







文章目录
Oracle数据库体系结构简介
Oracle实例:是存在于物理内存上的一种数据结构,用来管理和访问Oracle数据库,由系统提供的多个后台进程和一个共享内存池组成,共享的内存池可以被所有进程访问
实际上oracle实例也就是平常所说的数据库服务
区别:实例可以操作任何数据库,任何时刻一个实例只能关联一个数据库;但是一个数据库可以被多个实例同时操作【RAC】
在双十一:同款商品可以被多个用户访问;单个用户只能操作一件商品
-- 插入 sql 文件
@d:/del_data.sql;
@d:/hr_cre.sql;
@d:/hr_popul.sql;
SQL语句主要分为三大类
| 种类 | 含义 |
|---|---|
| DML(Data Manipulation Language) | 数据库操纵语言:修改和查询数据记录INSERT,DELETE,UPDATE,SELECT |
| DDL(Data Manipulation Language) | 数据库定义语言:定义数据库的结构,创建,修改和删除CREATE TABLE,CREATE INDEX,DROP TABLE,DROP INDEX,ALTER TABLE(修改表结构,添加、删除和修改列长度) |
| DCL(Data Control Language) | 数据库控制语言:用来控制数据库的访问,GRANT授权,REVOKE撤销授权,COMMIT提交事务,ROLLBACK事务回退,SAVEPOINT设置保存点,LOCK锁定特定部分数据库 |
补充SQL初步
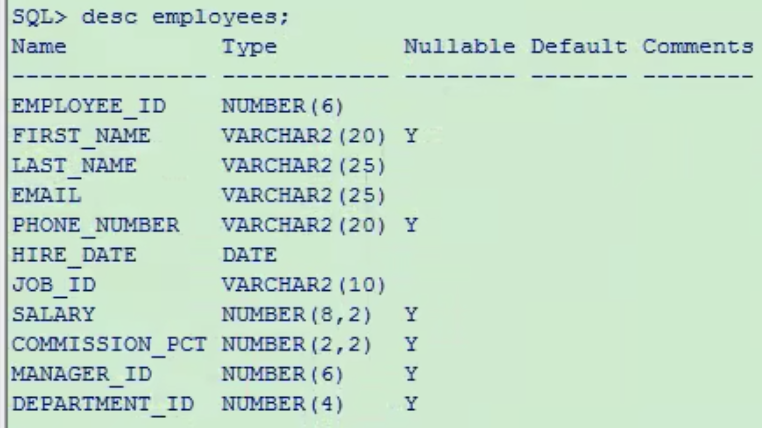
--查询表结构
desc employees;
算术运算符作用于时间(时间只能加减不能乘除)和数字
--查询前天,今天和明天日期
select sysdate-1, sysdate, sysdate+1
from dual;
NULL值:无效,为指定的值(并不是空格或者0)。凡是NULL值参与了运算,结果都是NULL
导入sql文件
@d:/xxx.sql
别名
--别名使用双引号,字符串是单引号
SELECT sysdate-1 AS "昨天", sysdate AS "今天", sysdate+1 AS "明天"
FROM dual
需要注意的是oracle中字符串是单引号,别名用的是双引号
连接符
和MySQL的 CONCAT(str1, str2)不同的是把列于列,列与字符连接在一起用 || 表示合成列
--oracle中拼接字符串时 "||"
SELECT EMPLOYEE_NAME || '`s ID is:' || EMPLOYEE_ID
FROM employee
distinct去重的坑
--查询出的字段需要数量上相对
SELECT last_name, distinct(department_id)
FROM employee
报错原因是 last_name 需要和 去重后的部门ID 数量相对应,否则就是表达式缺失
过滤和排序数据
WHERE子句紧跟随在FROM后边
日期格式
- 字符和日期要包含在单引号中
- 字符大小写敏感,日期格式敏感
- 默认的日期格式是 DD-MON月-RR
--查询的日期格式
SELECT last_name, hire_date FROM employees WHERE hire_date = '7-6-1994'
--查询出的hire_date字段数据格式:1994/6/7 星期
SELECT last_name, hire_date FROM employees WHERE to_char(hire_date, 'yyyy-mm-dd') = '1994-06-07'
比较运算
| 操作符 | 含义 |
|---|---|
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| >= | 大于等于 |
| > | 大于 |
| != | 不等于,也可以是<> |
其它比较运算符
| 操作符 | 含义 |
|---|---|
| BETWEEN…AND… | 闭区间内的值 |
| INT(SET) | 等于值列表中的一个 |
| LIKE | 模糊查询 |
| IS NULL | 空值 |
| IS NOT NULL | 非空值 |
--模糊查询过程中转义字符问题:查询名字中含有"_"的员工
SELECT last_name, department_id, salary
FROM employees
WHERE last_name LIKE '%\_%a' EXCAPE ('\')
逻辑运算
| 操作符 | 含义 |
|---|---|
| AND | 并 |
| OR | 或 |
| NOT | 否 |
优先级
| 优先级 | |
|---|---|
| 1 | 算术运算符 |
| 2 | 连接运算符 |
| 3 | 比较运算符 |
| 4 | IS [NOT] NULL,IN,LIKE |
| 5 | [NOT] BETWEEN…AND… |
| 6 | NOT |
| 7 | AND |
| 8 | OR |
排序
- 默认生升序asc,降序desc
- 一级排序相同则会自动跳到二级排序
单行函数
SQL中不同类型的函数
单行函数
字符

