 awk命令详解与实战应用
awk命令详解与实战应用




 本文详细介绍了awk的工作原理,包括其逐行处理、字段分割及内建变量的使用,如$0、NR、$n、FS、OFS、NF、RS等。awk命令格式和常见操作如模式匹配、条件判断也进行了阐述。通过实例展示了awk在处理行内容、统计、字段筛选等方面的应用。同时,简单提及了date命令的日期格式化输出。文章适合对awk感兴趣的Linux系统管理员和程序员阅读。
本文详细介绍了awk的工作原理,包括其逐行处理、字段分割及内建变量的使用,如$0、NR、$n、FS、OFS、NF、RS等。awk命令格式和常见操作如模式匹配、条件判断也进行了阐述。通过实例展示了awk在处理行内容、统计、字段筛选等方面的应用。同时,简单提及了date命令的日期格式化输出。文章适合对awk感兴趣的Linux系统管理员和程序员阅读。
目录
1、awk工作原理
- 逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
- awk倾向于将一行分成多个"字段"然后再进行处理。
- awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。
- 使用awk命令的过程中,可以使用逻辑操作符"&&"表示"与"、"|"表示"或"、"!"表示"非",还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
2、awk命令格式
awk 选项 '模式或条件 {操作}' 文件1 文件2 ....
或者
awk -f 脚本文件 文件1 文件2 .....
3、awk常见的内建变量(可以直接使用)
| 内建变量 | 作用 |
| $0 | 当前处理的行的整行内容 |
| NR | 当前处理的行的行号(序数) |
| $n | 当前处理行的第n个字段(第n列) |
| FS | 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同 |
| OFS | 输出内容的列分隔符 |
| NF | 当前处理的行的字段个数 $NF代表最后一个字段 |
| FILENAME | 被处理的文件名 |
| RS | 行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录, 而awk一次仅读入一条记录进行处理。预设值是'\n ' |
3.1$0 当前处理的行的整行内容

