






常用面知识
1. http
1.1 http和https的区别
- http是明文传输,https是加密传输
- http是默认80端口,https默认是443端口
- https需要进行加密,需要证书认证
1.2 post和get区别
- get是幂等的没有任何副作用,不会更改服务器的状态,post是非幂等的,更改服务器的状态
- get带参是通过url,post带参通过表单
- get发送一个tcp包,post发送两个
2. java 集合

Collection 和 Collections 有什么区别?
collection是接口 是集合类的顶层接口\
Collections是工具类,提供一系列的静态方法,用于对集合的元素进行排序、搜索以及线程安全操作
Iterator和ListIterator的区别?
Iterator 可用来遍历Set和List,但是ListIterator只能遍历List。
Iterator对集合只能是前向遍历,ListIterator既可以前向也可以后向。
ListIterator实现了Iterator接口
ArrayList
ArrayList是基于数组实现的,LinkedList是链表实现的。ArrayList 是线程不安全的,并发add会出现下标越界
2.1 map 的实现原理:
hashmap变量
table// 哈希表 主要结构
entryset//
size // 节点大小
modCount// 结构性变
treshold // 扩容 预值 = capacity*loadFactor
loadFactor //负载因子
HashMap 的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
static class Node<K,V> implements Map.Entry<K,V> {
//hash值
final int hash;
//key
final K key;
//值
V value;
//链表连接相同哈希的值
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
插入
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//建立 节点 tab 和 p 下标 n和i
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果map为空初始化操作
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//路由寻址公式: (table.length-1)&node.hash
//取出hash值对应的节点 如果为空
if ((p = tab[i = (n - 1) & hash]) == null)
// 则tab[i] = 新节点
tab[i] = newNode(hash, key, value, null);
else {//如果当前位置有值
//建一个node节点,和一个Key
Node<K,V> e; K k;
//如果 p的hash值等于要存的hash值并且(键相同或者Key不等于空且键的引用地址相同)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// e 是取出的节点 其key值要要存入的值相同,
e = p;
//如果是一个树节点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//已经是链表了
else {
for (int binCount = 0; ; ++binCount) {
// 查找到 一个链路的节点的next等于null 说明找不到一个和要存入值相同的节点
if ((e = p.next) == null) {
// 将新节点存入链路
p.next = newNode(hash, key, value, null);
// 如果链路的大小 大于 树的预值
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果找不到哈希值和key值相同的节点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//循环下一个
p = e;
}
}
if (e != null) { // existing mapping for key
进行替换
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//结构性修改次数
++modCount;
//如果 大小大于预值
if (++size > threshold)
// 扩容
resize();