大小写控制函数
--小写和大写
SELECT LOWER('hand-china.COM') AS "LOWER小写", UPPER('hand-china.COM') AS "UPPER大写", INITCAP('hand-china.COM') AS "INITCAP大驼峰"
FROM dual
字符控制函数
| 函数 | 结果 |
|---|---|
| CONCAT(‘Hello’, ‘World’) | HelloWorld |
| SUBSTR(‘HelloWorld’, 2, 4) | ello |
| LENGTH(‘HelloWorld’) | 10 |
| INSTR(‘HelloWorld’, ‘W’) | 6 |
| LPAD(salary, 10, ‘*’) | ******7500 |
| RPAD(salary, 10, ‘*’) | 7500****** |
| TRIM(‘H’ FROM ‘HelloHWorldH’) | elloHWOrld |
| REPLACE(‘abcdab’, ‘b’, ‘m’) | amcdam |
数值

--日期或者数字进行截断
SELECT TRUNC(435.45, 1), TRUNC(435.45), TRUNC(435.45, -1)
435.4 435 430
日期
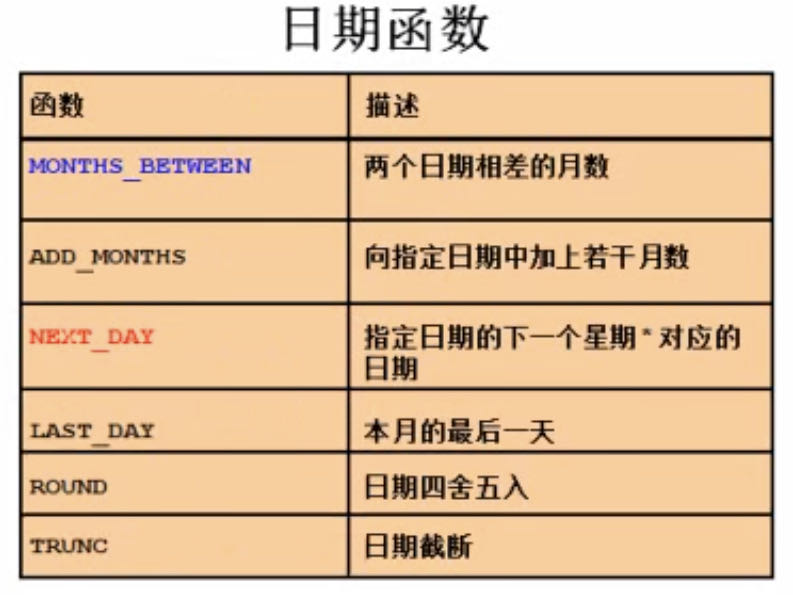
--两个日期之间相差的天数
SELECT "title", "level", SYSDATE-"create_time" AS "WorkedDays" FROM cxf_44569;
--两个日期之间相差的月数
SELECT "title", "level", (SYSDATE-"create_time")/30 AS "WorkedDays1", MONTHS_BETWEEN(SYSDATE, "create_time") AS "WOrkedDays2" FROM cxf_44569;
--指定月数加上月数,指定日期下一个星期对应的日期
SELECT ADD_MONTHS(SYSDATE, 2), ADD_MONTHS(SYSDATE, -3), NEXT_DAY(SYSDATE, '星期六') FROM dual;
--每个月的倒数第二天创建的题目信息
SELECT * FROM cxf_44569 WHERE "create_time" = LAST_DAY("create_time")-1;
--日期的四舍五入和截断
SELECT SYSDATE, ROUND(SYSDATE, 'MONTH'), ROUND(SYSDATE, 'MM'), TRUNC(SYSDATE, 'HH') FROM dual;
转换