3.2NR 处理指定行内容
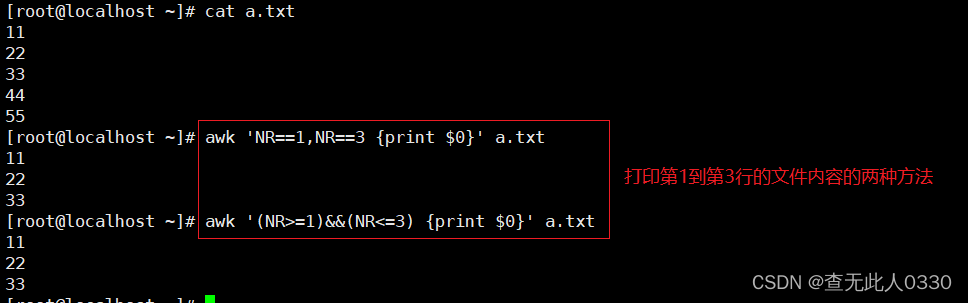
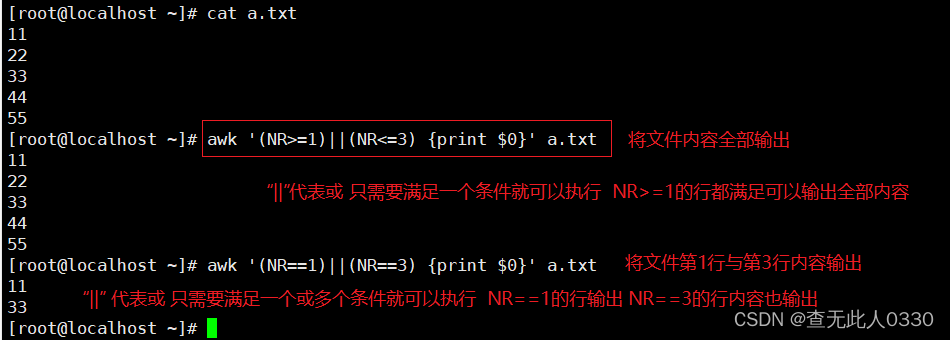
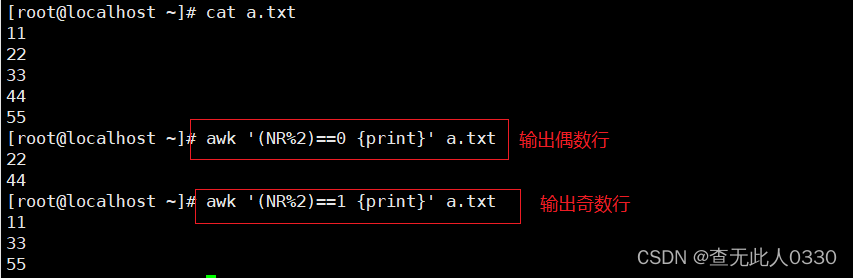
3.2.1 使用数字处理行内容
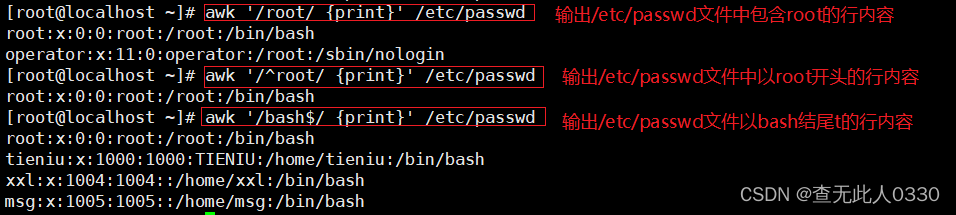
3.2.2使用字符串处理行内容
3.2.3打印行号
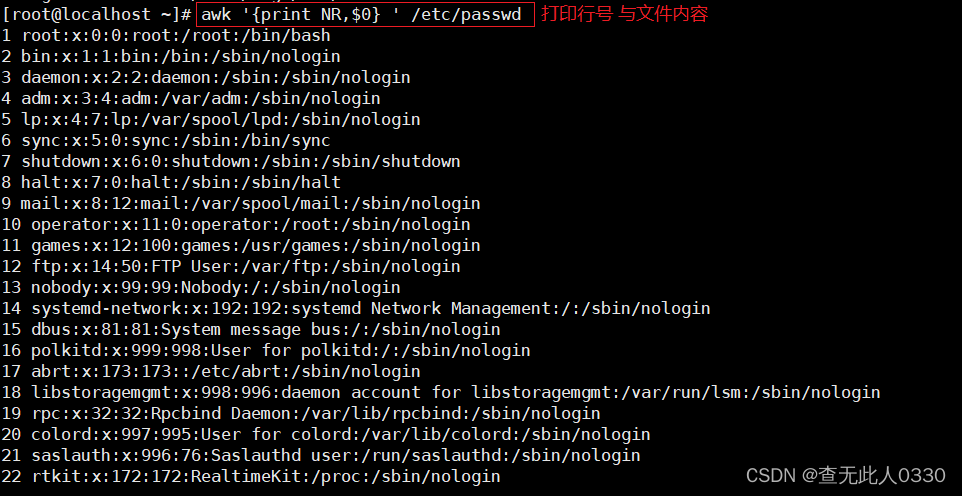
使用BEGIN输出包含指定字符的行并统计有多少行
awk 'BEGIN{ ..};{..} ;END{.. .}' 文件
- BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作;
- awk再处理指定的文本,之后再执行END模式中指定的动作;
- END{ } 语句块中,往往会放入打印结果等语句。
awk 'BEGIN{x=0};/\/bash$/{x++};END {print x}' /etc/passwd
统计以/bin/bash 结尾的行数,等同于grep -c "/bash$"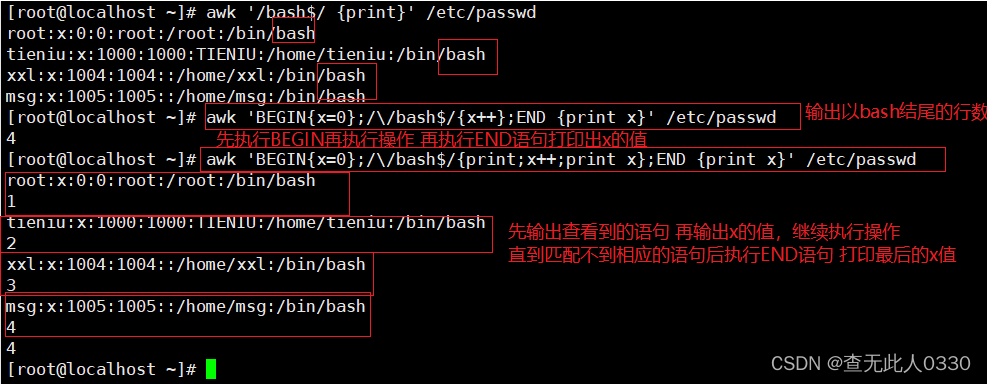
以:为行分隔符,进行统计行号
![]()
3.3 $n 当前处理行的第n个字段

