







slub内存管理的4个主要接口函数如下(参考kernel-4.19):
//slab缓存的创建
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void *));
//slab object的分配
void *kmem_cache_alloc(struct kmem_cache *cachep, int flags);
//slab object的释放
void kmem_cache_free(struct kmem_cache *cachep, void *objp);
//slab缓存的释放
void kmem_cache_destroy(struct kmem_cache *);本篇主要介绍slab object释放的函数kmem_cache_free
一、函数关系调用图
1、kmem_cache_free函数调用关系图

2、两个路径释放对应的object释放情况说明
2.1 fastpath
如果obj对应的page跟kmem_cache *s所属的per cpu的page是匹配的,是可以直接释放的,进入obj快速释放路径,更新了c->freelist,否则进入慢速释放路径。代码流程:set_freepointer->this_cpu_cmpxchg_double。状态:FREE_FASTPATH++
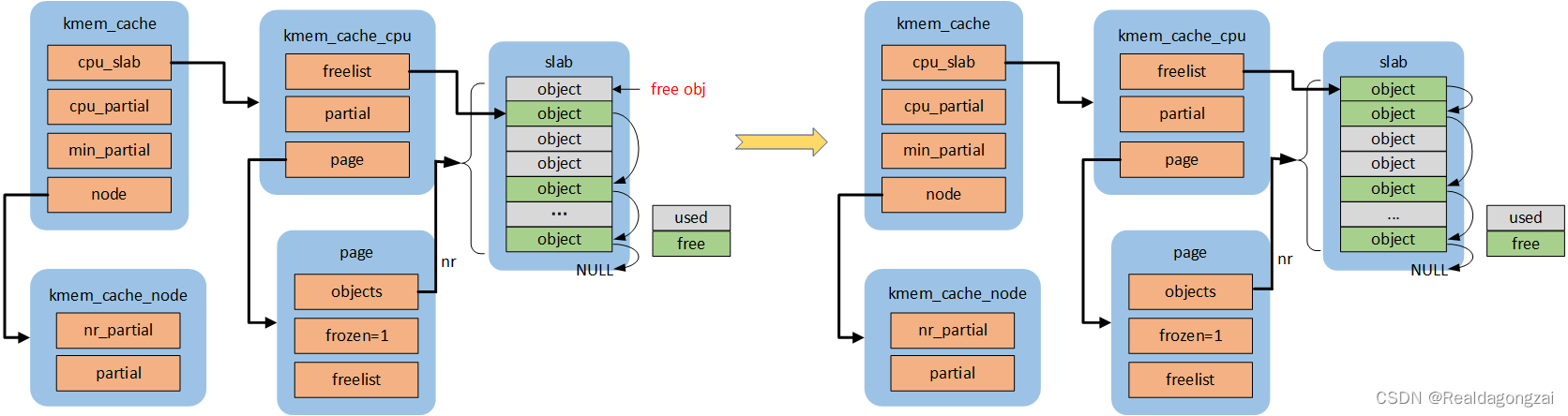
2.2 slowpath-1
(慢速路径释放,统一是对page->freelist操作,而不是c->freelist)
如果这个page对应的page->freelist为空(slab是full slab)且new.frozen =1,那么释放obj变成partial empty slab后,按照规则需要将其放到kmem_cache *s对应的per cpu partial链表的头部,但是在添加之前会判断per cpu partial链表中所有的空闲obj数目(pobjects)是否会大于s->cpu_partial,如果不会直接添加到per cpu partial链表头部即可;否则,会调用unfreeze_partials函数,将per cpu partial上的所有page解冻(frozen置0),然后将per cpu partial链表上所有page,添加到各自对应的node partial上,最后在将这个page添加到per cpu partial。代码流程:put_cpu_partial->unfreeze_partials(pobjects>s->cpu_partial)。状态:FREE_SLOWPATH++,CPU_PARTIAL_FREE++,(可能还会涉及CPU_PARTIAL_DRAIN++,FREE_ADD_PARTIAL++,DEACTIVATE_EMPTY++)