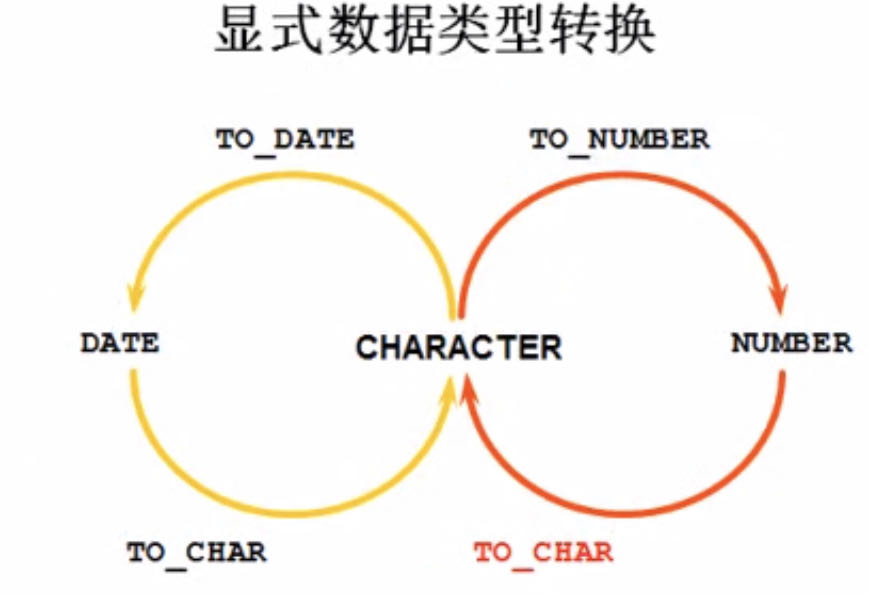
TO_CHAR 和 TO_DATE
--日期转字符串
SELECT "title", TO_CHAR("create_time", 'yyyy"年"mm"月"dd"日"')
FROM cxf_44569
WHERE '2023年08月30日' != TO_CHAR("create_time", 'yyyy"年"mm"月"dd"日"')
--字符串转日期
SELECT "title", TO_CHAR("create_time", 'yyyy"年"mm"月"dd"日"')
FROM cxf_44569
WHERE "create_time" != TO_DATE('2023年08月31日', 'yyyy"年"mm"月"dd"日"')
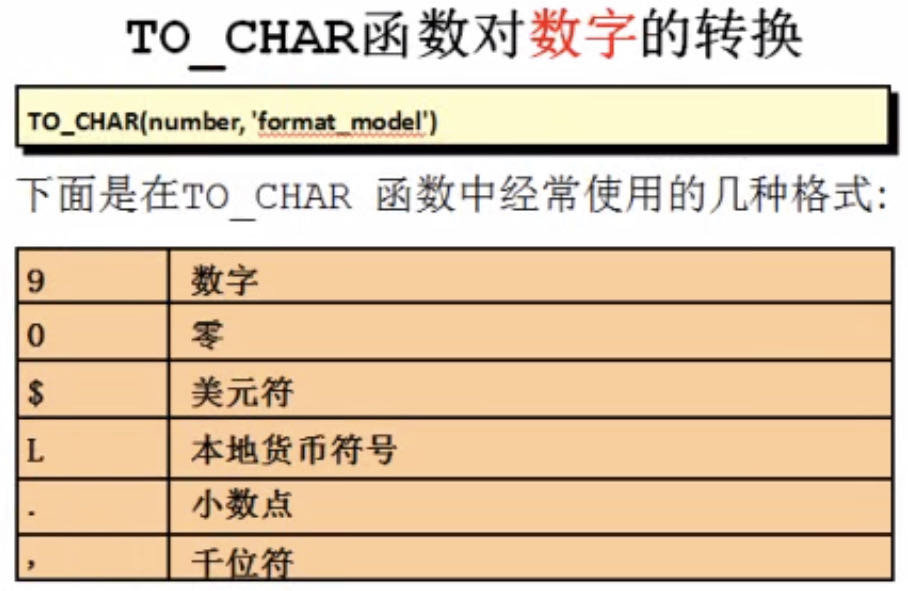
TO_CHAR 和 TO_NUMBER


--按照数据本地货币格式查询
SELECT TO_NUMBER('¥001,234,567.89', 'L000,000,999.99')
FROM dual

货币类型符号需要相对应
通用
适用于任何数据类型,同时也适用于空值
- NVL(expr1, expr2):expr1为NULL,则返回expr2
- NVL2(expr1, expr2, expr3):expr1不为NULL则返回expr2;否则返回expr3
- NULLIF(expr1, expr2):如果expr1和expr2相等,则返回NULL;否则返回expr1
- COALESCE(expr1, expr2, …exprN):如果第一个表达式为NULL则返回第二个;如果第二个还为NULL,则返回第三个
--NUL查询奖金提成后的工资
SELECT employee_id, last_name, salary*12(1+NVL(commission_pct, 0)) FROM employees
使用条件表达式

--CASE xxx WHEN xxx END
SELECT employee_id,
last_name,
department_id,
(CASE department_id
WHEN 10 THEN salary * 1.1
WHEN 20 THEN salary * 1.2
ELSE salary * 1.3 END
) AS "New_Salary"
FROM employees
WHERE department_id IN (10, 20, 30)
--DECODE()
SELECT employee_id,
last_name,
department_id,
DECODE(
department_id,
10, salary * 1.1,
20, salary * 1.2,
30, salary * 1.3
) AS "NewSalary"
FROM employees
WHERE department_id IN (10, 20, 30)
嵌套查询
- 单行函数可以嵌套查询
- 嵌套函数的执行顺序是先内后外
多表查询
等值连接
两个表中的数据有有交集
--查询员工信息,部门信息,地址信息
SELECT e.employee_id, e.last_name, e.department_id, d.department_id, d.location_id, l.city
FROM employees e, departments d, locations l
WHERE e.department_id = d.department_id
AND d.location_id = l.location_id
非等值连接
两个表中的数据互不交集
--查询运功信息和工作信息【两个表没有关联关系】
SELECT e.employee_id, e.last_name, e.salary, j.grade_level
FROM employees e, job_grades j
WHERE e.salary BETWEEN j.lowest_sal
AND j.highest_sal
左外连接
--查询员工信息和部门信息
SELECT e.last_name, e.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id(+)
--查询员工信息和部门信息
SELECT e.last_name, e.department_id, d.department_name
FROM employees e LEFT OUTER JOIN departments d
WHERE e.department_id = d.department_id
满外连接
-- 有个员工没有部门ID,但满外连接也会把该员显示出来
SELECT e.last_name, e.department_id, d.department_name
FROM employees e FULL JOIN departments d
WHERE e.department_id = d.department_id
自连接
--查询员工及员工老板的信息
SELECT emp.last_name, manaer.last_name, manager.salary, manager.email
FROM employee emp, employee manager
WHERE emp.manager_id = manager.employee_id
AND TO_CHAR(emp.last_name) = 'chen'
聚合分组函数
SUM,AVG,MIN,MAX在统计字段的时候自动会舍去NULL值
--查询各个部门不同岗位的平均工资
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id, job_id
--查询各部门平均工资大于6k的部门和部门平均工资
SELECT department_id, avg(salary)
FROM employees
GROUP BY department_id
HAVING AVG(salary) > 6000
- 如果要使用
WHERE的话,需要紧跟FROM之后- 包含在
SELECT中的一定要出现在GROUP BY之后;出现在GROUP BY之后的不一定需要出现在SELECT中WHERE中不能使用聚合函数;HAVING中可以使用聚合函数
子查询
--查询job_id与141号员工相同,但salary比143号员工多的员工信息
SELECT last_name, employee_id, salary
FROM employeee
WHERE job_id = (SELECT job_id FROM employee WHERE employee_id = 141) AND salary > (SELECT salary FROM employee FROM employee WHERE employee_id = 143)
--查询部门中工资比本部门平均工资高的员工号,姓名和工资
SELECT employee_id, last_name, salary
FROM employee e1
WHERE salary > (
SELECT AVG(salary)
FROM employee e2
WHERE e1.employee_id = e2.employee_id
GROUP BY department_id
)
创建和管理表

