






1.概述
DB 数据库(Database):存数据的仓库,其本质是一个文件系统,保存了一系列有组织的数据
DBMS 数据库管理系统:一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制。用户通过数据库管理系统访问数据库中表内的数据
SQL 结构化查询语言:专门用来与数据库通信的语言
关系型数据库设计规则
E-R(实体 联系)模型中三个主要概念:实体集、属性和联系集
实体集对应数据库的一个表,实体则对应数据库表中的一行,也称为一条记录,一个属性则对应数据库表中的一列,也称为一个字段
表的关联关系:一对一、一对多、多对多和自我引用
2.基本的select语句
1.SQL的分类:
DDL:数据定义语言 CREATE\ ALTER\ DROP \ RENAME\TRUNCATE
DML:数据操作语言 INSERT \ DELETE \ UPDATE \ SELECT (关键)
DCL:数据控制语言 COMMIT \ ROLLBACK \ SAVEPOINT \ GRANT \ REVOKE
\G可以使得查询的信息由列变成行来显示(转置)

2. 建议遵守大小写规范:win下大小写不敏感,linux大小写敏感
建议:数据库名、表名、表别名、字段名、字段别名都小写
关键字、函数名、绑定变量等都大写
3.注释: #单行注释
/*
多行注释
*/
-- 注释文字(--后面加空格)
4.导入现有的数据表、表的数据
方式1:source文件的全路径名
方式2:基于具体的图形化界面的工具可以导入数据
navicat : 点击localhost——运行sql文件
5.最基本的SELECT语句: SELECT 字段1,字段2,... FROM 表名
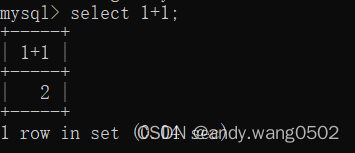
SELECT 1+1;
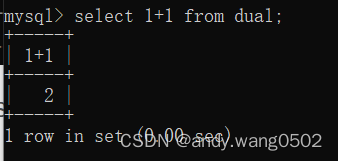
SELECT 1+1 FROM DUAL;#DUAL伪表
SELECT * FROM
#*:表中的所有的字段(或列)

6.列的别名

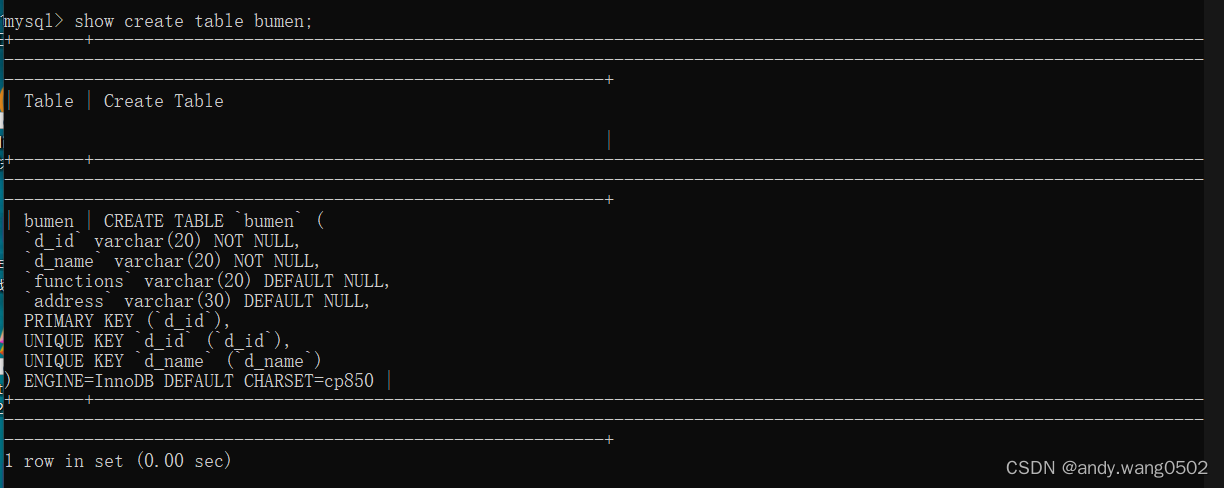
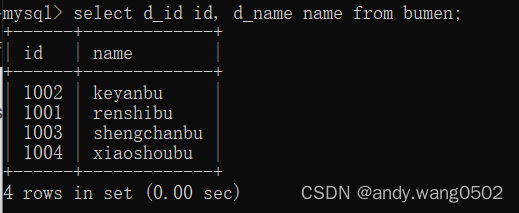
select d_id id, d_name name from bumen;
#as:全称:alias(别名),可以省略
#列的别名可以使用一对""引起来。不要使用''
7.去除重复行
# select DISTINCT birthday from student;


8.空值参与运算
#空值:null
#null不等同于0
#空值参与运算
结果还是null
解决方案引入 :ifnull()
9.着重号``
#当表名、字段名和关键字冲突时,坚持使用,要用着重号引用起来
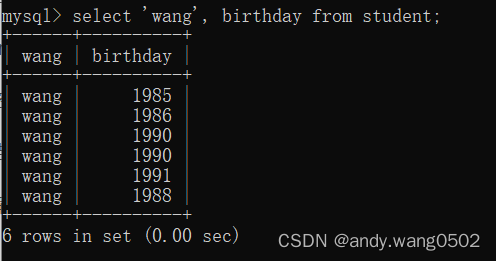
10.查询常数
select 'wang' as corporation, birthday from student;
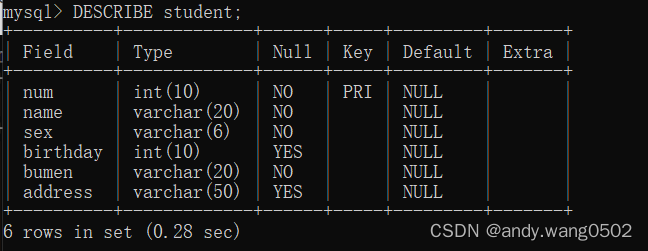
11.显示表结构
DESCRIBE student;#显示了表中字段的详细信息
DESC效果一样
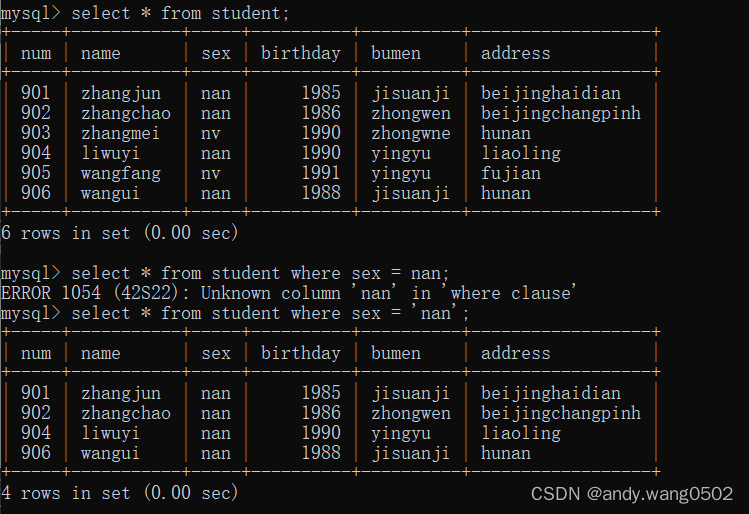
12.过滤数据
#select * from student where sex = 'nan';
#where 写在from结构的后面
3.运算符
1.算术运算符
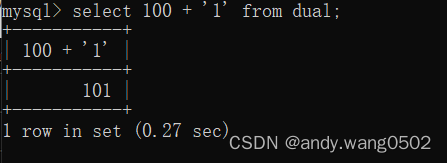
#加减乘除 + - * / div % mod (取模)