(1)pobjects <= s->cpu_partial

(2)pobjects > s->cpu_partial

2.3 slowpath-2
如果这个page对应的was_frozen初始值就是1,说明该page是属于其他CPU的,当前CPU无法对其进行任何操作(添加到CPU partial或者node partial),直接return。状态:FREE_SLOWPATH++,FREE_FROZEN++
2.4 slowpath-3
如果释放obj后,slab是empty slab(new.inuse为0),首先会得到这个page对应的node,然后按照规则判断n->nr_partial 是否小于s->min_partial,如果是,则直接执行释放操作即可;否则会调用remove_partial/remove_full将其从node partial/full链表中删除,还给buddy system。代码流程:remove_partial/remove_full->discard_slab。状态:FREE_SLOWPATH++,FREE_REMOVE_PARTIAL++/FREE_SLAB++
(1)n->nr_partial < s->min_partial

(2)n->nr_partial >= s->min_partial
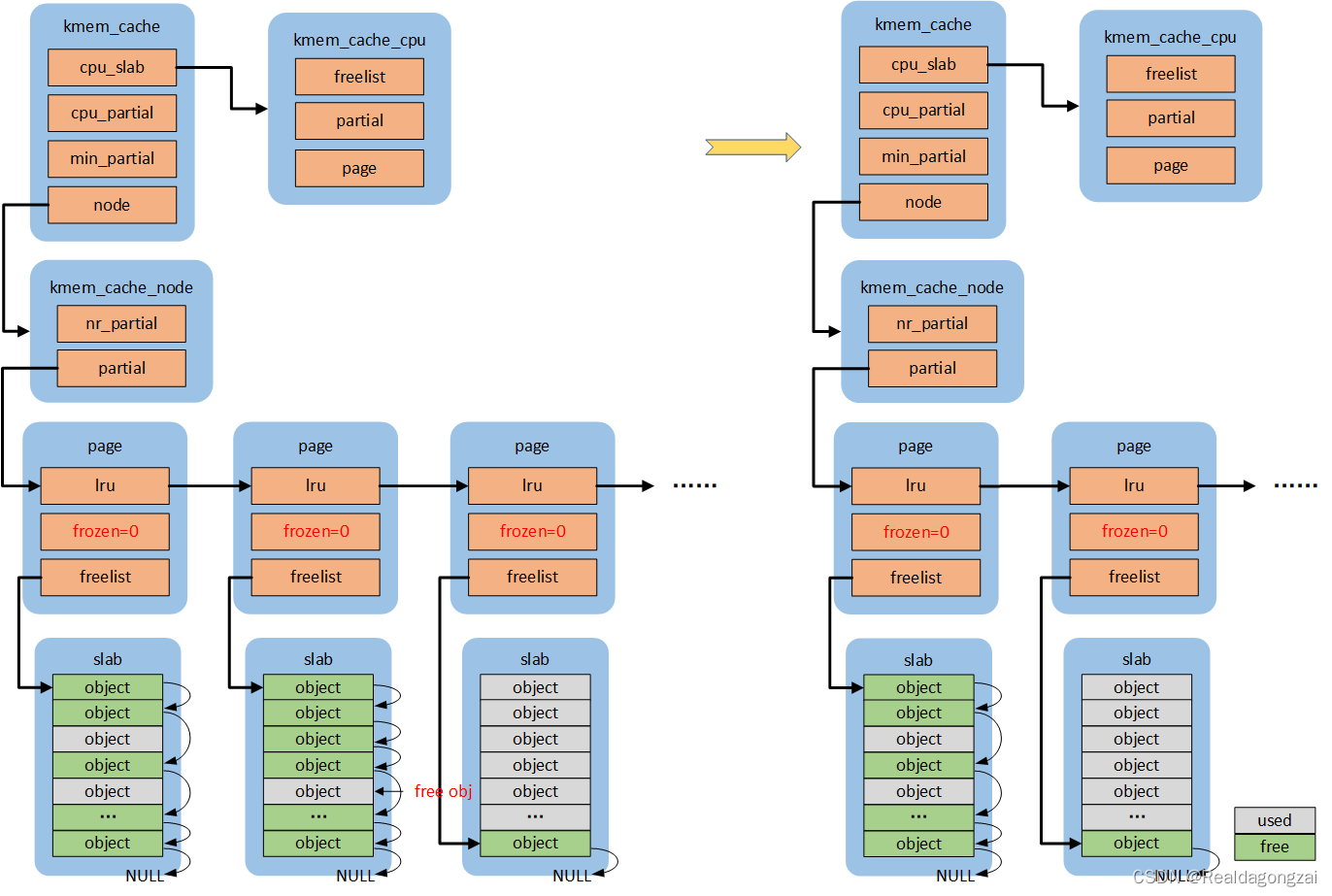
2.5 slowpath-4
如果未使能SLUB_CPU_PARTIAL,虽然是full slab,但是由于没有CPU partial,只能将这个page添加到该page对应node partial尾部,如果开启了slub debug,首先还会执行remove_full操作。代码流程:remove_full->add_partial。状态:FREE_SLOWPATH++,FREE_ADD_PARTIAL++
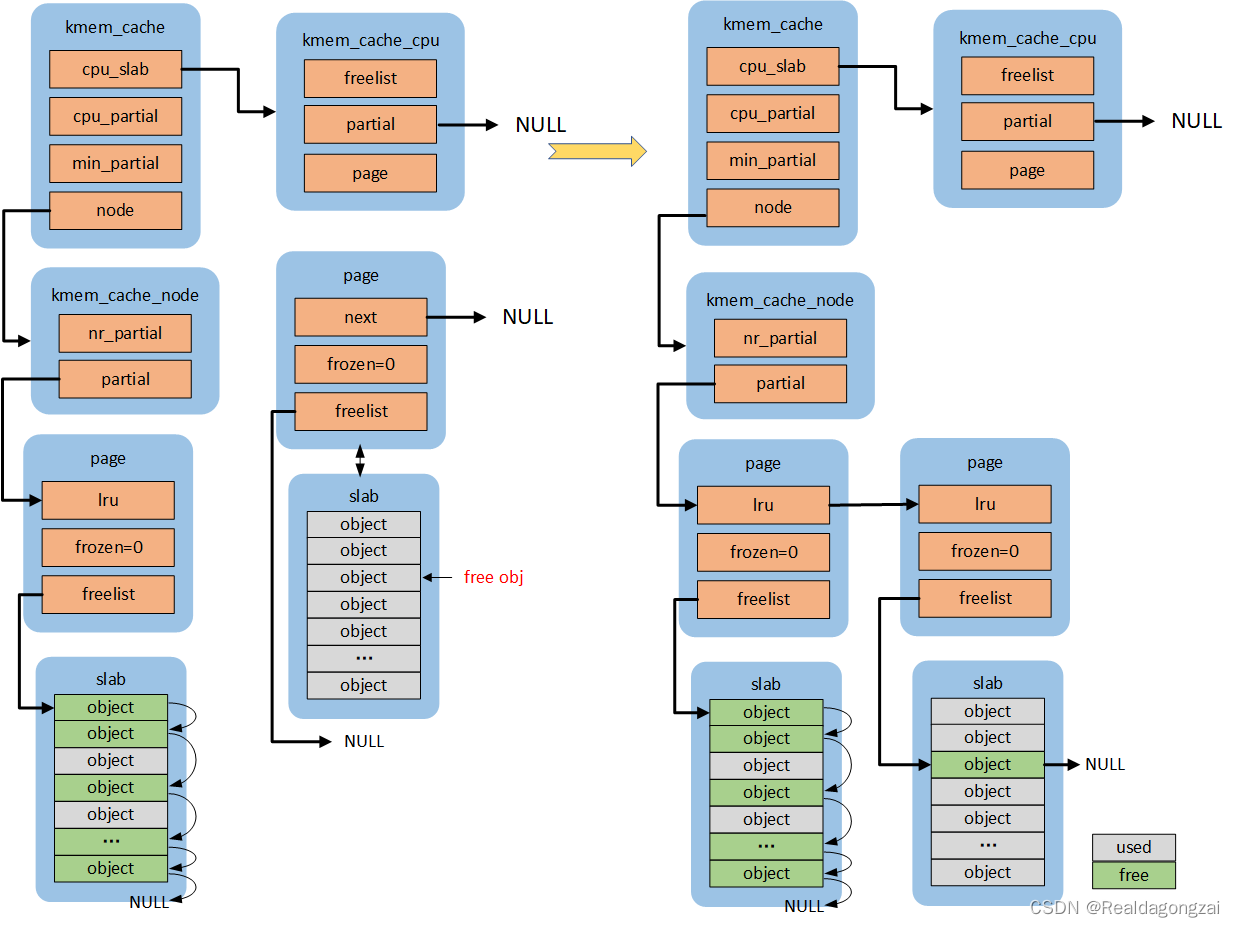
二、kmem_cache_free函数
mm/slub.c
void kmem_cache_free(struct kmem_cache *s, void *x)
{
//1、获取回收对象的kmem_cache
s = cache_from_obj(s, x);
if (!s)
return;
//2、对象回收的核心函数
slab_free(s, virt_to_head_page(x), x, NULL, 1, _RET_IP_);
//对对象的回收进行trace跟踪
trace_kmem_cache_free(_RET_IP_, x);
}
EXPORT_SYMBOL(kmem_cache_free);
/*1
kmem_cache在kmem_cache_free()的入参已经传入了,但这里仍要去重新判断获取该结构,
主要是由于当内核将各kmem_cache链接起来的时候,