$n ~ "字符串" 代表打印出第n个字段中包含某字符的行
$n =="字符串" 代表打印出第n个字段中为某字符串的行
$n != "字符串" 代表打印出第n个字段中不为某字符的串行示例:
#打印出第一字段中包含root的行中的第一列于第3列
awk -F: '$1~"root"{print $1,$3} ' /etc/passwd![]()
3.4 FS(-F)列分割符,指定每行文本的字段分隔符
awk -F 分隔符 '{操作}'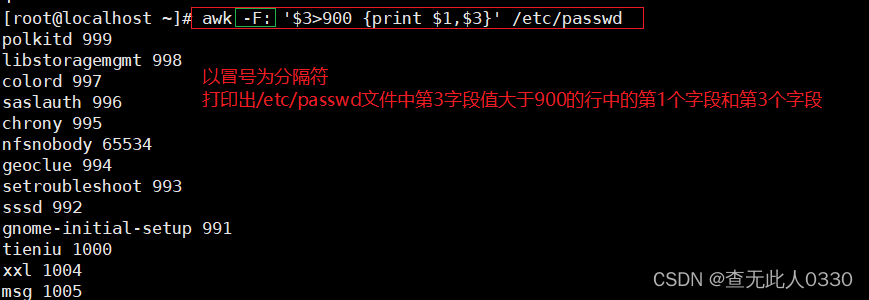
与!一起使用