#在sql中,+没有连接的作用,就表示加法。此时,会将字符串转化成数值(隐式转换)
2.比较运算符
2.1 = 等于运算符
<=>安全等于
<> !=不等于
< <= >= >
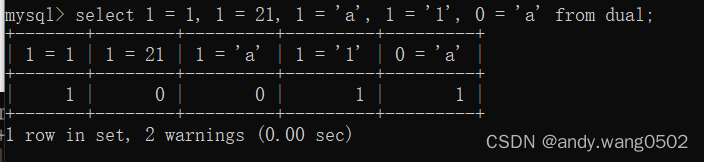
#字符串存在隐式转换,如果转换数值不成功,则看作0
#两边都是字符串的话,则按照ANSI的比较规则进行比较
#只要有null参与判断,结果就为null
<=>安全等于,唯一的区别就是可以用来对null进行判断,两边都是null,返回1
2.2比较运算符
# is null \ is not null \ isnull
# LEAST() \ GREATEST() 最大最小
#(NOT)BETWEEN 条件1(下界) AND条件2(上界) (查询条件一和条件2范围内的数据,包含边界)
# IN \ NOT IN (set) 离散的查询
# LIKE :模糊查询 %(不确定个数的字符,0个或多个) _(代表一个不确定的字符)
#转义字符:\
#REGEXP \ RLIKE:正则表达式 ^以开头 $结尾

2.3逻辑运算符
# NOT ! OR || AND && XOR (异或,追求异)
#AND的优先级高于OR
2.4位运算符
# & | ^ ~ >> <<
4.排序与分页
4.1排序
#如果没有使用排序操作,默认情况下查询返回的是先后添加的顺序现实的
#使用ORDER BY对查询的数据进行排序操作 ACS升序 DESC降序
#OEDER BY 默认的按照升序排列
#可以使用列的别名进行排序
#列的别名只能在ORDER BY中使用,不能在WHERE中使用 (sql语句先操作from where,再看select 和 order by)
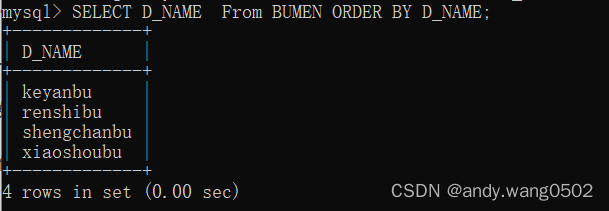

