






1.前言
受到ResNet论文1提出的 residual结构来减轻退化问题的启发,我模仿着resnet网络的结构,新搭建了一个神经网络模型,用于cifar-10数据集2图片分类任务构建了用于残差链接的卷积块并添加到自己新搭建的模型中,使得模型在训练30步后准确率可达90%以上,模型结构和准确率见后面章节的图。工程文件结构如下图所示:
模型在五个卷积模块内进行了三次残差链接,经一层平均池化后传给三层全连接层并输出结果。
本项目包含了两个格式的cifar10数据集[0]: 一个是二进制文件数据集(cifar-10-batches-py),训练用。 一个是图片文件数据集(CIFAR10_imge_version),测试用。
训练步骤:
1.下载源文件并解压,解压后文件结构如图所示
2.cd CIFAR-10
3.安装依赖:pip install -r requirements.txt
4.开始训练:python3 train.py
5.测试模型输出:python3 test.py
此外我还提供了我自己训练好的模型权重供大家测试,下载后放到文件夹saved_model里
2.模型结构
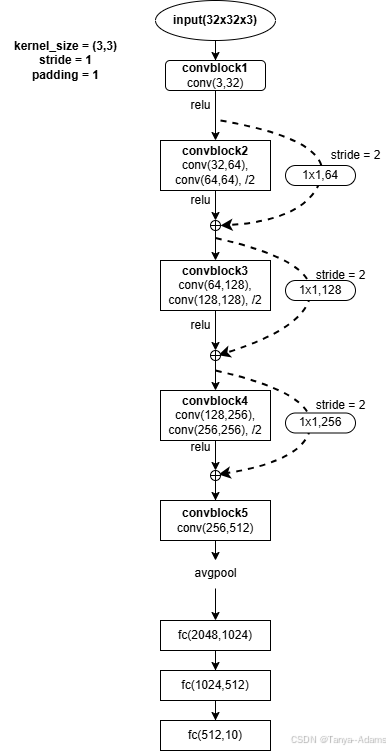
概括地说,模型在五个卷积模块内进行了三次残差链接,经一层平均池化后传给三层全连接层并输出结果,由于新搭建的模型结构相比于resnet18没有那么复杂,所以模型退化效果弱了很多,准确率才能够进一步提升。更多模型设计细节请参考源码MyModel.py。
MyModel.py:
ModelName = 'MyModel'
import torch.nn as nn
# 卷积块
def conv_block(in_channels, out_channels, pool=False):
layers = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)]
if pool: layers.append(nn.MaxPool2d(2,stride=2,padding=0))
return nn.Sequential(*layers)
# 用于残差链接的卷积块
def ResBlock(in_channels, out_channels):
return nn.Sequential(
# 1x1卷积用于调整维度
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=2, padding=0),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = conv_block(3, 32)
self.conv2 = nn.Sequential(
conv_block(32, 64),
conv_block(64, 64, pool=True)
)
self.res1 = ResBlock(32,64)
self.conv3 = nn.Sequential(
conv_block(64, 128),
conv_block(128, 128, pool=True)
)
self.res2 = ResBlock(64, 128)
self.conv4 = nn.Sequential(
conv_block(128, 256),
conv_block(256, 256, pool=True)
)
self.res3 = ResBlock(128, 256)
self.conv5 = nn.Sequential(
conv_block(256, 512),
nn.AvgPool2d(2,2,padding=0)
)
self.linear = nn.Sequential(
nn.Flatten(),
# nn.Dropout(0.2),
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Dropout(0.2),
nn.Linear(1024, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, 10)
)
def forward(self, x):
out1 = self.conv1(x)
out2 = self.conv2(out1)
res_1 = self.res1(out1) + out2
out3 = self.conv3(res_1)
res_2 = self.res2(res_1) + out3
out4 = self.conv4(res_2)
res_3 = self.res3(res_2) + out4
out5 = self.conv5(res_3)
out5 = self.linear(out5)
return out5
3.训练细节
在训练过程中,测试集使用了图像增强手段:
随即裁剪:边界为4
随机水平翻转:概率为默认
归一化:参数是网上搜的,听网上说这样的平均值和标准差非常合适cifar-10的图片
验证集就只做了转为向量和归一化这两步了,因为不需要算梯度
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
# 归一化
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
接下来就是加载数据和定义下降步数了,这里我的下降步数是30步,其实30步就已经有些过拟合了。
注意:
我将num_workers设为8是因为我的cpu核心数是8,你也要根据你的cpu核心数来适当地调整这个参数值,如果设置过高,可能会导致过多的上下文切换,反而降低性能。
batchsize的值要根据自己的显存量力而行,这里我用的硬件是Linux 4090super 服务器,如果你的显存是4g,建议设为64以下.