afterNodeInsertion(evict);
return null;
}
整体结构
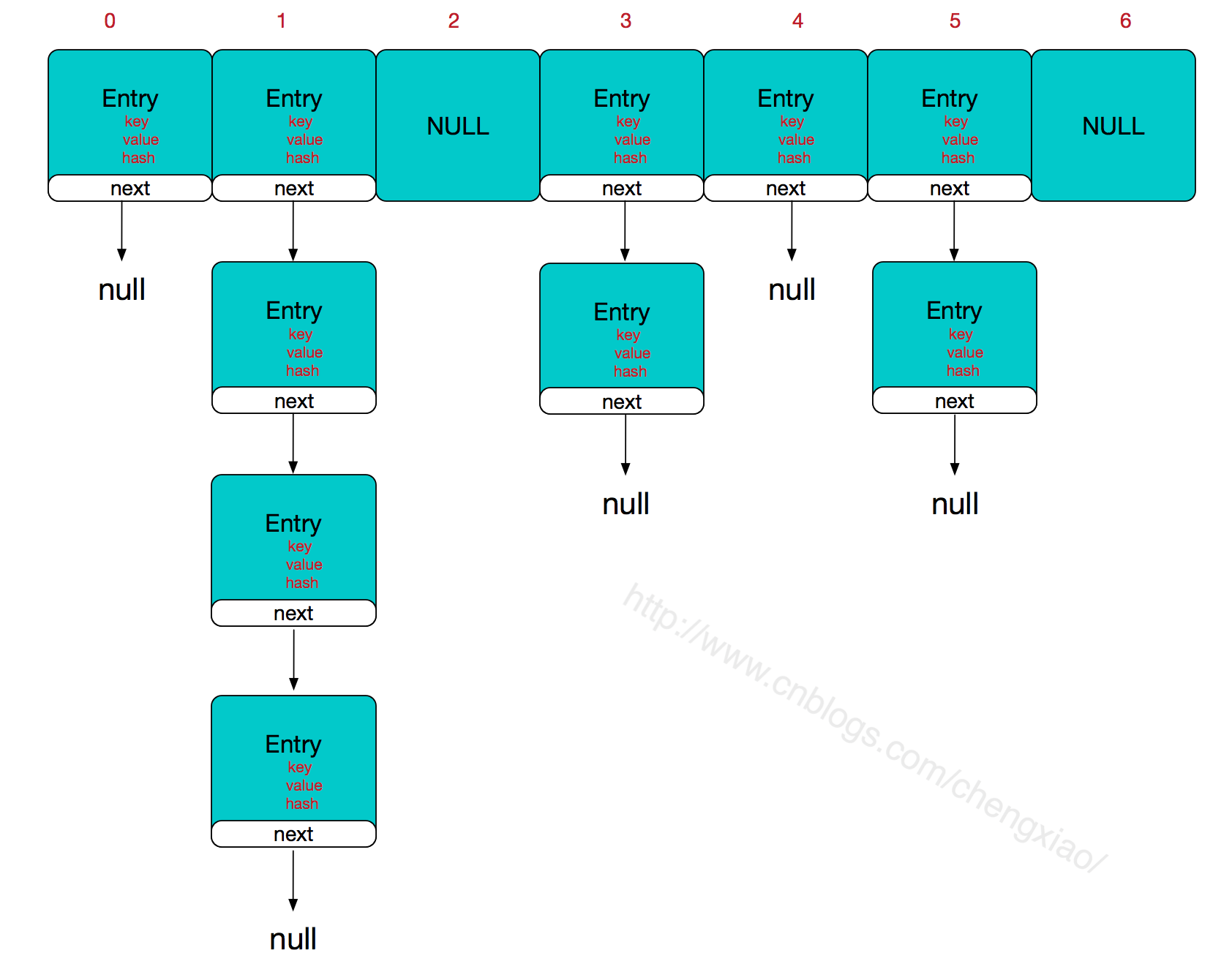
java 1.8以后如果链超过8会转化为红黑树,少于6转化为链表。因为链表查找平均长度为n/2 红黑树平均长度为lgn
扩容机制:
Resize()
ConcurrentHashmap
参数:
final int MAXIMUM_CAPACITY = 1 << 30; //最大容量
final int DEFAULT_CAPACITY = 16; //默认初始容量
final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; //最大数组大小
static final float LOAD_FACTOR = 0.75f;//默认负载因子
final int TREEIFY_THRESHOLD = 8; //转化为树的阈值
static final int UNTREEIFY_THRESHOLD = 6; //转化为链表的阈值
static final int MIN_TREEIFY_CAPACITY = 64; //最小的表容量转化为树 =4* 树阈值
构造方法
public ConcurrentHashMap() {
}//初始大小为16的map
public ConcurrentHashMap(int initialCapacity) {//动态设置map的初始大小
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {//通过map构造 map
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
方法
size//大小
isEmpty//为空判断
get//取值
containsKey //内容包括key
containsValue// 内容包括value
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 如果值或者键有空值 抛出空指针异常
if (key == null || value == null) throw new NullPointerException();
//通过key 获取hash值
int hash = spread(key.hashCode());
int binCount = 0;
//将table存给tab
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//通过hash获取数组的角标
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//将节点加入
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//如果正在扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//对数组hash位置加锁
synchronized (f) {
//在次校验 角标还是f
if (tabAt(tab, i) == f) {
链表
if (fh >= 0) {
binCount = 1;
//遍历链表 查到相同则替换
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//如果是空 连接到最后
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
inittable
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
//当 tab 为空时
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
//如果正在扩容或者初始化放弃锁
Thread.yield(); // lost initialization race; just spin
//CAS 原子操作,原理是比较获取的值与当前值相不相同 如果相同改为-1
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
//判断是不是为空
if ((tab = table) == null || tab.length == 0) {
//如果给了容量 则设置否则默认 sc 容量有初始值才大于0
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
//创建一个数组 容量是初始值或者默认值
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
