







本篇仅仅分享设计思路,感兴趣自行下载学习!
一、项目背景

本文介绍了基于Python的B站视频的数据分析可视化系统设计与实现。该系统帮助用户深入了解B站视频的趋势,并通过数据分析和可视化技术展示相关信息。利用Python的网络爬虫技术获取B站上的视频数据,包括视频标题、上传者、播放量、点赞数等信息。借助数据分析库Pandas对获取的数据进行处理和分析,例如计算了不同用户视频发布个数、粉丝量、视频长度、视频观阅人数,还分析了不同视频的舆情分布和流行趋势。接着,利用可视化库Echarts将分析结果呈现为图表,例如柱状图、饼图、折线图等,以便用户直观地理解数据。为了提供更加个性化的服务,系统还集成了协同过滤算法推荐功能,根据用户的历史观看记录和偏好,推荐可能感兴趣的视频。最后,设计并实现了一个交互式的用户界面,用户可以通过界面选择感兴趣的话题和日期范围,系统将动态展示相关视频的数据分析结果。通过本系统,用户可以更好地了解B站视频的特点和趋势,同时享受到个性化的视频推荐服务,为用户提供了一个便捷而全面的数据分析工具。
设计文档下载学习: 基于Python的B站视频数据分析可视化系统论文
二、技术栈
2.1 网络爬虫技术
网络爬虫技术是一个能自动获取网上信息的技术,其工作流程一般包括以下几个步骤:确定爬取的起始页面,这可以是一个或多个URL。爬虫程序通过HTTP请求获取页面的内容,可以是HTML、XML、JSON等格式。爬虫解析页面内容,提取出所需的信息,如链接、文本、图片等。在解析过程中,爬虫可能需要处理页面结构的变化、编码方式、反爬虫机制等问题。爬虫将提取到的信息保存到本地文件或者传输到其他系统进行进一步处理。
