






文章目录
〇. 前言
本文将系统的介绍Java面试高频考点:HashMap。内容包括但不限于
- HashMap 实现原理
- HashMap 扩容机制
- HashMap 源码解析
- HashMap 高频面试题
注意:若未经特殊说明,所有的内容将基于JDK1.8进行分析解释。
一. 实现原理
HashMap 的数据结构:散列表(哈希表),即 数组 + 链表 / 红黑树。
- 向HashMap中put元素时,利用key.hashcode()计算 数组下标;
- 根据下标存储时,若key已存在,则 覆盖 掉旧key;
- 当 某条链表长度 >= 8 且 数组长度 >= 64 时,该链表转化为红黑树。
- 获取数据时,也是通过key.hashcode()计算数组下标,完成定位查找。
注意:HashMap在 JDK1.7 和 JDK1.8 中的区别。
- JDK1.8处理哈希冲突的方式正如上面所描述的,拉链 + 红黑树;并且在HashMap 扩容resize() / 删除元素remove() 时,红黑树会进行 拆分 / 删除,若操作后 结点数 <= 6,则再次退化成链表。
- JDK1.7的处理方式非常简单,完全使用拉链法处理。
正如ArrayList一样,HashMap的核心原理也要从添加元素的方法入手,探究 put方法的具体流程,搞清楚HashMap具体的存储逻辑(扩容机制)。
二. 源码分析(存储逻辑 与 扩容机制)
首先我们要了解HashMap如何添加元素的,元素增多时的存储逻辑如何;当达成什么条件时,会触发HashMap的扩容机制。
1.HashMap 的 核心成员变量
// 数组的 默认初始容量 == 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 数组的 默认加载因子 == 0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 【关键】存储具体 键值对 的数组
transient Node<K,V>[] table;
// 键值对数量
transient int size;
// 键值对类型的实现
static class Node<K,V> implements Map.Entry<K,V> {
finalint hash; // 用于数组定位
// ⭐下标位置 i = (数组容量 - 1) & hash
// & 按位与(全1则1,有0则0)
final K key; // 键
V value; // 值
Node<K,V> next; // 下一个元素(拉链)
