







一、引入深度学习

假设A选取数字是有规律的,与他选取范围的上限有关
构建模型预测A心里想的数字
1.抽象过程
模型输入:A给出的上限数值
模型输出:A心里想的数值
首先B随便猜一个数 ----模型随机初始化
模型函数 :Y = k * x (此样本x = 100)
此例子中B选择的初始k值为0.6
A计算B的猜测与真正答案的差距 ----计算loss
损失函数 = sign(y_true – y_pred)
A告诉B偏大或偏小 ----得到loss值
B调整了自己的“模型参数” ----反向传播
参数调整幅度依照B自定的策略 ----优化器&学习率
重复以上过程 最终B的猜测与A的答案一致 ----loss = 0
2.优化方式
为快速获得正确模型,AB可以优化的地方
(1)随机初始化
假如B一开始选择的k值为88,则直接loss=0
NLP中的预训练模型实际上就是对随机初始化的技术优化
(2)优化损失函数
假如损失函数为loss = y_true – y_pred,即当B猜测60的时候,A告知低了28
(3)B调整参数的策略
B采取二分法调整,50 -> 75 -> 88
(4)调整模型结构
不同模型能够拟合不同的数据集
二、人工神经网络
人工神经网络(Artificial Neural Networks,简称ANNs),也简称为神经网络(NN)。它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。
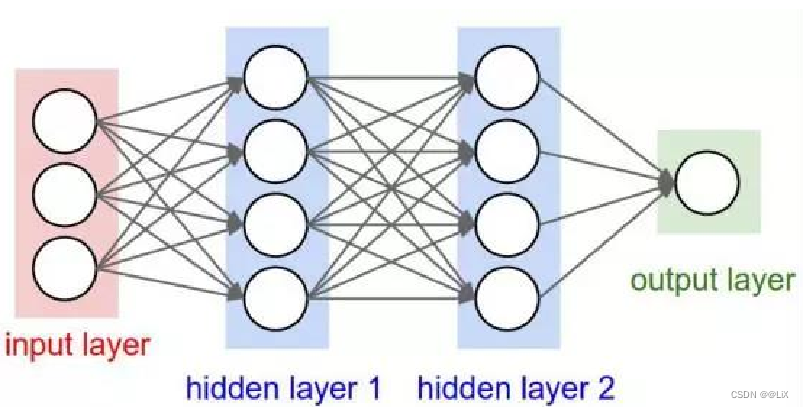
1.相关概念
(1)隐含层/中间层
神经网络模型输入层和输出层之间的部分,隐含层可以有不同的结构: RNN、CNN、DNN、LSTM、Transformer 等等,它们本质上的区别只是不同的运算公式
(2)随机初始化
隐含层中会含有很多的权重矩阵,这些矩阵需要有初始值,才能进行运算;初始值的选取会影响最终的结果;一般情况下,模型会采取随机初始化,但参数会在一定范围内;在使用预训练模型一类的策略时,随机初始值被训练好的参数代替
