







一、JDK1.8
1.1 Lambda 表达式
Lambda 表达式是1.8最实用的一个新特性,也是最常用的,其干净利落的语法使得用起来就停不下来。可以替换为lambda表达式的必须是函数式接口,函数式接口是只有一个抽象方法的接口,用作 Lambda 表达式的类型。使用@FunctionalInterface注解修饰的类,编译器会检测该类是否只有一个抽象方法或接口,否则,会报错。可以有多个默认方法,静态方法。
lambda表达式中无法操作修改外部变量,即不支持i++,这是java对闭包支持的不够全面
Lamdba表达式无法使用return(return;不能return xxx;)和break结束循环,return;和continue的效果类似。
1.1.1 使用lambda移除集合元素
剔除集合中不符合条件的元素是最基础也是最常用的操作,普通for循环正向remove会有问题,虽然不报错,但是不会剔除干净,因为集合的下表在动态变化,如果直接使用增强for,则会直接抛出ConcurrentModificationException异常,可以使用迭代器或者倒序遍历删除的方式,java8结合lambda可以一行代码就搞定
list.removeIf(s -> s.equals("1"));
1.2 Stream 流
Stream流并不是常说的I/O流,更像具有迭代器特性的集合工具类。
IO 流是内存和硬盘之间的传输,Stream 流则都在内存中对 集合中元素数据的操作.
stream是对集合对象功能的增强,它可以对集合对象进行各种非常便利、高效的聚合操作,或者大批量数据操作。Stream 会隐式地在内部进行遍历,做出相应的数据转换。
1.2.1 获取流
单列集合获取流
Collection<String> c = new ArrayList<>();
Stream<String> stream1 = c.stream();
ArrayList<String> list = new ArrayList<>();
Stream<String> stream2 = list.stream();
HashSet<String> set = new HashSet<>();
Stream<String> stream3 = set.stream();
双列集合获取流
双列集合没有Stream 流,只能建集和值集分开获取。
HashMap<String, Integer> map = new HashMap<>();
// 1. keySet 键集
map.keySet().stream();
// 2. values 值集
map.values().stream();
// 3. entrySet 键值对集合
map.entrySet().stream();
数组获取流
使用 Stream 类定义的 of 静态方法
Stream<Integer> stream1 = Stream.of(10, 20, 30, 40, 50);
int[] arr = new int[]{ 10, 20, 30, 40, 50 };
Stream<int[]> stream2 = Stream.of(arr);
1.2.2 使用
forEach
stream.forEach(s -> System.out.println(s));
stream.forEach(System.out::println);
//map集合使用foreach
hashMap.forEach((k, v) -> {
});
filter
filter接受一个函数作为参数,该函数用Lambda表达式表示。
//new 1
List<PersonModel> collect = data
.stream()
.filter(person -> {
if ("男".equals(person.getSex()) && person.getAge() < 20) {
return true;
}
return false;
})
.collect(toList());
//new 2
List<PersonModel> collect1 = data
.stream()
.filter(person -> ("男".equals(person.getSex()) && person.getAge() < 20))
.collect(toList());
Stream<String> stream = Stream.of("张无忌", "张学友", "刘德华", "张三", "张三丰");
stream.filter((name) -> {
return name.startsWith("张");
})
.filter(name -> name.length() > 2)
.forEach(System.out::println);
count
long count = stream.filter((name) -> { return name.startsWith("张"); }).filter(name -> name.length() > 2).count();
limit
和MySQL是一样的作用。
stream.filter((name) -> { return name.startsWith("k"); }).filter(name -> name.length() > 2).limit(2).forEach(System.out::println);
skip
跳过前几个,返回其他的。
stream.skip(2) .forEach(System.out::println);
map(映射 )
将流中的每一个元素映射到 Function 函数式接口参数中
stream.map(s -> Integer.parseInt(s)).forEach(System.out::println);
//new 1
List<String> collect = data.stream().map(person -> person.getName()).collect(toList());//省略了returen和{}
//new 2
List<String> collect1 = data.stream().map(PersonModel::getName).collect(toList());
//根据姓名创建对象;
stream.map((name) -> new Person(name));
stream.map(Person::new);
FlatMap
map和flat返回值不同
Map 每个输入元素,都按照规则转换成为另外一个元素。还有一些场景,是一对多映射关系的,这时需要 flatMap。
Map一对一,Flatmap一对多,map和flatMap的方法声明是不一样的
Stream map(Function mapper); Stream flatMap(Function> mapper);
