







目录

首先,深度学习问题是一个机器学习问题,指从有限样例中,通过算法总结出一般性的规律,并可以应用到新的未知数据上。
其次,和传统的机器学习不同,深度学习采用的模型一般比较复杂,指样本的原始输入到输出目标之间的数据流经过多个线性或非线性的组件。
贡献度分配问题:每个组件对最终输出结果的贡献是多少。贡献度问题是深度学习的一个很关键的问题,关系到如何学习每个组件的参数。目前可以比较好解决贡献度分配问题的模型是人工神经网络。
人工神经网络:一种受人脑神经系统的工作方式启发而构造的一种数学模型。人工神经网络既可以看做是信息从输入到输出的信息处理系统;也可以看做是一种深度的机器学习,即深度学习。
神经网络和深度学习并不等价。深度学习既可以采用神经网络模型,也可以采用其他模型(如深度信念网络是一种概率图模型)。因为神经网络模型可以很好的解决贡献度分配问题,所以神经网络模型成为深度学习中的主要采用的模型。
1.1 人工智能
John McCarthy 提出了人工智能的定义:人工智能就是要让机器的行为看起来就像是人所表现出的智能行为一样。
简而言之,人工智能就是让机器具有人类的智能,这也是人们长期追求的目标。
智能一词很难定义,1950年,阿兰·图灵提出了著名的图灵测试:“一个人在不接触对方的情况下,通过一种特殊的方式,和对方进行一系列的问答。如果在相当长时间内,他无法根据这些问题判断对方是人还是计算机,那么就可以认为这个计算机是智能的”。
要通过图灵测试,计算机必须具备理解语言、学习、记忆、推理、决策等能力,于是人工智能延伸出了很多不同的子学科。目前,人工智能的主要领域大体上可以分为以下几个方面:
感知 即模拟人的感知能力,对外部刺激信息(视觉和语音等)进行感知和加工。
主要研究领域包括语音信息处理和计算机视觉等。
学习 即模拟人的学习能力,主要研究如何从样例或与环境交互中进行学习。主
要研究领域包括监督学习、无监督学习和强化学习等。
认知 即模拟人的认知能力,主要研究领域包括知识表示、自然语言理解、推理、
规划、决策等。
1.1.1 人工智能的发展历史
 推理期 : 研究者都通过人类的经验,基于逻辑或者事实归纳出来一些规则,然后通过编写程序来让计算机完成一个任务.但随着研究的深入,研究者意识到这些推理规则过于简单,对项目难度评估不足,原来的乐观预期受到严重打击。人工智能的研究开始陷入低谷,很多人工智能项目的研究经费也被消减。
推理期 : 研究者都通过人类的经验,基于逻辑或者事实归纳出来一些规则,然后通过编写程序来让计算机完成一个任务.但随着研究的深入,研究者意识到这些推理规则过于简单,对项目难度评估不足,原来的乐观预期受到严重打击。人工智能的研究开始陷入低谷,很多人工智能项目的研究经费也被消减。
知识期:这一时期,研究者意识到知识对于人工智能系统的重要性。特别是对于一些复杂的任务,需要专家来构建知识库。专家系统可以简单理解为“知识库+推理机”,是一类具有专门知识和经验的计算机智能程序系统。专家系统一般采用知识表示和知识推理等技术来完成通常由领域专家才能解决的复杂问题,因此专家系统也被称为基于知识的系统。一个专家系统必须具备三要素:(1)领域专家级知识;(2)模拟专家思维;(3)达到专家级的水平。
学习期:对于人类的很多智能行为(比如语言理解、图像理解等),我们很难知道其中的原理,也无法描述出这些智能行为背后的“知识”。为了解决这类问题,研究者开始将研究重点转向让计算机从数据中自己学习。从人工智能的萌芽时期开始,就有一些研究者尝试让机器来自动学习。
1.1.2 人工智能的流派
尽管人工智能的流派非常多,但主流的方法大体上可以归结为以下两种:
符号主义 又称逻辑主义、心理学派或计算机学派,是通过分析人类智能的功能,然后通过计算机 来实现这些功能。符号主义有两个基本假设:(1)信息可以用符号来表示;(2)符号 可以通过显式的规则(比如逻辑运算)来操作。人类的认知过程可以看作是符号操作过 程。在人工智能的推理期和知识期,符号主义的方法比较盛行,并取得了大量的成果。
连接主义 又称仿生学派或生理学派,是认知科学领域中的一类信息处理的方法和理论。在认知科 学领域,人类的认知过程可以看做是一种信息处理过程。连接主义认为人类的认知过程 是由大量简单神经元构成的神经网络中的信息处理过程,而不是符号运算。因此,连接 主义模型的主要结构是由大量的简单的信息处理单元组成的互联网络,具有非线性、分 布式、并行化、局部性计算以及适应性等特性。
符号主义方法的一个优点是可解释性,而这也正是连接主义方法的弊端。深度学习的主要模型神经网络就是一种连接主义模型。
1.2 人工神经网络
人工神经网络是为模拟人脑神经网络而设计的一种计算模型,它从结构、实现机理和功能上模拟人脑神经网络。
人工神经网络与生物神经元类似,由多个节点(人工神经元)相互连接而成,可以用来对数据之间的复杂关系进行建模。不同节点之间的连接被赋予了不同的权重,每个权重代表了一个节点对另一个节点的影响大小。每个节点代表一种特定函数,来自其他节点的信息经过其相应的权重综合计算,输入到一个激活函数中并得到一个新的活性值。
人工神经网络可以看作是一个通用的函数逼近器,一个两层的神经网络可以逼近任意的函数,因此人工神经网络可以看作一个可学习的函数,并应用到机器学习中。理论上,只要有足够的训练数据和神经元数量,人工神经网络就可以学到很多复杂的函数。
人工神经网络模型的塑造任何函数的能力大小可以称为网络容量,与可以被储存在网络中的信息的复杂度以及数量相关。
1.3 机器学习
机器学习是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并将这些规律应用到未观测样本上的方法。
传统的机器学习关注学习一个预测模型,一般需要将数据表示为一组特征,特征的表示形式可以是连续的数值、离散的符号或其他形式。在实际任务中使用机器学习模型一般会包含以下几个步骤
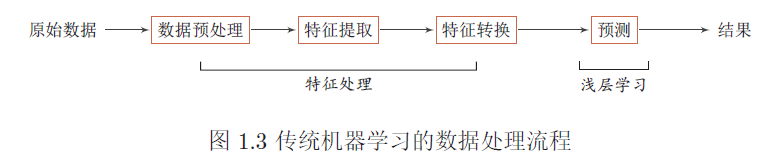
- 数据预处理:经过数据的预处理,如去除噪声等。比如在文本分类中,去除停用词等。
- 特征提取:从原始数据中提取一些有效的特征。比如在图像分类中,提取边缘、尺度不变特征变换特征等。
- 特征转换:对特征进行一定的加工,比如降维和升维。降维包括特征抽取和特征选择两种途径。常用的特征转换方法有主成分分析、线性判别分析等。
- 预测:机器学习的核心部分,学习一个函数进行预测。
传统的机器学习模型主要关注于最后一步,即构建预测函数。但是实际操作过程中,不同预测模型的性能相差不多,而前三步中的特征处理对最终系统的准确性有着十分关键的作用。由于特征处理一般都需要人工干预完成,利用人类的经验来选取好的特征,并最终提高机器学习系统的性能。因此,很多的模式识别问题变成了特征工程问题。开发一个机器学习系统的主要工作量都消耗在了预处理、特征提取以及特征转换上。
1.4 表示学习
如果有一种算法可以自动地学习出有效的特征,并提高最终机器学习模型的性能,那么这种学习就是可以叫做表示学习(Representation Learning)。
语义鸿沟 语义鸿沟问题是指输入数据的底层特征和高层语义信息之间的不一致性和差异性。如果可以有一个好的表示在某种程度上可以反映出数据的高层语义特征,那么我们就可以相对容
易地构建后续的机器学习模型。