#二级排序,直接在OEDER BY后面加即可
4.2分页
#使用limit实现数据的分页显示
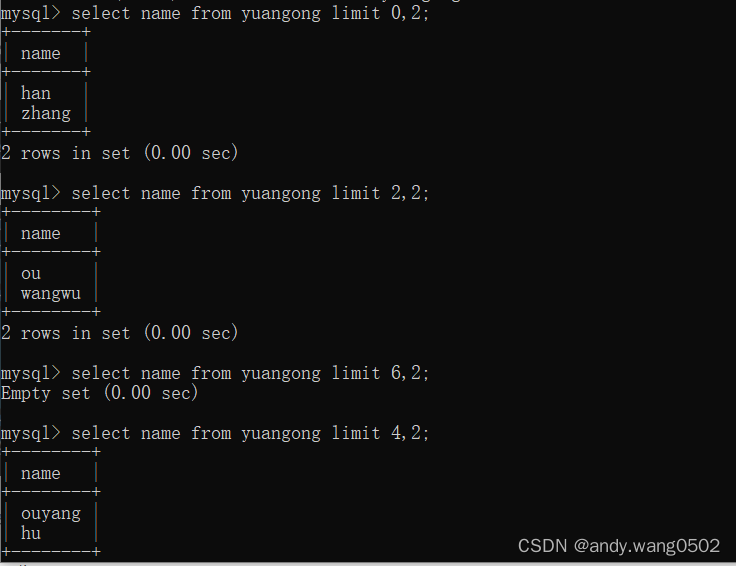
limit (pageNO - 1)* pageSize,pageSize;
#WHERE ..... ORDER BY ... LIMIT 声明顺序
#limit的格式:严格来说:limit 位置偏移量,条目数
#limit 0,条目数 等价于 limit 条目数
#limit条目数 offset 偏移量
5.多表查询
出现笛卡尔积(交叉连接)的错误:缺少了多表的连接条件 连接条件无效
#多表查询的正确方式:需要有连接条件
#如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表
#建议多表查询时,每个字段前都指明其所在的表
#可以给表起别名,在SELECT和WHERE中使用表的别名,如果起了别名,则一定要使用
#如果有n个表实现多表的查询,则至少需要n-1个连接条件
多表查询的分类:
角度一:等值连接和非等值连接
角度二:自连接和非自连接
角度三:内连接和外连接
内连接:合并具有同一列的两个以上的表的行,结果集中不包含一个表与另一个表不匹配的行
外连接:合并具有同一列的两个以上的表的行,结果集中除了包含一个表与另一个表匹配的行,还查询到了左表或右表不匹配的行
外连接的分类:左外连接、右外连接、满外连接
#SQL92语法实现外连接:使用 +
#SQL99语法使用JOIN ....ON的方式
#SQL99实现内连接 inner join
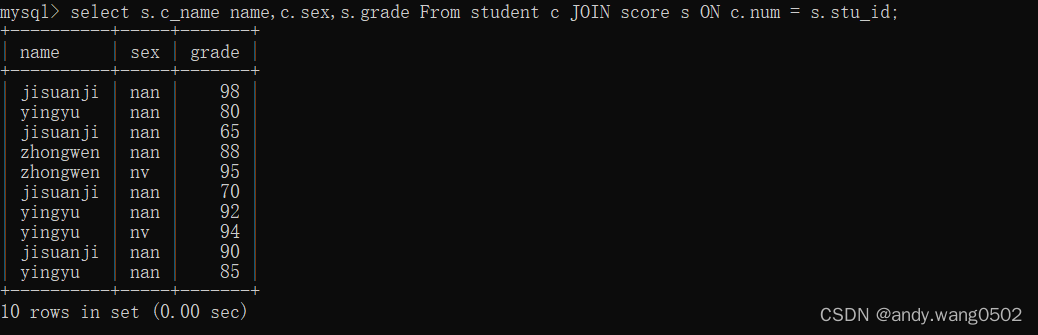
#SQL99实现外连接 left / right outer join
满外连接:
#UNION的使用
合并查询结果
UNION 返回两个查询的结果集的并集,并去重(效率低)
UNION ALL 不去重
#7种JOIN的实现
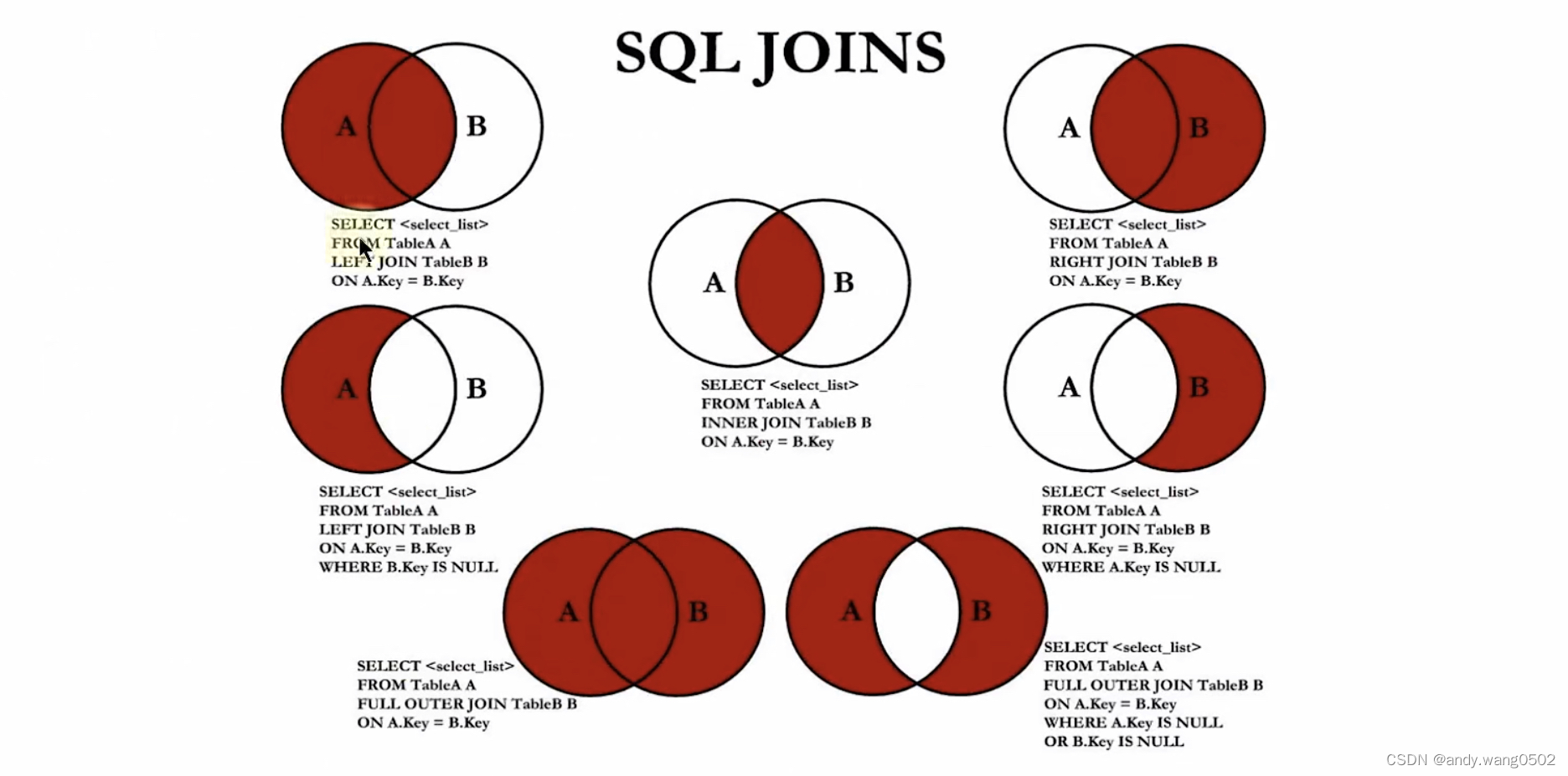 #中图:内连接
#中图:内连接
#左上图:左外连接
#右上图:右外连接
#左中图:在最后加where 左表条件 is null;
#右中图:在最后加where 右表条件 is null
#左下图:满外连接
方式1:左上图union all 左中图
方式2:左中图union all 左上图
#右下图:左中图 union all 右中图
#SQL99语法新特性:自然连接 natural join :自动查询两张连接表中所有的相同的字段,然后进行等值连接(不够灵活)
#USING连接:当连接表中的字段名一样时,可以使用JOIN ON 可以简化成JOIN ... USING...
6.函数
从函数的定义分为自定义函数和内置函数
MYSQL的内置函数及分类
数值函数、字符串函数、日期和时间函数、流程控制函数、加密与解密函数、获取MASQL信息函数、聚合函数
总体上分为 单行函数 多行函数
6.1单行函数
round() 四舍五入
truncate() 截断
concat()连接字符串
insert(str,idx,len,replacestr)插入
replace(str,a,b)替换
UPPER/LOWER 大写小写
left(str,n)最左的n个字符返回
LPAD(str,len,pad)字符串pad在左边补充str至n位(实现右对齐)
RPAD(实现左对齐)
TRIM()去除首尾空格
TRIM(s1 from s)去掉s首尾的s1
STRCMP(s1,s2)比较ASCII码
SUBSTR(s,index,len)返回index开始的子字符串
LOCATE(substr,str)返回子字符串首次出现的位置
ELT(m,s1,s2,...)返回第m个字符串
FIELD(s,s1,s2...)返回S在字符串列表中第一次出现的位置
FIELD_IN_SET(s1,s2)返回s1在s2中出现的位置,s2是一个以逗号分隔的字符串
NULLIF(value1,value2)相等返回null,否则返回value1
日期和时间函数
获取日期和时间
CURDATE() CURTIME() NOW() SYSDATE() UTC_DATE()
日期和时间戳的转换
UNIX_TIMESTAMP()
EXTRACT(type from date)返回日期特定的部分,type指定返回值
TIME_TO_SEC()时间和秒钟转换的函数
DATE_ADD(datetime,INTERVAL expr type)返回与给定日期时间相差INTERVAL时间段的日期时间
日期的显示格式化与解析
格式化:日期---> 字符串
解析: 字符串 ---> 日期
DATE_FORMAT(date,fmt)按照字符串fmt格式化日期date值
TIME_FORMAT(time,fmt)按照字符串fmt格式化日期time值
%Y 4位数字表示年份 %y两位数字表示年份
%M 月名表示月份 %m两位数字表示月份
%b缩写的月名 %c数字表示月份
%D 因为后缀表中月中的天数 %d两位数字表示月中的天数
%e数字形式表示月中的天数
解析:格式化的逆过程
STR_TO_DATE(str, fmt)
流程控制函数
IF(value, value1, value2) 如果value为true,返回value1,否则返回value2
IFNULL( value1, value2) 如果value1不为NULL,返回value1,否则返回value2
CASE WHEN....THEN....WHEN...THEN.... ELSE....END 类似于JAVA的if else
CASE...WHEN...THEN...WHEN....THEN...ELSE...END 类似switch
加密与解密函数
对数据库的数据进行加密,以防止数据被他人窃取。
PASSWORD(str) 返回字符串str的加密版本。41位长的字符串,不可逆(MASQL 8.0弃用)
MD5() SHA()

