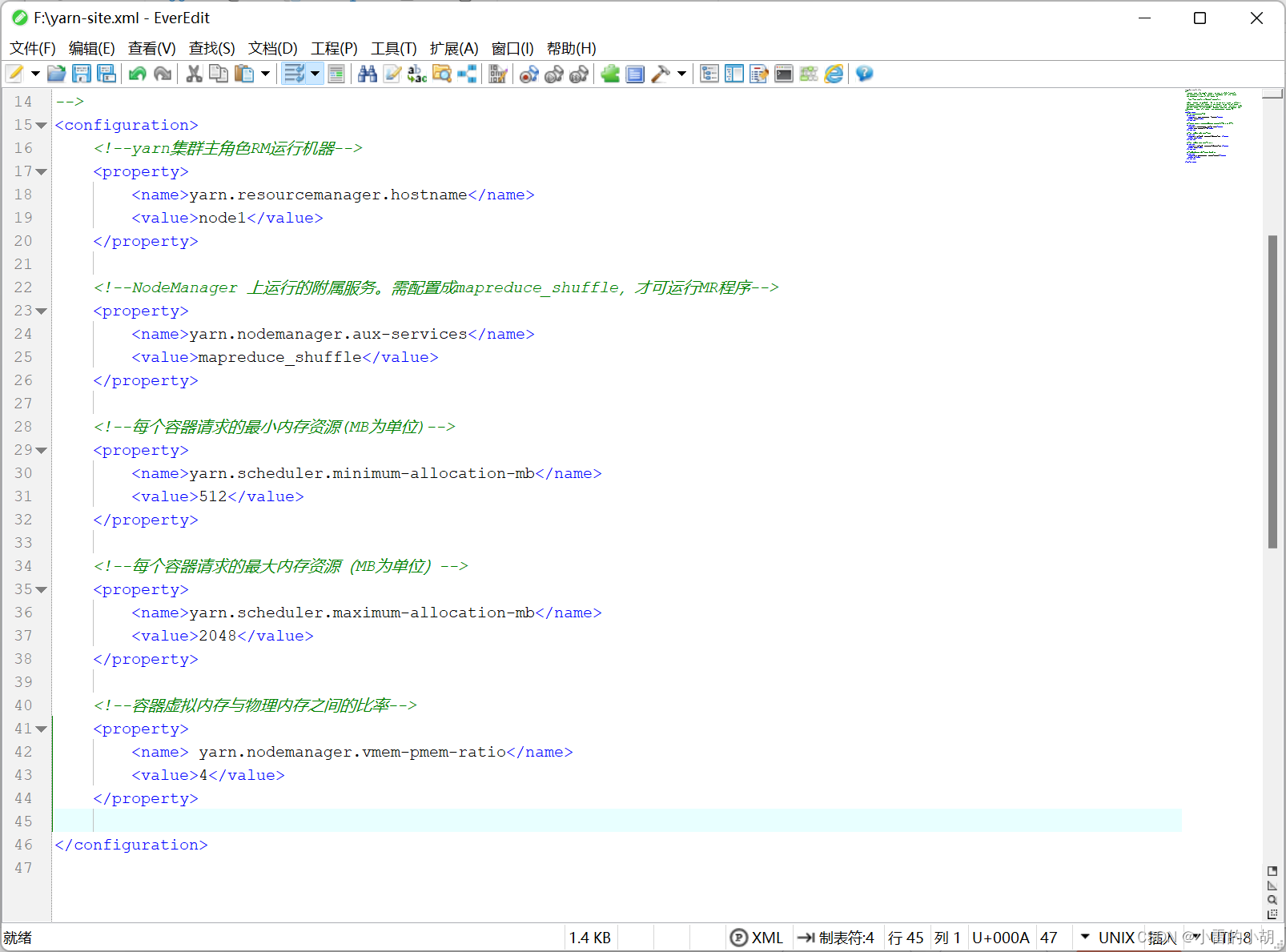
11.7、修改yarn-site.xml文件(配置YARN),在<configuration>中添加如下代码:
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
11.8、修改workers文件,删除第一行的 localhost,然后添加如下代码:
node1
node2
node3 
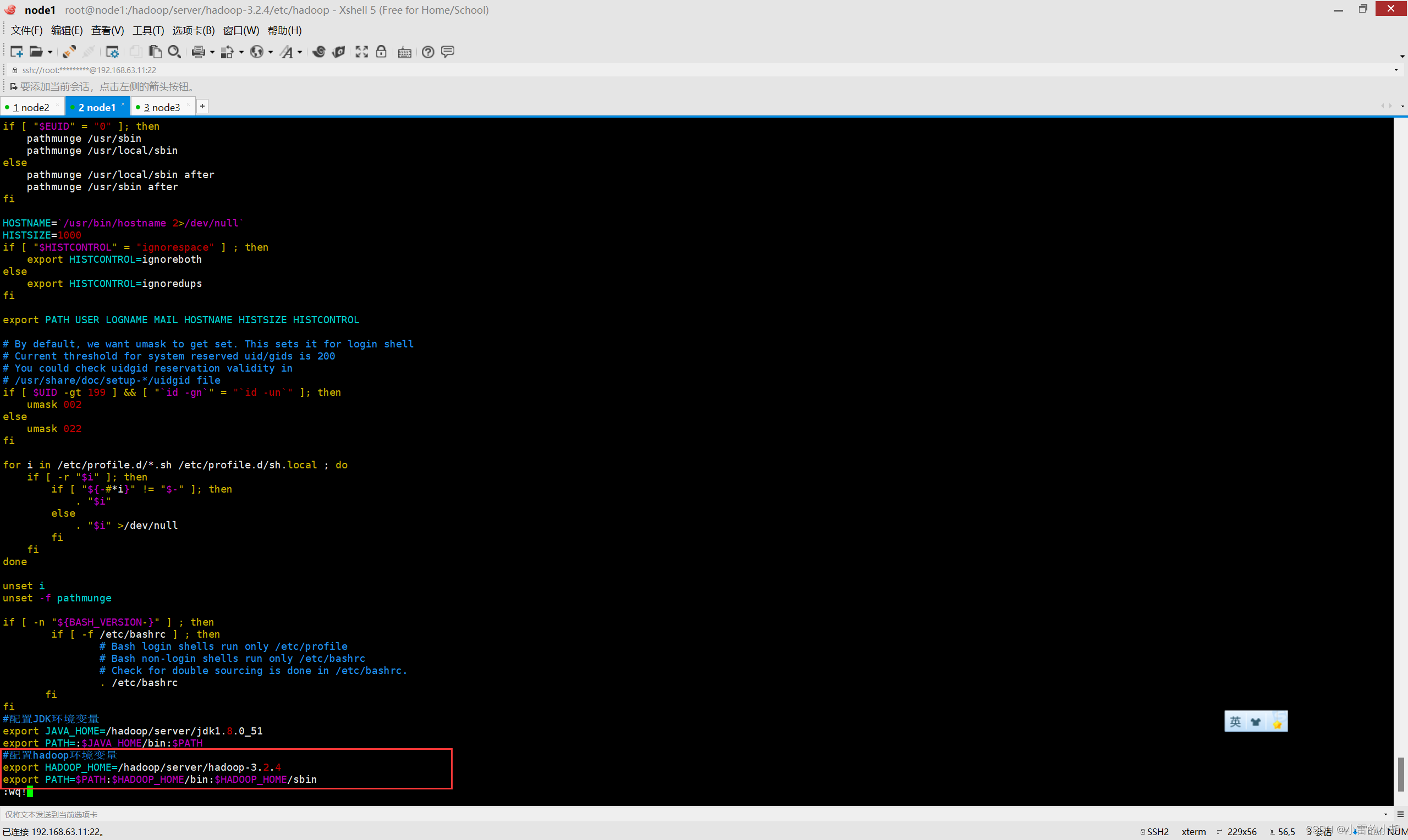
11.9 在 /etc/profile 中配置hadoop环境变量