--查询用户定义的表
SELECT * FROM user_tables
SELECT table_name FROM user_tables
--查询用户定义的数据对象
SELECT * FROM user_objects
SELECT DISTINCT object_type FROM user_objects
--查询用户定义的表,视图,同义词和序列
SELECT * FROM user_catalog
创建表
--白手起家
CREATE TABLE emp1 ( id NUMBER ( 10 ), name VARCHAR2 ( 25 ), hire_date TIMESTAMP, salary NUMBER ( 10, 2 ) )
--复制表结构+数据
CREATE TABLE emp2 AS SELECT
id,
name AS "n a m e",
hire_date,
salary
FROM
emp1;
--复制表结构
CREATE TABLE emp3 AS SELECT
id,
name AS "name",
hire_date,
salary
FROM
emp1
WHERE
1 = 2;
--白手起家
CREATE TABLE emp1 ( id NUMBER ( 10 ), name VARCHAR2 ( 25 ), hire_date TIMESTAMP, salary NUMBER ( 10, 2 ) )
--复制表结构+数据
CREATE TABLE emp2 AS SELECT
id,
name AS "n a m e",
hire_date,
salary
FROM
emp1;
--复制表结构
CREATE TABLE emp3 AS SELECT
id,
name AS "name",
hire_date,
salary
FROM
emp1
WHERE
1 = 2;
--新增一字段
ALTER TABLE emp1 ADD ( email VARCHAR ( 20 ) DEFAULT '无' );
--修改一个字段
ALTER TABLE emp1 MODIFY ( id NUMBER ( 15 ) );
--删除一个列
ALTER TABLE emp1 DROP email;
--重命名一个列
ALTER TABLE emp1 RENAME COLUMN sal TO "s a l";
--删除一个表
DROP TABLE emp3;
--清空表数据,但表结构还在【增删改可以回滚:DELETE可以回滚】
TRUNCATE TABLE emp2;
DELETE FROM emp2;
--修改表名
RENAME emp2 TO employees2;
数据处理
--插入一条数据
INSERT INTO emp1 ( id, name, hire_date, sal )
VALUES
( 10001, '张三', SYSDATE, 10000 );
--从其它地方拷贝数据进行复制【不用 VALUES但需要子查询中的值列表与 INSERT 子句中的列表对应】
INSERT INTO emp1 ( id, name, hire_date, sal ) SELECT
id + 1,
name,
hire_date,
sal
FROM
emp1;
--批量插入
BEGIN
FOR i IN 1 .. 50 LOOP
INSERT INTO cxf_44569("id", "title", "level", "type") VALUES (i, '标题'||i, TO_CHAR(i), 'oracle');
END LOOP;
END;
--更改数据:修改114号员工的工作和工资和205号员工相等
UPDATE emp1
SET job_id = ( SELECT job_id FROM emp1 WHERE employee_id = 205 )
AND salary = ( SELECT salary FROM emp1 WHERE employee_id = 205 )
WHERE
employee_id = 114;
--删除部门名称含有Public字符的部门ID
DELETE
FROM
emp1
WHERE
department_id = ( SELECT department_id FROM emp1 WHERE department_name LIKE '%Public%' );
--控制事务
DELETE FROM emp1 WHERE id = 1;
SAVEPOINT A;
DELETE FROM emp1 WHERE id=2;
SAVEPOINT B;
ROLLBACK TO SAVEPOINT A;
ROLLBACK;
约束