2.2 Python简介
Python 是一种面向对象的程序设计语言,功能强大,具有很多区别于其他语言 的个性化特点,其标准库涵盖了众多常用功能模块,如文件操作、网络通信、数据库连接等,使得开发者能够快速构建各种应用程序[6]。Python还拥有NumPy、Pandas、Matplotlib、TensorFlow等大量的第三方库和框架,可以帮助用户对获取的视频数据进行分析、可视化和统计,从而深入了解视频的趋势和特点,还能够帮助用户构建推荐系统,根据用户的兴趣和行为数据推荐他们可能感兴趣的视频。为数据科学、机器学习等领域提供了强大的支持。
2.3 MySQL数据库
MySQL 是一个多用户的 SQL 数据库,广泛应用于Web应用程序的后端数据存储、数据分析、在线交易处理等领域[7]。MySQL支持多种操作系统平台,同时也提供了Python、Java、PHP等多种编程语言的API,使得开发者可以方便地与MySQL数据库进行交互。
MySQL数据库采用了标准的SQL语言进行数据管理和操作,具有强大的数据存储和查询能力。它支持事务处理、索引、视图、存储过程、触发器等数据库特性,以及多种数据类型和约束,如整数、浮点数、字符串、日期时间等,满足了各种数据存储和处理需求[8]。MySQL还支持分布式数据库架构、主从复制、分区表等高级特性,可以满足大规模应用场景下的数据管理和扩展需求。
2.4 Echarts可视化