其通过obj地址(x)经virt_to_head_page()转换后获取的page页面结构远比用户传入kmem_cache的更值得可信
*/
static inline struct kmem_cache *cache_from_obj(struct kmem_cache *s, void *x)
{
struct kmem_cache *cachep;
struct page *page;
/*
* When kmemcg is not being used, both assignments should return the
* same value. but we don't want to pay the assignment price in that
* case. If it is not compiled in, the compiler should be smart enough
* to not do even the assignment. In that case, slab_equal_or_root
* will also be a constant.
*/
//判断memcg是否未开启且kmem_cache是否未设置SLAB_CONSISTENCY_CHECKS,如果是的话,则直接返回S
if (!memcg_kmem_enabled() &&
!unlikely(s->flags & SLAB_CONSISTENCY_CHECKS))
return s;
//通过object地址x得到对应的page
page = virt_to_head_page(x);
//得到该page对应的kmem_cache
cachep = page->slab_cache;
//判断调用者传入的kmem_cache是否与释放的对象所属的kmem cache相匹配,如果匹配则直接返回
//如果未使能memcg,默认返回true;使能了memcg会进行判断
if (slab_equal_or_root(cachep, s))
return cachep;
//否则,打印错误信息,返回调用者传入的s
pr_err("%s: Wrong slab cache. %s but object is from %s\n",
__func__, s->name, cachep->name);
WARN_ON_ONCE(1);
return s;
}
//2
static __always_inline void slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
/*
* With KASAN enabled slab_free_freelist_hook modifies the freelist
* to remove objects, whose reuse must be delayed.