// 其余代码已省去...
}
// hash的计算:扰动算法 —— 确保key.hashCode()只要有一位不同,结果就不同;这样hash更均匀,减少哈希碰撞!
// ⭐ ^ 异或(同0异1)
// >>> 无符号右移
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
⭐ 扩容阈值(threshold) == 数组容量 * 加载因子
举例说明:HashMap为初始容量16,加载因子保持0.75,那么当 元素数量 == 12(16 * 0.75),触发扩容!
- 加载因子 增大,空间利用率高,但哈希碰撞几率增加,存取效率低;
- 加载因子 减小,哈希碰撞减少,元素分布更均匀,但空间利用率低。
所以经测试,默认加载因子 == 0.75 最平衡 的。
2.了解 HashMap 的 默认构造方法
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
// all other fields defaulted
}
可以看到,默认构造只初始化了 加载因子(0.75),其他的成员变量依旧 保持默认(包括 键值对数组table)。
3.⭐HashMap的 存储逻辑:put方法 的执行流程
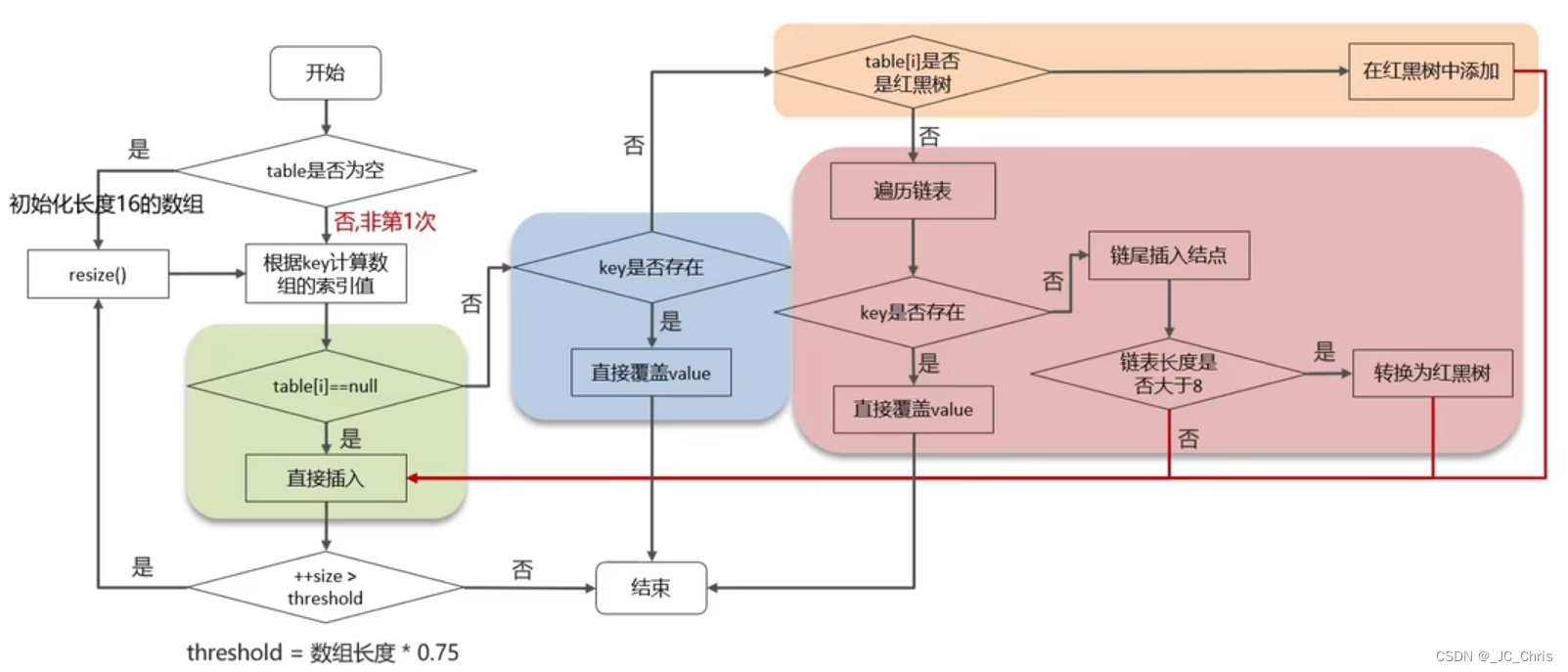
【STEP 01】根据 key.hashcode() 计算 数组索引。
针对【首次添加】的特殊情况:键值对数组table 进行 resize(),初始化长度为16,再进行 STEP 01 的计算操作。
【STEP 02 / 绿】判断索引位置是否为NULL,即没有 哈希冲突。
若 table[ i ] == NULL,直接新建结点并 插入 即可;
不满足则进入【STEP 03】。
【STEP 03 / 蓝】判断索引位置是否与 待插入元素 同key。
如果 table[ i ] 的 首个元素 就与 待插入元素同key,直接覆盖;
不满足则需要向下方的DS(链表 / 红黑树)中继续寻找。
【STEP 04 / 橙】判断索引位置是否为 红黑树。
如果 table[ i ] 位置是一颗红黑树,直接执行红黑树的 插入 操作即可,平均时间复杂度稳定在 O(log n);
不满足则说明一定是链表结构,进入【STEP 05】。
【STEP 05 / 红】遍历 链表(插入 与 转型 策略)。
首先需要遍历链表,如果链表中存在 “同key” 元素,直接覆盖;
不存在则向链表队尾 插入 新元素,并判断 链表长度 >= 8?