ENCODE(VALUE,password_seed)返回使用password_seed作为加密密码加密的value
DECODE(VALUE,password_seed)解密(弃用)
MYSQL信息函数
VERSION()版本号 , CONNECTION_ID()MYSQL服务器的连接数 DATABASE(), SCHEMA()当前所在的数据库 USER()当前连接MYSQL的用户名,“名@用户名”
CHARSET(value)返回字符串value自变量的字符集
COLLATION(value)返回字符串value的比较规则
其他函数
FORMAT(value,n)返回对数字value进行格式化后的结果数据,n表示四舍五入保留到小数点后n位
CONV(VALUE,from,to)将value的值进行不同进制的转换
INET_ATON(ipvalue)将以点分隔的IP地址转化位一个数字
INET_NTOA(value)数字IP转化为IP地址
BENCHMARK(n,expr)将表达式expr重复执行n此 ,测试MYSQL处理expr所耗费的时间
CONVERT(value USING char_code)将value的字符编码修改为char_code
7.聚合函数
对一组数据进行汇总的函数,返回一个值
7.1常见的聚合函数类型
AVG() SUM():只适用于数值类型的字段(或变量) (过滤null)
MAX() MIN():适用于数值类型、日期类型和字符串类型的字段
COUNT():作用计算指定字段在查询结果中出现的个数
如果计算表中有多少条记录:
count(*)
count(1)
count(具体字段):不一定对,因为不计算空值
#如果使用的是MyISAM引擎 三者的效率一样都是O(1)
#如果使用的是InnoDB存储引擎,count(*) = count(1) > count(字段)
7.2GROUP BY的使用
#需求:查询各个学生的平均成绩
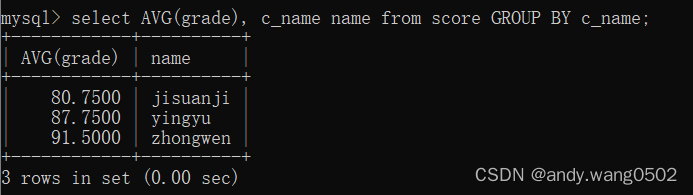
# SELECT中出现的非主函数的字段必须出现在GROUP BY中,反之,不一定
#GROUP BY声明在FROM后面,WHERE后面,ORDER BY前面,LIMIT前面
#with rollup计算总体的一个主函数
#with rollup和order by互斥
7.3HAVING的使用(过滤数据)
#如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE
#HAVING必须声明在GROUP BY的后面
#开发中,HAVING的前提是SQL使用了GROUP BY
#当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中
#当过滤条件中没有聚合函数时,建议声明在WHERE中
WHERE和HAVING的对比
HAVING的适用范围更广
如果过滤条件没有聚合函数,WHERE(先过滤,在连接)的执行效率要高于HAVING
7.4SQL底层执行原理
SELECT语句的完整结构
SELECT ....,.....,....(存在聚合函数)
FROM ....,(LEFT/RIGHT)JOIN ......, ON 多表的连接条件
WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件
GROUP BY....,.....
HAVING 包含聚合函数的过滤条件
ORDER BY.....,....(ASC / DESC)
LIMIT...,.....
SQL语句的执行过程
FROM .... --> ON -> (LEFT/RIGHT JOIN) -> WHERE -> GROUP BY -> HAVING
-> SELECT -> DISTINCT
-> ORDER BY -> LIMIT
每个步骤都会产生一个虚拟表
8.子查询
将一个查询语句嵌套在另一个查询语句内部的查询
需求:谁的年纪比HAN大
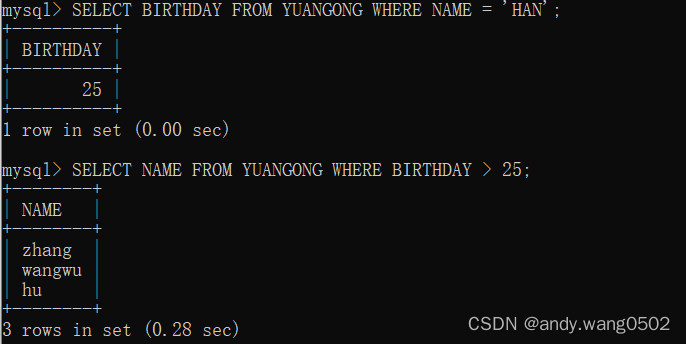
两次交互的时间长
方式2:自连接

方式3:子查询

称谓的规范:外查询(或主查询)、内查询(或子查询)
子查询在主查询之前一次执行完成
子查询的结果被主查询使用
注意事项:子查询要包含在括号内 将子查询放在比较条件的右侧 单行操作符对应单行子查询,多行操作符对应多行子查询
子查询的分类:
角度1:分为单行子查询和多行子查询:从内查询返回的结果的条目数
角度2:分为相关子查询 和 不相关子查询:内查询是否被执行多次
比如:相关子查询的需求:查询工资大于本部门平均工资的员工信息
不相关子查询的需求:查询工资大于本公司平均工资的员工信息
#单行子查询:
单行操作符: = != > >= < <=
题目:查询birthday比 id 8001的员工大的信息
子查询额编写技巧(或步骤): 从里往外写 从外往里写
SELECT BIRTHDAY FROM YUANGONG WHERE ID = 8001
SELECT ID, BIRTHDAY FROM YUANGONG WHERE BIRTHDAY >
串起来