//将创建的数组赋值给table
table = tab = nt;
// 0.75 n
sc = n - (n >>> 2);
}
} finally {
//记录扩容阈值
sizeCtl = sc;
}
break;
}
}
return tab;
}
LinkedHashMap
双向链表定义的map 记录插入顺序
参数:
LinkedHashMap.Entry<K,V> head //双向链表的头
LinkedHashMap.Entry<K,V> tail; //双向链表的尾
boolean accessOrder;//
hashcode和equal
哈希值相同 值不一定相同,值相同 hash一定相同。
== 和equal
==
- 基本数据类型 比较值
- 引用对象比地址
equal
- 引用对象比较地址
为什么要使用hashcode
collection 接口下有两个集合类:list 和 set
set是不重复的 实现原理是使用哈希算法计算哈希值将值放到对应的内存地址上,如果计算的哈希已经存在值,则使用equal进行比较如果相同则不存了,否则存到其他位置。
2.2 List 去重
1.使用LinkedHsahSet 去重
Set<String> set = new LinkedHashSet<>();
set.addAll(stringList);
stringList.clear();
stringList.addAll(set);
2.对象属性去重
Set<UserInfo> personSet = new TreeSet<>((o1, o2) -> o1.getUserId().compareTo(o2.getUserId()));
personSet.addAll(persons);
3.对象多属性去重
public static List<UserInfo> removeDupliByMorePro(List<UserInfo> persons) {
/** 集合操作流*/
List<UserInfo> personList = persons.stream()
/** 约束操作 collect(Collectors)*/
.collect(Collectors
/** collectingAndThen(toList(),midiList) 通过tolist()返回新的list*/
.collectingAndThen(Collectors
/** Collector*/
.toCollection(
/** 通过TreeSet 生成不重复的列*/
) -> new TreeSet<>(Comparator.comparing(
o -> {
// 根据useId和userName进行去重
return o.getUserId() + "," + o.getUsername();
}
)
)
), ArrayList::new
)
);
return personList;
}
List<User> list2 = list.stream().distinct().collect(Collectors.toList());
System.out.println("list2="+list2);
stream:
基本介绍:Stream(流)串行流
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源 流的来源。 可以是集合,数组,I/O channel, 产生器generator 等。
- 聚合操作 类似SQL语句一样的操作, 比如filter, map, reduce, find, match, sorted等。
Collectors
用于返回将流转换为集合和聚合元素的对象
List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
List<String> filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList());
System.out.println("筛选列表: " + filtered);
String mergedString = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.joining(", "));
System.out.println("合并字符串: " + mergedString);
方法:
-
forEach
Stream 提供了新的方法 ‘forEach’ 来迭代流中的每个数据。以下代码片段使用 forEach 输出了10个随机数:
-
map
map 方法用于映射每个元素到对应的结果,以下代码片段使用 map 输出了元素对应的平方数:
-
filter