*/
//2.1 如果开启kasan,slab_free_freelist_hook会将其obj放到内存隔离区,进行一些额外处理,delay free,这个函数默认返回true
if (slab_free_freelist_hook(s, &head, &tail))
//2.2 核心函数
do_slab_free(s, page, head, tail, cnt, addr);
}
//2.1
static inline bool slab_free_freelist_hook(struct kmem_cache *s,
void **head, void **tail)
{
/*
* Compiler cannot detect this function can be removed if slab_free_hook()
* evaluates to nothing. Thus, catch all relevant config debug options here.
*/
//四个config配置一个成立,就会进入,否则直接返回true
#if defined(CONFIG_LOCKDEP) || \
defined(CONFIG_DEBUG_KMEMLEAK) || \
defined(CONFIG_DEBUG_OBJECTS_FREE) || \
defined(CONFIG_KASAN)
void *object;
void *next = *head;
void *old_tail = *tail ? *tail : *head;
/* Head and tail of the reconstructed freelist */
*head = NULL;
*tail = NULL;
do {
object = next;
next = get_freepointer(s, object);
/* If object's reuse doesn't have to be delayed */
//开启kasan,slab_free_hook返回true,否则返回false,
if (!slab_free_hook(s, object)) {
/* Move object to the new freelist */
set_freepointer(s, object, *head);
*head = object;
if (!*tail)
*tail = object;
}
} while (object != old_tail);
if (*head == *tail)
*tail = NULL;
//这里*head为obj X,不为NULL,所以为true
return *head != NULL;
#else
return true;
#endif
}
2.1 do_slab_free函数
static __always_inline void do_slab_free(struct kmem_cache *s,
struct page *page, void *head, void *tail,
int cnt, unsigned long addr)
{
void *tail_obj = tail ? : head;
struct kmem_cache_cpu *c;
unsigned long tid;
redo:
/*
* Determine the currently cpus per cpu slab.
* The cpu may change afterward. However that does not matter since
* data is retrieved via this pointer. If we are on the same cpu
* during the cmpxchg then the free will succeed.
*/
//针对释放过程中出现因抢占而发生CPU迁移的时候
//这时要确保当前执行代码的CPU和kmem_cache *s所属的CPU是同一个,否则一直循环等待
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
/* Same with comment on barrier() in slab_alloc_node() */
//编译时的隔离屏障,防止汇编指令乱序,确保后面object和page是当前CPU的,而不是其他CPU的,slab_alloc_node里面讲过
barrier();
//如果page跟kmem_cache *s所属的per cpu的page是匹配的,是可以直接释放的,进入obj快速释放路径
if (likely(page == c->page)) {
//设置要释放的对象指向当前的空闲对象,即把释放的对象next为c->freelist,下面会重新更新c->freelist为head
set_freepointer(s, tail_obj, c->freelist);
/*原子操作,主要做了三件事:slab_alloc_node里面讲过
(1)重定向首指针指向当前CPU空间;
(2)判断tid和freelist未被修改;
(3)如果未被修改,则此次slab缓存object释放未被CPU迁移,那么就用新的tid和freelist覆盖旧的数据:
s->cpu_slab->freelist = head
s->cpu_slab->tid = next_tid(tid)
此时c->freelist得到了更新
否则,打印错误信息,释放失败
*/
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
c->freelist, tid,
head, next_tid(tid)))) {
note_cmpxchg_failure("slab_free", s, tid);
goto redo;
}
stat(s, FREE_FASTPATH);
} else
//如果page跟kmem_cache *s所属的per cpu的page是不匹配的,不能直接释放(page != c->page),进入obj慢速释放路径, tail_obj==head,这里只是放一个obj
__slab_free(s, page, head, tail_obj, cnt, addr);
}三、__slab_free函数(慢速释放路径)
/* obj慢速释放路径
* Slow path handling. This may still be called frequently since objects
* have a longer lifetime than the cpu slabs in most processing loads.
*
* So we still attempt to reduce cache line usage. Just take the slab
* lock and free the item. If there is no additional partial page
* handling required then we can return immediately.
