







MYSQL
数据库的操作
创建数据库:create database if not exists db_name;
使用数据库:use db_name;
删除数据库:drop database if exists db_name;
显示数据库:show databases;
查看当前位置:select database();
数据库表操作
创建表:
create table db_name{
fielname type,
fielname type1
};
--为了方便其它命令的介绍,这里创建一个学生表stu
create table db_name{
id int,
name varchar(20),
grade float
};
显示数据库中所有表名:
show tables from 数据库名;
查看表结构:
desc stu;
describe stu;

删除表:
drop table if exists stu;
数据库表的增删改查(CRUD)
新增:
insert into stu values(1,'海涛',99.9);
insert into stu values(2,'小章',92.1);
insert into stu values(3,'小刘',89.3);
insert into stu values(5,'小白',56.8) (6,'大曹',89);
insert into stu values (7,'不都',89);
-- 部分列插入
insert into stu (id,name) values(4,'半藏');
查询:
--全列查询
select * from stu;
--指定列查询
select name from stu;

去重:distinct
--查询字段1,并去掉重复值
select distinct grade from stu;

排序:order by
--asc为升序
--desc为降序
--默认是asc
select * from stu order by grade asc;
select * from stu order by grade desc;


条件查询:where
| 比较运算符 | 说明 |
|---|---|
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,null不安全,例如null=null结果是null |
| <=> | 等于,null安全,例如null<=>null是true(1) |
| !=,<> | 不等于 |
| between a0 and a1 | 范围匹配[a0,a1],如果 a0 <= value <= a1,返回 true(1) |
| in(option,…) | 如果是option中的任意一个,返回true(1) |
| is null | 是null |
| is not null | 不是null |
| like | 模糊查询。%表示任意多个(包括0)任意字符;_表示任意一个字符 |
--查询分数在[80,90]的学生的信息
select * from stu where grade between 80 and 90;
--使用and也可以实现
select * from stu where grade >=80 and grade <=90;

in:
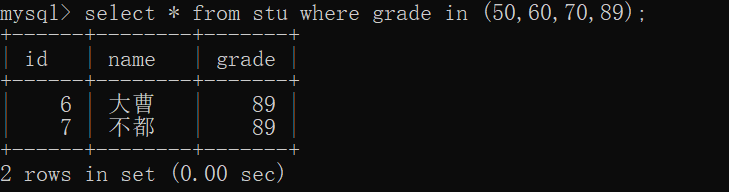
--查询成绩是50或60或70或89的学生信息
select * from stu where grade in (50,60,70,89);
--使用or也可以实现
select * from stu where grade=50 or grade=60 or grade=70 or grade=89;
模糊查询:like
select * from stu where name like '小%';--匹配到小章、小刘、小白、小小李
select * from stu where name like '小_';--匹配到小章、小刘、小白


分页查询:limit
--按id分页,每页3条记录,分别显示第1、2、3页
--第一页
select * from stu order by id limit 3 offset 0;
--第二页
select * from stu order by id limit 3 offset 3;
--第三页
select * from stu order by id limit 3 offset 6;
修改:update
--把半藏的名字改为亚索
update stu set name='亚索' where name='半藏';
删除:delete
--删除名字是不都的信息
delete from stu where name='不都';
关联查询
–先创建学生表(student)和班级表(classes),学生表中id为主键,class_id是外键,关联班级表id
DROP TABLE IF EXISTS student;
--UNIQUE :保证某列的每行必须有唯一的值
--DEFAULT:指定插入数据时,name列为空,默认值unkown
--auto_increment:自增长
CREATE TABLE student (
id INT PRIMARY KEY auto_increment,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20),
classes_id int,
FOREIGN KEY (classes_id) REFERENCES classes(id)
);
DROP TABLE IF EXISTS classes;
CREATE TABLE classes (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
`desc` VARCHAR(100)
);
-- 创建课程表
DROP TABLE IF EXISTS course;
CREATE TABLE course (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
-- 创建课程学生中间表:考试成绩表
DROP TABLE IF EXISTS score;
CREATE TABLE score (
id INT PRIMARY KEY auto_increment,
score DECIMAL(3, 1),
student_id int,
course_id int,
FOREIGN KEY (student_id) REFERENCES student(id),
FOREIGN KEY (course_id) REFERENCES course(id)
);
--插入数据
insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
('中文系2019级3班','学习了中国传统文学'),
('自动化2019级5班','学习了机械自动化');
insert into course(name) values
('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
insert into score(score, student_id, course_id) values
-- 黑旋风李逵
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- 菩提老祖
(60, 2, 1),(59.5, 2, 5),
-- 白素贞
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- 许仙
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- 不想毕业
(81, 5, 1),(37, 5, 5),
-- 好好说话
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- 镇元大仙
(80, 7, 2),(92, 7, 6);
内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
--别名:select 字段名 别名 from 表名;
--关联查询可以对关联表使用别名
select sco.score,sco.student_id,stu.name from student stu inner join score sco on stu.id=sco.student_id and stu.name='镇元大仙';
select sco.score,sco.student_id,stu.name from student stu, score sco where stu.id=sco.student_id and stu.name='镇元大仙';