map和flatMap的区别: flatMap的可以处理更深层次的数据,入参为多个list,结果可以返回为一个list,而map是一对一的,入参是多个list,结果返回必须是多个list。也就是说如果入参都是对象,那么flatMap可以操作对象里面的对象,而map只能操作第一层。flatMap与map的区别在于 flatMap是将一个流中的每个值都转成一个个流,然后再将这些流扁平化成为一个流 ,相当于一层层剥开再进行聚合,假如要获取班级里所有学生的成绩,这个可以直接使用map获取到成绩的聚合集,但是如果要获取一个学校的所有班级的学生的成绩,map就没法直接拿到结果,还得配合传统遍历,使用flatMap可以一层层剥开,再结合map获取,最后再聚合产生结果集。
//返回类型不一样
List<String> collect = data.stream().flatMap(person -> Arrays.stream(person.getEname().split("-"))).collect(toList());
System.out.println("collect:"+collect);
List<Stream<String>> collect1 = data.stream().map(person -> Arrays.stream(person.getEname().split("-"))).collect(toList());
System.out.println("collect1:"+collect1);
//用map实现
List<String> collect2 = data.stream()
.map(person -> person.getEname().split("-"))
.flatMap(Arrays::stream).collect(toList());
System.out.println("collect2:"+collect2);
//另一种方式
List<String> collect3 = data.stream()
.map(person -> person.getEname().split("-"))
.flatMap(str -> Arrays.asList(str).stream()).collect(toList());
System.out.println("collect3:"+collect3);
concat
拼接组合 :
Stream<String> stream1 = Stream.of("11", "22",);
Stream<String> stream2 = Stream.of("33", "44");
//Stream 类的静态方法 concat
Stream<String> stream = Stream.concat(stream1, stream2);
Reduce
类似递归,数字(字符串)累加
//累加,初始化值是 10
Integer reduce = Stream.of(1, 2, 3, 4)
.reduce(10, (count, item) -> {
System.out.println("count:" + count);
System.out.println("item:" + item);
return count + item;
}); //20
Integer reduce1 = Stream.of(1, 2, 3, 4).reduce(0, (x, y) -> x + y);//10
String reduce2 = Stream.of("1", "2", "3").reduce("0", (x, y) -> (x + "," + y));//0,1,2,3
max和min
List<Student> students = new ArrayList<>();
students.add(new Student("路人甲", 22, 175));
students.add(new Student("路人乙", 40, 180));
students.add(new Student("路人丙", 50, 185));
Optional<Student> max = students.stream().max(Comparator.comparing(stu -> stu.getAge()));
Optional<Student> min = students.stream().min(Comparator.comparing(stu -> stu.getAge()));
if (max.isPresent()) {
System.out.println(max.get());
}
if (min.isPresent()) {
System.out.println(min.get());
}
其他
还有一些不太常用的,如anyMatch/allMatch/noneMatch(匹配)、sorted(排序)、distinct(去重)、findAny(查找,类似与过滤)等。
并发流
多线程处理集合中的数据,特点:顺序不一致
输入流的大小并不是决定并行化是否会带来速度提升的唯一因素,性能还会受到编写代码的方式和核的数量的影响。影响性能的五要素是:数据大小、源数据结构、值是否装箱、可用的CPU核数量,以及处理每个元素所花的时间。
Stream流转换为并发流 : paralell
stream.parallel().forEach(System.out::println);
集合对象直接获取并发流 : paralellStream
list.parallelStream().forEach(System.out::println);
//做个基本测试,数字的大小对结果会有影响。
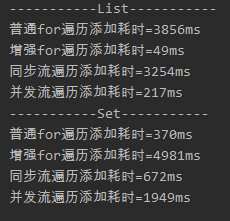
调试
list.map.fiter.map.xx 为链式调用,最终调用collect(xx)返回结果,分惰性求值和及早求值
返回值是 Stream是惰性求值,是另一个值或为空,则是及早求值。使用这些操作的理想方式就是形成一个惰性求值的链,最后用一个及早求值的操作返回想要的结果。
通过peek可以查看每个值,同时能继续操作流
//peek打印出遍历的每个per
data.stream().map(per -> per.getName()).peek(p -> {
System.out.println(p);
}).collect(toList());
collect
collect在流中生成列表,map,等常用的数据结构,是高级集合类中的神器。
//toList
List<String> collect = data.stream().map(PersonModel::getName).collect(Collectors.toList());//collectors可省略
//toSet
Set<String> collect = data.stream().map(PersonModel::getName).collect(Collectors.toSet());
//toMap
Map<String, Integer> collect = data.stream().collect(Collectors.toMap(PersonModel::getName, PersonModel::getAge));