满足则执行 treeifyBin方法(内部会判断数组长度 >= 64?),转红黑树。
【STEP 06】扩容 resize()
我们可以看到,在STEP 02 / 04 / 05 中都有新的键值对元素 插入;
每次插入完成后,都要判断 ++size > threshold(数组容量 * 0.75);
满足则触发扩容机制,执行 resize();否则直接结束存储流程。
特别的,STEP 01 中 首次添加元素 时也会执行 resize()。
4.⭐HashMap的 扩容机制
当HashMap中存放 键值对 的数组table进行扩容之后,首要任务是将元素全部 重新定位。
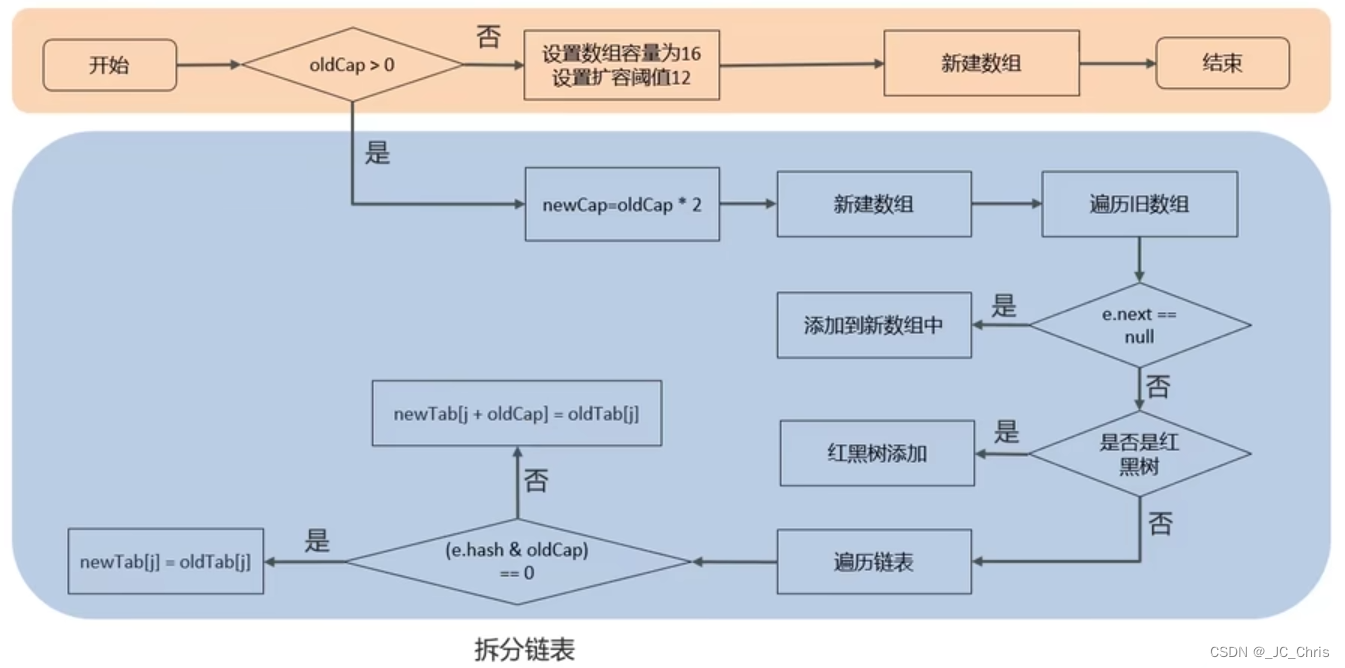
< CASE 01 > 首次 添加元素
设置 数组容量为 16,并添加首个元素即可。
回顾:下标位置 i = hash & (数组容量 - 1)
< CASE 02> 达 阈值 扩容,即 size = 数组容量 * 0.75
【STEP 01】创建 新数组
创建一个新数组,容量 是旧数组的 两倍;
【STEP 02】遍历 旧数组
遍历旧数组,把元素依次取出并 重新定位 到新数组。
不同类型DS 使用不同的策略,判断顺序:STEP 03 → 04 → 05。
【STEP 03】索引位置 是 单个元素
新下标位置 i = hash & (新数组容量 - 1)
单个元素 填入 新下标位置 即可。
【STEP 04】索引位置 是 红黑树
// 红黑树将被【一分为二】
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// split方法的参数
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit)
变量解释:
- j:旧索引
- newTab:新数组
- oldCap:旧数组容量
具体的分割策略如下:
① 准备 两个链表,并且对应 新数组位置:lo → j,hi → j + oldCap;
② 依次 遍历旧红黑树 中键值对元素e;
③ ⭐计算并判断 e.hash & oldCap == 0? 满足链入lo,不满足链入hi;
④ ⭐分别判断 lo和hi的元素数量 <= 6?满足则 红黑树退化为链表,不满足则 成树;
⑤ 将 lo 和 hi 分别添加到对应的 新数组位置 即可。
【STEP 05】索引位置 是 链表
链表的核心思路也是【一分为二】,与红黑树很相似,无需处理红黑树退化。
具体的分割策略如下:
① 准备 两个链表,并且对应 新数组位置:lo → j,hi → j + oldCap;
② 依次 遍历旧链表 中键值对元素e;
③ ⭐计算并判断 e.hash & oldCap == 0? 满足链入lo,不满足链入hi;