NOT NULL
CREATE TABLE emp
(
id NUMBER ( 10 ) CONSTRAINT emp_id_pk PRIMARY KEY,
name VARCHAR2 ( 20 ) CONSTRAINT emp_name_nn NOT NULL,
salary NUMBER ( 10, 2 ),
email VARCHAR2(20),
CONSTRAINT emp_email_uk UNIQUE(email)
);
列约束和表约束
CREATE TABLE emp2
(
--列级约束
id NUMBER ( 10 ) CONSTRAINT emp2_id_pk FPRIMARY KEY,
name VARCHAR2 ( 20 ) CONSTRAINT emp2_name_nn NOT NULL,
salary NUMBER ( 10, 2 ) CONSTRAINT emp2_salary_ CHECK ( salary > 1500 AND salary < 30000 ) NOT NULL,
email VARCHAR ( 20 ),
deparment_id NUMBER ( 10 )
--表级约束
CONSTRAINT emp2_email_uk UNIQUE ( email )
--唯一约束
--主键约束
-- CONSTRAINT emp2_id_pk FPRIMARY KEY(id),
--外键约束
CONSTRAINT emp2_dept_id_fk FOREIGN KEY ( department_id ) REFERENCES departments ( department_id ) ON DELETE CASCADE --级联删除
-- CONSTRAINT emp2_dept_id_fk FOREIGN KEY(department_id) REFERENCES departments(department_id) ON DELETE SET NULL--级联置空
);
- 对于 UNIQUE 的NOT NULL约束,则允许插入的数据为NULL不会违反唯一值约束
- 对于 NOT NULL 只能添加在列级上
在创建表级外键约束的时候需要添加上 FOREIGN KEY 关键字
--列级约束
department NUMBER(10) CONSTRAINT emp2_dpt_id_fk REFERENCES dpt2(department_id)
--表级约束
CONSTRAINT FOREIGN KEY emp2_dpt_id_fk REFERENCES dpt2(department_id)
添加或删除约束
--NULL约束只能用MODIFY修改
ALTER TABLE emp2 MODIFY(sal NUMBER(10,2, NOT NULL));
--删除一个约束
ALTER TABLE emp2 DROP CONSTRAINT emp2_name_uk;
--添加一个约束【添加之前需要把符合当前数据】
ALTER TABLE emp2 ADD CONSTRAINT emp2_name_uk UNIQUE(name);
--无效化一个约束
ALTER TABLE emp2 DISABLE CONSTRAINT emp2_nmae_uk;
--有效化一个约束
ALTER TABLE emp2 ENABLE CONSTRAINT emp2_name_uk;
--查询约束
SELECT constraint_name, constraint_type, search_condition FROM user_constraints WHERE table_name = 'emp2';
--查询定义约束的列
SELECT constraint_name, column_name FROM user_cons_columns WHERE table_name = 'emp2';
视图
视图基础
--创建数据库
CREATE TABLE emp
(
id NUMBER ( 10 ) CONSTRAINT emp_id_pk PRIMARY KEY,
name VARCHAR2 ( 20 ) CONSTRAINT emp_name_nn NOT NULL,
salary NUMBER ( 10, 2 ),
email VARCHAR2(30),
CONSTRAINT emp_email_uk UNIQUE(email)
);
--插入数据
INSERT INTO emp ( id, name, salary, email ) VALUES ( 1, '张三', 6000, 'zhangsan@qq.com' );
INSERT INTO emp ( id, name, salary, email ) VALUES ( 2, '李四', 7500, 'lisi@qq.com' );
INSERT INTO emp ( id, name, salary, email ) VALUES ( 3, '王五', 9000, 'wangwu@qq.com' );
INSERT INTO emp ( id, name, salary, email ) VALUES ( 4, '老六', 4500, 'laoliu@qq.com' );
INSERT INTO emp ( id, name, salary, email ) VALUES ( 5, '小七', 5500, 'xiaoqi@qq.com' );
INSERT INTO emp ( id, name, salary, email ) VALUES ( 6, '甲', 3500, 'jia@qq.com' );
INSERT INTO emp ( id, name, salary, email ) VALUES ( 7, '乙', 6500, 'yi@qq.com' );
INSERT INTO emp ( id, name, salary, email ) VALUES ( 8, '丙', 9500, 'bing@qq.com' );
INSERT INTO emp ( id, name, salary, email ) VALUES ( 9, '丁', 3500, 'ding@qq.com' );
INSERT INTO emp ( id, name, salary, email ) VALUES ( 10, '戊', 1500, 'wu@qq.com' );
INSERT INTO emp ( id, name, salary, email ) VALUES ( 11, '戎', 2500, 'rong@qq.com' );
--创建视图
CREATE VIEW emp_view AS
SELECT id, name, salary, email FROM emp;
--查询视图
SELECT * FROM emp_view;
--查询视图
SELECT * FROM emp_view;
--查询表【发现此时视图已经修改了表数据】
SELECT * FROM emp;
--还可以给视图字段更换别名
CREATE VIEW emp_view1 AS
SELECT id AS "ID", name AS "名称", salary AS "薪资", email AS "邮箱" FROM emp;
--修改视图
CREATE OR REPLACE VIEW emp_view1 AS
SELECT id AS "ID", name AS "名称", salary AS "薪资", email AS "邮箱" FROM emp;
--创建只读视图【此时就无法修改视图】
CREATE
OR REPLACE VIEW emp_view1 AS SELECT
id AS "ID",
name AS "名称",
salary AS "薪资",
email AS "邮箱"
FROM
emp WITH READ ONLY;
--删除视图
DROP VIEW emp_view1;
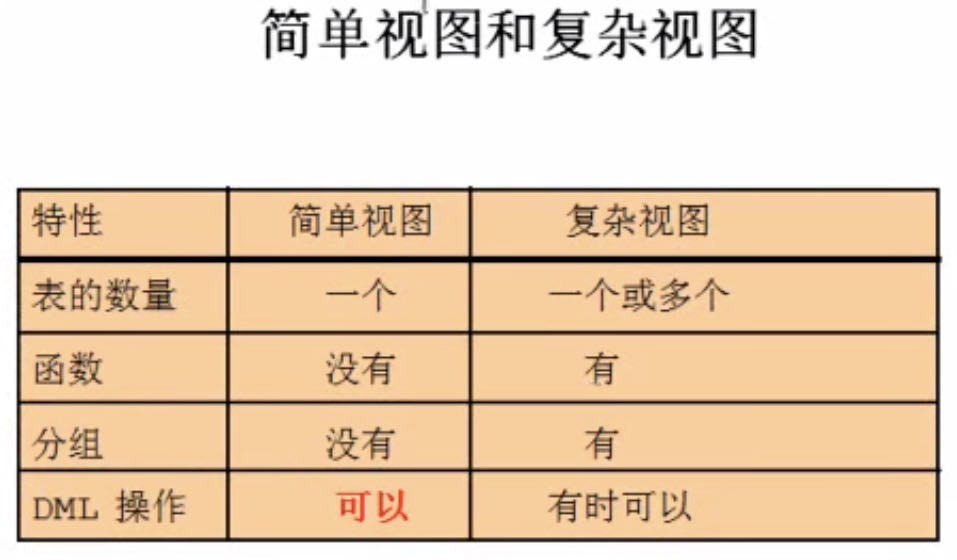
- 创建视图过程中使用了分组函数就是复杂视图
- 复杂视图的 DML 无法进行操作
Top-N分析
SELECT ROWNUM, name, salary FROM
(SELECT name, salary FROM emp ORDER BY salary DESC)
WHERE ROWNUM <= 3;