filter 方法用于通过设置的条件过滤出元素。以下代码片段使用 filter 方法过滤出空字符串:
-
collectingAndThen(toList(), Collections::unmodifiableList)进行额为的转换,可将原来的list 经过转换器变为新的list
3.JWT
3.1 header
{
//类型
"typ": "JWT",
//签名算法
"alg": "HS256"
}
3.2 Payload
{
"sub": "1",
"iss": "http://localhost:8000/auth/login",
"iat": 1451888119,
"exp": 1454516119,
"nbf": 1451888119,
"jti": "37c107e4609ddbcc9c096ea5ee76c667"
}
sub: 该JWT所面向的用户
iss: 该JWT的签发者
iat(issued at): 在什么时候签发的token
exp(expires): token什么时候过期
nbf(not before):token在此时间之前不能被接收处理
jti:JWT ID为web token提供唯一标识
3.3 签名(签名)
secret 秘钥
4. 前端 Token处理
发送时请求头放在 Authorization
5.final 和static
- final 表示不变的,如果是数据类型被final修饰则无法被改变,
- 如果方法被final修饰,则不能被重写,
- final 修饰类,该类不能被继承所有方法不能被冲重写,但是可以重载
static 属于静态资源,
-
修饰方法是类方法,可以使用类.方法使用
-
修饰变量 是类变量,类.变量使用
6.泛型限定符
上界<? extend Fruit>
下界<? super Apple>
则 ? extends ParentClass 表示要匹配的类型继承自ParentClass类,
而 ? super ChildClass 表示要匹配的类型是ChildClass的父类
7.泛型 参数化类型
将类型由原来的具体的变为不具体的。
8.String ,StringBuffer和StringBuilder
String 是静态的 一旦定义无法被修改,
StringBuffer和StringBuilder能够被修改,StringBuffer是线程安全的
9.为什么实现Serializable
实现的作用是可以将对象存为字节流,然后可以恢复,在分布式系统中实现序列化进行网络传输
10.树
树的遍历
public class Order {
/**
* 先根遍历
* @param root 要的根结点
*/
public void preOrder(Tree root) {
if(!root.isEmpty()) {
visit(root);
for(Tree child : root.getChilds()) {
if(child != null) {
preOrder(child);
}
}
}
}
二叉树
public class Tree<T> {
//Node节点
private Node<T> root;
//查找
public Node<T> find(int key) {
return null;
}
//插入方法
public void insert(int id, T data) {
//新建一个节点
Node<T> newNode = new Node<>();
newNode.setIndex(id);
newNode.setData(data);
if (null == root) {
root = newNode;
}else {
//从根节点开始查找
Node<T> current = root;
//声明父节点的引用
Node<T> parent;
while (true) {
//父节点的引用指向当前节点
parent = current;
//如果角标小于当前节点,插入到左节点
if (id < current.getIndex()) {
current = current.getLeftChild();
//节点为空才进行赋值,否则继续查找
if (null == current) {
parent.setLeftChild(newNode);
return;
}
}else {
//否则插入到右节点
current = current.getRightChild();
if (null == current) {
parent.setRightChild(newNode);
return;
}
}
}
}
}
public Node delete(int id) {
return null;
}
}
ThreeMap
是一个红黑树 复杂度是O(lgN),性能低于哈希表,但是可以提供有序输出。