shuffle=True: 在每个 epoch 开始时打乱数据顺序,确保模型不会学习到数据的顺序性,注意只有在测试集才开启这个超参数。
# 引入数据集
cifar_path = r'data/'
# 训练数据集
train_data_set = datasets.CIFAR10(root=cifar_path,train=True,transform=transform_train,download=False)
# 测试数据集
test_data_set = datasets.CIFAR10(root=cifar_path,train=False,transform=transform_test,download=False)
# 加载数据集到dataloader里面,根据自己显卡的显存来调整batchsize大小,显存少就调小,现存多就调大
batch_size = 128
train_data_loader = DataLoader(train_data_set,batch_size=batch_size,shuffle=True,num_workers=8)
test_data_loader = DataLoader(test_data_set,batch_size=batch_size,shuffle=False,num_workers=8)
# 下降步数
epochs = 30
训练时用的优化器是Adam,以前用SGD感觉效果都不如Adam好,学习率调度使用的是余弦退火策略,经本人实验这个用起来比学习率线性衰退策略效果好上那么一点点
# 实例化网络模型
myModel = MyModel()
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# adam优化器
optimizer = torch.optim.Adam(myModel.parameters(),lr=0.001)
# SGD优化器:效果不如adam好
# optimizer = torch.optim.SGD(myModel.parameters(),lr=0.01,momentum=0.9,nesterov=True)
# 学习率调度:余弦退火策略
scheduler = CosineAnnealingLR(optimizer, T_max=epochs)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
以下是完整的训练代码:
train.py
import os.path
import torch
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
from torch.utils.tensorboard import SummaryWriter
from torch.optim.lr_scheduler import CosineAnnealingLR
from MyModel import MyModel,ModelName
import logging
# 你可以用日志来debug,也可以纯用print
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
# 图像增强
writer = SummaryWriter(log_dir=f'logs/{ModelName}')
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
# 归一化
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 引入数据集
cifar_path = r'data/'
# 训练数据集
train_data_set = datasets.CIFAR10(root=cifar_path,train=True,transform=transform_train,download=False)
# 测试数据集
test_data_set = datasets.CIFAR10(root=cifar_path,train=False,transform=transform_test,download=False)
# 加载数据集到dataloader里面,根据自己显卡的显存来调整batchsize大小,显存少就调小,现存多就调大
batch_size = 128
train_data_loader = DataLoader(train_data_set,batch_size=batch_size,shuffle=True,num_workers=8)
test_data_loader = DataLoader(test_data_set,batch_size=batch_size,shuffle=False,num_workers=8)
# 下降步数
epochs = 30
# 实例化网络模型
myModel = MyModel()
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# adam优化器
optimizer = torch.optim.Adam(myModel.parameters(),lr=0.001)
# SGD优化器:效果不如adam好
# optimizer = torch.optim.SGD(myModel.parameters(),lr=0.01,momentum=0.9,nesterov=True)
# 学习率调度:余弦退火策略
scheduler = CosineAnnealingLR(optimizer, T_max=epochs)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if __name__ == '__main__':
if torch.cuda.is_available():
# logging.debug('gpu可用!')
print('gpu可用!')