对 ROWNUM 只能使用 “<” 或 “<=”,而用 “=”,“>”,“>=” 都将不能返回任何数据
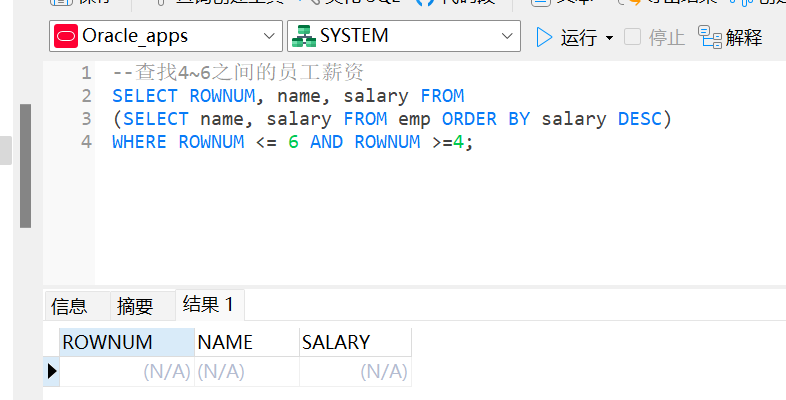
--查找4~6之间的员工薪资
SELECT ROWNUM, name, salary FROM
(SELECT name, salary FROM emp ORDER BY salary DESC)
WHERE ROWNUM <= 6 AND ROWNUM >=4;
--查找4~6之间的员工薪资
SELECT rn, name, salary
FROM
( SELECT ROWNUM AS rn, name, salary
FROM
(
SELECT name, salary FROM emp ORDER BY salary DESC
)
)
WHERE rn >= 4 AND rn <= 6;
其它数据对象

序列

--创建序列
CREATE SEQUENCE empseq
INCREMENT BY 1 --每次增长1
START WITH 1 --从1开始增长
MAXVALUE 100 --提供的最大值,NOMAXVALUE无限制
CYCLE --需要循环
CACHE 50; --不需要缓存登录
--使用之前一定要先获取下一个值【迭代器到11为止】
SELECT empseq.nextval FROM dual;
--获取当前值
SELECT empseq.currval FROM dual;
--使用序列
INSERT INTO emp(id, name, salary) VALUES(empseq.nextval, '戌', 1500, 'xu@qq.com');
--修改序列的增量,最大值,最小值,循环选项或是否装入内存
ALTER SEQUENCE empseq
INCREMENT BY 2
MAXVALUE 100
NOCYCLE
NOCACHE
--查看当前有哪些序列
SELECt sequence_name, min_value, max_value, increment_by, last_number FROM user_sequences;
--删除序列
DROP SEQUENCE empseq;
- 修改序列只有后续插入的值才会改变
- 改变序列的初始值只能通过删除序列之后重建序列的方法实现
- 将序列值装入内存可以提高访问效率
- 序列在下列情况下会出现 裂缝
- 回滚
- 系统异常
- 多个表同时使用同一序列
- 如果不将序列的值装入内存(NOCACHE),可使用表 USER_SEQUENCES 查看序列当前的有效值
索引