每个节点要么是红要么是黑,根永远是黑,叶子永远是黑,红色节点的子节点是黑,到每个子树的叶子节点经过的黑色节点一致。
11.线程安全
CAS
compare and swap 自旋锁 比较和交换
过程是 进行操作前获取内存中的值,进行操作,再取内存的值和本地的值比较相同则更新,否则不更新。
ABA问题 是A 被修改为B 然后修改为A 单从值上无法看出被修改了。解决是加上版本号
lock cmpxchg 指令
如何保证线程安全
尽量减少资源共享,尽量将一个客的计算工作放在一个线程。
线程的状态
创建 :创建一个线程实例 Thread thread = new Thread();
就绪:在调用start()方法后,线程获取了除CPU的其他资源,处于就绪状态
运行:线程获取CPU使用权,run方法开始执行
阻塞:运行中的线程由于其他原因放弃对CPU使用(其他线程抢占)而处于阻塞状态:
-
等待阻塞:调用wait()方法,该线程释放所有资源,包括CPU()资源和锁资源,并且释放锁标志,jvm会把该线程放入等待池,不会自动唤醒,要等待其他线程的notify()或notifyAll()唤醒该线程才会重新获得锁标志并且出入就绪态
-
同步阻塞:由于线程获取同步锁synchronized失败而处于阻塞状态
-
其他阻塞:sleep()方法或join()方法,该类型阻塞会自动唤醒,sleep()超时,join()等待子线程完成后线程会自动唤醒而处于就绪状态,该状态不会释放锁资源,但会释放CPU()资源,会暂时放弃对CPU的占有,进入锁池。
死亡:线程执行完run方法或退出run方法就进入了死亡状态
线程池
存放线程的容器,需要的时候从线程池获取不需要创建,使用完毕返回线程池不需要注销,从而减少创建和销毁线程的开销。
线程同步与异步
同步就是阻塞式操作,异步是非阻塞式操作,同步程序调用一个方法当完成后才能执行下一步,但是异步并不需要等待返回。
sleep和yield的区别和wait
- sleep执行后进入阻塞态,yeild执行后进入就绪态
- sleep执行后抛出InterruptedException,yield没有任何异常
- sleep比yeild有更好移植性
- sleep 后给所有线程执行机会,yeild后只给和当前优先级一样或更高的线程机会
- sleep 不放弃对象锁,过时之后自动恢复,wait释放对象锁,只有当针对此对象发送notify后线程才会进入对象锁定池准备获取对象锁
| 是否释放锁 | 是否有异常抛出 | 解释 | 所属类 | |
|---|---|---|---|---|
| sleep | 否 | 是 | 休眠 | thread |
| yield | 否 | 否 | 退让,让高优先级开始执行 | thread |
| wait | 是 | 否 | Object |
java线程创建
- 一种方法是继承Thread 类 重写run()方法
- 一个实现Runnable接口 重写run()方法
- Callable和Future创建线程:实现接口Callable重写call作为线程执行体且有返回值,使用FutureTask对象封装callable对象call返回值。将FutureTask对象作为Thread对象的目标启动新线程,可以使用get后获得返回值
start启动线程
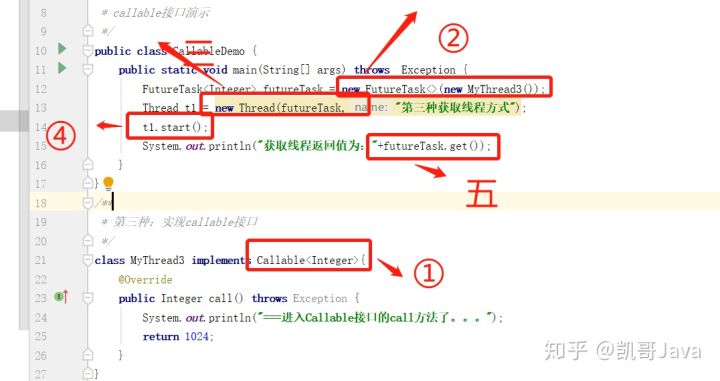
同步方法和同步代码块
同步方法的对象锁默认是this或者当前类class对象,而同步代码块可以选择加什么锁,具有更细的粒度,可以选择只同步部分代码。
java 的线程池
- newFixedThreadPool创建一个指定工作线程数量的线程池
- newCachedThreadPool创建一个可缓存的线程池。
- newSingleThreadExecutor创建一个单线程化的Executor,
- newScheduleThreadPool创建一个定长的线程池,而且支持定时的以及周期性的任务执行,类似于Timer
synchronized和volatile
- synchronized关键字会以当前实例对象作为锁对象,对线程进行锁定 synchronized则可以使用在变量、方法、和类级别的 会造成线程阻塞
- volatile关键字主要用来修饰变量对变量进行读写同步
synchronized和Lock
| 类别 | synchronized | Lock |
|---|---|---|
| 存在层次 | Java的关键字,在jvm层面上 | 是一个接口 |
| 锁的释放 | 1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常,jvm会让线程释放锁 | 在finally中必须释放锁,不然容易造成线程死锁 |