data.stream().collect(Collectors.toMap(per -> per.getName(), value -> {return value + "1";}));
// 指定类型
List<PersonModel> data = Data.getData();
TreeSet<PersonModel> collect = data.stream().collect(Collectors.toCollection(TreeSet::new));
//正反分组,接收一个Predicate函数式接口。
Map<Boolean, List<Student>> listMap = students.stream().collect(Collectors.partitioningBy(student -> student.getSex().contains("man")));
//分组,下面是分为正反两组,也可以按照字段直接分组,适用与主子结构体的封装。
Map<Boolean, List<PersonModel>> collect = data.stream().collect(Collectors.groupingBy(per -> "男".equals(per.getSex())));
//最大值
students.stream.collect(maxBy(comparing(s -> s.getAge()))).orElseGet(Student::new);
//平均值
Double collect = students.stream().collect(averagingInt(Student::getAge));
//字符串拼接
//joining接收三个参数,第一个是分隔符,第二个是前缀符,第三个是结束符。也可以不传入参数,这样就是直接拼接。
String collect = data.stream().map(personModel -> personModel.getName()).collect(Collectors.joining(",", "{", "}"));
//自定义
List<String> collect = Stream.of("1", "2", "3").collect(Collectors.reducing(new ArrayList<String>(), x -> Arrays.asList(x), (y, z) -> {y.addAll(z);return y;}));
//to arr[ ]
Object[] objects = list.stream().toArray();
//解决泛型数组问题,传递数组的构造引用
String[] strings = list.stream().toArray(String[]::new);
//数组转集合
List<String> list = Stream.of(strings).collect(Collectors.toList());
注意:从Array转换为stream有两种办法,Stream.of()和Arrays.stream();在面对引用类型时,这两种方法都没有问题,而面对primitive类型的数组时,前一种方式却不能得到期望的结果,为了避免这个坑,建议使用Arrays.stream(xxx)方式来处理array到stream的转换。
1.3 时间类
1.8之前java的时间处理API都在 java.util.Date包,而且处理起来比较麻烦,而且类似SimpleDateFormat的坑让人深受其害。
新API基于ISO标准日历系统,java.time包下的所有类都是不可变类型而且线程安全。
1.3.1 LocalDate
只有年月日,不包含具体时间
获取今天的日期
// 只获取日期,格式2019-10-08
LocalDate today = LocalDate.now();
//2019
int year = today.getYear();
//10
int month = today.getMonthValue();
//8
int day = today.getDayOfMonth();
获取指定日期
//2011-05-22
LocalDate date = LocalDate.of(2011,5,22);
获取日期前后的日期
可以直接跳年或者月日,也可以指定单位跳,plus就是跳到将来,minus就是跳到过去
LocalDate today = LocalDate.now();
today.plusDays(1);
today.plusMonths(1);
today.plusYears(1);
LocalDate plus = today.plus(1, ChronoUnit.WEEKS);
LocalDate minus = today.minus(1, ChronoUnit.WEEKS);
日期比较
LocalDate date1 = LocalDate.now();
LocalDate date2 = LocalDate.of(2011, 5, 22);
if (date1.equals(date2)) {
System.out.println("相等");
} else {
System.out.println("不等");
}
查看源码,发现LocalDate类重写了equals方法,比较办法也是比较直接,年对年,月对月,日对日。
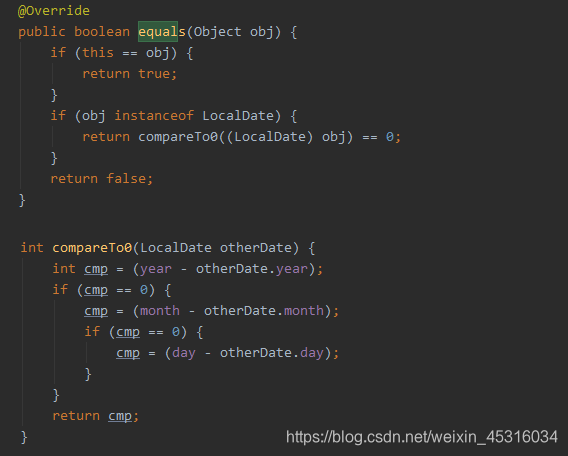
节假日生日检查
LocalDate date1 = LocalDate.now();
LocalDate date2 = LocalDate.of(2019,10,1);
MonthDay monthDay = MonthDay.of(date2.getMonth(),date2.getDayOfMonth());
MonthDay currentMonthDay = MonthDay.from(date1);
if(currentMonthDay.equals(monthDay)){
System.out.println("国庆节到了");
}
判断闰年
LocalDate today = LocalDate.now();
if(today.isLeapYear()){
System.out.println("This year is Leap year");
}
1.3.2 LocalTime
只包含时间信息,没有日期
//21:43:37.911
LocalTime time = LocalTime.now();
获取时间的前后时间
//往后三小时的时间
LocalTime newTime = time.plusHours(3);
//往前三小时的时间
LocalTime newTime2 = time.minusHours(3);
1.3.3 LocalDateTime
日期+时间
//2019-10-10T22:10:01.386
LocalDateTime now = LocalDateTime.now();















 3253
3253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