ECharts提供了丰富的图表类型,包括折线图、柱状图、饼图、雷达图、0散点图等,以及各种动画效果和交互功能,如数据缩放、拖拽、悬停提示等,使得用户能够直观地展示和探索数据,ECharts支持主流的Web浏览器,并提供了丰富的API和配置选项,方便开发者根据需求定制图表样式和行为,在展示数据上起着十分关键的作用。
2.5 协同过滤算法
协同过滤算法是一种常用于推荐系统的技术,它基于用户的历史行为数据,比如用户的点击、观看、评分等,来发现用户间的相似性或者视频间的相似性,从而进行个性化推荐,实现视频推荐的功能。
协同过滤算法可以根据用户的观看历史、点赞记录等行为数据,计算用户之间的相似度。通过分析用户之间的行为模式,可以找到具有相似兴趣的用户群体,从而向某个用户推荐其相似用户喜欢的视频。用户就能够发现更多与其兴趣相关的视频内容,提升了用户体验。
协同过滤算法也可以基于视频的内容特征进行推荐。通过分析视频的标签、描述、类别等信息,可以计算视频之间的相似度。当用户观看了某个视频后,系统可以根据该视频的内容特征,向用户推荐与其相似度较高的其他视频。这种基于内容的推荐方式能够更好地满足用户的个性化需求,提高推荐的准确性。
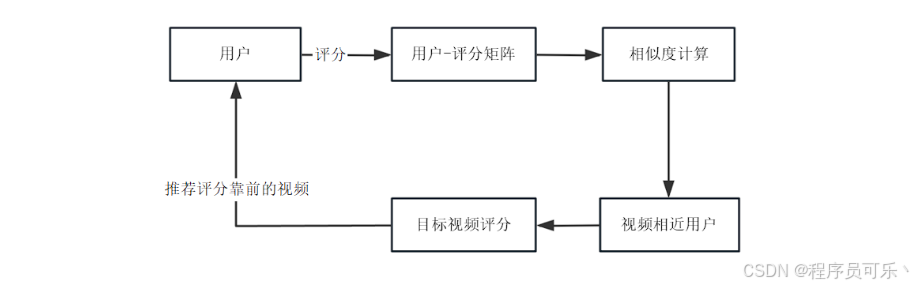
三、系统架构设计
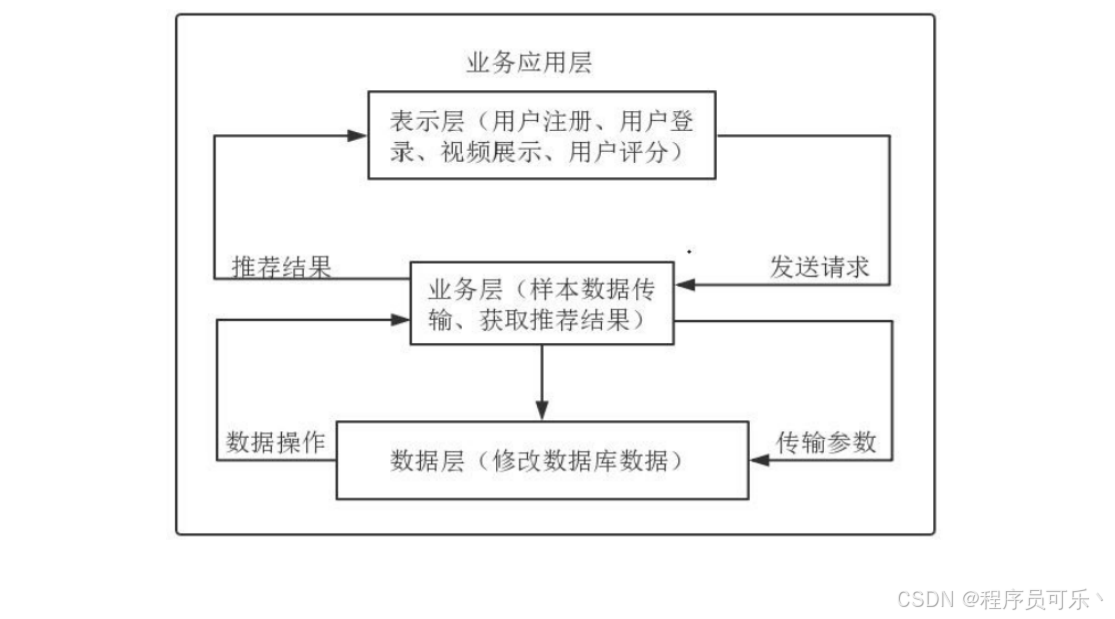
1.业务应用层:该层负责处理用户与系统的交互,包括接收用户请求、呈现页面、处理用户输入等。在这个系统中,业务应用层通过Web应用框架Flask搭建用户界面,提供给用户数据查询、分析和可视化的功能。用户通过页面交互与系统进行数据查询、分析、和可视化操作。