#子查询中的空值问题
#非法使用子查询
多行子查询
操作符:IN 等于列表中的任意一个
ANY 需要和单行比较操作符一起使用,和子查询返回的某一个值比较
ALL 需要和单行比较操作符一起使用,和子查询返回的所有值比较
SOME 实际上是ANY的别名,一般使用ANY
举例:
#IN
找到每门课考的最差的学生的id

#ANY
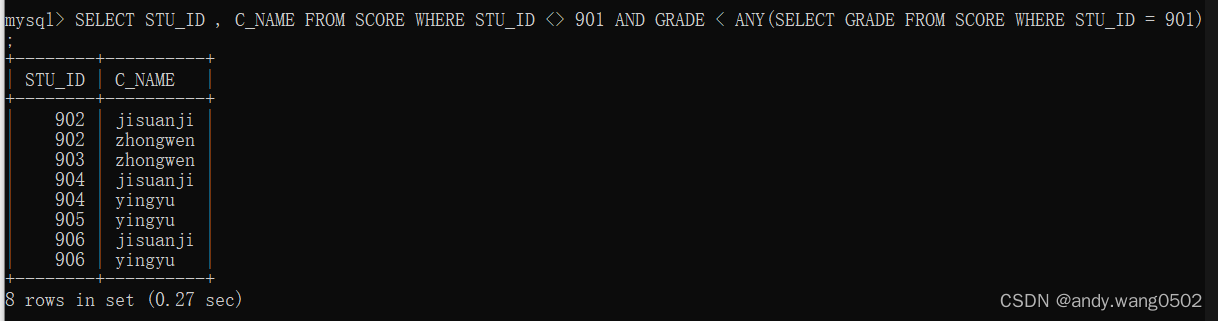
#ALL

查询平均分数最低的id
MYSQL中聚合函数不能嵌套使用
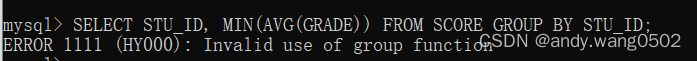
取别名

不相关子查询:

在SELECT查询中,除了GROUP BY和LIMIT外,其他位置都可以声明子查询
EXISTS 和 NOT EXISTS关键词的使用
自连接的方式好,处理速度比子查询快

9.创建和管理表
数据存储过程:创建数据库 —— 确认字段——创建数据表——插入数据
创建数据库:
CREATE DATABASE IF NOT EXISTS
管理数据库
查看当前连接中的数据库都有哪些
show databases
切换数据库
use
查看当前数据库中都有哪些数据表
show tables
查看当前使用的数据库
select database() from dual
查看指定数据库下保存的数据表
show tables from mysql
#修改数据库
#更改字符集
ALTER DATABASES 数据库名 CHARACTER SET ' '
#数据库不能改名,可视化工具中是通过复制旧表实现改名
#删除数据库
DROP DATABASE
DROP DATABASE IF EXISTS
创建数据表
#方式1:
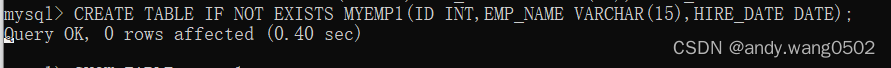
查看表结构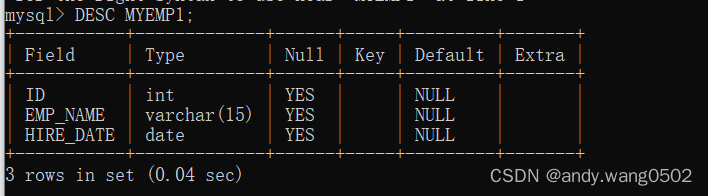
方式2:基于现有的表(查询语句中字段的别名可以作为新创建的表的字段的名称)
复制表不需要数据,可以设置一个筛选条件

