






pandas库
1.输出数据集的前n行:head
import pandas as pd
df=pd.read_csv("seed.csv")
print(df.head(n-1))
2.输出数据集的行数与列数:shape
print(df.shape)
返回值为(13,5),代表13行5列
3.输出某一行或者某几行,某一列或者某几列:loc和iloc
4.判断缺失值:isnull
返回的是值为False/True的矩阵
1.df.isnull()
import pandas as pd
df=pd.read_csv("HR.csv")
print(df.isnull())

2.df.isnull.any()表示判断哪些”列”存在缺失值
import pandas as pd
df=pd.read_csv("HR.csv")
print(df.isnull().any())

注:检查数字列表里是否有空值
tmp = table.row_values(i)
if u'' in tmp:
以下代码的前提
import pandas as pd
df=pd.read_csv("seed.csv")
或者
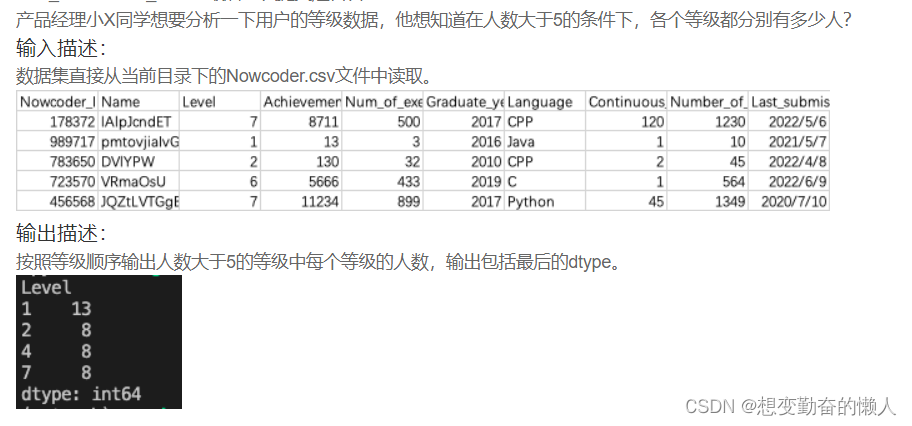
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Name:用户名
Level:等级
5.筛选符合条件的行:“==”,query
print(df[df['Age']==23])#找到age这一列所有年龄为23的并输出所在的行,包括行号
#df['Age']==23返回的值是True和False
print(df.query('Age==23 & Native==40'))#两个条件
df=new.query("department=='functional' & item_name=='javelin'")
#另一种方法
print(nowcoder.groupby('Level').Name.count()>5)
#如下图
6.输出部分列的数据
print(df[['Age','AnnualIncome']])
print(df[['Age','AnnualIncome']].loc[1,:])#输出部分列部分行的数据
7.输出后几行的数据:tail
print(df[['Age','AnnualIncome']].tail(3))
8.逻辑运算,同时满足几个条件:query
print(df.query('Age==23 | Age==25 | Native==30'))
注:&和and的用法一样,|和or的用法一样
9.一列中不同值的个数:value_counts()
print(df.Age.value_counts())
print(df['Age'].value_counts())#返回的是series
#两种用法相同
10.求一列的最大值和最小值,平均数,中位数,众数,分位数,方差,标准差,求和:max,min,mean,median,mode,quantile,var,std,sum
print(df['Age'].min())
print(df['Age'].max())
print(df.Age.mean())
print(int(Nowcoder.query("Num_of_exercise>=10").Level.median()))#为什么加int呢?
print(df.Age.mode())
print(df['Age'].quantile(0.25))
print(Nowcoder['Num_of_exercise'].var().round(2))#求方差,保留两位小数
print(Nowcoder['Number_of_submissions'].std().round(2))#求标准差
A_sum=Nowcoder.Achievement_value.sum()
11.保留小数:round
ddf=df.query('Workclass==5').Age.mean()
print(round(ddf,1))#求有条件的一列数的平均数并保留一位小数
12.计算一列数不同值的个数以及按顺序输出不同值:unique,nunique,value_counts,drop_duplicates
print(df['Age'].unique())#返回n维数组,是有哪些不同的值,按顺序
print(df['Age'].nunique())#一共有几个种类
print(df['Age'].value_counts())#返回series(带索引的数组)
print(df['Age'].value_counts().keys())#返回的是list
print(df['Age'].unique().tolist())#将数组转换成列表
print(df['Age'].drop_duplicates())#去重,返回series,返回的是值(不同的
print(df['Age'].drop_duplicates().tolist())
print(df['Age'].drop_duplicates().count())#返回不同值的个数
注:.value_counts() 统计不同值的个数,不包括 NaN;unique() 用来展示每个不同的值,包括 NaN
13.变量类型的转换
1.转换成dataframe
print(df.Age.mode())#求众数,输出的是series类型,一般输出值后面有Name: Age, Length: 200, dtype: int64
print(df.Age.mode().to_frame('Age'))#转换成dataframe类型,会包含表头
print(type(df['Age']))#类型是series
print(type(df[['Age']]))#类型是dataframe
14.输出一列字符串的长度:str.len
print(Nowcoder.Name.str.len())
#用于确定Pandas系列中每个字符串的长度。此方法仅适用于一系列字符串。由于这是一个字符串方法,因此必须在每次调用.str之前添加前缀。否则会产生错误。
15.更换列名
df['age']=df['Age']
16.count和value_counts的区别:
17.排序:sort_values
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
by:要排序的名称或名称列表。(如果轴为 0 或“索引”,则 by 可能包含索引级别或列标签。如果轴为 1 或“列”,则 by 可能包含列级别或索引标签。
axis:要排序的轴。若axis=0或’index’,则按照指定列中数据大小排序;若axis=1或’columns’,则按照指定索引中数据大小排序,默认axis=0
ascending:bool或bool的列表,默认为True,即为升序排列。 为多个排序顺序指定列表。如果这是一个布尔值列表,则必须匹配by的长度。
inplace:是否用排序后的数据集替换原来的数据,默认为False,即不替换。
kind: 排序算法的选择。对于DataFrames,此选项仅在对单个列或标签排序时应用。
na_position:如果是第一个,则将NaNs放在开头;如果是最后一个,把NaNs放在最后。
ignore_index:如果为True,则结果轴将被标记为0,1,,n - 1。
key:在排序之前对值应用键函数。这类似于内置sorted()函数中的key参数,显著的区别是这个key函数应该是向量化的。它应该期望一个Series,并返回一个与输入具有相同形状的Series。它将被独立地应用到每一列。
例:
print(sales.sort_values(by='monetary',ascending=False).head(3)#按降序排列,并且输出排序后的前三行
print(sales.sort_values(by='monetary',ascending=False).head(3).reset_index(drop=True))#索引从0开始















 2180
2180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