| 锁的获取 | 假设A线程获得锁,B线程等待。如果A线程阻塞,B线程会一直等待 | 分情况而定,Lock有多个锁获取的方式,具体下面会说道,大致就是可以尝试获得锁,线程可以不用一直等待 |
| 锁状态 | 无法判断 | 可以判断 |
| 锁类型 | 可重入 不可中断 非公平 | 可重入 可判断 可公平(两者皆可) |
| 性能 | 少量同步 | 大量同步 |
如何避免死锁
破坏死锁的产生条件:
破坏请求和保存
破坏不可抢占条件,难以实现
破坏循环等待
公平锁 和不公平锁
公平锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
- 优点:所有的线程都能得到资源,不会饿死在队列中。
- 缺点:吞吐量会下降很多,队列里面除了第一个线程,其他的线程都会阻塞,cpu唤醒阻塞线程的开销会很大。
非公平锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。只要CAS设置同步状态成功
- 优点:可以减少CPU唤醒线程的开销,整体的吞吐效率会高点,CPU也不必取唤醒所有线程,会减少唤起线程的数量。
- 缺点:你们可能也发现了,这样可能导致队列中间的线程一直获取不到锁或者长时间获取不到锁,导致饿死。
11.JVM
内存模型:
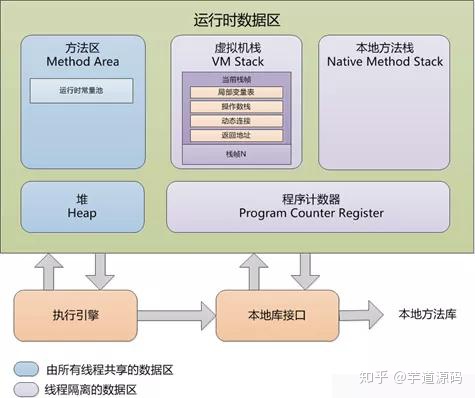
- 方法区:储存已经被虚拟机加载的类信息、常量、静态变量,即时编译后的代码数据
- 本地方法栈:调用本地native的内存模型
- 堆:Java对象存储的地方,所有线程共享区域,存放new生成的对象和数组,是垃圾回收器管理的内存区域,因此被称为"GC堆"
- 程序计数器:指向当前线程正在执行的字节码指令
- 虚拟机栈:执行方法的内存模型,当方法执行时,创建一个栈帧,入栈,执行返回或者抛出异常时出栈。
GC
GC中如何判断对象是否需要回收
java 垃圾回收采用可达性分析的方式,以roots为起点进行搜索,搜索路径称为‘‘引用链’’,当一个对象要是没有任何引用链与roots连接,这个对象不可达,两次不可达标记后就会成为可回收对象。然后要看finalize方法有没有与引用链上的对象关联,有关联 则自救成功,否则二次标记,就可以称为可回收垃圾了。
Roots对象
- 虚拟机栈中引用的对象
- 方法区中类静态属性引用的对象
- 本地方法栈引用的对象
java会出现内存泄露吗
主要分两种内存泄漏
- 不再需要的对象引用
- 未释放的系统资源·
造成不需要的对象引用的,一般是短生命对象使用长生命周期对象;比如在一个方法中创建object对象,我希望他的生命周期是这个方法执行期间,但是object一直不释放。需要我们手动变为null
系统资源不能释放,是这种连接,使用后不关闭导致的
12.IO和NIO和AIO
java有几种类型的流
- 字节流 Inputstream OutPutStream
- 字符流 InputStreamReader OutputStreamWriter
BiO
阻塞型IO:客户端有请求时,服务器端就开启一个线程进行处理,
NIO
非阻塞型IO 客户端发送的请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动线程处理
AIO
NIO 2
13.反射
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制
获取class对象的方式:
- Class.forName(“全类名”):将字节码加载进内存,返回Class对象
Class classobj2 = Class.forName("fanshe.Student");
System.out.println(classobj2.getName());
- 类名.class:通过类名的属性class获取
Class classobj3 = Student.class;
System.out.println(classobj3.getName());
- 对象.getCLass():获取
Student stu = new Student();
Class classobj1 = stu.getClass();
System.out.println(classobj1.getName());
14.java 异常
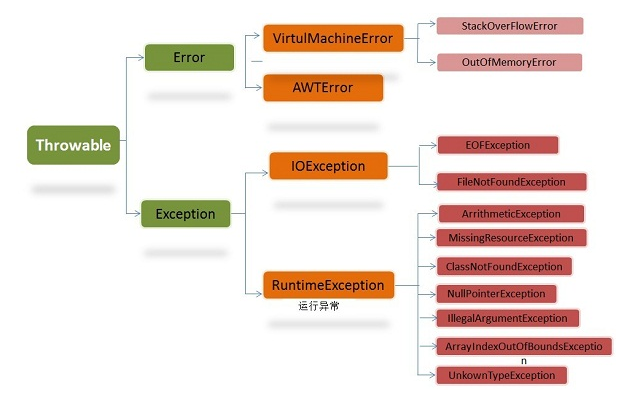
按照严重程度分为两种
1.Error(错误)
硬件或者操作系统的错误。致命错误。栈溢出或者内存溢出
2.Exception(异常)
-
Io异常 编译异常
-
RuntimeException 运行异常
- 空指针
- 下标越界
- 数组存储异常
- 类转换异常
3.异常处理的顺序
一般顺序 try -->catch–>finally
当有return时
情况1.
