






岛问题
一个矩阵中只有0和1两种值,每个位置都可以和自己的上下左右相连,如果一片1连在一起,这个部分叫做一个岛,求一个矩阵有多少个岛
思路:遍历,infect
class Solution {
public int numIslands(char[][] grid) {
int res = 0;
if(grid == null || grid[0] == null ){
return 0;
}
int N = grid.length;
int M = grid[0].length;
for(int i = 0; i < N; i++){
for(int j = 0; j < M; j++){
if(grid[i][j] == '1'){
res++;
infect(grid,i,j,N,M);
}
}
}
return res;
}
public void infect(char[][] grid, int i, int j, int N, int M){
if(i < 0 || i >= N || j < 0 || j >=M || grid[i][j] != '1'){
return;
}
grid[i][j] = '2';
infect(grid,i-1,j,N,M);
infect(grid,i+1,j,N,M);
infect(grid,i,j-1,N,M);
infect(grid,i,j+1,N,M);
}
}整体遍历阶段调用1次,infect4次,时间复杂度O(N*M)
进阶:任何设计一个并行算法解决这个问题
特别大的二维数组分片计算岛,然后再union
并查集 Boolean isSameSet(a,b) void union(a,b)
链表表示时,isSameSet时不快,不是O(1),哈希表时,union不是O(1)
并查集:往上指的图结构
每个集合都有一个代表元素
union,少的顶部挂在数量多的顶部
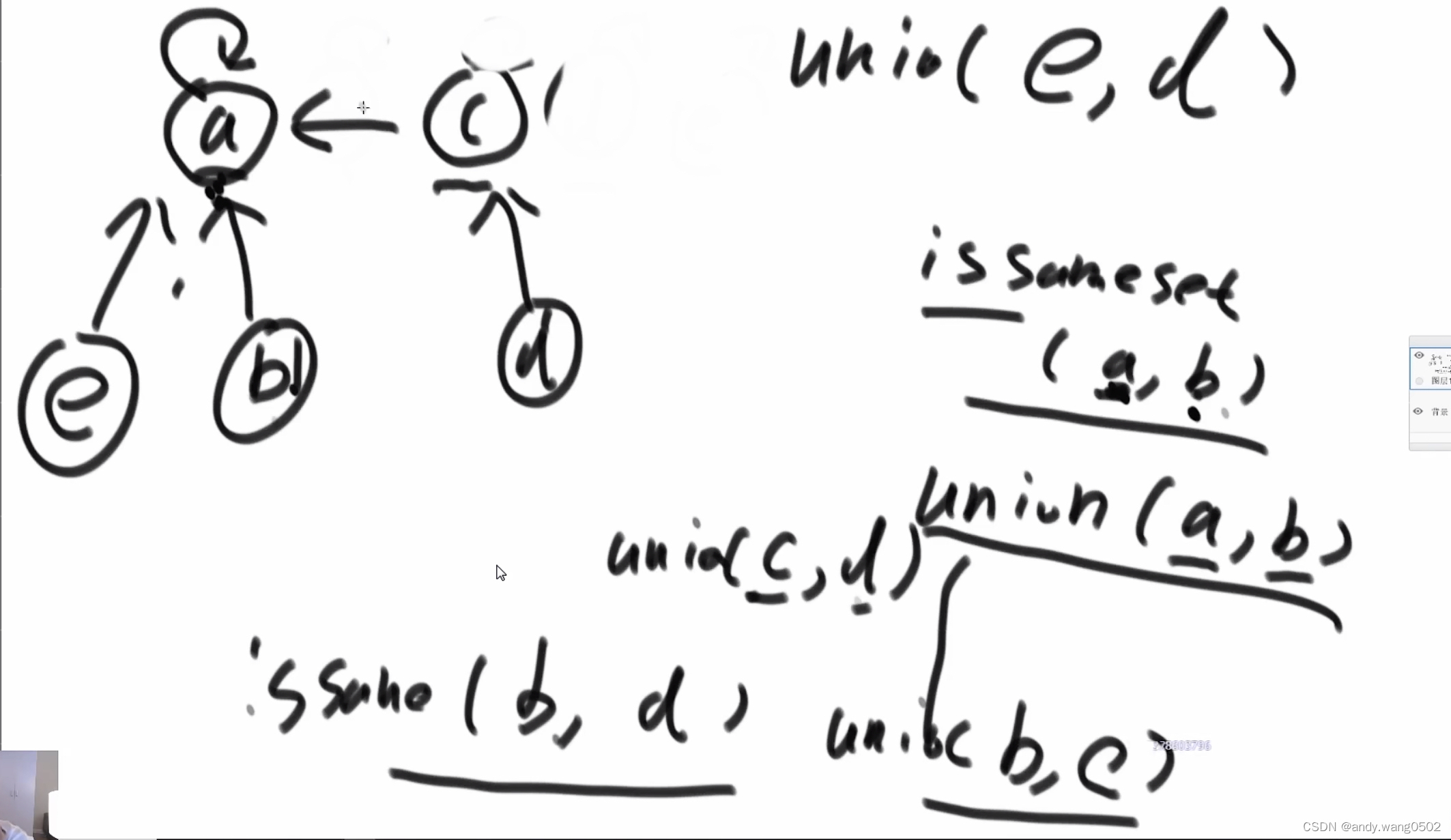
并查集的优化:往上找时,isSame(Y,?),找到顶点时,扁平化,整条连都各自直接指向顶节点。
//样本进来会包一层,叫做元素
public static class Element<V> {
public V value;
public Element(V value){
this.value = value;
}
}
public static class UnionFindSet<V> {
public HashMap<V, Element<V>> elementMap;
//key 某个元素 value 该元素的父
public HashMap<Element<V>, Element<V>> fatherMap;
//key 某个集合的代表元素 value该集合的大小
public HashMap<Element<V>, Integer> sizeMap;
public UninFindSet(List<V> list){
elementMap = new HashMap<>();
fatherMap = new HashMap<>();
sizeMap = new HashMap<>();