vim /etc/profile
#在最末尾添加以下内容
export HADOOP_HOME=/hadoop/server/hadoop-3.2.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
11.10、输入:以下代码使配置生效
source /etc/profile然后输入 hadoop 检测环境变量是否配置成功
12、分发配置
在node1会话中输入下列命令,将所有配置复制给node2、node3
scp -r /hadoop node2:/
scp -r /hadoop node3:/
scp -r /etc/profile node2:/etc/
scp -r /etc/profile node3:/etc/命令执行完毕之后,在node2、node3虚拟机上分别执行 source /etc/profile,是配置生效。并输入java -version 、javac、hadoop等命令检测环境变量是否生效
13、启动Hadoop集群
13.1、格式化HDFS,在首次启动HDFS时,必须要先将其进行格式化,命令如下:
hdfs namenode -format itcast-hadoop![]()
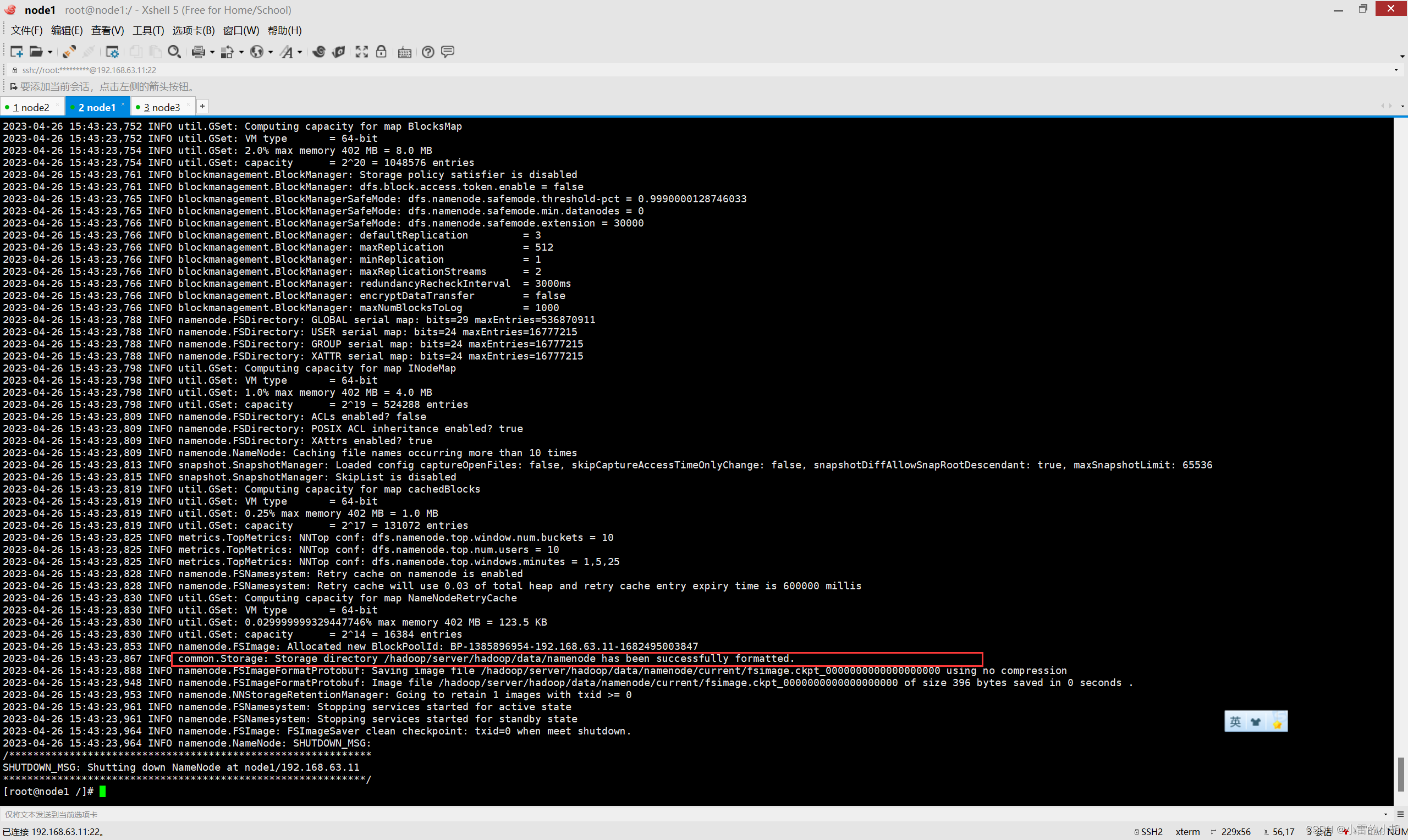