*/
static void __slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
void *prior;
int was_frozen;
struct page new;
unsigned long counters;
struct kmem_cache_node *n = NULL;
unsigned long uninitialized_var(flags);
//更新状态信息FREE_SLOWPATH
stat(s, FREE_SLOWPATH);
//(1)判断是否开启slub debug,
//(2)如果开启debug,通过free_debug_processing()额外进行一下状态的校验,校验成功返回1,否则返回0
if (kmem_cache_debug(s) &&
!free_debug_processing(s, page, head, tail, cnt, addr))
return;
do {
//第一次循环,n为NULL,直接跳过
//后续每次循环,除非跳出循环,否则都会释放前面加的锁,并将n重新置为NULL,
if (unlikely(n)) {
spin_unlock_irqrestore(&n->list_lock, flags);
n = NULL;
}
prior = page->freelist;
counters = page->counters;
//将要释放的obj添加到page->freelist的头部, head==tail(根据参数输入当前只有一个obj要释放,但是代码支持释放多个obj)
set_freepointer(s, tail, prior);
/*
counters的赋值操作会将和其位于相同union内的
inuse,objects,frozen字段赋值
*/
new.counters = counters;//new.counters = page->counters,
was_frozen = new.frozen;
new.inuse -= cnt;//cnt等于1,相当于减1,因为要释放了,所以inuse要减1
/*
如果new.inuse为0,则slab中没有可分配出去的对象,即当前释放的对象是对应slab中的最后一个对象,释放之后slab全为空闲,empty slab;
prior为NULL,则slab中没有可用的对象,即slab为满,full slab,这类slab是没有链表领养它们的;
was_frozen为0,则说明不属于cpu partial。
这个if语句实际上是对full slab和empty slab做了一些特殊处理
*/
if ((!new.inuse || !prior) && !was_frozen) {
/*
如果使能了SLUB_CPU_PARTIAL(默认使能),kmem_cache_has_cpu_partial返回非0,否则返回0。
若开启SLUB_CPU_PARTIAL且prior为NULL(full slab), 释放当前obj后,变成partial empty,
那么就会将其添加到kmem_cache *s对应的per cpu partial (即new.frozen = 1)
*/
if (kmem_cache_has_cpu_partial(s) && !prior) {
/*
* Slab was on no list before and will be
* partially empty
* We can defer the list move and instead
* freeze it.
*/
new.frozen = 1;
//否则(未开启SLUB_CPU_PARTIAL或者不为full slab)
} else { /* Needs to be taken off a list */
//得到s->node[page_to_nid(page)],获取节点信息,并且获取修改slab list所需的锁,以便之后释放空slab
n = get_node(s, page_to_nid(page));
/*
* Speculatively acquire the list_lock.
* If the cmpxchg does not succeed then we may
* drop the list_lock without any processing.
*
* Otherwise the list_lock will synchronize with
* other processors updating the list of slabs.
*/
//只有slab在释放这obj后为empty slab时才需要获取锁,并且在执行释放操作后释放锁
spin_lock_irqsave(&n->list_lock, flags);
}
}
/*
cmpxchg_double_slab将page->freelist更新为head(head,这个head,tail应该是考虑到要释放多个obj的时候,此时只释放一个obj,head==tail),
page->counters=new.counters,成功返回true(你可以认为通过这个操作把obj给释放了),否则继续循环重试。下面的代码就是对这个obj对应的page的处理情况
*/
} while (!cmpxchg_double_slab(s, page,
prior, counters,
head, new.counters,
"__slab_free"));
//如果n等于NULL,要么这个obj所属的slab为full slab,要么full slab和empty slab都不是,
//要么was_frozen等于1(表明这个slab已经挂在某个per CPU上了)
if (likely(!n)) {
/*
* If we just froze the page then put it onto the
* per cpu partial list.
*/
/*
这个slab为full slab,释放后是partial empty,put_cpu_partial将这个page添加到kmem_cache *s对应的per cpu partial链表的头部,同步会做一些特殊情况处理
同步更新状态信息CPU_PARTIAL_FREE
*/
if (new.frozen && !was_frozen) {
put_cpu_partial(s, page, 1);
stat(s, CPU_PARTIAL_FREE);
}
/*
* The list lock was not taken therefore no list
* activity can be necessary.
*/
/*
slab是属于其他CPU的slab cache,当前的CPU不是冻结slab的CPU,其无法执行其他的操作(将其添加到CPU partial或者node partial),
因此更新状态信息FREE_FROZEN即可,表明是其他CPU上的slab
*/
if (was_frozen)
stat(s, FREE_FROZEN);
return;
}
/*
n不等于NULL(was_frozen==0,同时未开启SLUB_CPU_PARTIAL或者不为full slab)
此时如果这个slab在释放这obj后为empty slab且
满足kmem_cache_node的nr_partial大于等于kmem_cache的min_partial的情况下,则会释放该slab的内存,
跳转到slab_empty直接释放该slab的内存,不会将其挂在node partial上
*/
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
goto slab_empty;
/*
* Objects left in the slab. If it was not on the partial list before
* then add it.