④ 将 lo 和 hi 分别添加到对应的 新数组位置 即可。
三. 高频面试题
1. HashMap 的 寻址算法 ?
在介绍HashMap核心成员变量的时候提到过该问题,在此总结。
寻址,即 由 key.hashcode() 确定 数组下标位置 的过程。
【STEP 01】扰动算法:hash = hashcode ^ ( hashcode >>> 16 )
hashcode只要 一位 不同,hash就不同;
这样hash的分布 更均匀,后续 哈希碰撞 的几率会减小。
【STEP 02】数组定位:下标 = hash & ( capacity - 1 )
类似操作也可以使用 取模% 运算,capacity % hash;
但是当 capacity 为 2的倍数 时,按位与& 就能够 代替 模运算%,效率更高!
2. 为什么 HashMap 的 数组容量 要保持 2^n ?
首先,回顾一下 2^n 的二进制形式:
2:10 → 2-1:1
4:100 → 4-1:11
8:1000 → 8-1:111
16:10000 → 16-1:1111
…(这与面试题息息相关)
(1)该数字特征对于 【利用hash计算下标位置】 的过程有 两点加成,即 “ 寻址算法 STEP 02 ”:
- 效率层面:若capacity为2^n,则可以使用 按位与& 代替 取模运算%,提升效率。
- 空间层面⭐:若capacity为2^n,则 capacity-1 的二进制是 全1状态,那么 hash & (capacity-1) 就可以 完整的 表示 capacity种 结果,对应全部的索引。(配合 “扰动算法”,元素会 更加均匀的 分布在数组table中)
举个例子:
(1)当前数组容量capacity为16,数组下标0~15,capacity-1的二进制为1111;
(2)由于 按位与&运算 的特点(全1则1,有0则0),只有hash的二进制 后4位 起到定位作用,所以 hash & ( capacity - 1 ) 可能的结果 有且仅有16种,空间 全面利用!
(补充)并且由于 “扰动” 后的hash是 均匀的,故hash的二进制 后4位 也是相对均匀的;所以分布到 16个下标 中也是均匀的,空间 平均利用!
(反例)假设数组容量capacity为15,capacity-1的二进制为1110;显然,只有 3位 二进制位 起到定位作用,hash & ( capacity - 1 ) 可能的结果仅有8种,意味着有7个索引位都将 失去意义,空间利用率极大削减!
如果理解了上面的案例,那么剩余的内容也很好理解。
(2)该数字特征对于 【扩容后 链表 / 红黑树 的拆分】 的过程有 一点加成,即 “ 扩容机制 STEP 04 / 05 ”:
- 空间分布⭐:若capacity为2^n,则 capacity 的二进制是 10…,这样确保 e.hash & oldCap 的结果只有 0 / 其他,对应分割成 两个 链表。(配合 “扰动算法”,元素会 更加均匀的 分割到 lo和hi 中)
举个例子:
(1)当前数组容量capacity为16,capacity的二进制为10000;
(2)由于 按位与&运算 的特点(全1则1,有0则0),只有hash的二进制 第5位 起到分割作用,所以 e.hash & oldCap 可能的结果 有且仅有0 / 16,分别归于 lo 和 hi 两个链表!
(补充)并且由于 “扰动” 后的hash是 均匀的,故hash的二进制 第5位 也是相对均匀的;所以分布到 两个链表 中也是均匀的,空间 平均利用!