try {
return i;
}finally{
i++;
}
当 return i 返回常量时,finally 无法对i进行修改
情况2.
try {
return Obj;
}finally{
System.out.println("finally模块被执行");
obj = null;
}
当 return Obj返回引用类型时,finally 对引用类型进行修改
情况3.
try {
int a = 8/0;
return 1;
}catch (Exception e) {
return 2;
}finally{
System.out.println("finally模块被执行");
return 0;
}
当 finally也有 return 时 只返回finally的值
Spring Boot
1.事务
1.1编程式事务:
TransactionTemplate:
-
TransactionCallback
-
TranactionCallbackWithoutResult
public class SimpleService implements Service {
//在这个实例中的所有方法中共享一个TransactionTemplate
private final TransactionTemplate transactionTemplate;
//使用构造函数注入来提供PlatformTransactionManager
public SimpleService(PlatformTransactionManager transactionManager) {
this.transactionTemplate = new TransactionTemplate(transactionManager);
// 事务设置在这
//传播模式
this.transactionTemplate.setIsolationLevel(TransactionDefinition.ISOLATION_READ_UNCOMMITTED);
//超时设置
this.transactionTemplate.setTimeout(30); // 30 seconds
// and so forth...
}
public Object someServiceMethod() {
return transactionTemplate.execute(new TransactionCallback() {
// 匿名TransactionCallback 类 重写 doInTransaction 里面是事务内容
public Object doInTransaction(TransactionStatus status) {
try {
updateOperation1();
updateOperation2();
} catch (SomeBusinessException ex) {
// setRollbackOnly 可以回撤事务
status.setRollbackOnly();
}
return resultOfUpdateOperation2();
}
});
//没有回调的方法
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus status) {
try {
updateOperation1();
updateOperation2();
} catch (SomeBusinessException ex) {
status.setRollbackOnly();
}
}
});
}
}
PlatformTransactionManager
- 可以传入TransactionDefinition
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
// 明确设置事务的名是只能通过编程完成的事
def.setName("SomeTxName");
//设置传播行为
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
TransactionStatus status = txManager.getTransaction(def);
try {
// 业务逻辑
}
catch (MyException ex) {
txManager.rollback(status);
throw ex;
}
txManager.commit(status);
1.2声明式事务
1.3并发事务产生的问题
- 事务更新丢失
- 脏读
事务A读到了事务B还没有提交的数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dl4BSfiI-1623914773186)(E:\Desktop\stu\學習筆記\常用面知识.assets\未命名文件 (2)]-1623833646293.png)
- 更新丢失 两个事务同时操作一个数据,若一个事务出现回滚,出现回滚丢失
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zgzk8xp7-1623914773187)(E:\Desktop\stu\學習筆記\常用面知识.assets\未命名文件 (3)]-1623833397771.png)
- 不可重复读 在一个事务里面读取了两次某个数据,读出来的数据不一致
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-McQv7NeL-1623914773187)(E:\Desktop\stu\學習筆記\常用面知识.assets\未命名文件 (4)]-1623833414518.png)
1.4隔离级别
- 读未提交 读取尚未提交的数据
- 读已提交 不允许读尚未提交的数据
- 重复读 在读取的过程中不允许操作
- 串行 单线程的操作事务
2.外部jar包如何引入springboot管理
然后使用@Autowried 若出现冲突可使用 多实现解决方式
写一个配置类
@configuration
public classConfig{
@Bean
Object getObject(){
new CLassname =new classname();
return CLassname;
}
}
3.常用注解和作用
核心注解:
-
@SpringBootApplication
- @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
- @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能:
- @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
- @ComponentScan:Spring组件扫描