*/
/*
n不等于NULL(was_frozen==0,同时未开启SLUB_CPU_PARTIAL或者不为full slab)
若是未开启SLUB_CPU_PARTIAL(new.frozen不为1),但是slab为full slab,释放obj后,从full变成partial,所以需要将其添加到partial链表上。
如果开启slub debug,将从full链表中remove_full()移出,否则就直接调用add_partial()添加至node partial队列的尾部。
更新状态信息FREE_ADD_PARTIAL
*/
if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) {
if (kmem_cache_debug(s))
remove_full(s, n, page);
add_partial(n, page, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
//spin_unlock_irqrestore()释放中断锁并恢复中断环境
spin_unlock_irqrestore(&n->list_lock, flags);
return;
slab_empty:
/*
如果prior不为NULL,说明其在partial链表的状态为partial,从partial表中删除这个slab,
注意:slub算法让每个CPU的kmem_cache只要维护一个链表,就是partial链表,但是开启了slub debug,则还会有full链表,看结构体kmem_cahce_node的成员变量就知道,而slab算法每个状态都有一个链表,即维护free链表,partial链表,full链表。
*/
if (prior) {
/*
* Slab on the partial list.
*/
remove_partial(n, page);
stat(s, FREE_REMOVE_PARTIAL);
} else {
/* Slab must be on the full list */
remove_full(s, n, page);
}
spin_unlock_irqrestore(&n->list_lock, flags);
stat(s, FREE_SLAB);
//将这个page从kmem_cache* s中删除,还给伙伴系统
discard_slab(s, page);
}3.1 free_debug_processing函数
/* Supports checking bulk free of a constructed freelist */
static noinline int free_debug_processing(
struct kmem_cache *s, struct page *page,
void *head, void *tail, int bulk_cnt,
unsigned long addr)
{
struct kmem_cache_node *n = get_node(s, page_to_nid(page));
void *object = head;
int cnt = 0;
unsigned long uninitialized_var(flags);
int ret = 0;
spin_lock_irqsave(&n->list_lock, flags);
slab_lock(page);
if (s->flags & SLAB_CONSISTENCY_CHECKS) {
//检查kmem_cache与page中的slab信息是否匹配,如果不匹配,可能发生了破坏或者数据不符
if (!check_slab(s, page))
goto out;
}
next_object:
cnt++;
if (s->flags & SLAB_CONSISTENCY_CHECKS) {
//free时,做的一致性检查
if (!free_consistency_checks(s, page, object, addr))
goto out;
}
//如果设置了SLAB_STORE_USER标识,将记录obj释放的track信息
if (s->flags & SLAB_STORE_USER)
set_track(s, object, TRACK_FREE, addr);
//trace()记录对象的轨迹信息
trace(s, page, object, 0);
/* Freepointer not overwritten by init_object(), SLAB_POISON moved it */
//init_object()将obj相关区域填充成相应magic number(SLAB_RED_ZONE和POISON_FREE)(见Slub Debug原理中的free object layout)
init_object(s, object, SLUB_RED_INACTIVE);
//考虑到如果一次性释放连续的多个obj,如果还未到tail,跳转到next_object继续对每个obj执行一次check
/* Reached end of constructed freelist yet? */
if (object != tail) {
object = get_freepointer(s, object);
goto next_object;
}
ret = 1;
out:
if (cnt != bulk_cnt)
slab_err(s, page, "Bulk freelist count(%d) invalid(%d)\n",
bulk_cnt, cnt);
slab_unlock(page);
spin_unlock_irqrestore(&n->list_lock, flags);
if (!ret)
slab_fix(s, "Object at 0x%p not freed", object);
return ret;
}
static inline int free_consistency_checks(struct kmem_cache *s,
struct page *page, void *object, unsigned long addr)
{
//检查obj地址的合法性,确保地址确切地为obj的首地址,而非obj的中间位置
if (!check_valid_pointer(s, page, object)) {
slab_err(s, page, "Invalid object pointer 0x%p", object);
return 0;
}
//检测obj是否已经被释放,避免造成重复释放置
if (on_freelist(s, page, object)) {
object_err(s, page, object, "Object already free");
return 0;
}
//根据slab flag:SLAB_RED_ZONE,SLAB_POISON和SLUB_RED_ACTIVE的设置,对obj进行完整性检测
if (!check_object(s, page, object, SLUB_RED_ACTIVE))
return 0;
//确保用户传入的kmem_cache与page所属的kmem_cache类型是匹配的,否则将记录错误日志
if (unlikely(s != page->slab_cache)) {
if (!PageSlab(page)) {
slab_err(s, page, "Attempt to free object(0x%p) outside of slab",
object);
} else if (!page->slab_cache) {
pr_err("SLUB <none>: no slab for object 0x%p.\n",
object);
dump_stack();
} else
object_err(s, page, object,
"page slab pointer corrupt.");
return 0;
}
//如果上述检查未出现错误,返回1
return 1;
}3.2 put_cpu_partial函数
作用:如果pobjects<=s->cpu_partial,将page添加到kmem_cache *s对应的per cpu partial链表的头部,否则会将当前CPU partial所有page解冻(frozen置0,调用unfreeze_partials),然后添加到node partial上,最后再将这个page添加到当前CPU partial上
/*这个函数实际上在kmem_cache_alloc时也会调用,不过alloc obj时,drain为0,free obj时,drain为1
* Put a page that was just frozen (in __slab_free) into a partial page
* slot if available.