与if语句或者while或三目运算符等一起使用时需要再嵌套一个大括号{ }
三元运算符:
(条件表达式)?(A表达式或者值):(B表达式或者值)
条件表达式成立为真时会取:号前面的A的值
条件表达式不成立为假时会取:号后面的B的值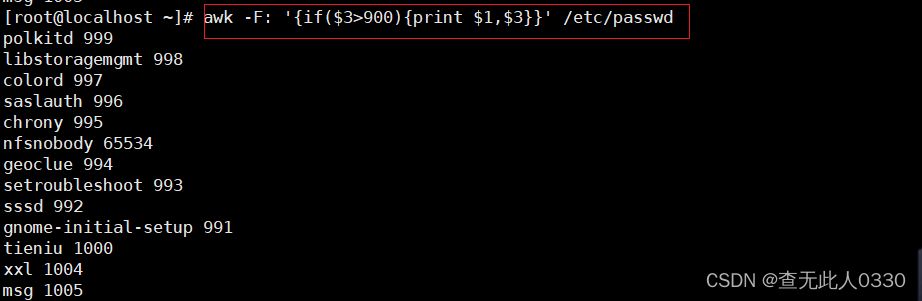
三元运算符
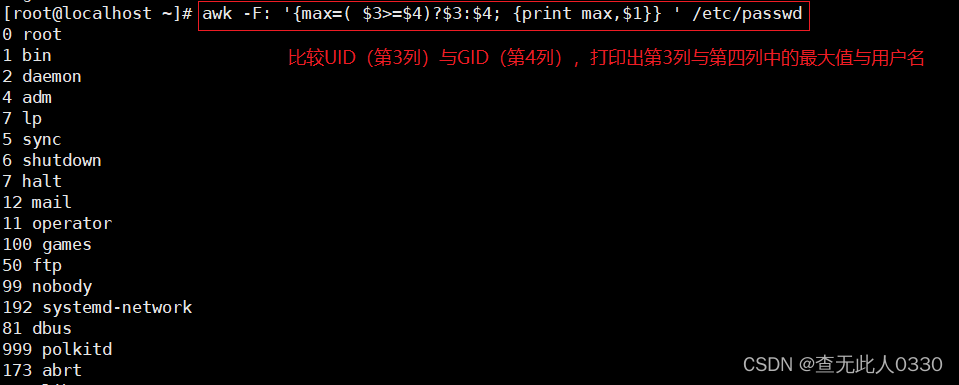
3.5 OFS输出内容的列分隔符
将空格换为“|”
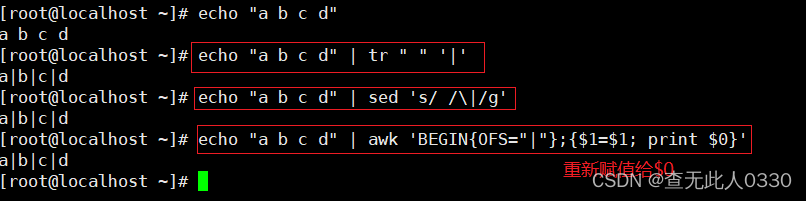
3.6 NF当前处理的行的字段个数
打印第一个字段与最后一个字段
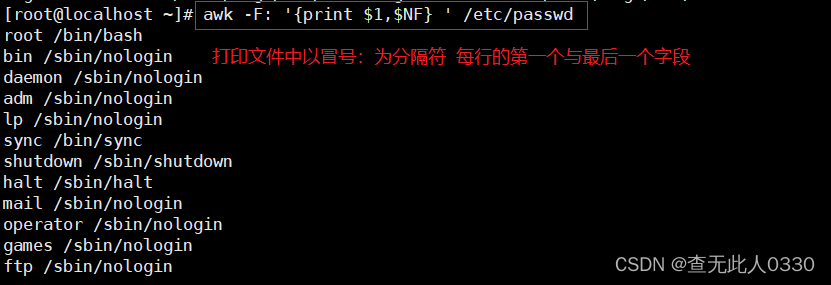