-
@AutoWired: 自动注入bean 当加上(required=false)时找不到不报错
-
@Service 用于标注业务层
-
@RestController 控制层
-
@Repository:标注一个dao持久层组件类。
4.接口多实现如何注入
-
按照实现类的类名找
-
@Qualifier
-
@Resource
@Autowired PrsonService personServiceImpl1 //查找personServiceImpl1实现类@Qualifier("personServiceImpl1") @Autowired@Service("Impl") public class personServiceImpl1 implements PersonService{ } @Resource(name="Impl")
5.AOP
基本名称:
Aspect(切面): Aspect 声明类似于 Java 中的类声明,在 Aspect 中会包含着一些 Pointcut 以及相应的 AdviceJoint point(连接点):表示在程序中明确定义的点,典型的包括方法调用,对类成员的访问以及异常处理程序块的执行等等,它自身还可以嵌套其它 joint point。Pointcut(切点):表示一组 joint point,这些 joint point 或是通过逻辑关系组合起来,或是通过通配、正则表达式等方式集中起来,它定义了相应的 Advice 将要发生的地方Advice(通知):Advice 定义了在Pointcut里面定义的程序点具体要做的操作,它通过 before、after 和 around 来区别是在每个 joint point 之前、之后还是代替执行的代码。Target(目标对象):织入Advice的目标对象.。Weaving(织入):将Aspect和其他对象连接起来, 并创建Adviced object 的过程
1.静态代理
//抽象角色:增删改查业务
public interface UserService {
void add();
void delete();
void update();
void query();
}
//真实对象,完成增删改查操作的人
public class UserServiceImpl implements UserService {
public void add() {
System.out.println("增加了一个用户");
}
public void delete() {
System.out.println("删除了一个用户");
}
public void update() {
System.out.println("更新了一个用户");
}
public void query() {
System.out.println("查询了一个用户");
}
}
//代理角色,在这里面增加日志的实现
public class UserServiceProxy implements UserService {
private UserServiceImpl userService;
public void setUserService(UserServiceImpl userService) {
this.userService = userService;
}
public void add() {
log("add");
userService.add();
}
public void delete() {
log("delete");
userService.delete();
}
public void update() {
log("update");
userService.update();
}
public void query() {
log("query");
userService.query();
}
public void log(String msg){
System.out.println("执行了"+msg+"方法");
}
}
2.动态代理
2.1 JDK动态代理
public interface IUserDao {
void find();
void save();
}
public class UserDao implements IUserDao{
@Override
public void find() {
System.out.println("模拟查询");
}
@Override
public void save() {
System.out.println("模拟保存");
}
}
public class Handler implements InvocationHandler{
Object target;
public Handler (){
}
public Handler (Object target){
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String name = method.getName();
before(name);
Object result=method.invoke(target,args);
System.out.println("执行结束");
return result;
}
public void before(String methodName){
System.out.println("开始执行方法");
}
//生成代理类
public Object getProxy(){
return Proxy.newProxyInstance(this.getClass().getClassLoader(),
target.getClass().getInterfaces(),this);
}
}
public class Client3 {
public static void main(String[] args) {
UserDao userdao = new UserDao();
Handler Handler = new Handler(userdao);
UserDao proxy = (UserDao) Handler.getProxy();
proxy.find();
}
}
linux
vi 编辑器
数据库
1前端
scoped 如何实现单页面修改不污染全局
scoped会在元素上添加唯一的属性(data-v-x形式),css编译后也会加上属性选择器,从而达到限制作用域的目的。
vue 父子组件通信
父传子prop 即可实现
子传父
子组件使用$emit(function,data) 父组件监听function,v-on=‘function’
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









