






多层感知机
多层感知机在单层神经⽹络的基础上引⼊了⼀到多个隐藏层(hidden layer)。隐藏层位于输⼊层和输 出层之间。隐藏层中 的神经元和输⼊层中各个输⼊完全连接,输出层中的神经元和隐藏层中的各个神经元也完全连接。因 此,多层感知机中的隐藏层和输出层都是全连接层。
虽然神经⽹络引⼊了隐藏层,却依然等价于⼀个单层神经⽹络。不难发现,即便再添加更多的隐藏层,以上设计依然只 能与仅含输出层的单层神经⽹络等价。
CNN卷积神经网络
以计算机视觉特征提取为例子介绍这类模型

3X3的是卷积核,或者说是过滤器(这里提到的卷积一般不包括两次镜像反转,先向右转再上下反转),卷积核维度一般取奇数,为了有一个中心和方便计算padding的值。主要属性有移动的步长stride和padding
这里展示的是一个简易的垂直边缘检测,可以看到一个6X6的输入在经过3X3的卷积核卷积一次后变为了4X4的输出,如果是在大型神经网络中可能会有很多道卷积,这也会导致输出的图形越来越迷你。同时图形角落或边缘的像素点在输出中采用较少,由此会导致丢失掉图形边缘的许多信息。为了防止这两种情况发生,可以在原图形外面再填充一数层像素(通常取0),几层也就是padding的值。通常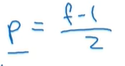 。所以卷积有两种模式,分别是valid和same,对应外层是否填充了像素点(或者说输出图形的尺寸是否与输入的相同)
。所以卷积有两种模式,分别是valid和same,对应外层是否填充了像素点(或者说输出图形的尺寸是否与输入的相同)
两种经典的3X3卷积核
把这九个数字当做九个参数,用反向传播算法去学习
加上步长以后的输出维度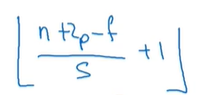
三维卷积(立方体卷积)
卷积核和输入的通道数维度必须相等

如图一个6X6X3的彩色图像经过两个3X3X3的卷积核卷积后得到了一个4X4X2的立方体输出,由此我们知道了可以利用多个三位卷积核同时实现垂直/水平/45度等任何形式的边缘检测(特征映射)
卷积网络的特征:不管输入的图片大小,参数数量保持固定不变,防止过拟合。输出图像的深度(管道数)取决于过滤器(卷积核)的数量.。在真实的卷积网络模型中,通常随着层数的增加图像尺寸在不断变小,深度(通道数)在不断增加。难点在于确定卷积核维数,stride,padding这三个超参的大小。
CONV(卷积层) POOL池化层 FC(全连接层)
池化层
最大池化:保留一个区域中的最大值。最大化操作的功能就是只要在任何一个象限内提取到某个特征,它都会保存在最大池化的输出里。换言之就是如果在过滤器中提取到某个特征,那么保留其最大值,如果没有提取到这个特征,那么其最大值也会很小。最大池化的特点是它有一组超参,却没有参数需要学习,一旦确定了f和s,它就是一个固定运算。(通常f和s都取2),通常对每个信道都会做池化处理。
最大池化的输入和输出尺寸
卷积神经网络实例
大量的参数存在于全连接层,conv卷积层参数较少,池化层没有参数。随着神经网络的加深激活值逐渐变小
卷积层的两大优势:参数共享,稀疏连接,从而避免过拟合
参数共享:在例子中九个参数可以提取整个图像的特征
稀疏连接:在例子中每个输出都只与图像中的九个像素点有关,其他位置的信息无法影响该输出

平移不变是卷积网络在计算机视觉中的一大优势
深度卷积网络:
1.几种经典卷积神经网络模型:
LeNet-5 识别手写数字(只能是灰度图片)

AlexNet表现比LeNet更为出色,它有6000万个参数,且使用了ReLu激活函数
VGG-16网络 没有太多超参数,只需要专注于搭建卷积层。16的意思是这个网络包括16个卷积层和全连接层。图像在卷积层信道翻倍,然后在池化层尺寸缩小一半。非常有规律。

2.残差网络
深度很大的神经网络很难训练,因为存在梯度消失和梯度爆炸的问题。那么层数增多的时候,最终的求出的梯度更新将以指数形式增加,即发生梯度爆炸,如果此部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。
梯度消失:梯度消失问题发生时,接近于输出层的hidden layer 3等的权值更新相对正常,但前面的hidden layer 1的权值更新会变得很慢,导致前面的层权值几乎不变,仍接近于初始化的权值
梯度爆炸:当我们将w初始化为一个较大的值时,例如>10的值,那么从输出层到输入层每一层都会有一个s‘(zn)*wn的增倍,当s‘(zn)为0.25时s‘(zn)*wn>2.5,同梯度消失类似,当神经网络很深时,梯度呈指数级增长,最后到输入时,梯度将会非常大,我们会得到一个非常大的权重更新,这就是梯度爆炸的问题
为了能够训练深度很深的神经网络,我们用到了残差网络ResNets(Residual Networks)技术

图中上方蓝色的线和下面紫色的线就是跳跃连接,能将信息传递到网络的更深层

图中有五个残差块
构建一个ResNets网络就是将很多这样的残差块堆积在一起,形成一个深度神经网络

没有残差网络,随着网络深度的增加,训练错误会减少然后再增加
序列模型
循环神经网络RNN
以nlp为例子介绍这个模型
先建立词典,假设有10000个热词,one-hot表示法(就是softmax分类任务里的标签表示)创建标签。

nlp中一个词的词义通常需要联系前文,所以a[t]是这个词的输出,同时也是下一个单词输入的变量之一,对a[t]再经过一层隐藏层处理得到y^是对这个词词义的预测输出
nlp循环神经网络的激活函数通常采用tanh

左右两边的公式等价,右边是为了简洁将左边的公式略作变形
时间反向传播算法
多种不同的RNN神经网络

语言模型
通过概率来判断当前识别到的语句可能的意思,先建立词典,再将输入的单词转换为one-hot标签,不在字典中的可以设为<UNK>标签。结尾<EOS>标签
解决RNN网络中的梯度消失问题:GRU门控循环单元 梯度爆炸的解决方法:裁剪梯度

实际应用中的GRU单元
 LSTM长短期记忆神经网络
LSTM长短期记忆神经网络

Γ门标记 a激活值 c~候选值 Γu更新门 Γf遗忘门 Γo输出门 c记忆细胞擅长于长时间记录某个值
双向RNN

从左边执行一遍前向传播,输入X4得到a^<—(4),a^<—(4)再和X3一起得到a^<—(3)。
深层RNN

实际应用中,三层的RNN网络已经算较大的了 。
注意力机制
seq2seq模型
机器翻译

前方为编码网络,后面为解码网络,用于机器翻译,这是一种较为常见的sequence to sequence模型。编码网络对输入的句子进行编码,解码网络则负责翻译成目标语言的句子。
图像描述

去掉softmax的卷积部分可以视为编码网络,后面输入一个RNN网络负责输出图像描述。

机器翻译模型的decoder部分近似于语言模型,两种模型之间的差别主要体现在语言模型第一个激活值输入为零向量,而机器翻译模型的encoder部分会计算出一系列向量来表示输入的句子。所以机器翻译又可以叫做条件语言模型。通过输入的句子,模型将会告诉你各种英文翻译所对应的可能性。可能的句子组合太过庞大,所以我们需要一种合适的搜索算法来找到最适合的句子。
集束搜索















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