输入以下命令,查看格式化是否成功
ll /hadoop/server/hadoop/data/namenode/current
13.2、一键启动hadoop集群
使用以下命令来启动或关闭集群
start-all.sh #启动
stop-all.sh #停止
检测是否启动成功,在node1、node2、node3会话中分别输入jps命令,与下图相同则启动成功:
node1:

node2:

node3:

14、访问Hadoop Web UI页面
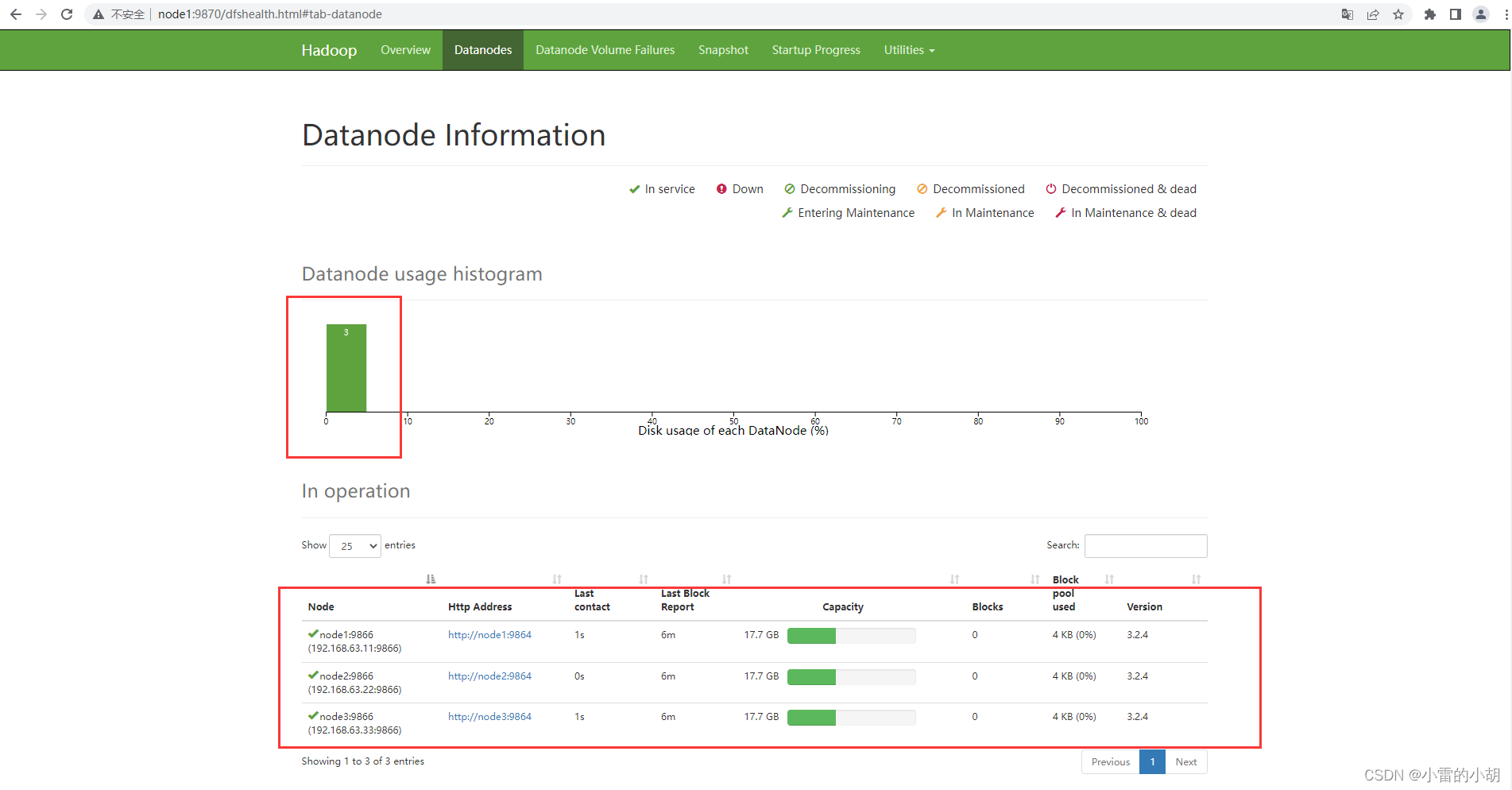