#修改表 ---- ALTER TABLE
DESC
#添加一个字段
ALTER TABLE 表名 ADD 字段 数据类型#默认添加到表中的最后一个字段
ALTER TABLE 表名 ADD 字段 数据类型 FIRST;放到第一个
#修改一个字段:数据类型、长度、默认值
ALTER TABLE 表名 MODIFY 字段 数据类型 DEFAULT '默认值'
#重命名一个字段
ALTER TABLE CHANGE 字段名 新的字段名 数据类型
#删除一个字段
ALTER TABLE 表名 DROP COLUMN 字段名
#重命名表
方式一:RENAME TABLE TO
方式二:ALTER TABLE RENAME TO
#删除表:不光将表结构删除,同时表中的数据也删除,释放表空间
DROP TABLE IF EXISTS
#清空表:删除表中的所有数据,但表结构保留
TRUNCATE TABLE
#DCL 中 COMMIT 和ROLLBACK
COMMIT:提交数据,一旦执行COMMIT,数据就被永久保留在数据库中,意味着数据不可以回滚
ROLLBACK:回滚操作。一旦执行,就可以实现数据的回滚,回滚到最近的一次COMMIT之后
#对比TRUNCATE和DELETE FROM
相同点:都可以实现对表中所有数据的删除,同时保留表结构
不同点:TRUNCATE TABLE:一旦执行此操作,表数据全部清除,同时,数据是不可以回滚的
DELETE FROM:一旦执行此操作,表数据可以全部清除,同时,数据是可以回滚的(不带where)
DCL 和 DML 的说明
1.DDL的操作一旦执行,就不可回滚; DML的操作默认情况下,一旦执行,也是不可以回滚的,(因为在DDL之后,一旦会操作一次commit)但是如果在执行DML之前,执行了SET autocommit = FALSE,则执行的DML操作就可以实现回滚
MYSQL8.0 DDL的原子性:要么成功要么回滚
第10章数据处理之增删改
0.储备工作
1.添加数据
方式1:一条一条的添加数据
一、没有指明添加的字段
注意:一定要按照声明的字段的先后顺序添加
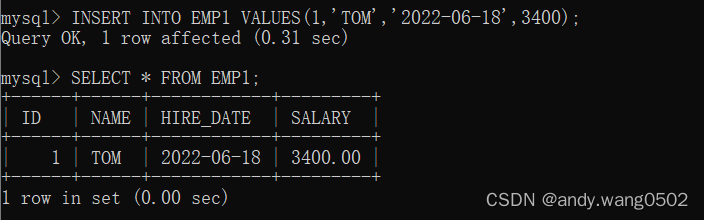
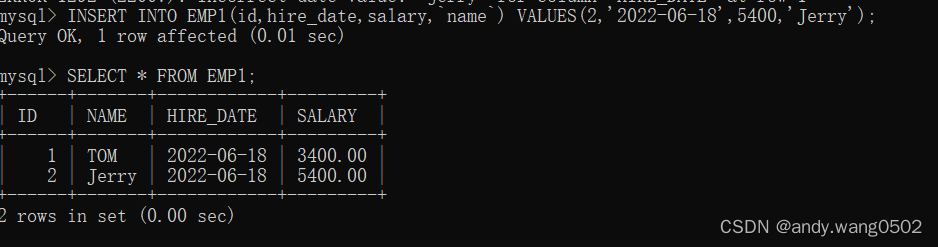
二、指明要添加的字段(推荐)
没有进行赋值的字段为null
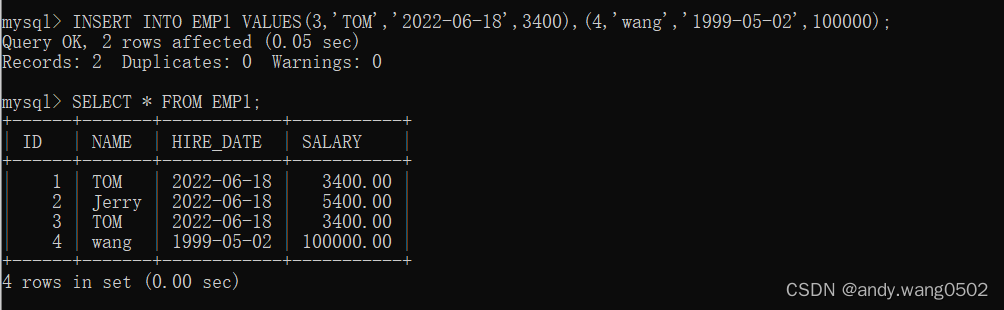
三、同时插入多条记录
方式2:将查询结果插入到表中
查询的字段一定要与添加到的表的字段一一对应
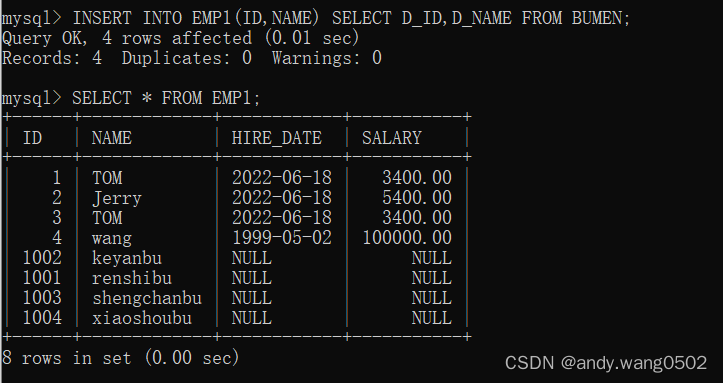
说明:要添加数据的字段不能低于查询字段的长度,否则会有添加不成功的风险
2.更新数据
UPDATE....SET....WHERE...
可以实现批量修改数据
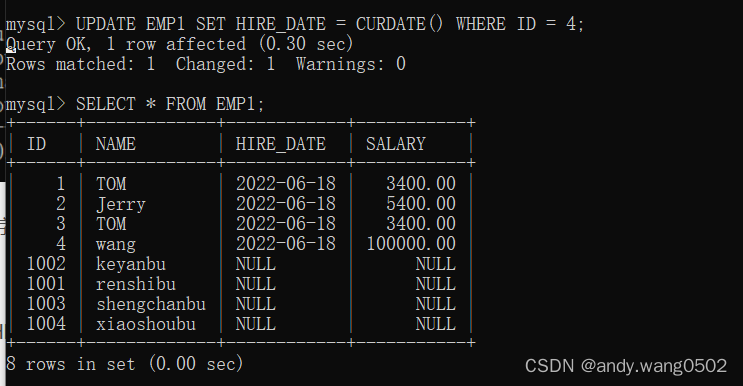
同时修改一条数据的多个字段
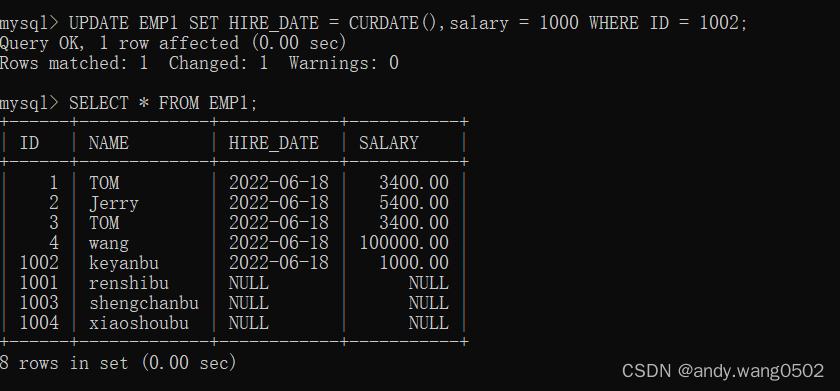
修改数据时,是可能存在不成功的情况的(可能由于约束造成)
3.删除数据
DELETE FROM .... WHERE...
小结:DML操作默认情况下,执行完以后都会自动提交数据,如果希望执行完以后不自动提交数据,则需要使用SET autocommit = false
MYSQL8新特性:计算列



