







1.2、运行时常量池
运行时常量池是每一个类或者接口的常量池(Constant Pool)的运行时的表现形式。
我们知道,一个类的加载过程,会经过:加载、连接(验证、准备、解析)、初始化的过程,而在类加载这个阶段,需要做以下几件事情:
- 通过一个类的全类限定名获取此类的二进制字节流。
- 在堆内存生成一个
java.lang.Class对象,代表加载这个类,做为这个类的入口。 - 将class字节流的静态存储结构转化成方法区(元空间)的运行时数据结构。
而其中第三点,将class字节流代表的静态储存结构转化为方法区的运行时数据结构这个过程,就包含了class文件常量池进入运行时常量池的过程。
所以,运行时常量池的作用是存储class文件常量池中的符号信息,在类的解析阶段会把这些符号引用转换成直接引用(实例对象的内存地址),翻译出来的直接引用也是存储在运行时常量池中。
class文件常量池的大部分数据会被加载到运行时常量池。

运行时常量池保存在方法区(JDK1.8元空间)中,它是全局共享的,不同的类共用一个运行时常量池。
另外,运行时常量池具有动态性的特征,它的内容并不是全部来源与编译后的class文件,在运行时也可以通过代码生成常量并放入运行时常量池。比如String.intern()方法。
1.2.1、字符串常量池
字符串常量池,简单来说就是专门针对String类型设计的常量池。
字符串常量池的常用创建方式有两种。
String a="Hello";String b=new String("Mic");
- a这个变量,是在编译期间就已经确定的,会进入到字符串常量池。
- b这个变量,是通过new关键字实例化,new是创建一个对象实例并初始化该实例,因此这个字符串对象是在运行时才能确定的,创建的实例在堆空间上。
字符串常量池存储在堆内存空间中,创建形式如下图所示。
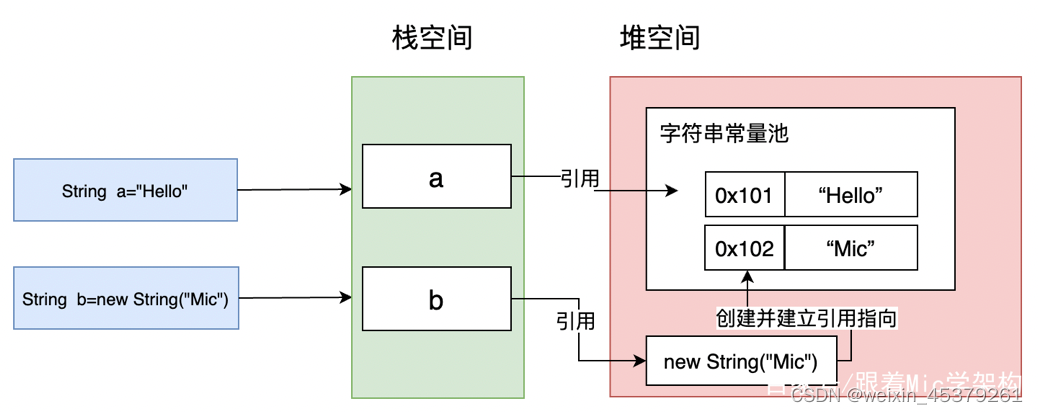