myModel = myModel.cuda()
else:
# 最好用gpu来跑,当然如果你对自己的cpu足够自信,你也可以删掉这个分支的代码
print('gpu不可用!这个项目用cpu得跑到猴年马月,装好gpu版torch再来吧')
# logging.debug('gpu不可用!这个项目用cpu得跑到猴年马月,装好gpu版torch再来吧')
exit()
writer_1 = SummaryWriter(log_dir=f'logs/{ModelName}/train')
writer_2 = SummaryWriter(log_dir=f'logs/{ModelName}/test')
for epoch in range(epochs):
# logging.debug('epoch:{}/{}'.format(epoch+1,epochs))
print('epoch:{}/{}'.format(epoch+1,epochs))
# 初始化损失
train_total_loss = 0.0
test_total_loss = 0.0
# 预测正确数
train_total_correct = 0
test_total_correct = 0
# 开始训练
myModel.train()
for data in train_data_loader:
images,labels = data
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = myModel(images)
# 计算损失
loss = criterion(outputs,labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
_,predicted = torch.max(outputs,1)
train_total_loss += loss.item()
train_total_correct += torch.sum(predicted == labels).item()
# logging.debug(f'Train: Loss:{train_total_loss:.4f}| Accuracy:{100*train_total_correct/len(train_data_set):.2f}%')
print(f'Train: Loss:{train_total_loss:.4f}| Accuracy:{100*train_total_correct/len(train_data_set):.2f}%')
writer_1.add_scalar(tag=f'loss_{ModelName}', scalar_value=train_total_loss, global_step=epoch + 1)
writer_1.add_scalar(tag=f'acc(%)_{ModelName}', scalar_value=100*train_total_correct/len(train_data_set), global_step=epoch + 1)
scheduler.step()
# 开始测试
myModel.eval()
with torch.no_grad():
for data in test_data_loader:
images,labels = data
images = images.to(device)
labels = labels.to(device)
outputs = myModel(images)
loss = criterion(outputs,labels)
_, predicted = torch.max(outputs.data, 1)
test_total_correct += torch.sum(predicted == labels).item()
test_total_loss += loss.item()
# logging.debug(f'Test: Loss:{test_total_loss:.4f}| Accuracy:{100*test_total_correct/len(test_data_set):.2f}%')
print(f'Test: Loss:{test_total_loss:.4f}| Accuracy:{100*test_total_correct/len(test_data_set):.2f}%')
writer_2.add_scalar(tag=f'loss_{ModelName}', scalar_value=test_total_loss, global_step=epoch + 1)
writer_2.add_scalar(tag=f'acc(%)_{ModelName}', scalar_value=100*test_total_correct/len(test_data_set), global_step=epoch + 1)
writer.close()
if not os.path.exists(f'saved_model/{ModelName}/'):
os.mkdir(f'saved_model/{ModelName}/')
torch.save(myModel.state_dict(), f'saved_model/{ModelName}/model.pth')
个人感觉在多次残差链接、卷积和最大池化后再加个平均池化的话效果会好很多,个人认为是卷积可能引入噪声,而最大池化可能会放大噪声,平均池化可以一定程度上抑制噪声的放大。
4.训练效果展示
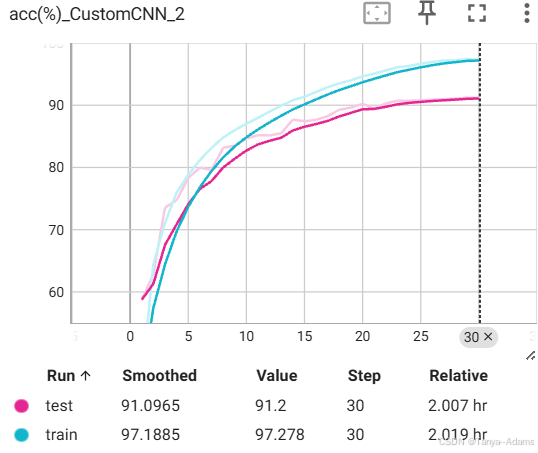
测试集和验证集准确率(我训练时名字还不叫MyModel):验证集准确率91%,测试集准确率97%
测试集和验证集损失下降情况:
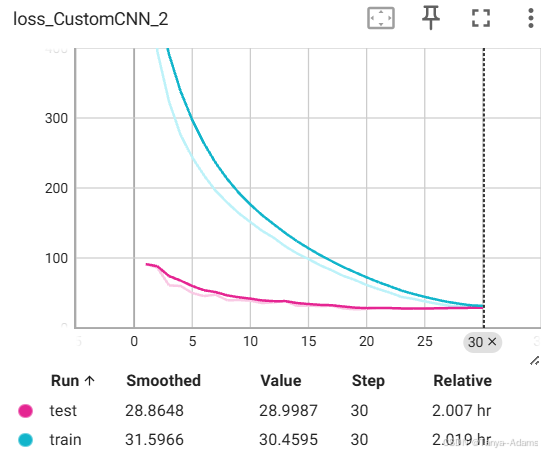
可以看到到第30步时就已经有些过拟合的苗头了,再训练多了真的会严重过拟合,所以三十步左右我认为就是这个模型的训练极限了。
你也可以验证一下,当你训练完成后,tensorboard日志文件都存会放在logs文件夹里,你可以使用以下命令来查看训练过程中的准确率和损失:
tensorboard --logdir logs\MyModel --host 127.0.0.1 --port 6006
5.源码下载链接
项目会提供下载链接,我训练的权重也会开源:
源码文件链接:百度网盘 提取码: nvpd
训练权重分享:百度网盘 提取码: javb


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