第11章MySQL数据类型精讲
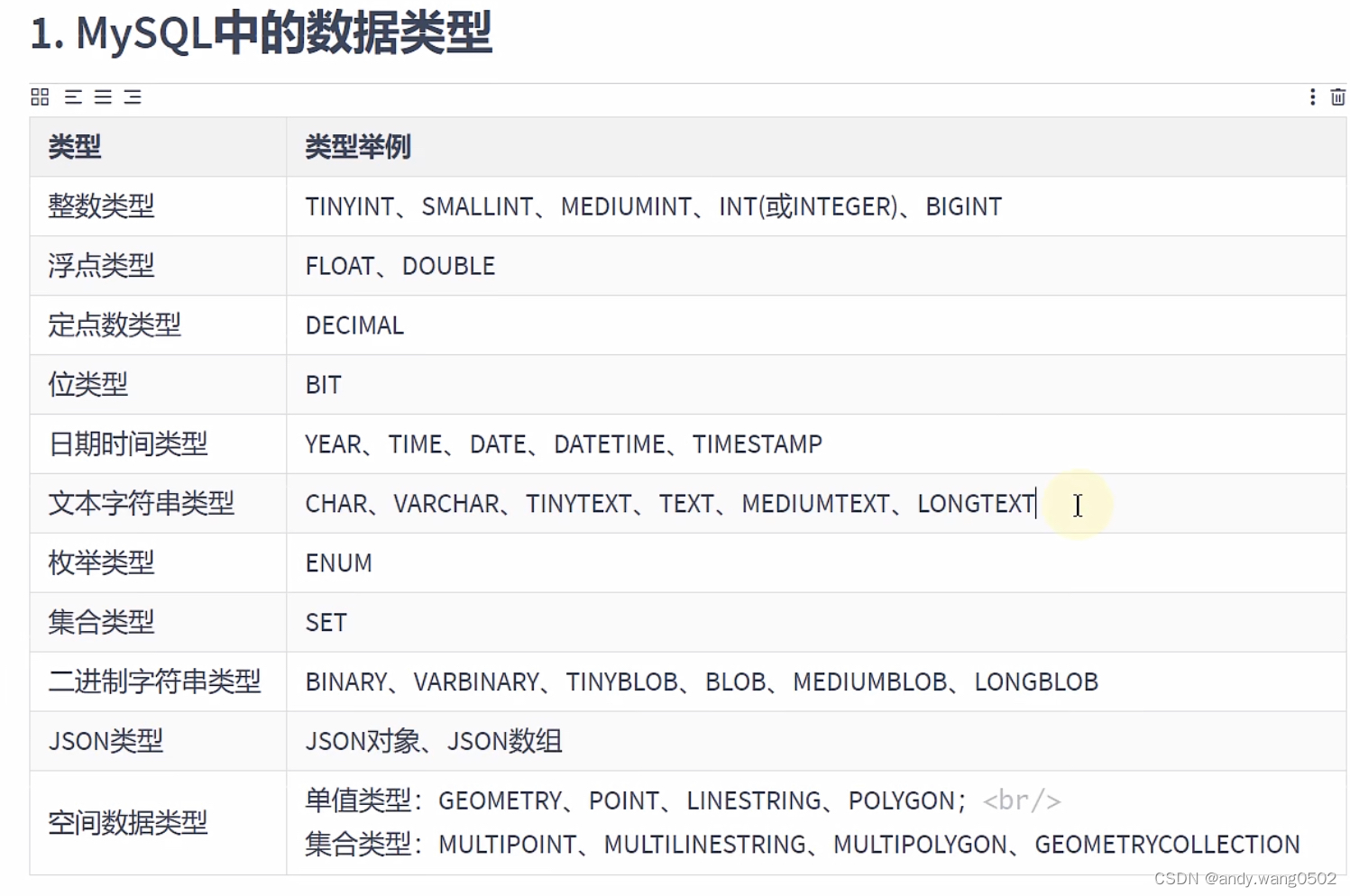
关于属性:CHARACTER SET NAME
创建数据库时指明字符集
创建表的时候,指明表的字符集
创建表,指明表中的字段时,可以指定字段的字符集
1.整数类型

可选属性:M宽度 ,配合ZEROFILL,当不足M时,用0填充
UNSIGNED 无符号
2.浮点类型
float表示单精度浮点数
double双精度浮点数

非标准语句:FLOAT(M,D) DOUBLE(M,D) M称为精度,D称为标度,(M,D)中M=整数位+小数位,D=小数位
浮点数的精度问题:浮点数是不正确的,要避免使用“=”来判断两个数是否相等
3.定点数类型(精准的)
DECIMAL(M,D),DEC, M+2字节
底层由字符串形式存储的
4.位类型BIT
存储的是二进制值,类似010101
5.日期与时间类型