*
* If we did not find a slot then simply move all the partials to the
* per node partial list.
*/
static void put_cpu_partial(struct kmem_cache *s, struct page *page, int drain)
{
//默认是开启SLUB_CPU_PARTIAL
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *oldpage;
int pages;
int pobjects;
//这个操作要关闭抢占
preempt_disable();
do {
pages = 0;
pobjects = 0;
//这oldpage是CPU partial链表第一个page
oldpage = this_cpu_read(s->cpu_slab->partial);
if (oldpage) {
//得到pobjects信息(当前CPU partial中空闲object数目)和pages信息(当前CPU partial中slab数目)
pobjects = oldpage->pobjects;
pages = oldpage->pages;
//根据输入参数,在进行obj free时,drain为1。如果空闲object数目大于s->cpu_partial
//则表示当前CPU partial链表已经满了,需要将此时CPU partial链表的所有page,全部移到per node partial上
if (drain && pobjects > s->cpu_partial) {
unsigned long flags;
/*
* partial array is full. Move the existing
* set to the per node partial list.
*/
local_irq_save(flags);
//将CPU partial链表中所有page,添加到这个page对应node partial的尾部,将frozen置为0,
//如果n->nr_partial >= s->min_partial,则将这个page添加到discard_page里面,然后统一释放这些page
unfreeze_partials(s, this_cpu_ptr(s->cpu_slab));
local_irq_restore(flags);
oldpage = NULL;
pobjects = 0;
pages = 0;
//更新CPU_PARTIAL_DRAIN状态信息
stat(s, CPU_PARTIAL_DRAIN);
}
}
//更新pages和pobjects
pages++;
pobjects += page->objects - page->inuse;
//将新来的page添加到CPU partial的链表首部,从这里也可以知道,cpu partial链表的第一个page包含该链表所有空闲对象的总数和slab的总数,
//第二个page包含除了第一个page外所有空闲对象的总数和slab的总数
page->pages = pages;
page->pobjects = pobjects;
page->next = oldpage;
//如果上面page成功添加到CPU partial,this_cpu_cmpxchg函数此时返回的oldpage,不是page,则退出循环
} while (this_cpu_cmpxchg(s->cpu_slab->partial, oldpage, page)
!= oldpage);
//如果s->cpu_partial为空,说明这个CPU partial里面没有空闲的object,按照规则,会将其从CPU partial中脱离,将里面的page挂到对应的node partial上面,
//这个在文章slub allocator工作原理里面有
if (unlikely(!s->cpu_partial)) {
unsigned long flags;
local_irq_save(flags);
unfreeze_partials(s, this_cpu_ptr(s->cpu_slab));
local_irq_restore(flags);
}
preempt_enable();
#endif
}3.2.1 unfreeze_partials函数
作用:将此时CPU partial链表的所有page,全部移到per node partial上,将CPU partial链表中所有page,添加到这个page对应node partial的尾部,将frozen置为0。如果n->nr_partial >= s->min_partial,则将这个page添加到discard_page里面,然后统一释放这些page
/*
* Unfreeze all the cpu partial slabs.
*
* This function must be called with interrupts disabled
* for the cpu using c (or some other guarantee must be there
* to guarantee no concurrent accesses).
*/
static void unfreeze_partials(struct kmem_cache *s,
struct kmem_cache_cpu *c)
{
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct kmem_cache_node *n = NULL, *n2 = NULL;
//discard_page里面保存要释放回buddy system的page
struct page *page, *discard_page = NULL;
//while循环遍历当前cpu partial中的所有page
while ((page = c->partial)) {
struct page new;
struct page old;
c->partial = page->next;
//得到此次循环page对应的node节点
n2 = get_node(s, page_to_nid(page));
//如果上次的node跟这次的node节点是一样,这锁继续使用,否则,需要先解上次的锁,再上这次的新锁
if (n != n2) {
if (n)
spin_unlock(&n->list_lock);
n = n2;
spin_lock(&n->list_lock);
}
do {
/*
counters的赋值操作会将和其位于相同union内的
inuse,objects,frozen字段赋值
*/
old.freelist = page->freelist;
old.counters = page->counters;
VM_BUG_ON(!old.frozen);//正常位于CPU partial上的page,frozen=1
new.counters = old.counters;
new.freelist = old.freelist;
//将frozen从1置为0,意味着从当前cpu partial解冻
new.frozen = 0;
/*
__cmpxchg_double_slab将page->freelist更新为new.freelist,
page->counters=new.counters,成功返回true,失败则继续循环重试
*/
} while (!__cmpxchg_double_slab(s, page,
old.freelist, old.counters,
new.freelist, new.counters,
"unfreezing slab"));
/*
如果在while循环执行中,这个page在释放这obj后为empty slab,且
满足kmem_cache_node的nr_partial大于等于kmem_cache的min_partial的情况下,
则会将这个page添加到discard_page上(后面discard_slab统一释放,将其中空闲的obj还给伙伴系统),不会将其挂在node partial上
*/
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) {
page->next = discard_page;
discard_page = page;
} else {
//1、否则,将这个page添加到该page对应的node节点的尾部
add_partial(n, page, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
}
//对最后一次循环,进行解锁
if (n)
spin_unlock(&n->list_lock);
//2、对需要还给伙伴系统的page,统一处理
while (discard_page) {
page = discard_page;
discard_page = discard_page->next;
stat(s, DEACTIVATE_EMPTY);
discard_slab(s, page);
stat(s, FREE_SLAB);
}
#endif
}
3.3 add_partial函数和discard_slab函数
作用:add_partial是向node partial链表的尾部插入指定的page;discard_slab是将这个page从kmem_cache中释放,还给伙伴系统
//1 介绍add_partial函数
/*
* Management of partially allocated slabs.