当使用String a=“Hello”这种方式创建字符串对象时,JVM首先会先检查该字符串对象是否存在与字符串常量池中,如果存在,则直接返回常量池中该字符串的引用。否则,会在常量池中创建一个新的字符串,并返回常量池中该字符串的引用。(这种方式可以减少同一个字符串被重复创建,节约内存,这也是享元模式的体现)。
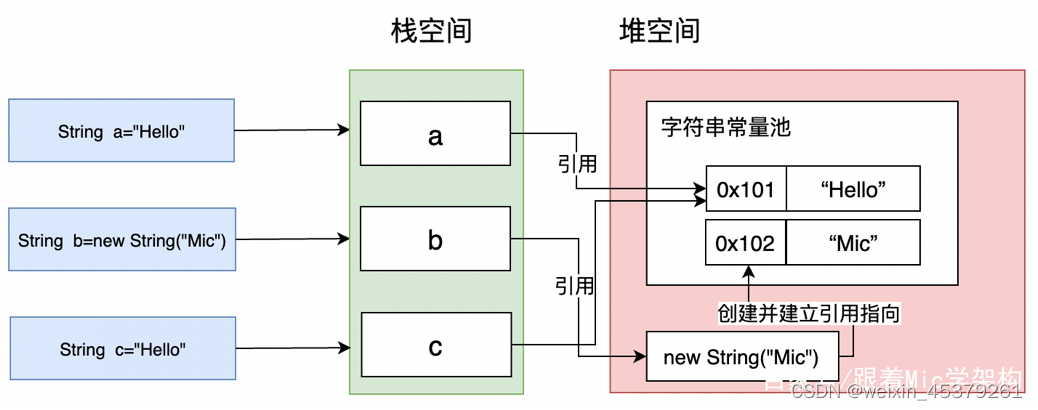
如下图所示,如果再通过String c=“Hello”创建一个字符串,发现常量池已经存在了Hello这个字符串,则直接把该字符串的引用返回即可。(String里面的享元模式设计)
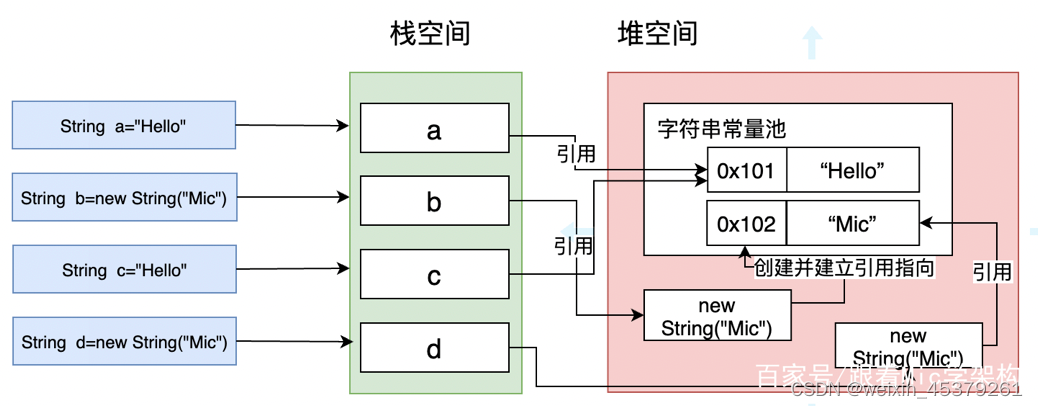
当使用String b=new String(“Mic”)这种方式创建字符串对象时,由于String本身的不可变性(后续分析),因此在JVM编译过程中,会把Mic放入到Class文件的常量池中,在类加载时,会在字符串常量池中创建Mic这个字符串。接着使用new关键字,在堆内存中创建一个String对象并指向常量池中Mic字符串的引用。
如下图所示,如果再通过new String(“Mic”)创建一个字符串对象,此时由于字符串常量池已经存在Mic,所以只需要在堆内存中创建一个String对象即可。
简单总结一下:JVM之所以单独设计字符串常量池,是JVM为了提高性能以及减少内存开销的一些优化:
- String对象作为Java语言中重要的数据类型,是内存中占据空间最大的一个对象。高效地使用字符串,可以提升系统的整体性能。
- 创建字符串常量时,首先检查字符串常量池是否存在该字符串,如果有,则直接返回该引用实例,不存在,则实例化该字符串放入常量池中。
字符串常量池是JVM所维护的一个字符串实例的引用表,在HotSpot VM中,它是一个叫做StringTable的全局表。
在字符串常量池中维护的是字符串实例的引用,底层C++实现就是一个Hashtable。
这些被维护的引用所指的字符串实例,被称作”被驻留的字符串”或”interned string”或通常所说的”进入了字符串常量池的字符串”!
