






一、了解HTTP协议
1. 浏览器背后的故事

2. 两个概念
- 文本表示图片、文字等信息
- 超文本表示文本中含有链接,可以通过链接跳转到某一页面
3. HTTP协议的概念
- 超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器
- HTTP是一个属于应用层的面向对象的协议,由于其简捷、决速的方式,适用于分布式超媒体信息系统。
4. HTTP事务处理过程
当客户端访问Web站点时,首先会通过DNS服务查询到域名的IP地址。然后浏览器通过IP地址生成HTTP请求,并通过TCP/IP协议发送给Web服务器。Web服务器接收到请求后会根据请求生成响应内容,并通过TCP/IP协议返回给客户端。

二、HTTP协议的特点
1. 支持客户/服务器模式
客户/服务器模式工作的方式是由客户端向服务器发出请求,服务器端响应请求,并进行相应服务
2. 简单快速
- 客户向服务器请求服务时, 只需传送请求方法和路径
- 请求方法常用的有GET, HEAD, POST。每种方法规定了客户与服务器联系的类型不同
- 由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快
3. 灵活
- HТТР允许传输任意类型的数据对象
- 正在传输的类型由Content—Type(Content—Type是HTTP包中用来表示内容类型的标识)加以标记
4. 无连接
- 无连接的含义是限制每次连接只处理一个请求
- 服务器处理完客户的请求,并收到客户的应答后,即断开连接
- 采用这种方式可以节省传输时间
5. 无状态
HTTP协议是无状态协议
无状态指的是客户端向服务器发送请求之后,服务器仅传回响应,并不对请求做任何的保留和记忆
无状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大
另一方面,在服务器不需要先前信息时它的应答就较快
三、HTTP1.0和HTTP1.1的区别
1、HTTP1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。
HTTP1支持长连接,在请求头里面有Connection:Keep-Alive。在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。
2、HTTP 1.1增加host字段
在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。
HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
由于HTTP 1.0不支持Host请求头字段,WEB浏览器无法使用主机头名来明确表示要访问服务器上的哪个WEB站点,这样就无法使用WEB服务器在同一个IP地址和端口号上配置多个虚拟WEB站点。在HTTP 1.1中增加Host请求头字段后,WEB浏览器可以使用主机头名来明确表示要访问服务器上的哪个WEB站点,这才实现了在一台WEB服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟WEB站点。
其他:
HTTP 1.1的持续连接,也需要增加新的请求头来帮助实现,例如,Connection请求头的值为Keep-Alive时,客户端通知服务器返回本次请求结果后保持连接;Connection请求头的值为close时,客户端通知服务器返回本次请求结果后关闭连接。HTTP 1.1还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头。
四、HTTP请求方法
1. GET
GET方法用来请求访问已被URI识别的资源
指定的资源经服务器端解析后返回响应内容
GET方法会将提交的参数显示在URL中,不安全
http://localhost/login.php?username=aa&password=1234
从上面的URL请求中,很容易就可以辨认出表单提交的内容
浏览器对于提交URL的长度也有所限制
2. POST
- POST方法的功能与GET类似
- 数据放在请求体中,没有直接放在请求头的URL中,较为安全,一般用于提交表单的数据,理论上URL 的长度没有限制
3. PUT
从客户端向服务器传送的数据取代指定的内容
PUT方法与POST方法最大的不同是: PUT是幂等的,而POST不是幂等的
幂等表示取代同一个地方的内容,即更新数据,如更换头像
非幂等如论坛发表评论,不会取代之前已发的内容
4. HEAD
一般用来测试某个地址是否可以连通
类似于GET请求,只不过返回的响应中没有具体的内容,用于获取报头
5. DELETE
请求服务器删除指定的资源
五、HTTP响应的状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见状态码:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
六、HTTP的长连接与短连接
HTTP协议是基于请求/响应模式的,因此只要服务端给了响应,本次HTTP请求就结束了
HTTP的长连接和短连接本质上是TCP长连接和短连接
HTTP/1.0中,默认使用的是短连接;也就是说,浏览器和服务器每进行一次HTTP操作,就建立—次连接, 结束就中断
HTTP/1.1起,默认使用长连接,用以保持连接特性
HTTP的长连接格式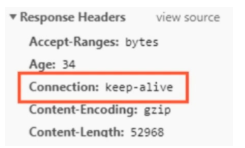
-
HTTP长连接与短连接简要过程
短连接:
建立连接一数据传输一关闭连接 … 建立连接一数据传输一关闭连接
长连接:
建立连接—数据传输…(保持连接)…数据传输—关闭连接
七、HTTP缓存
1. 简介
若每次相同的URL都重新请求服务器的资源,会导致服务器的压力较大,故引出了缓存机制;缓存的内容一般是css等改动频率比较低的静态资源,往往都是存在浏览器端,防止这些“多余”的请求重复的访问服务器
2. 描述缓存的报文头字段
Cache-Control
通用报文头,缓存控制字段
常见取值如下:
no—store:所有内容都不缓存
no—cache:缓存,但是浏览器使用缓存前,都会请求服务器判断缓存资源是否是最新
max—age=x(单位 秒):请求缓存后的X秒不再发起请求
s—maxage=x(单位 秒):代理服务器请求源站缓存后的X秒不再发起请求 (只对CDN缓存有效)
public:客户端和代理服务器(CDN)都可缓存
private:只有客户端可以缓存
3. HTTP缓存工作方式
**场景一:**让服务器与浏览器约定一个文件过期时间—Expires