14.1、在浏览器输入: http://node1:9870 ,访问Hadoop Web UI页面的HDFS集群,然后点击Datanodes,查看启动的节点。
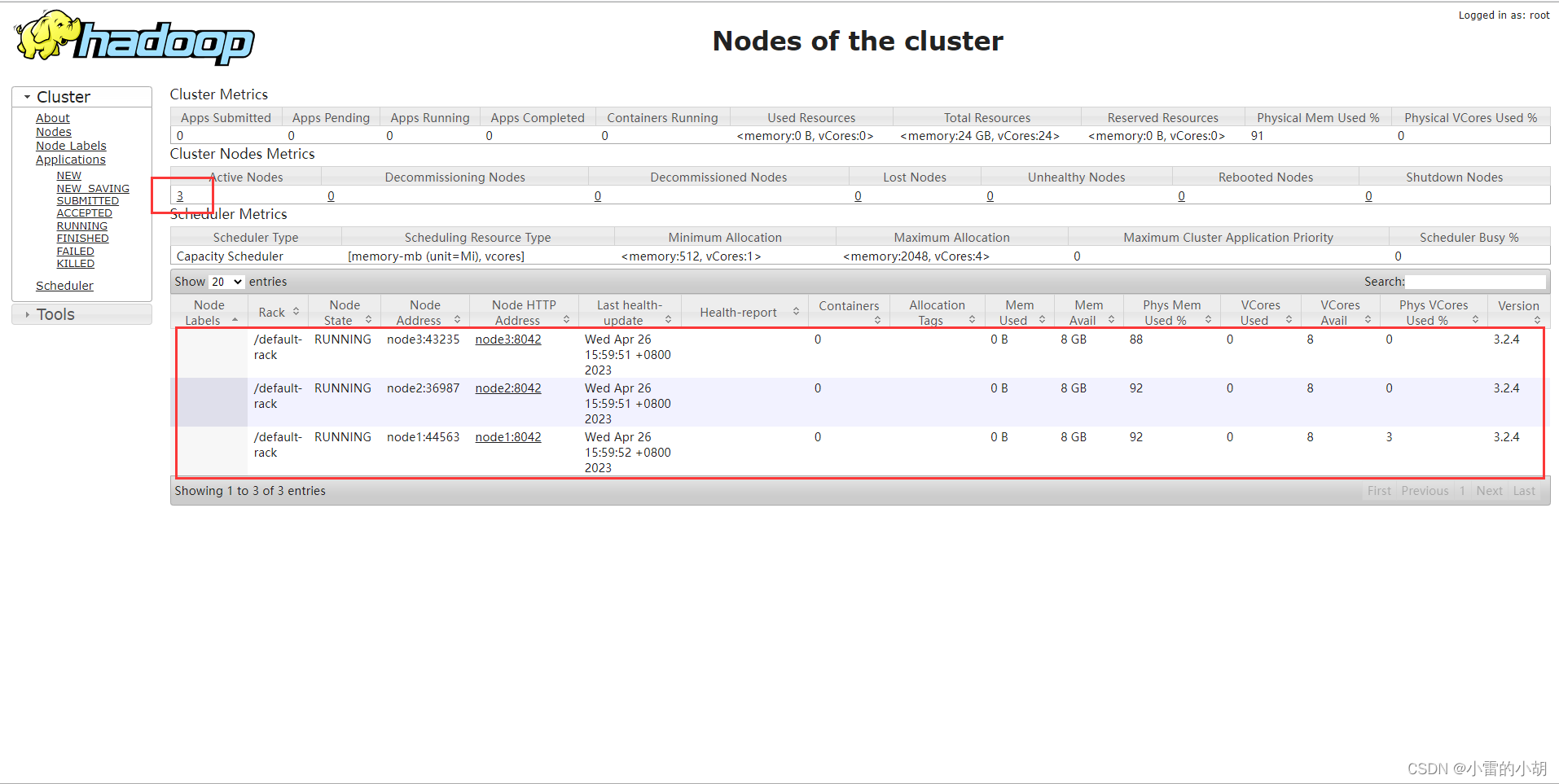
14.2、在浏览器输入 :http://node1:8088 访问并查看Hadoop Web UI页面的Yarn集群
到此,Hadoop集群已经搭建完成。














 2886
2886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