for(V value : list){
Element<V> element = new Element<V>(value);
elementMap.put(value, element);
fatherMap.put(element, element);
sizeMap.put(element, 1);
}
}
//给定一个元素,一直网上找,把代表元素返回
public Element<V> findHead(Element<V> element){
Stack<Element<V>> path = new Stack<>();
while(element != fatherMap.get(element)){
path.push(element);
element = fatherMap.get(element);
}
while(!path.isEmpty()){
fatherMap.put(path.pop(), element);
}//扁平化
return element;
}
public boolean isSameSet(V a, V b){
if(elementMap.containsKey(a) && elementMap.containsKey(b)){
return findHead(elementMap.get(a)) == findHead(elementMap.get(b));
}
return false;
}
public void union(V a, V b){
if (elementMap.containsKey(a) && elementMap.containsKey(b)){
Element<V> aF = findHead(elementMap.get(a));
Element<V> bF = findHead(elementMap.get(b));
if(aF != bF){
Element<V> big = sizeMap.get(aF) >= sizeMap.get(bF) ? aF : bF;
Element<V> small = big == aF ? bF : aF;
fatherMap.put(samll, big);
sizeMap.put(big, sizeMpa.get(aF) + sizeMap.get(bF));
sizeMap.remove(small);
}
}
}
}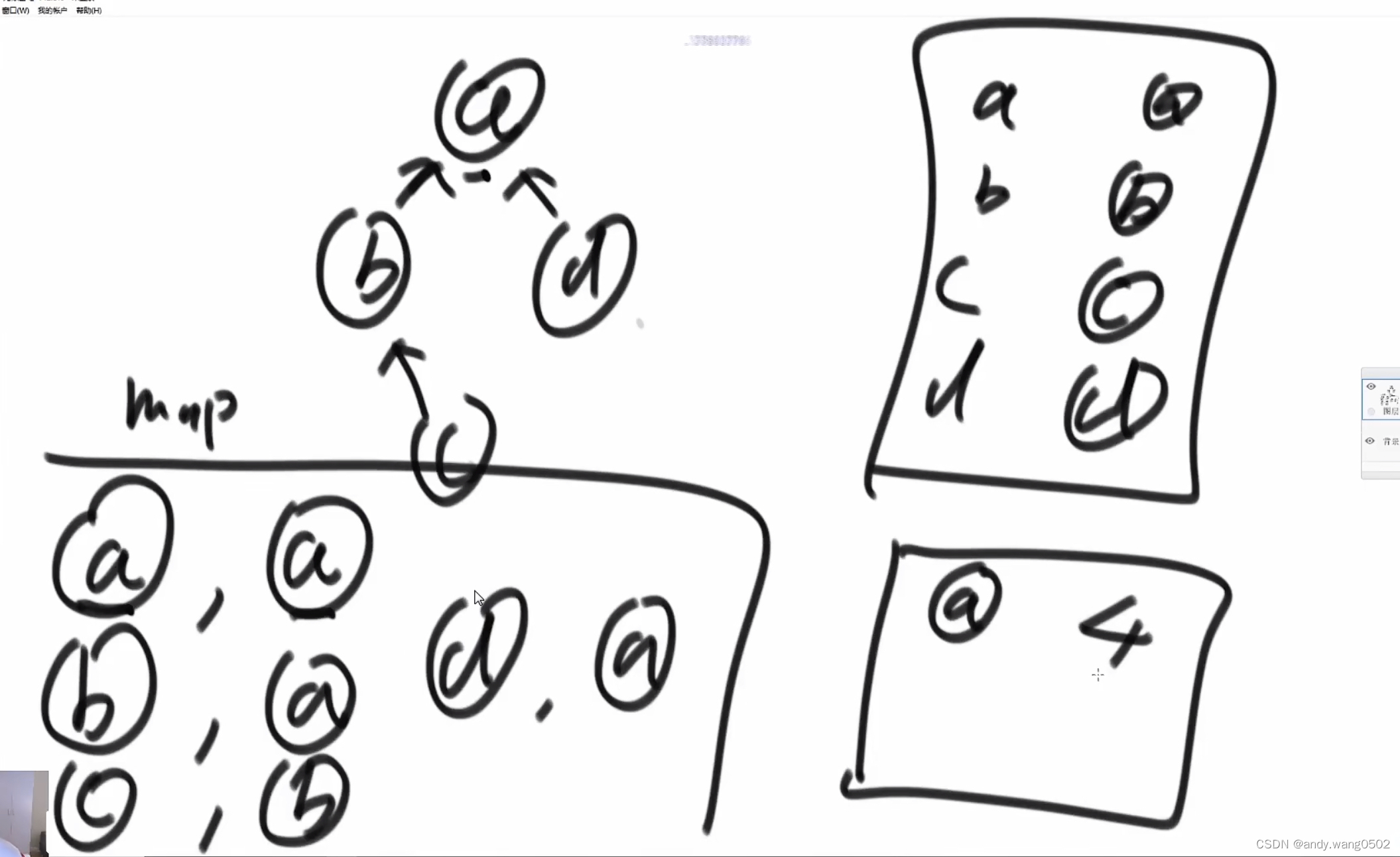
扁平化使得并查集速度加快
结论:N个样本,findHead的调用次数达到o(N)的复杂度后,单次findHead的复杂度o(1),
如何并行计算
当有两个CPU时,分一半计算
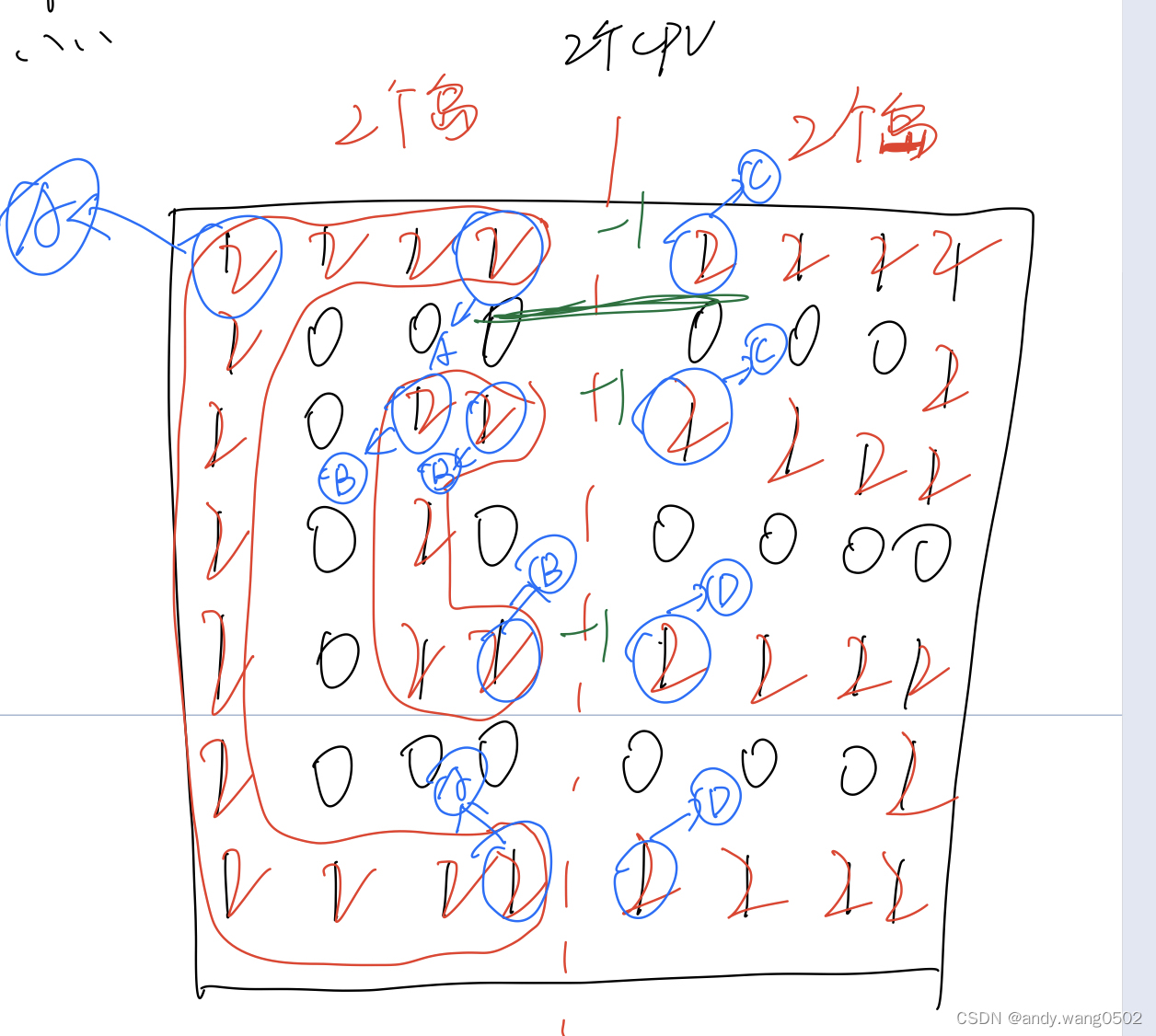
{A},{B},{C},{D},四个集合相碰合并,合并后只有一个岛
合并逻辑:每一侧在感染后,收集边界信息,边界相碰讨论
当有多个CPU时,讨论四个边界信息
KMP算法解决的问题
字符串str1和str2,str1是否包含str2,如果包含返回str2在str1中开始的位置,如何做到时间复杂度O(N)?