1.2.2、封装类常量池
除了字符串常量池,Java的基本类型的封装类大部分也都实现了常量池。包括Byte,Short,Integer,Long,Character,Boolean
注意,浮点数据类型Float,Double是没有常量池的。
封装类的常量池是在各自内部类中实现的,
比如IntegerCache(Integer的内部类)。
要注意的是,这些常量池是有范围的:
- Byte,Short,Integer,Long : [-128~127]
- Character : [0~127]
- Boolean : [True, False]
测试代码如下:
public static void main(String[] args) {
Character a=129;
Character b=129;
Character c=120;
Character d=120;
System.out.println(a==b);
//定义的数字大于Character包装类常量池的范围。
System.out.println(c==d);
System.out.println("...integer...");
Integer i=100;
Integer n=100;
Integer t=290;
Integer e=290;
System.out.println(i==n);
System.out.println(t==e);
//定义的数字大于Integer包装类常量池的范围。
}
运行结果:
false true…integer…true false
封装类的常量池,其实就是在各个封装类里面自己实现的缓存实例(并不是JVM虚拟机层面的实现),
如在Integer中,存在IntegerCache,提前缓存了-128~127之间的数据实例。
意味着这个区间内的数据,都采用同样的数据对象。
这也是为什么上面的程序中,通过 == 判断得到的结果为true。
这种设计其实就是享元模式的应用。
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue = sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i =parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low)-1);
}
catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
........
封装类常量池的设计初衷其实和String相同,也是针对频繁使用的数据区间进行缓存,避免频繁创建对象的内存开销。
1.2.3、关于字符串常量池的问题探索
在上述常量池中,关于String字符串常量池的设计,还有很多问题需要探索:
- 如果常量池中已经存在某个字符串常量,后续定义相同字符串的字面量时,是如何指向同一个字符串常量的引用?也就是下面这段代码的断言结果是true。
String a="Mic";String b="Mic";assert(a==b); //true- 字符串常量池的容量到底有多大?
- 为什么要设计针对字符串单独设计一个常量池?
1.2.3、为什么要设计针对字符串单独设计一个常量池?
首先,我们来看一下String的定义。
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash;
// Default to 0
}
从上述源码中可以发现。
-
String这个类是被final修饰的,代表该类无法被继承。
-
String这个类的成员属性value[]也是被final修饰,代表该成员属性不可被修改。
-
因此String具有不可变的特性,也就是说String一旦被创建,就无法更改。这么设计的好处有几个:
- 3.1、方便实现字符串常量池: 在Java中,由于会大量的使用String常量,如果每一次声明一个String都创建一个String对象,那将会造成极大的空间资源的浪费。Java提出了String pool(串池)的概念,在堆中开辟一块存储空间String pool(串池),当初始化一个String变量时,如果该字符串已经存在了,就不会去创建一个新的字符串变量,而是会返回已经存在了的字符串的引用。如果字符串是可变的,某一个字符串变量改变了其值,那么其指向的变量的值也会改变,String pool将不能够实现!
- 3.2、线程安全性,在并发场景下,多个线程同时读一个资源,是安全的,不会引发竞争,但对资源进行写操作时是不安全的,不可变对象不能被写,所以保证了多线程的安全。
- 3.3、保证 hash 属性值不会频繁变更。确保了唯一性,使得类似HashMap容器才能实现相应的key-value缓存功能,于是在创建对象时其hashcode就可以放心的缓存了,不需要重新计算。这也就是Map喜欢将String作为Key的原因,处理速度要快过其它的键对象。所以HashMap中的键往往都使用String。
注意,由于String的不可变性可以方便实现字符串常量池这一点很重要,这是实现字符串常量池的前提。
字符串常量池小结
小结:字符串常量池,其实就是享元模式的设计,它和在JDK中提供的IntegerCache、以及Character等封装对象的缓存设计类似,只是String是JVM层面的实现。
字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价。JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化。
-
为了减少在JVM中创建的字符串的数量,字符串类维护了一个字符串池,每当代码创建字符串常量时,JVM会首先检查字符串常量池。
-
如果字符串已经存在池中,就返回池中的实例引用。
-
如果字符串不在池中,就会实例化一个字符串并放到串池中。Java能够进行这样的优化是因为字符串是不可变的,可以不用担心数据冲突进行共享。
-
我们把字符串常量池当成是一个缓存,**通过双引号定义一个字符串常量时,首先从字符串常量池中去查找,**找到了就直接返回该字符串常量池的引用,否则就创建一个新的字符串常量放在常量池中。















 2220
2220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









