






本文是针对负样本采样过程中可能采样到假阴性样本的问题提出的相关方法,现有的方法通常侧重于保持具有高梯度的难负样本进行训练,导致优先选择假负样本。假阴性噪声可能导致模型的过拟合和较差的泛化性。为了解决这个问题,本文提出了一种增益调整动态负采样方法 。
由于常用方法存在假负例的情况,因此本文希望找到一种更可靠的衡量方式来找到负样本。本节设计了一个曝光感知函数来衡量曝光数据中的负信号,对于一个用户u,以及他交互的商品数据集合Δu,曝光数据中未交互商品 为真正负样本的概率为:
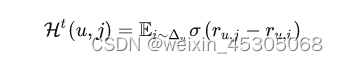
设计了一个增益感知函数来计算商品j是一个真正的负样本的概率,如下式,其中α是使训练稳定的平滑超参数,ϵ防止分母为0。
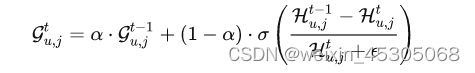
在训练阶段选择具有较高 G 的候选负样本作为负样本
分组优化
以前的工作通常优化成对的基于边际的损失,将高分分配给正实例,将低分分配给负实例。考虑到一下两方面,作者提出分组损失。
作者选择的base是GMF,在原来的loss上引入正负样本组交叉loss:

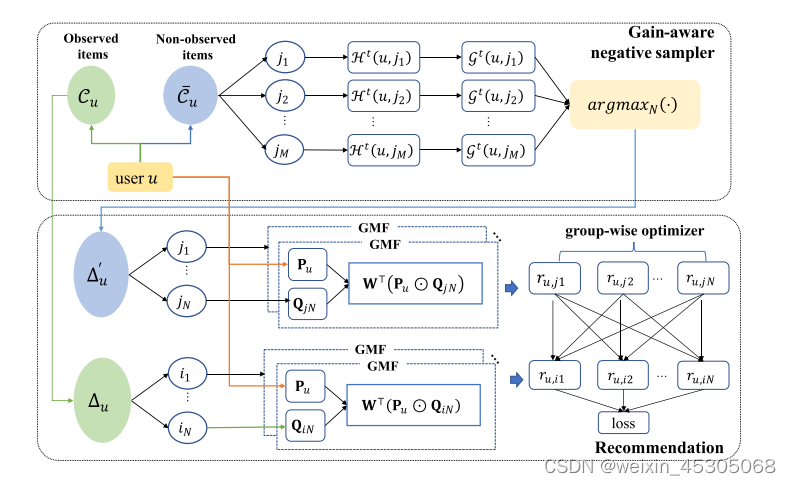
- 对于用户u,将观察数据中的交互商品集合Cu中采样N次得到Δu作为用户u的正样本组;将未观察数据中的商品集合C¯u中采样N次得到Δu′作为用户u的负样本组。
- 由于负采样的空间非常巨大或未知,对于第 次迭代中的每个用户,首先通过随机采样构造一个子集δ∈{j1,...,jM}⊂C¯u
- 然后通过GDNS从中采样topN个构成Δu′
- 然后构造损失















 2947
2947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