2.表示层:表示层是系统中用户直接接触的界面部分,包括前端界面设计和交互逻辑。通过HTML、CSS、JavaScript等技术构建,实现用户友好的数据展示和操作界面。在B站视频数据分析可视化系统中,表示层负责展示数据分析结果、提供交互式可视化图表,以及响应用户的操作和查询请求。
3.业务层:业务层是系统的核心部分,负责实现业务逻辑和处理各种业务需求。在该系统中,业务层主要包括数据处理、分析和特征提取等功能,以及与数据层的交互。通过Python编写数据处理和分析的算法,实现对B站视频数据的清洗、转换、分析等操作。
4.数据层:数据层负责管理系统所需的数据,包括数据的存储、获取、更新和删除等操作。在B站视频数据分析可视化系统中,数据层主要涉及到数据的获取(使用网络爬虫技术)、存储(通常采用数据库)、以及提供数据访问接口供业务层调用。数据层使用Python库来操作数据库(如MySQL、MongoDB等),以及实现数据获取和存储的功能。
数据库设计
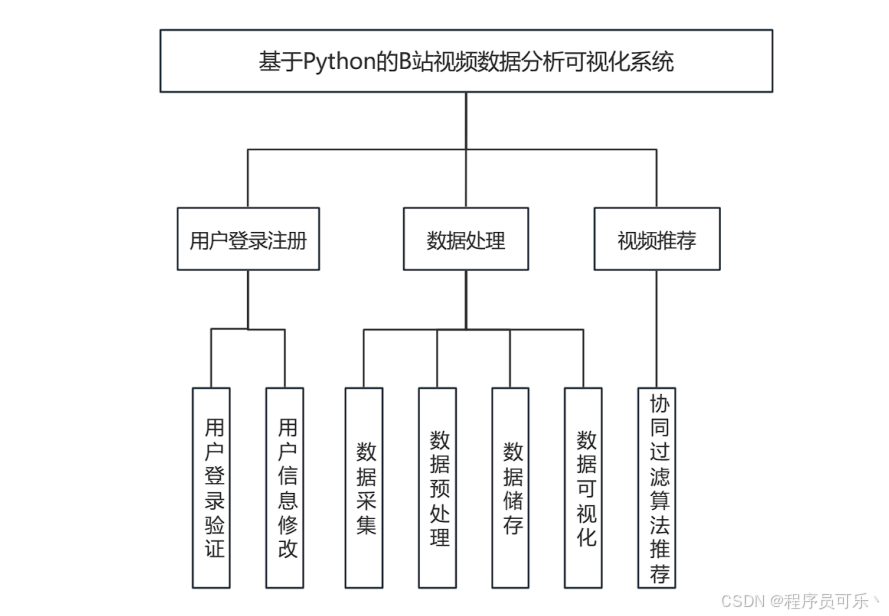
四、模块设计
该系统的功能模块设计包括用户登录注册、数据处理模块。
用户的登录注册模块负责用户的注册登陆以及信息修改。
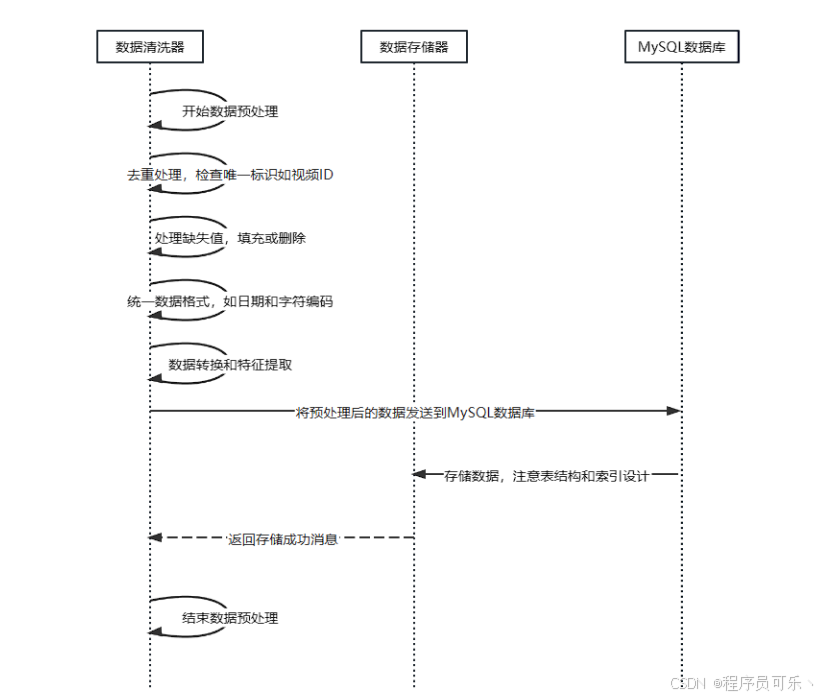
数据处理模块包括:数据获取,负责从B站获取视频数据,并将数据传递给数据预处理模块;数据预处理,对获取的数据进行清洗和转换;数据储存,对预处理完成的数据进行保存,存储成sql文件形式;数据可视化展示,利用ECharts等可视化库将分析结果以图表形式展示给用户。