6.文本字符串类型
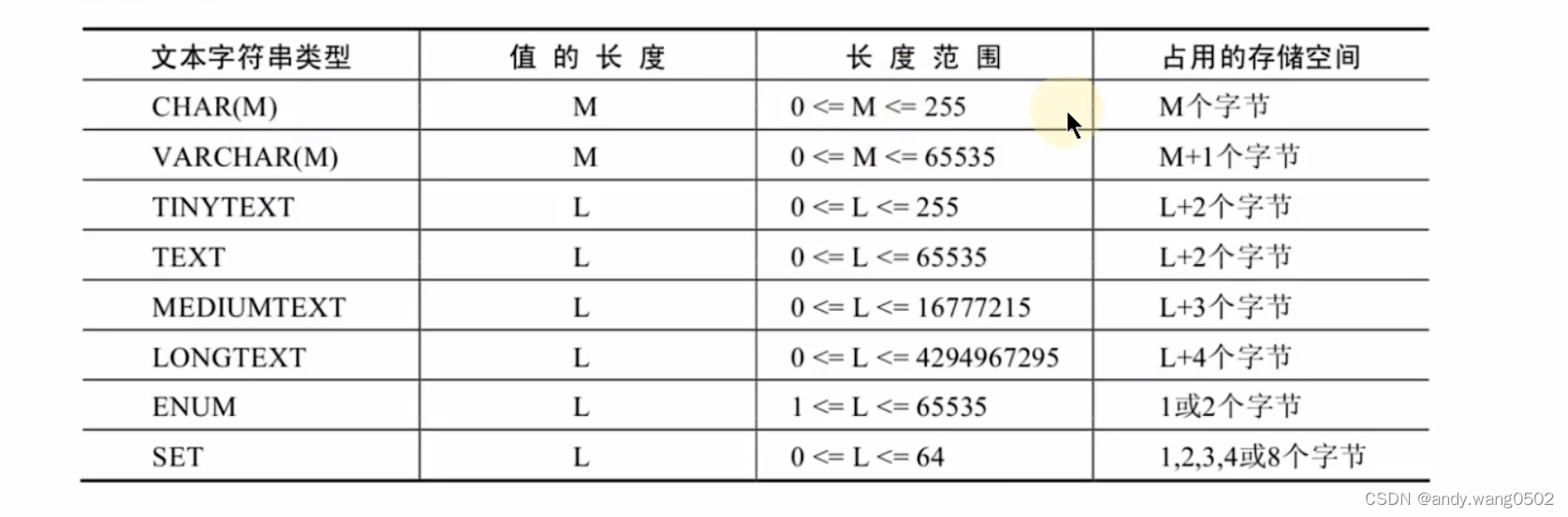
7.二进制字符串类型:存储一些二进制数据:图片、音频和视频等
分为BINARY与VARBINARY类型
BOLB存放二进制大对象
8.JSON
第12章 约束
为了保证数据的完整性,SQL规范以约束的方式对表数据进行额外的条件限制。从以下四个方面进行考虑:实体完整性、域完整性、引用完整性和用户自定义完整性
什么叫约束:对表中字段的限制
约束的分类:角度1:约束的字段的个数:单列约束VS多列约束
角度2:约束的作用范围:列级约束:声明此约束时声明在对应字段的后面
表级约束:在表中所有字段都声明完,在所有字段的后面 声明的约束
角度3:约束的作用(功能):1.not null(非空约束)2.unique(唯一性约束)3.primary key(主键约束)4.foreign key(外键约束)5.check(检查约束)6.default(默认值约束)
如何添加约束:在CREATE TABLE添加约束
在ALTER TABLE时增加约束、删除约束
如何查看表中的约束
SELECT * FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS
WHERE TABLE_NAME = '表名称';
not null(非空约束)
建表时 CREAT TABLE 表名称(
字段名 数据类型 not null ,
字段名 数据类型 not null )
在ALTER TABLE时增加约束、删除约束
ALTER TABLE 表名
MODIFY 字段名 数据类型 not null
ALTER TABLE 表名
MODIFY 字段名 数据类型 null
唯一性约束unique
建表时 CREAT TABLE 表名称(
字段名 数据类型 not null UNIQUE,#列级约束
字段名 数据类型 not null
#表级约束
CONSTRAINT uk_表名称_字段名 UNIQUE(字段名))
在创建唯一约束的时候,如果不给唯一约束命名,就默认和列名相同
可以向声明为UNIQUE的字段上添加null值,而且可以多次添加null
在ALTER TABLE时增加约束、删除约束
方式一:
ALTER TABLE 表名
ADD CONTRAINT 别名 UNIQUE(字段名)
方式二:
ALTER TABLE 表名
MODIFY 字段名 数据类型 UNIQUE
复合的唯一性约束
CREATE TABLE USER(
id INT,
`name` VARCHAR(15),
`password` VARCHAR(25),
#表级约束
CONTRAINT uk_user_name_pwd UNIQUE(`name`,`password`))
删除UNIQUE约束
添加唯一性约束的列上也会自动创建唯一索引
删除唯一约束只能通过删除唯一索引的方式删除
删除时需要指定唯一索引名,唯一索引名就和唯一约束名一样
如果创建唯一约束时未指定名称,如果是单列,就默认和列名相同;如果是组合列,那么默认和()中排在第一个的列名相同,也可以自定义唯一性约束名
#如何删除
ALTER TABLE 表名
DROP INDEX 索引名
)
PRIMARY KEY约束
一个表最多只能有一个主键约束
主键约束特征:非空且唯一,用于唯一的标识表中的一条记录
CREATE TABLE USER(
id INT PRIMARY KEY,#列级约束
`name` VARCHAR(15),
`password` VARCHAR(25))
CREATE TABLE USER(
id INT,
`name` VARCHAR(15),
`password` VARCHAR(25),
#表级约束
CONSTRAINT 别名(没有必要取名字) PRIMARY KEY(字段名))
在ALTER TABLE时添加约束
ALTER TABLE 表名
ADD PRIMARY KEY(字段名)
ALTER TABLE 表名
DROP PRIMARY KEY;
(实际开发中不会删除主键元素)
自增列:AUTO_INCREMENT
作用:某个字段的值自增
要求:(1)一个表最多只能有一个自增列 (2)当需要产生唯一标识符或顺序值时,可设置自增长(3)自增长列约束的列必须是键列(主键列,唯一键列) (4)自增约束的列的数据类型必须是整数类型 (5)如果自增列指定了0和null,会在当前最大值的基础上自增;如果自增列手动指定了具体值,直接赋值为具体值
MYSQL8.0新特性:自增变量持久化
FOREIGN KEY约束
作用:限定某个表的某个字段的引用完整性
主表和从表/父表和子表
特点:从表的外键列,必须引用、参考主表的主键或唯一约束的列
在创建建外约束时,如果不给外键约束命名,默认名不是列名,而是自动产生一个外键名,也可以指定外键约束名
创建表时就指定外键约束的话,先创建主表,再创建从表
删表时,先删除从表,在删除主表
当主标的记录被从表参照时,主表的记录将不允许删除,如果要删除数据,需要先删除从表中依赖该记录的数据,然后才可以删除主表的记录
在主表中指定外键约束,并且一个表可以建立多个外键约束
从表的外键列与主表被参照的列名字可以不相同,但是数据类型必须一样,逻辑意义一致
当创建外键约束时,系统默认会在所在的列上建立对应的普通索引
删除外键约束后,必须手动删除对应的索引
结论:对于外键约束,最好是采用: `ON UPDATE CASCADE ON DELETE RESTRICT`的方式
开发中:不得使用外键和级联
CHECK约束
检查某个字段的值是否符合xx要求,一般指的是值的范围
create table(
id INT,
salary DECIMAL(10,2) CHECK(salary > 2000)
)
DEFAULT约束
CREATE TABLE(
id INT DEFAULT 2000
)
建表时加 not null default 或 default 0
第13章视图
1.常见的数据库对象

为什么要使用视图?
帮我们使用表的一部分而不是全部的表,另外针对不同的用户制定不同的查询视图
视图的理解:
视图是一种虚拟表,本身不具有数据的,占用很少的内存,建立在已有表的基础上,视图赖以建立的这些表称为基表,对视图做DML操作,会影响对应的基表中的数据,反之亦然。
视图本身的删除,不会导致基表中数据的删除
视图的应用场景:针对小型项目,不推荐使用视图,针对大型项目,可以考虑使用视图
视图的本质可以看作是存储起来的SELECT语句
视图的优点:简化查询;控制数据的访问
创建视图:
针对于单表:
CREATE VIEW 视图名称
AS 查询语句
查看视图
语法1:查看数据库的表对象、视图对象
SHOW TABLES;
查看视图的结构
DESCRIBE 视图名称
查看视图的属性信息
SHOW TABLE STATUS LIKE `视图`
查看视图的详细定义信息
SHOW CREATE VIEW 视图名称
更新视图的数据会导致基表中数据的修改,同理更新表中的数据也会导致视图的修改
(不建议更新视图中的数据,对视图的修改都是通过对实际数据表里数据的操作来完成的)
第14章存储过程和存储函数
含义:存储过程就是一组经过预先编译的SQL语句的封装
执行过程:存储过程预先存储在MySQL服务器上,需要执行的时候,客户端只需要向服务器。发出调用存储过程的命令,服务器端就可以把预先存储好的这一系列SQL语句全部执行
视图是虚拟表,二存储过程是程序化的SQL,可以直接操作底层数据表,相比于面向集合的操作方式,能够实现一些更复杂的数据处理。
创建存储过程
CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...)
[characteristics...]
BEGIN
存储过程体
END
第15章变量、流程控制和游标
系统变量分类:系统变量(全局系统变量、会话系统变量) VS 用户自定义变量
查看系统变量:
#查看全局系统变量
SHOW GLOBAL VARIABLES
#查询会话系统变量
SHOW SESSION VARIABLES
SHOW VARIABLES#默认查询的是会话系统变量
#查询部分系统变量
SHOW GLOBAL VARIABLES LIKE 'admin_%'















 8356
8356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