**场景二:**让服务器与浏览器在约定文件过期时间的基础上,再加一个文件最新修改时间的对比 Last—Modified 与 if-Modified-Since

**场景三:**让服务器与浏览器在过期时间 Expires + Last-Modified 的基础上,增加一个文件内容唯一对比标记
Etag 与 lf-None- Match , 再加入一个max-age来加以代替Expires

4. 缓存改进方案
MD5 / hash缓存
对一个资源添加MD5或者Hash修改之后同时也修改其请求路径,本地没有此路径的缓存,则会发起新的请求获取到改变的内容;解决浏览器无法跳过缓存过期时间主动感知文件变化的问题
CDN缓存
CDN是构建在网络之上的内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率
举个例子理解CDN缓存:原来一个城市只有一个火车票总售卖点,流量大,压力大;后来城市建立了很多代售点,居民可以就近买票;代售点称为CDN节点,可以处理一部分请求,减轻总服务器的压力
5. CDN缓存工作方式
第一次请求:

后续请求:

八、断点续传和多线程下载
1. 简介
HTTP是通过在Header里两个参数实现的,客户端发请求时对应的是Range ,服务器端响应时对应的是Content—Range
续传成功,响应会返回状态码206
内容若有改动,响应会返回状态码200及新文件的内容
2. 请求头Range
指定第一个字节的位置和最后一个字节的位置
一般格式:Range:(unit=first byte pos)-[last byte pos]
左开右闭,但实际执行时两边都是闭区间
3. 响应头Content—Range
在发出带Range的请求后,服务器会在Content—Range头部返回当前接受的范围和文件总大小
一般格式:Content-Range: bytes (unit first byte pos) - [last byte pos]/[entity length]
在响应完成后,返回的响应头内容也不同:
HTTP/1.1 200 Ok (不使用断点续传方式)
НТТP/1.1 206 Partial Content (使用断点续传方式)
4. 断点续传过程
客户端下载一个1024K的文件,已经下载了其中512K
网络中断,客户端请求续传,因此需要在HTTP头中申明本次需要续传的片段 Range:bytes=512000-
这个头通知服务端从文件的512K位置开始传输文件直到文件全部传输完毕
服务端收到断点续传请求,从文件的512K位置开始传输,并且在HTTP头中增加 Content-Range:bytes 512000-/1024000
并且此时服务端返回的HTTP状态码应该是206,而不是200














 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