*/
static inline void
__add_partial(struct kmem_cache_node *n, struct page *page, int tail)
{
n->nr_partial++;//自增该node节点链表管理的的page数目
//向该node节点的尾部添加这个page,根据参数,在尾部添加
//这个n->partial链表是双向链表,它设置了算法导论里面说的哨兵,哨兵是一个哑对象,位于表头和表尾之间
//起到简化边界条件的处理,可以方便的往表头和表尾插入新的对象
if (tail == DEACTIVATE_TO_TAIL)
list_add_tail(&page->lru, &n->partial);
else
//否则,向该节点的头部添加这个page
list_add(&page->lru, &n->partial);
}
static inline void add_partial(struct kmem_cache_node *n,
struct page *page, int tail)
{
lockdep_assert_held(&n->list_lock);
__add_partial(n, page, tail);
}
//2 介绍discard_slab函数
static void __free_slab(struct kmem_cache *s, struct page *page)
{
//获取创建这个slab时所用的页表数目(pages),好后面释放给伙伴系统
int order = compound_order(page);
int pages = 1 << order;
//对该slab缓冲区进行一次检测,主要是检测是否有内存破坏(内存越界和use-after-free)以记录相关信息
if (s->flags & SLAB_CONSISTENCY_CHECKS) {
void *p;
slab_pad_check(s, page);
for_each_object(p, s, page_address(page),
page->objects)
check_object(s, page, p, SLUB_RED_INACTIVE);
}
mod_lruvec_page_state(page,
(s->flags & SLAB_RECLAIM_ACCOUNT) ?
NR_SLAB_RECLAIMABLE : NR_SLAB_UNRECLAIMABLE,
-pages);
//清除page的标志位
__ClearPageSlabPfmemalloc(page);
__ClearPageSlab(page);
page->mapping = NULL;
if (current->reclaim_state)
current->reclaim_state->reclaimed_slab += pages;
//从memcg系统删除这个page
memcg_uncharge_slab(page, order, s);
//通过伙伴系统释放从这个page开始个数为2的order次方的页面
__free_pages(page, order);
}
static void free_slab(struct kmem_cache *s, struct page *page)
{
//如果设置了SLAB_DESTROY_BY_RCU标识,将会通过RCU的方式将page释放掉,否则调用__free_slab
if (unlikely(s->flags & SLAB_TYPESAFE_BY_RCU)) {
call_rcu(&page->rcu_head, rcu_free_slab);
} else
__free_slab(s, page);
}
//会将这个page添加到discard_page上(后面discard_slab统一释放,将其中空闲的obj还给伙伴系统),
//不会将其挂在node partial上
static void discard_slab(struct kmem_cache *s, struct page *page)
{
//把要释放的slab所包含的对象数量(page->objects)从page对应的节点中删除,并且减少节点的nr_slabs
dec_slabs_node(s, page_to_nid(page), page->objects);
//释放page
free_slab(s, page);
}3.4 remove_full函数和remove_partial函数
作用:分别从full表和partial表中删除指定的page
//开启slub debug是如下定义;如未开启,直接为空函数
static void remove_full(struct kmem_cache *s, struct kmem_cache_node *n, struct page *page)
{
//SLAB_STORE_USER??
if (!(s->flags & SLAB_STORE_USER))
return;
lockdep_assert_held(&n->list_lock);
//将这个page从full链表中删除
list_del(&page->lru);
}
static inline void remove_partial(struct kmem_cache_node *n,
struct page *page)
{
lockdep_assert_held(&n->list_lock);
//将这个page从partial链表中删除
list_del(&page->lru);
//同时自减n->nr_partial,因为其从node partial链表中删除的
n->nr_partial--;
}













 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