1.4.1 局部表示和分布式表示
好的表示:
- 一个好的表示应该具有很强的表示能力,即同样大小的向量可以表示更多信息。
- 一个好的表示应该使后续的学习任务变得简单,即需要包含更高层的语义信息。
- 一个好的表示应该具有一般性,是任务或领域独立的。虽然目前的大部分表示学习方法还是基于某个任务来学习,但我们期望其学到的表示可以比较容易的迁移到其它任务上。
以颜色表示为例,我们可以用很多词来形容不同的颜色,如果要在计算机中表示颜色,一般有两种表示方法。
局部表示:一种表示颜色的方法是以不同名字来命名不同的颜色,这种表示方式叫做局部表示,也称为离散表示或符号表示。局部表示通常可以表示为one-hot 向量的形式。
局部表示有两个不足之处:(1)one-hot 向量的维数很高,且不能扩展。如果有一种新的颜色,我们就需要增加一维来表示;(2)不同颜色之间的相似度都为0,即我们无法知道“红色”和“中国红”的相似度要比“红色”和“黑色”的相似度要高。
分布式表示:另一种表示颜色的方法是用RGB值来表示颜色,不同颜色对应到R、G、B三维空间中一个点,这种表示方式叫做分布式表示。分布式表示通常可以表示为低纬的稠密向量。
分布式表示的向量维度一般都比较低。不同颜色之间的相似度也很容易计算。
词嵌入:嵌入通常指将一个度量空间中的一些对象映射到另一个低维的度量空间中,并尽可能保持不同对象之间的拓扑关系。比如自然语言中词的分布式表示,也经常叫做词嵌入。
1.4.2 表示学习
要学习到一种好的高层语义表示(一般为分布式表示),通常需要从底层特征开始,经过多步非线性转换才能得到。
一个深层结构的优点是可以增加特征连续的重用性,从而指数级地增加表示能力。因此,表示学习的关键是构建具有一定深度的多层次特征表示。
1.5 深度学习
深度学习是机器学习的一个子问题,其主要目的是从数据中自动学习到有效的特征表示。
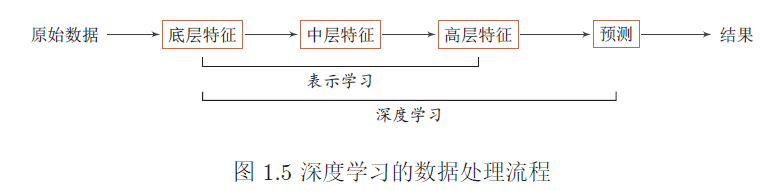
深度学习是将原始的数据特征通过多步的特征转换得到一种特征表示,并进一步输入到预测函数得到最终结果。和“浅层学习”不同,深度学习需要解决的关键问题是贡献度分配问题。
目前,深度学习采用的模型主要是神经网络模型,其主要原因是神经网络模型可以使用误差反向传播算法,从而可以比较好地解决贡献度分配问题。
1.5.1 端到端学习
端到端学习(End-to-End Learning),也称端到端训练,是指在学习过程中不进行分模块或分阶段进行训练,直接优化任务的总体目标。在端到端学习中,一般不需要明确地给出不同模块或阶段的功能,中间过程不需要人为干预。
端到端学习的训练数据为“输入-输出”对的形式,无需提供其它额外信息。因此,端到端学习和深度学习一样,都是要解决“贡献度分配”问题。目前,大部分采用神经网络模型的深度学习也可以看作是一种端到端的学习。
1.6 总结
在传统机器学习中,除了模型和学习算法外,特征或表示也是影响最终学习效果的重要因素,甚至在很多的任务上比算法更重要。
如何自动学习有效的数据表示成为机器学习中的关键问题。
早期的表示学习方法,比如特征抽取和特征选择,都是人工引入一些主观假设来进行学习的。这种表示学习不是端到端的学习方式,得到的表示不一定对后续的机器学习任务有效。
深度学习是将表示学习和预测模型的学习进行端到端的学习,中间不需要人工干预。深度学习所要解决的问题是贡献度分配问题,而神经网络恰好是解决这个问题的有效模型。















 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