str1"ABC1234de" str2"1234"
暴力解法:尝试每一个开头
“111111111111112” “1112” 时复杂度较高o(N*M)
KMP算法:讨论哪一个开头能配出str2,无则返回-1
最长前缀和后缀的匹配长度
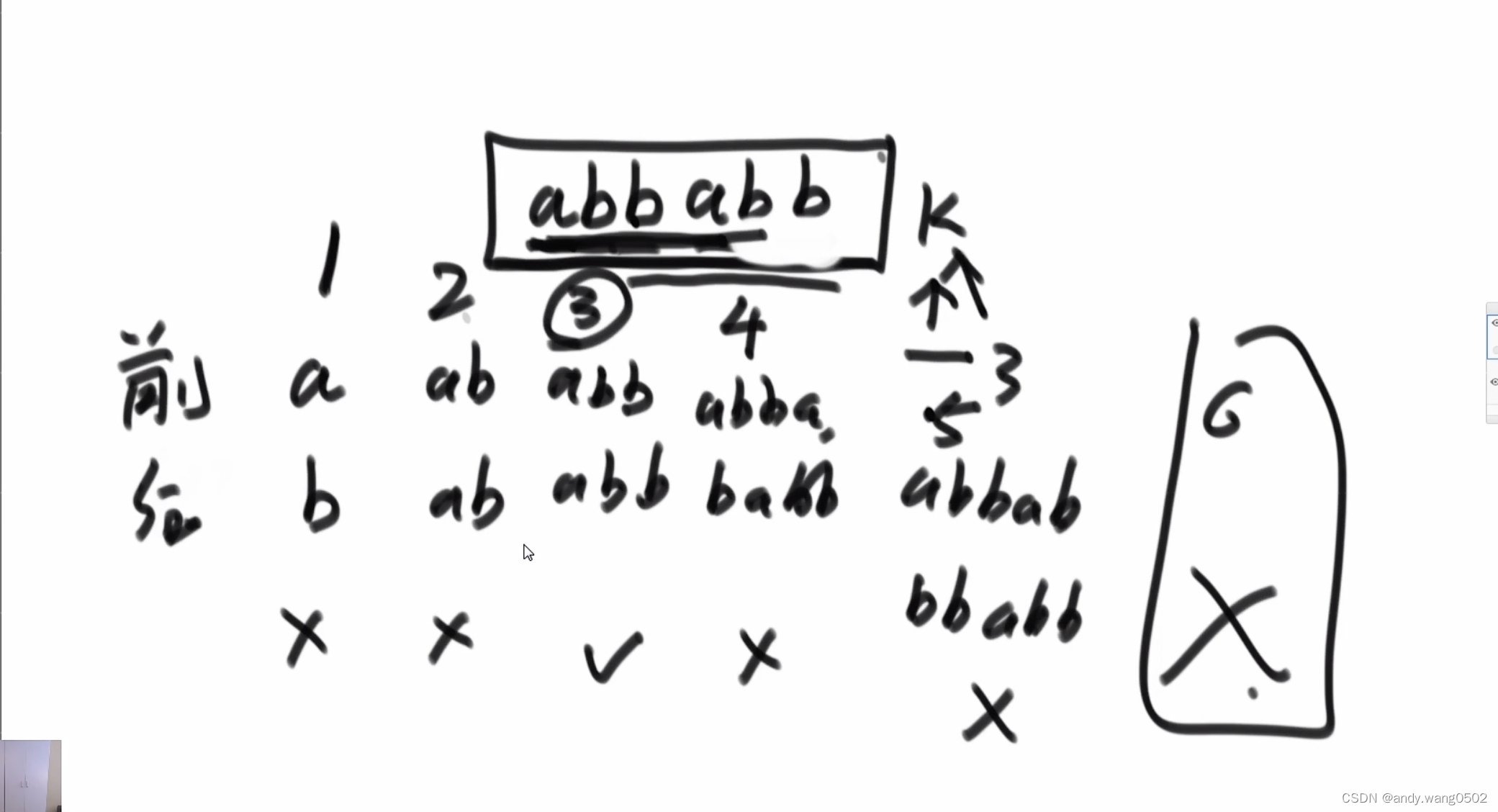
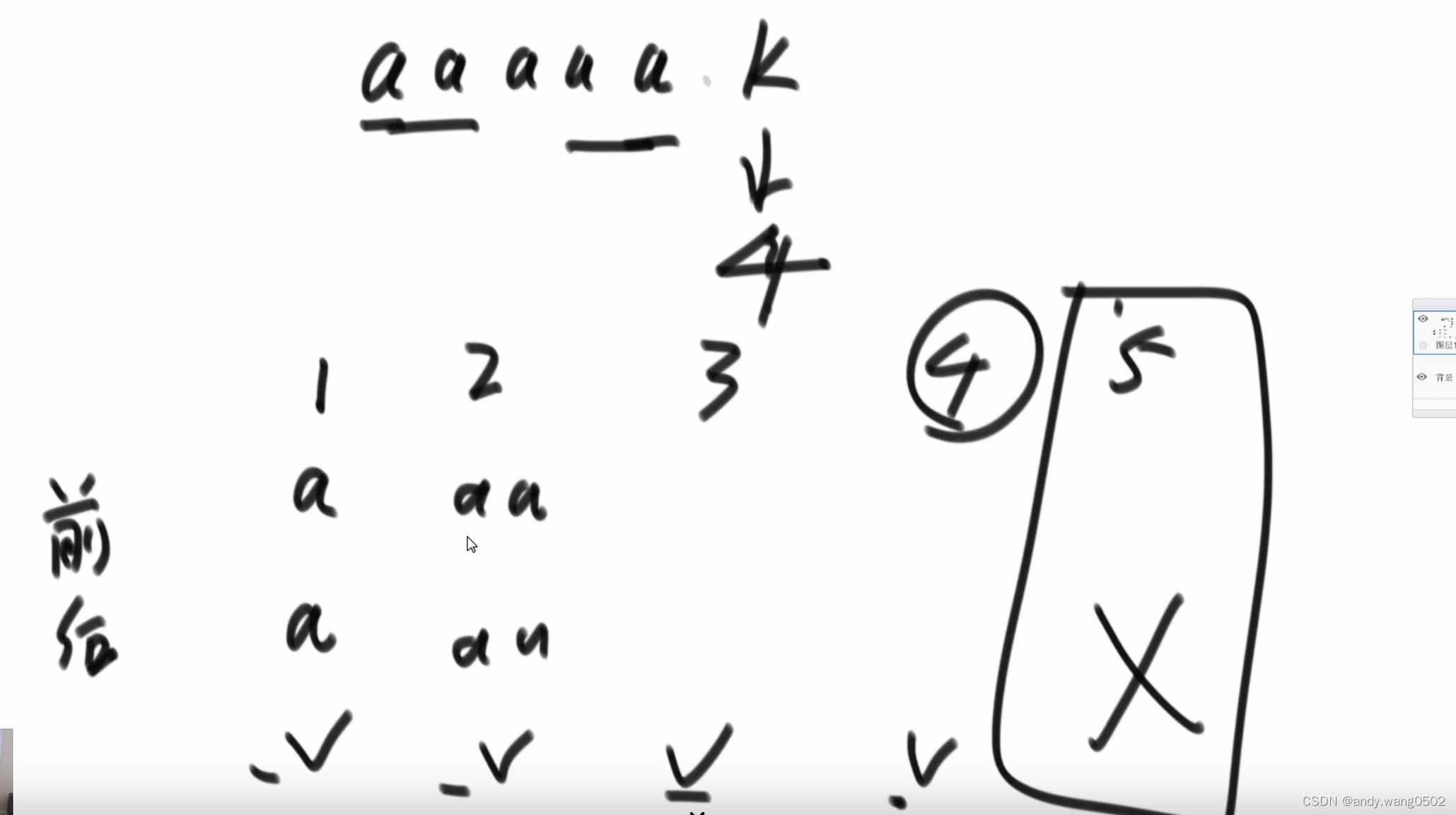
对str2求该信息
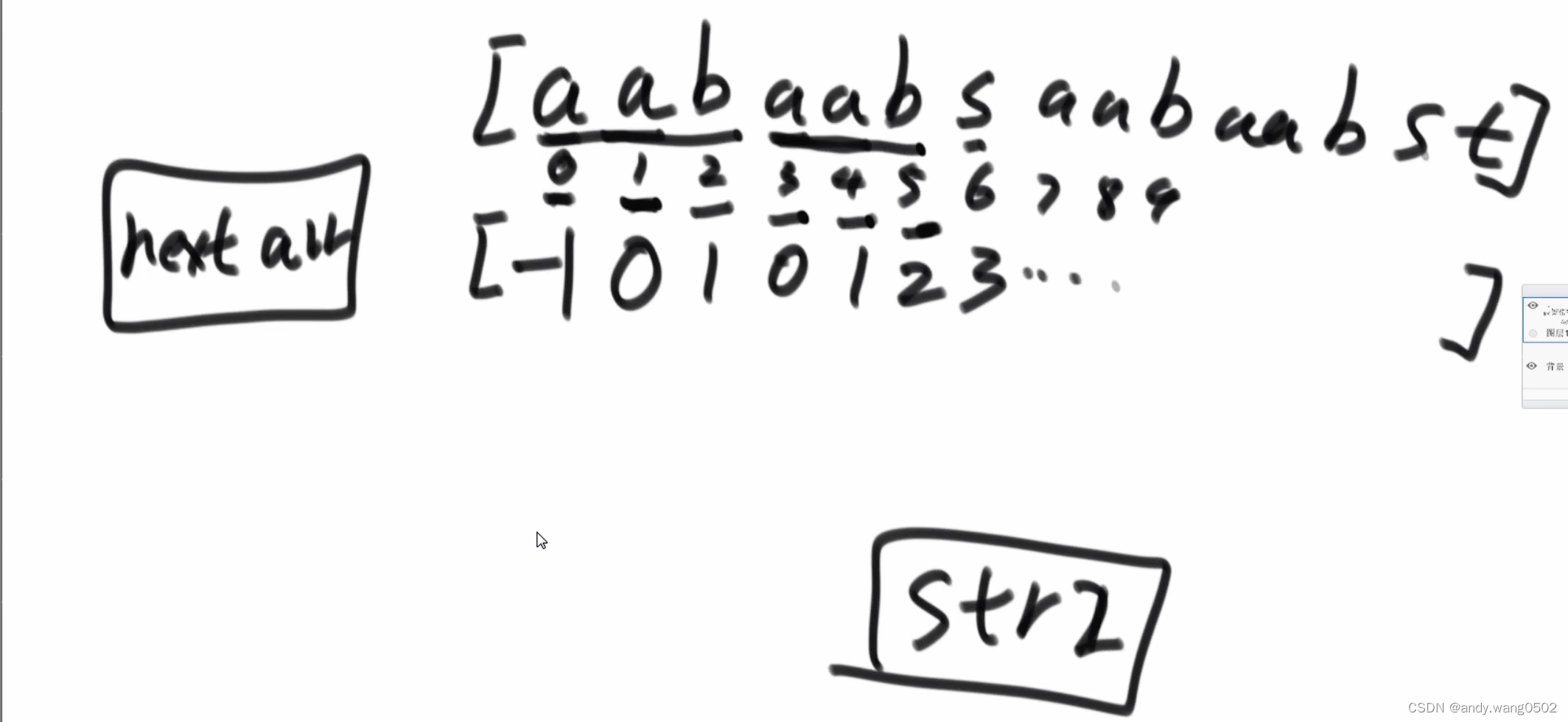
KMP过程
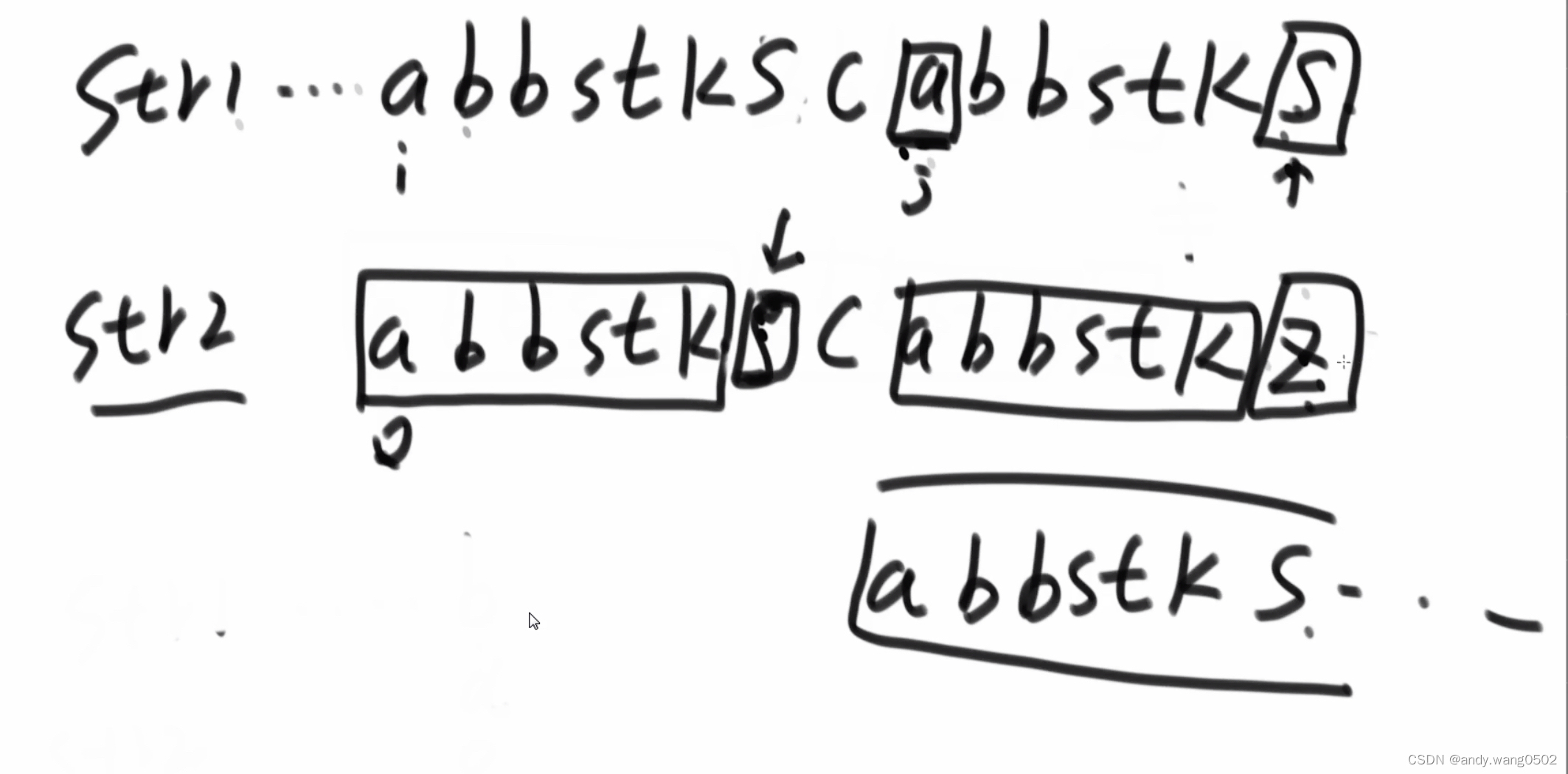
1)j开头判断是否配出str2