(反例)假设数组容量capacity为15,capacity的二进制为1111;此时,有4个二进制位 起到定位作用,e.hash & oldCap 可能的结果达到16种,意味着用 e.hash & oldCap == 0 分割会导致 lo 链特别短、hi 链 特别长,空间分布极不均匀!
2. JDK1.7中的 HashMap “多线程死循环” 问题?
(1)JDK1.7会出现“多线程死循环”问题,是因为在JDK1.7中,HashMap的所有 链表插入操作 全部都使用了 头插法;这样做的本意是降低插入成本,时间复杂度维持在 O(1)。
(2)而在JDK1.8中,HashMap的所有 链表插入操作 全部转用 尾插法,避免了“多线程死循环”问题;同时,JDK1.8的HashMap引入 红黑树,无需担心元素过多导致的尾插法开销过大的问题。
接下来具体分析一下:为什么 头插法 是导致 “多线程死循环” 的罪魁祸首?
① 当HashMap进行 【扩容】 的时候,旧数组 状态如下:
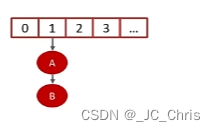
② 转移链表元素 时涉及 重新拉链(头插法),所以预期的 新数组 状态:
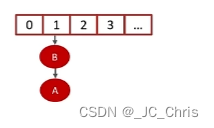
在这个过程中,遍历旧链表的时候,会准备两个变量:e 和 next 。
准备状态时:
- e 指向当前需要迁移的变量,假设是A
- next 指向下一个迁移的变量,是B
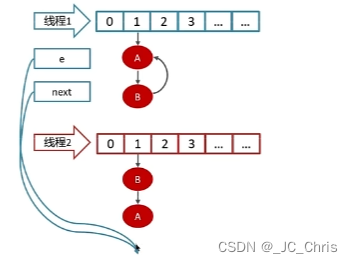
③ ⭐多线程 状态下,会出现特殊情况:
当 线程1 准备扩容时,它创建了两个指针变量 e 和 next,分别指向了 A 和 B 元素;
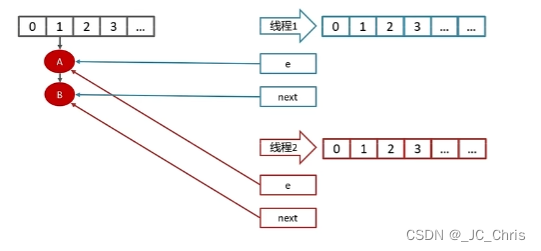
但是此时,线程2 开启了相同的扩容操作,并且 优先抢到了时间片,头插迁移;
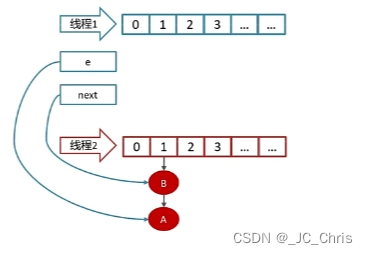
线程2 的 迁移完成。
线程1 继续执行,先迁移 指针 e 位置的元素,即 A;
随后调整 e 和 next,e 指向下一个 元素 B。
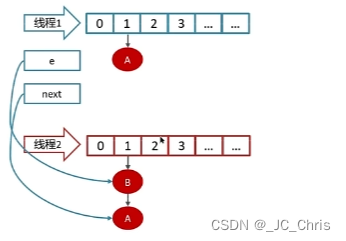
问题出现了 ❗ ❗ 此时 线程1 的 next 预期中应该已为 NULL;
但是正是由于 线程2 优先头插,把 元素B 最终的 next 又改为了 元素A;
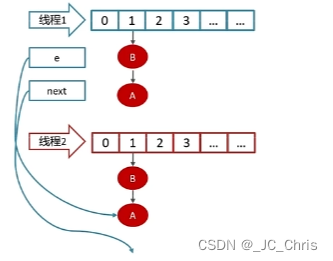
所以,最后对于 线程1 来说,灾难发生了:
当前 指针e 插入 元素B 之后,还要再次 头插 元素A,形成了 A → B → A 的死循环。















 171
171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