--查询所有学生的成绩和个人信息
--学生表、成绩表、课程表3表关联查询
select stu.id,stu.sn,stu.name,sco.course_id,cou.name,sco.score from student stu inner join score sco on stu.id=sco.student_id inner join course cou on sco.course_id=cou.id order by stu.id;

外连接:
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
-- “老外学中文”同学 没有考试成绩,也显示出来了
select * from student stu left join score sco on stu.id=sco.student_id;
-- 对应的右外连接为:
select * from score sco right join student stu on stu.id=sco.student_id;


自连接
自连接是指在同一张表连接自身进行查询
--显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
select * from score s1 join score s2 on s1.student_id=s2.student_id and s1.score<s2.score and s1.course_id=1 and s2.course_id=3;
JDBC
(1)获取连接——DriverManager和DataSource两种方式
(2)创建操作命令对象——Statement、PreparedStatement、CallableStatement
(3)执行sql语句
(4)如果是查询语句,需要处理结果集ResultSet
(5)释放资源(反向释放 )
DriverManager和DataSource区别
1、DriverManger创建的连接无法重复利用,每次使用完释放资源时,通过connection.close()都是关闭物理连接
2、DataSource提供连接池的支持,这些连接是可以复用的,每次释放资源调用connection.close()都是将Connection对象回收
Statement对象
Statement对象主要是将SQL语句发送到数据库。JDBC API主要提供了3种Statement对象
1、Statement
用于执行不带参数的简单sql语句
2、PreparedStatement(实际开发中最常用的)
用于执行带或不带参数的sql语句
sql语句会预编译在数据库系统
执行速度快于Statement
3、CallableStatement
用于执行数据库存储过程的调用
PreparedStatement的优点:
(1)可以防止sql注入
(2)可以使用预编译的sql
事务
事务是一组原子性的SQL查询,或者说一个独立的工作单元
事务内的语句,要么全部执行成功,要么全部执行失败
ACID
ACID:原子性(atomicity)、一致性(consistency)、隔离性(isolation)、持久性(durability)
一个运行良好的事务处理系统,必须具备这些标准特征
原子性:一个事务被视为不可分割的最小工作单元,对一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性
一致性:数据库总是从一个一致性的状态转换到另一个一致性的状态
隔离性:一个事务所做的修改在最终提交以前,对其他事务是不可见的
持久性:一旦事务提交,所做的修改会永久保存到数据库中
隔离级别
在SQL标准中定义了4种隔离级别
READ UNCOMMITTED(未提交读):
在READ UNCOMMITTED级别,事务中的修改,即使没有提交,对其他事务也是可见的。事务可以读取未提交的数据,这也叫做脏读。这个级别实际应用比较少。
READ COMMITTED(提交读):
大多数数据库系统的默认隔离级别是READ COMMITTED(mysql不是),READ COMMITTED满足之前提到的隔离性的简单定义:一个事务开始时,只能“看见”已经提交的事务所做的修改。
REPEATABLE READ(可重复读):
mysql的默认事务隔离级别
REPEATABLE READ解决了脏读的问题,该级别保证了在同一事务中多次读取同样记录的结果是一致的。
SERIALIZABLE(可串行化):
最高级别的隔离,SERIALIZABLE会在每一行数据上都加锁,可能会导致大量的超时和锁争用的问题。
索引
索引(在mysql中也叫“键(key)”)是存储引擎用于快速找到记录的一种数据结构
索引的类型
mysql支持的索引类型👇👇👇
B-Tree索引
使用B-Tree数据结构来存储数据
B-Tree通常意味着所有的值都是按照顺序存储的,并且每一个叶子页到根的距离相同















 3513
3513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