3.7 RS行分隔符
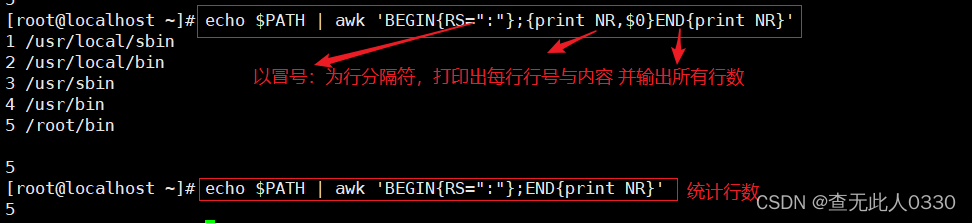
4、awk实例:
查看内存使用率

查看CPU空闲率
top -b -n 1 只会输出一次top的结果 不会进行刷新


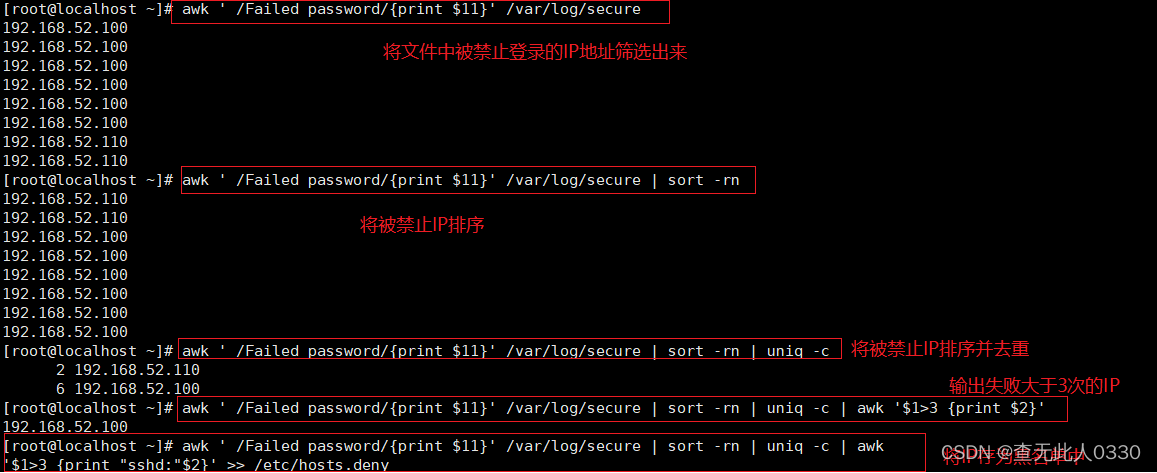
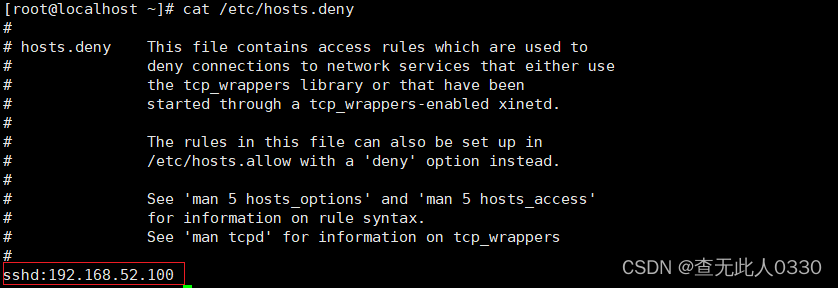
通过脚本分析/var/log/secure查看哪些主机在暴力破解本服务,如果统计出密码验证失败超过三次就把IP加入到黑名单中/etc/hosts deny
5、date命令
![]()
以数字形式输出
[root@localhost ~]# date +"%F"
2022-04-24![]()
以年月日的形式输出
[root@localhost ~]# date +"%Y%m%d"
20220424![]()
输出当月的第一天
[root@localhost ~]# date +"%Y%m01"
20220401
![]()
输出下一个月的第一天
[root@localhost ~]# date -d "$(date -d "1 month" +"%Y%m01")"
2022年 05月 01日 星期日 00:00:00 CST
[root@localhost ~]# date -d "$(date -d "1 month" +"%Y%m01")" +"%Y%m%d"
20220501

输出本月的最后一天
[root@localhost ~]# date -d "$(date -d "1 month" +"%Y%m01") - 1 day" +"%Y%m%d"
20220430![]()
输出上个月的倒数第3天
[root@localhost ~]# date -d "$(date +"%Y%m01") - 3 day" +"%Y%m%d"
20220329
输出服务器重启时间
[root@localhost ~]# date -d "$(awk -F. '{print $1}' /proc/uptime) second ago" +"%Y%m%d %H;%M;%S"
20220424 14;27;32
![]()

















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