视频推荐模块:利用协同过滤算法,计算用户与视频的交出数据,进而做出视频的推荐。
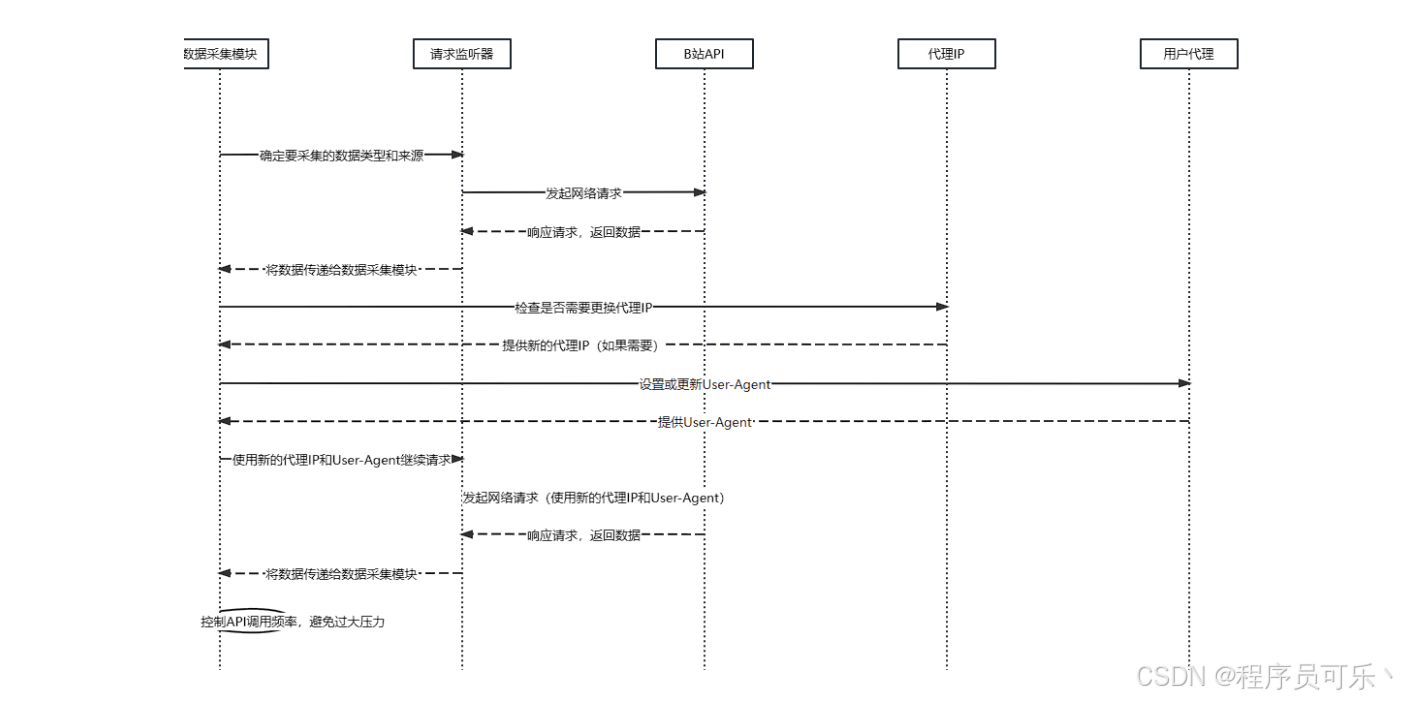
B站数据采集模块设计
设计B站数据采集模块时,首先需要明确采集的数据类型和来源。采集目标视频的相关数据,包括视频标题、上传者、播放量、评论点赞数等信息。这些数据可以通过B站提供的API接口获取,因为B站开放了一些API接口供开发者使用,以便获取相关信息。
确定采集方法后,考虑到B站API接口的便捷性和合法性,本文选择通过调用API来获取数据。在使用Python编程语言,并结合网络请求库Requests库,来向B站的API发送请求并获取数据。对于API请求的频率和速率,需要进行适当的控制,以避免对B站服务器造成过大的负载压力。
在数据采集的过程中,可能会遇到一些反爬虫机制。为了应对这些情况,在请求头中添加一些模拟正常用户行为的信息User-Agent,从而降低被识别为爬虫的风险。
B站数据预处理模块设计
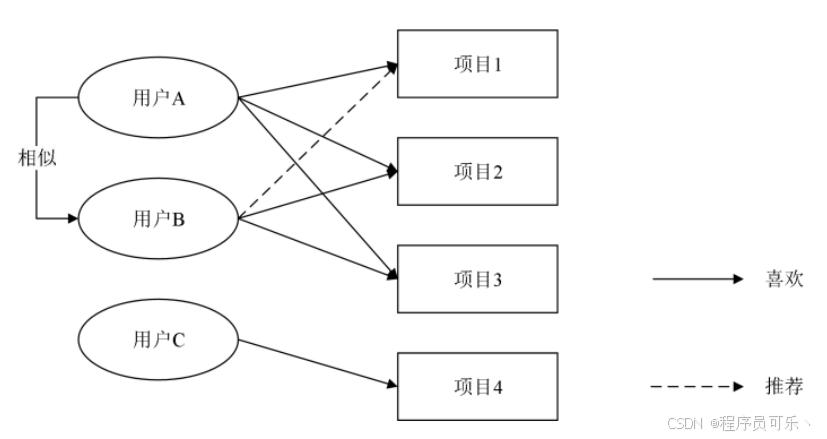
基于用户的协同过滤算法模块设计
1.用户相似度计算:首先,需要计算用户之间的相似度。使用不同的相似度度量方法,如余弦相似度、皮尔逊相关系数等。这些方法可以基于用户的行为数据计算用户之间的相似度。
2.相似用户的视频选择:对于目标用户,找到与其相似度最高的一组用户,即相似用户集合。然后,从这些相似用户观看过但目标用户尚未观看过的视频中进行选择,作为推荐给目标用户的视频。
