






流程:
系统导出的表格索引名称都是英文,语言障碍导致阅读困难,所以决定将英文全部加上中文解释。但能够依靠的是一张中英文对应表,虽然每个表头都有,但是顺序是不一样的,所以需要建立索引,一一对应,行列对调一下,再插入一列写进去,最后对调回来就可以了。
原英文表格:

给出的中英文txt文件:

得出的结果表格:

实现过程:
1.初始化和读取文件
import pandas as pd
#读取
df = pd.read_excel('going.xlsx', header=None)
df1 = pd.read_csv('-c.txt', header=None, sep='\t', encoding='utf-8')pandas库更新啦,很久没用的我不得已卸载重下,头铁直接冲下了一个半小时毫无音讯,挂个镜像半分钟……
df读取的就是英文表头的表格,df1是中英文对照的txt文件,【sep='\t'】是因为我的txt每一行前面都有个空格。
2.分列与命名
df1 = df1[0].str.split(' ', expand=True, n=2)
df1 = df1.rename(columns={1: 'name', 2: 'cn_name'})
df1 = df1[['name', 'cn_name']]第一行:
现在的txt文件读进来已经根据每行分开了,再用split对它进行分列,分列的依据还是两列数据之间的空格;expand=true指的是会把切割出来的内容分成一列,如果你不想要就写成FALSE;这个n的意思是分列几次,假如说我的文件内容是【1,2,3,4】,n=1就会分成【1】和【2,3,4】,n=2会分成【1】【2】【3,4】;因为我的文件里每一行开头都有个空格,所以分了两次,第一列就是空格。
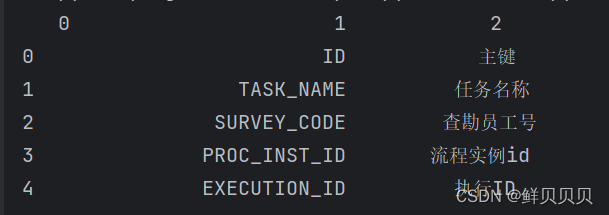
第二行:
将分好列命名一下,如上图0是空格列,1是英文,2是中文。
第三行:
因为有三列,所以只提取表头为这两个的两列,关于为什么是双重[[]],是因为要提取的是列表元素,详情可以参考这篇文章,说的很清楚。https://zhuanlan.zhihu.com/p/139559986
3.行列转换及表格命名
df = df.T
df = df.rename(columns={0: 'name'})
第一行:
就是简单的行列兑换,第一行变为第一列,这样很多操作都很容易做成。
第二行:
因为df本身就是表格,所以第一行换成第一列后,可以直接命名第0列为name
4.按照索引合并:
df = pd.merge(df, df1, on="name", how='left')
df = df.rename(columns={'cn_name': 0})
df = df.T第一行:
merge函数用来合并表格是很好用的,这行意思就是根据name,以左连接的方式进行合并。
意思就是df的数据一定全保留,df1对于df进行基于name的填写,df的name中没有的表头df1即使有也不会写入,这样就可以满足按照索引进行填写了。
第二行:
将原本的第二列,也就是中文列改为0,虽然位置没有改变,但实际上现在这一列已经变成了最小列。
第三行:
转换行列至原型。
5.排序与导出
现在导出表格的话其实是这样的,中文列在最下面,这也是为什么要提前把它设为0,便于后面排序到前面;还因为行列转换多出来一行索引做表头:

代码:
df.columns = df.iloc[0]
df = df.drop(df.index[0])
df = df.sort_index()
df.to_excel('done.xlsx', index=False, header=True)第一行:
将0列提取出来赋予表头,iloc函数就是主打的提取。
第二行:
将第一行删除,经过第一行我们可以得到的是表头和第一行都是英文名称的表格,因此删去第一行就好。
第三行:
进行排序,这样可以把中文列提前到表头下第一行。
第四行:
正常输出
6.完整代码
import pandas as pd
#读取
df = pd.read_excel('going.xlsx', header=None)
df1 = pd.read_csv('-c.txt', header=None, sep='\t', encoding='utf-8')
#分割
df1 = df1[0].str.split(' ', expand=True, n=2)
#print(df1)
df1 = df1.rename(columns={1: 'name', 2: 'cn_name'})
df1 = df1[['name', 'cn_name']]
df = df.T
df = df.rename(columns={0: 'name'})
df = pd.merge(df, df1, on="name", how='left')
df = df.rename(columns={'cn_name': 0})
df = df.T
#将name列的值作为列名
df.columns = df.iloc[0]
df = df.drop(df.index[0])
df = df.sort_index()
df.to_excel('done.xlsx', index=False, header=True)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