--删除序列
CREATE INDEX emp_id_index ON emp(id);
什么时候创建索引?
- 列中数据值分布范围很广
- 列经常在 WHERE 子句或连接条件中出现
- 表经常被访问而且数据量很大,访问的数据大概占据数据总量的2%~4%
什么时候不要创建索引
- 表很小
- 表经常更新
- 查询的数据大于2%~4%
- 列不经常作为连接条件或出现在WHERE子句中
索引在查询的时候速度快了,但是插入速度也就慢了
同义词
使用同义词访问相同的对象
- 方便访问其它用户对象
- 缩短对象名字长度
--添加同义词
--添加同义词
CREATE SYNONYM e FOR emp;
SELECT * FROM e;
--删除同义词
DROP SYNONYM e;
控制用户权限及练习
授权
- 数据库安全性
- 系统安全性
- 数据安全性
- 系统权限:对于数据库的权限
- 对象权限:操作数据库对象的权限
以下创建用户和赋予权限都是利用 SYSTEM 用户创建 cvter 用户
--创建用户【用户是cvter并不是C##cvter,因为oracle官网说明了创建用户之前需要加C##或者c##】
CREATE USER C##cvter IDENTIFIED BY qwe123
--修改密码
ALTER USER C##cvter IDENTIFIED BY ewq321;
创建用户之后应该赋予权限
- 创建会话:CREATE SESSION
- 创建表:CREATE TABLE
- 创建视图:CREATE VIEW
- 创建序列:CREATE SEQUENCE
- 创建过程:CREATE PROCEDURE
--赋予权限
GRANT CREATE SESSION TO C##cvter;--远程登陆数据库权限
GRANT CREATE TABLE TO C##cvter;
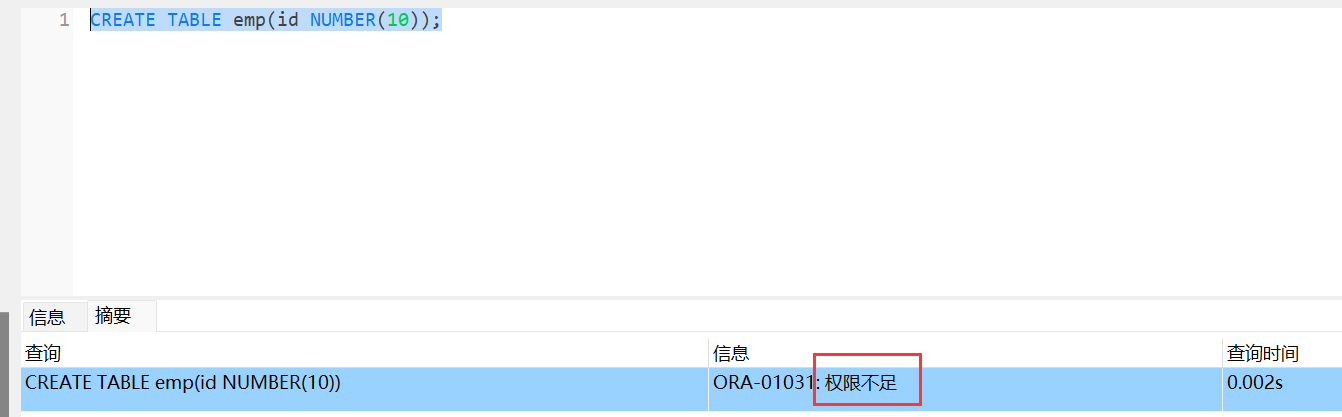
创建用户表空间
用户拥有 CREATE TABLE 权限之外还需要发呢配相应的表空间才可以开辟存储空间用于创建表
--创建用户表空间
ALTER USER C##cvter QUOTA UNLIMITED ON users;--无限制表空间大小
ALTER USER C##cvter QUOTA 5M ON users;--限制表空间大小为5MB
创建角色并赋予权限
--创建角色
CREATE ROLE C##my_role;
GRANT CREATE SESSION, CREATE TABLE, CREATE VIEW TO C##my_role;
CREATE USER C##cvter02 IDENTIFIED BY qwe123;
GRANT C##my_role TO C##cvter02;
对象授权
还需要对新建的用户开放 system.emp 的 select和update 权限而其它权限无法使用
--对象权限
GRANT select, update ON system.emp TO C##cvter;
--其它权限无法使用
DROP TABLE system.emp;
WITH GRANT OPTION 和 PUBLIC 关键字
--WITH GRANT OPTION 使用户同样具有分配权限的权利
GRANT select, update ON system.emp TO C##cvter WITH GRANT OPTION;
--向数据库中所有用户分配权限
GRANT select ON system.emp TO PUBLIC;
收回对象权限
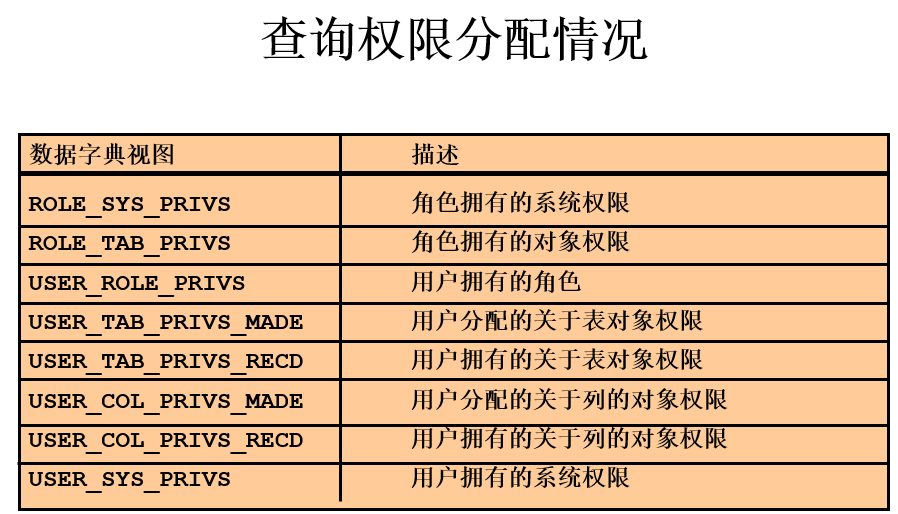
--查询用户拥有的权限
SELECT * FROM user_tab_privs_recd;
--收回cvter的select和update权限
REVOKE select, update ON system.emp FROM C##cvter;
SET集合运算符