(3)损失函数
损失函数(loss function或cost function)用来计算模型的预测值与真实值之间的误差。模型训练的目标一般是依靠训练数据来调整模型参数,使得损失函数到达最小值。损失函数有很多,选择合理的损失函数是模型训练的必要条件。
(4)导数与梯度
导数表示函数曲线上的切线斜率。 除了切线的斜率,导数还表示函数在该点的变化率。
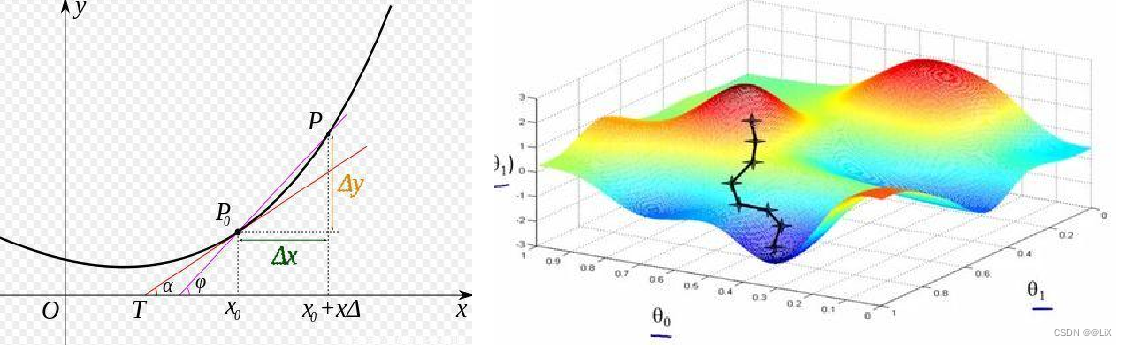
(5)梯度下降
梯度表示函数向哪个方向增长最快,那么他的反方向,就是下降最快的方向。梯度下降的目的是找到函数的极小值,因为我们最终的目标是损失函数值最小
(6)优化器
假如一步走太大,就可能错过最小值,如果一步走太小,又可能困在某个局部低点无法离开
学习率(learning rate),动量(Momentum)都是优化器相关的概念
(7)Mini Batch/epoch
一次训练数据集的一小部分,而不是整个训练集,或单条数据;它使得内存较小、不能同时训练整个数据集的电脑也可以训练模型。
它是一个可调节的参数,会对最终结果造成影响;不能太大,因为太大了会速度很慢。 也不能太小,太小了以后可能算法永远不会收敛。
我们将遍历一次所有样本的行为叫做一个 epoch
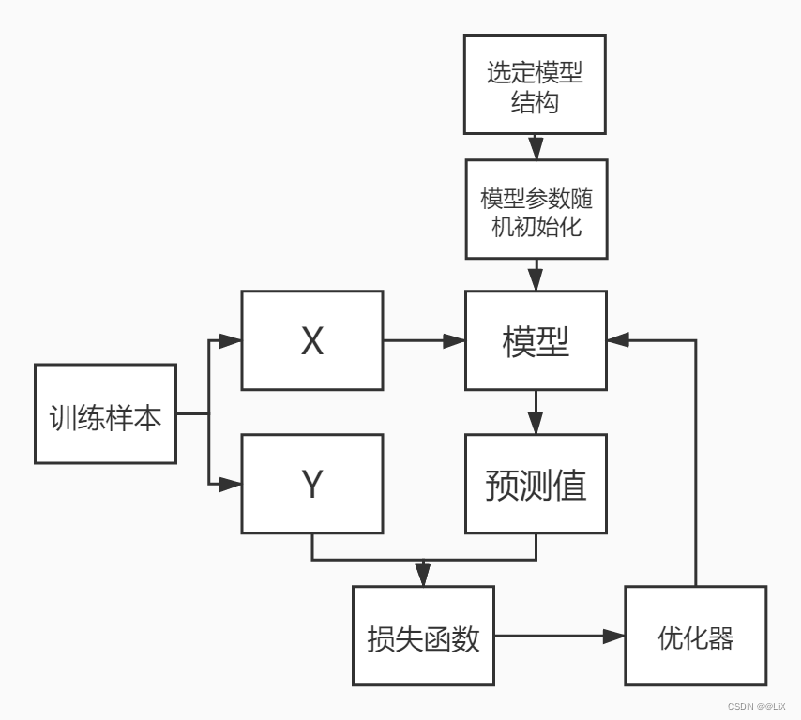
训练迭代进行:模型训练好后把参数保存即可用于对新样本的预测
要点:
模型结构选择
初始化方式选择
损失函数选择
优化器选择
样本质量数量
三、总结
机器学习的本质,是从已知的数据中寻找规律,用来预测未知的样本
深度学习是机器学习的一种方法
深度学习的基本思想:
选公式->参数随机初始化->标注数据算误差->根据误差调整参数
简而言之,“先猜后调”



























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











