







目录
一、概念理解
(1)Flume简介
Apache Flume是一个分布式,可靠且可用的系统,用于有效地收集,聚合大量日志数据并将其从许多不同的源移动到集中式数据存储中。Apache Flume的使用不仅限于日志数据聚合。由于数据源是可定制的,因此Flume可用于传输大量事件数据,包括但不限于网络流量数据,社交媒体生成的数据,电子邮件消息以及几乎所有可能的数据源。Apache Flume是Apache Software Foundation的顶级项目。
(2)Flume特点
(1)可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:
- end-to-end:收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送
- Store on failure:这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送
- Best effort:数据发送到接收方后,不会进行确认
(2)可恢复性
事件在通道中上演,该通道管理从故障中恢复。Flume支持持久的文件通道,该通道由本地文件系统支持。还有一个内存通道可以将事件简单地存储在内存队列中,这样速度更快,但是当代理进程死亡时,仍保留在内存通道中的任何事件都无法恢复。
(3)可扩展性
Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。
其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
(4)可管理性
- 所有agent和colletor由master统一管理,这使得系统便于维护。
- 多master情况,Flume利用ZooKeeper和gossip,保证动态配置数据的一致性。
- 用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。
- Flume提供了web 和shell script command两种形式对数据流进行管理。
(5)功能可扩展性
- 用户可以根据需要添加自己的agent,collector或者storage。
- Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)。
二、Flume中核心架构组件

结合上图,Flume的一些核心组件
- Web Server:数据产生的源头。
- Agent:Flume的核心就是Agent 。Agent是一个Java进程,包含组件Source、 Channel、 Sink,且运行在日志收集端,通过Agent接收日志,然后暂存起来,再发送到目的地。(Agent使用JVM 运行Flume。每台机器运行多个agent,但是在一个agent中只能包含一个source。)
- Source:Agent核心组件之一,Source(源)用于从Web Server收集数据,然后发送到Channel(通道)。
- Channel:Agent核心组件之一,Channel(通道)可以用来从Source接收数据,然后发送到Sink,Channel存放临时数据,有点类似队列一样。
- Sink:Agent核心组件之一,Sink(接收器)用来把数据发送的目标地点,如上图放到HDFS中。
- Event:整个数据传输过程中,流动的对象都是实现了org.apache.flume.Event接口的对象。Event也是事务保证的级别。
- Flow:Event从源点到达目的点的迁移的抽象
(1)Agent
Flume 运行的核心是 Agent。Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具,含有三个核心组件,分别是source、 channel、 sink。通过这些组件, Event 可以从一个地方流向另一个地方。
(2)source
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。 Flume提供了很多内置的Source, 支持 Avro, log4j, syslog 和 http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如AvroSource,SyslogTcpSource。 如果内置的Source无法满足需要, Flume还支持自定义Source。
source类型:

(2)Channel
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。
Channel类型:

(3)Sink
Sink从Channel中取出事件,然后将数据发到别处,可以向文件系统、数据库、 hadoop存数据, 也可以是其他agent的Source。在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。
Sink类型:

三、Flume拦截器、数据流以及可靠性
(1)Flume拦截器
当我们需要对数据进行过滤时,除了我们在Source、 Channel和Sink进行代码修改之外, Flume为我们提供了拦截器,拦截器也是chain形式的。拦截器的位置在Source和Channel之间,当我们为Source指定拦截器后,我们在拦截器中会得到event,根据需求我们可以对event进行保留还是抛弃,抛弃的数据不会进入Channel中。

(2)Flume数据流
- Flume 的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
- Flume 传输的数据的基本单位是 Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。 Event 从 Source,流向 Channel,再到 Sink,本身为一个 byte 数组,并可携带 headers 信息。 Event 代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,这也正是Flume强大之处。如图:

(3)Flume可靠性
Flume 使用事务性的方式保证传送Event整个过程的可靠性。 Sink 必须在Event 被存入 Channel 后,或者,已经被传达到下一站agent里,又或者,已经被存入外部数据目的地之后,才能把 Event 从 Channel 中 remove 掉。这样数据流里的 event 无论是在一个 agent 里还是多个 agent 之间流转,都能保证可靠,因为以上的事务保证了 event 会被成功存储起来。比如 Flume支持在本地保存一份文件 channel 作为备份,而memory channel 将event存在内存 queue 里,速度快,但丢失的话无法恢复。
四、Flume使用场景
(1)多个agent顺序连接
可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接的Agent 的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。
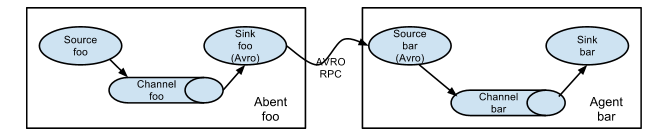
这个例子里面为了能让数据流在多个Agent之间传输,前一个Agent的sink必须和后一个Agent的source都需要设置为avro类型并且指向相同的hostname(或者IP)和端口。
(2)多Agent的复杂流
这种情况应用的场景比较多,比如要收集Web网站的用户行为日志, Web网站为了可用性使用的负载集群模式,每个节点都产生用户行为日志,可以为每个节点都配置一个Agent来单独收集日志数据,然后多个Agent将数据最终汇聚到一个用来存储数据存储系统,如HDFS上。

可以通过使用 Avro Sink 配置多个第一层 Agent(Agent1、Agent2、Agent3),所有第一层Agent的Sink都指向下一级同一个Agent(Agent4)的 Avro Source上(同样你也可以使用 thrift 协议的 Source 和 Sink 来代替)。Agent4 上的 Source 将 Event 合并到一个 channel 中,该 channel中的Event最终由HDFS Sink 消费发送到最终目的地。
(3)多路复用流
Flume支持多路复用数据流到一个或多个目的地。这是通过使用一个流的[多路复用器](multiplexer )来实现的,它可以 复制 或者 选择 数据流到一个或多个channel上。
很容易理解, 复制 就是每个channel的数据都是完全一样的,每一个channel上都有完整的数据流集合。 选择 就是通过自定义一个分配机制,把数据流拆分到多个channel上。

上图的例子展示了从Agent foo扇出流到多个channel中。这种扇出的机制可以是复制或者选择。当配置为复制的时候,每个Event都被发送到3个channel上。当配置为选择的时候,当Event的某个属性与配置的值相匹配时会被发送到对应的channel。
例如Event的属性txnType是customer时,Event被发送到channel1和channel3,如果txnType的值是vendor时,Event被发送到channel2,其他值一律发送到channel3,这种规则是可以通过配置来实现的。
参考文章:
- https://flume.liyifeng.org/#flume-sources(中文官方文档)
- https://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#architecture(官方文档)
- https://www.cnblogs.com/zhangyinhua/p/7803486.html(推荐阅读)
- https://yq.aliyun.com/articles/369857
- https://www.iteye.com/blog/qianshangding-2259404
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!
















 3559
3559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











