







Thompson Sampling–汤普森采样应用之代码篇
关键词:机器学习,在线学习,人工智能,强化学习,汤普森采样解决最优路径问题,汤普森采样代码例子,Thompson Sampling 机器学习代码例子
1.简介
汤普森选样是一种采样方法,其意在研究在探索成本最低的情况下找到最高的收益(Global Maximum)。如果你还不清楚基础概念,可以看这一篇:
【算法】如何根据算法在赌场发家致富?汤普森采样之多臂强盗算法!
汤普森采样的应用前景其实非常非常的广,小到出门上班选择路线,大到赌场梭哈发家致富。

而当前比较流行的研究应用有:
1)多臂强盗问题(Multi-armed bandit)也就是我们说的赌场老虎机;
2)EE问题(Exploration-Exploitation),也就是大家说的冷启动问题,旨在研究提高给用户推送广告的准确性;
3)机器学习-强化学习(reinforcement learning),人工智能,都很厉害,但是目前看以看到的研究材料不多。
。。。以及非常非常多,万物皆可汤普森。
这里为了引发大家的思路写一个很简单很basic的应用场景。
2.应用举例
2.1故事背景
我们的赌吧老哥Tom刚刚搬到一个新城市,安顿好住所之后嘛,赌瘾来犯难免手痒,他就想了解一下当地赌场的情况。

对于Tom老哥而言最首要的问题就是交通问题,在这个新城市有很多种到达赌场的路线,我们假设他知道每条路大概消耗的时间而不知道每条路平均的消耗时间。(也就是说他知道这条路距离比较长,但是这条路他不堵车啊,反而到达时间要比别的短)。因此他要做的第一件事就是找到到达赌场平均时间最短的那一条路径。
2.2信息分析
假设我们有如下的线路地图,其中有V1到V12一共12个vertex,以及16条路径。Tom老哥的家在V1,赌场的位置在V12。
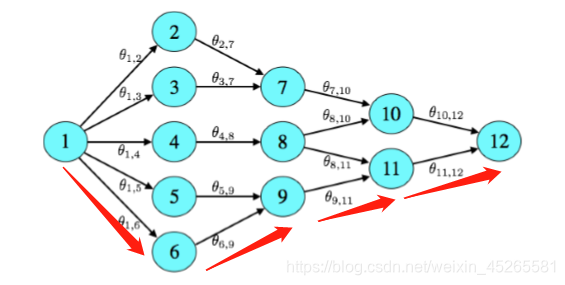
我们通过注视法可以看出来其实从V1到V12一共只有6条路可以走,设为X1,X2,…,X6。
2.3设置事件属性
因为我们目前要处理的是随机时间,所以我们给Xi定义不同的六种随机属性,然后写一个随机时间模拟器,用来模拟每条路每次的耗时情况。
这里我们模拟器输入为每条路的属性,模拟器会首先提取出该条路段的最高限速,用模拟的概率表示突发时间,如果有突发事件发生速度会有不同比例的减低。
代码不需要看懂,明白意思就行!
我这边是定义了一个x的属性,为了方便修改直接用了list而没有创建类,在比较大的项目中我真的强烈建议大家用类来做,list修改起来会瞎真的。
#每条路属性定义
#x=[limited speed, s:km, probability that may rain or tafic jam]
x1=[30,15,10,"x1",0,1,1]
x2=[40,10,5,"x2",0,1,1]
x3=[60,30,30,"x3",0,1,1]
x4=[40,30,30, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