3.推荐列表生成:将选择的视频组合成一个推荐列表,按照一定的规则和优先级排序,向目标用户展示。
4.反馈处理:根据用户的反馈信息,不断更新用户的喜好和相似度信息,从而改进推荐的准确性。
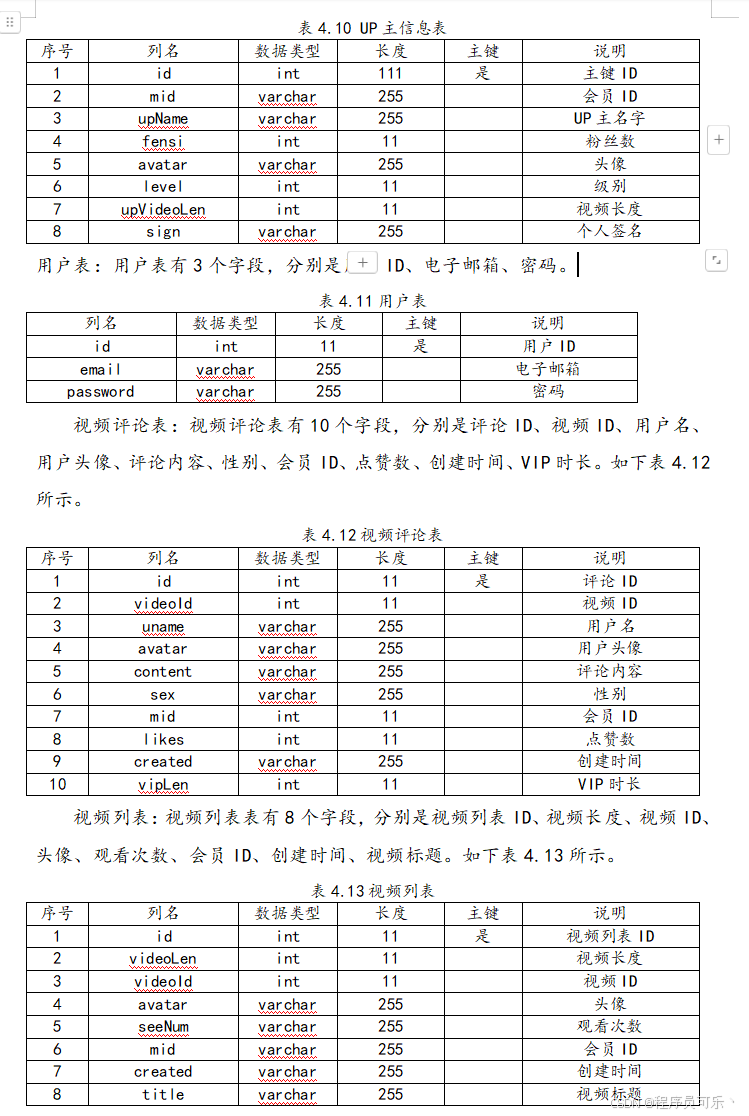
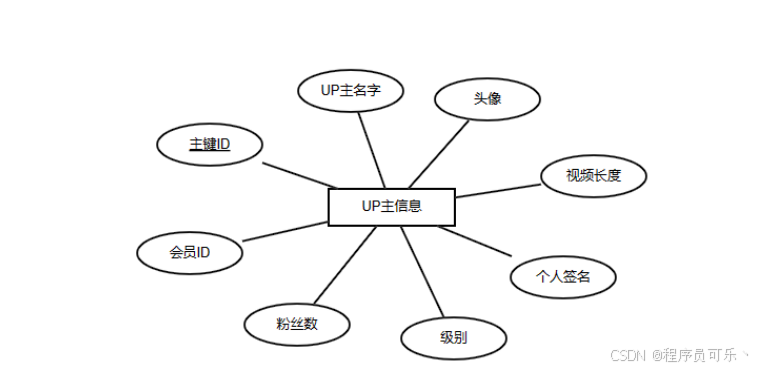
E-R图(实体-关系图)是数据库概念设计中使用的一种图形化工具,用于表示实体类型、实体之间的关系以及实体的属性。本文的实体有UP主信息、用户信息、评论信息、视频信息。各实体的E-R图如下所示。
UP主信息实体:UP主信息实体包括主键ID、会员ID、UP主名字、粉丝数、头像、级别、视频长度、个人签名。
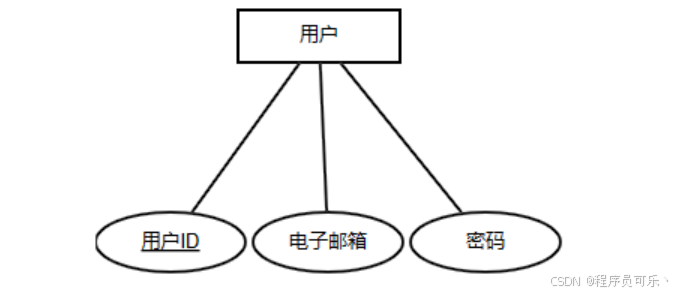
用户实体:用户实体包括用户ID、电子邮箱、密码。
视频评论实体:视频评论实体包括评论ID、视频ID、用户名、用户头像、评论内容、性别、会员ID、点赞数、创建时间、VIP时长。

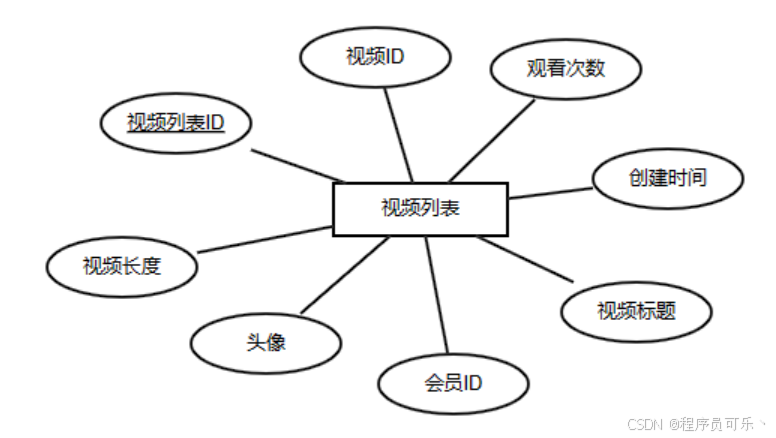
视频列表实体:视频列表实体包括视频列表ID、视频长度、视频ID、头像、观看次数、会员ID、创建时间、视频标题。
参考文献


感兴趣自行下载学习

设计文档下载学习: 基于Python的B站视频数据分析可视化系统论文
本篇分享设计思路,感兴趣自行下载学习!
支持项目定制,支持功能修改,感兴趣联系!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