查询的数据列数和数据类型应该精准对应
UNION ALL 会返回全部的集合。而UNION会返回去重后的集合
高级子查询
多列子查询
--查询与141号或174号员工的manager_id和department_id相同的其他员工的employee_id, manager_id, department_id
SELECT
employee_id,
manager_id,
department_id
FROM
employees
WHERE
(manager_id, department_id) IN ( SELECT manager_id, department_id FROM employees WHERE employee_id IN ( 141, 174 ) )
AND employee_id NOT IN ( 141, 174 );
在FROM 子句中使用子查询
--返回比本部门平均工资高的员工的last_name, department_id, salary及平均工资
SELECT last_name, department_id, salary, (SELECT AVG(salary) FROM employees e3 WHERE e1.department_id = e3.department_id GROUP BY department_id)
FROM employees e1
WHERE salary >
(SELECT AVG(salary) FROM employees e2 WHERE e1.department_id = e2.department_id GROUP BY department_id);
SEELCT last_name, e1.department_id, e2.avg_sal ) FROM employees e1, (SELECT department_id, AVG(salary) avg_sal FROM employees GROUP BY department_id) e2 WHERE e1.department_id = e2.department_id;
在 SQL 中使用单列子查询
--显式员工的employee_id,last_name和location。其中,若员工department_id与location_id为1800的department_id相同,则location为’Canada’,其余则为’USA’
SELECT employee_id, last_name,
( CASE department_id WHEN ( SELECT department_id FROM departments WHERE location_id = 1800 ) THEN 'Canada' ELSE 'USA' END ) location
FROM
employees;
--查询员工的employee_id,last_name,要求按照员工的department_name排序
SELECT employee_id, last_name
FROM employees e
ORDER BY (SELECT department_name FROM departments d WHERE e.department_id = d.department_id);
相关子查询

--若employees表中employee_id与job_history表中employee_id相同的数目不小于2,输出这些相同id的员工的employee_id,last_name和其job_id
SELECT employee_id, last_name, job_id
FROM employees e1
WHERE 2 <= (
SELECT COUNT(*) FROM job_history WHERE employee_id = e1.employee_id
);
使用 EXISTS 和 NOT EXISTS 操作符

EXISTS
--查询公司管理者的employee_id, last_name, job_id, department_id信息
--方案一
SELECT e1.employee_id, e1.last_name, e1.last_name, e1.job_id, e1.department_id
FROM employees e1
WHERE e1.employee_id IN (SELECT manager_id FROM employees e2 WHERE e1.employee_id = e2.manager_id );
--方案二
SELECT DISTINCT e1.employee_id, e1.last_name, e1.last_name, e1.job_id, e1.department_id
FROM employees e1, employees e1
WHERE e1.employee_id = e2.manager_id;
--方案三
SELECT employee_id, last_name, job_id, department_id
FROM employees e1
WHERE EXISTS (SELECT 'A' FROM employees e2 WHERE e1.employee_id = e2.manager_id);
NO EXISTS
--查询departments表中,不存在于employees表中的部门的department_id和department_name
SELECT department_id, department_name
FROM departments d
WHERE (
SELECT 'C'
FROM employees
WHERE department_id = d.department_id
);
--差集
SELECT department_id, department_name
FROM departments d
MINUS
SELECT department_id, department_name
FROM employees
使用子查询删除和更新数据
--更新
UPDATE emp
SET department_name = ( SELECT department_name FROM departments WHERE emp.department_id = department_id );
--删除
DELETE
FROM
employees e
WHERE
employee_id IN ( SELECT employee_id FROM emp_history WHERE employee_id = e.employee_id );
使用 WITH 子句

--查询公司中各部门的总工资大于公司中各部门的平均总工资的部门信息
WITH dept_sumsal AS ( SELECT department_name, SUM( salary ) sum_sal1, sumsal, FROM departments d, employees e WHERE d.department_id = e.department_id GROUP BY department_name ),
dept_avgsal AS (SELECT SUM(sum_sal)/COUNT(*) avg_sum_sal2 FROM dept_sumsal)
SELECT * FROM dept_sumal WHERE sum_sal1 > (SELECT avg_sum_sal2 FROM dept_avgsal) ORDER BY department_name;















 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