2)i和j之间的位置配不出和str2相同的串(反证法,与更长的前缀后缀匹配矛盾)
str2不能再往前跳的时候,i++
public static int KMP(String s, String m){
if (s == null || m == null || m.length() < 1 || s.length() < m.length()){
return -1;
}
char[] str1 = s.toCharArray();
char[] str2 = m.toCharArray();
int i1 = 0;
int i2 = 0;
int[] mext = getNextArray(str2);//o(M)
//O(N)
while( i1 < str1.length && i2 < str.length ){
if (str1[i1] == str2[i2]){
i1++;
i2++;
}else if(next[i2] == -1){//i2 = 0 str2中的位置已经无法往前跳了
i1++;
}else{
i2 = next[i2];
}
}
//i1越界或者i2越界
return i2 == str2.length ? i1 - i2 : -1;
}
public static int[] getNextArray(char[] ms){
if(ms.length == 1){
return new int[]{ -1 };
}
int[] next = new int[ms.length];
next[0] = -1;
next[1] = 0;
int i = 2;//next的数组
int cn = 0;
while(i < next.length ){
if (ms[i - 1] == ms[cn]){
next[i++] = ++cn;
}
//当前跳到cn位置的字符,和i-1位置的字符配不上
else if(cn > 0){
cn = next[cn];
}else{
next[i++] = 0;
}
}
return next;
}复杂度也是O(2M)
N>M
KMP的复杂度为o(N)















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









