










7.3 链表处理
7.3.1 链表概念
struct node {
typename data;//数据域
node* next;//指针域
};链表可以分为带头结点的和不带头结点的链表。
7.3.2 为链表节点分配内存空间
1. malloc函数
typename* p = (typename*) malloc(sizeof(typename));
int* p = (int*) malloc(sizeof(int));
int* p = (int*) malloc(10000*sizeof(int));//申请的动态数组过大容易失败2.new运算符
typename* p = new typename;
int* p = new int;
node* p = new node;3. 内存释放
malloc函数申请的内存使用free函数释放
typename* p = (typename*) malloc(sizeof(typename));
free(p);new运算符申请的内存使用delete运算符释放
typename* p = new typename;
delete p;7.3.3 链表的基本操作
1.插入
//将x插入以head为头结点的链表的第pos个位置上
void insert(node* head, int pos, int x) {
node* p;
for (int i = 0; i < pos - 1; i++) {
p = p->next;
}
node* q = new node;
q->data = x;
q->next = p->next;
p-> next = q;
}2.删除
//删除以head为头结点的链表中所有数据域为x的节点
void del(node* head, int x) {
node* p = head->next;
node* pre = head;
while(p != NULL) {
if(p->data == x) {
pre->next = p->next;
delete(p);
p = pre->next;
}else {
pre = p;
p = p->next;
}
}
}
7.4.3 静态链表
struct Node {
typename data;
int next;
}node[size];【PAT A1032】
To store English words, one method is to use linked lists and store a word letter by letter. To save some space, we may let the words share the same sublist if they share the same suffix. For example, loading and being are stored as showed in Figure 1.
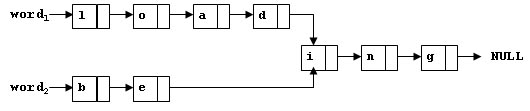
Figure 1
You are supposed to find the starting position of the common suffix (e.g. the position of i in Figure 1).
Input Specification:
Each input file contains one test case. For each case, the first line contains two addresses of nodes and a positive N (≤105), where the two addresses are the addresses of the first nodes of the two words, and N is the total number of nodes. The address of a node is a 5-digit positive integer, and NULL is represented by −1.
Then N lines follow, each describes a node in the format:
Address Data NextwhereAddress is the position of the node, Data is the letter contained by this node which is an English letter chosen from { a-z, A-Z }, and Next is the position of the next node.
Output Specification:
For each case, simply output the 5-digit starting position of the common suffix. If the two words have no common suffix, output -1 instead.
Sample Input 1:
11111 22222 9
67890 i 00002
00010 a 12345
00003 g -1
12345 D 67890
00002 n 00003
22222 B 23456
11111 L 00001
23456 e 67890
00001 o 00010
结尾无空行Sample Output 1:
67890
结尾无空行Sample Input 2:
00001 00002 4
00001 a 10001
10001 s -1
00002 a 10002
10002 t -1
结尾无空行Sample Output 2:
-1
结尾无空行#include<iostream>
#include<cstdio>
using namespace std;
const int maxn = 100010;
struct NODE{
char data;
int next;
bool flag;//节点是否在第一条链表出现
}node[maxn];
int main() {
for (int i = 0; i < maxn; i ++ ){
node[i].flag = false;
}
int s1, s2, n;
if(scanf("%d%d%d", &s1, &s2, &n)){};
int address,next;
char data;
for (int i = 0; i < n; i ++) {
if(scanf("%d %c %d", &address, &data, &next)){};
node[address].data = data;
node[address].next = next;
}
int p;
for (p = s1; p != -1; p = node[p].next) {
node[p].flag = true;
}
for (p = s2; p != -1; p = node[p].next) {
if(node[p].flag == true) break;
}
if(p != -1){
printf("%05d\n",p);
}else{
cout<<"-1"<<endl;
}
return 0;
}7.4.4 静态链表解题思路
①定义静态链表
struct Node{
int address;//结点地址
typeName data;//数据域
int next;//指针域
XXX;//结点的某个性质
};//node[100000];②静态链表初始化,初始化XXX字段。例如对结点是否在链表上来说,可以初始化为0(false),表示结点不在链表上。
③根据链表的首节点的地址,开始遍历整个链表。遍历过程对结点的性质XXX进行标记,并且对有效结点个数进行计数count。
④由于使用静态链表,是直接采用地址映射的方式,这样会使得数组下标不连续,而且很多时题目给出的节点并不都是有效结点。为了能够可控的访问有效结点,可以先对数组排序,然后把有效结点移动到数组左端。这样就可以使用第3步得到的count访问他们。
排序的时候可以借助字段XXX,无效的节点的XXX字段可以设置的比较小。
bool cmp {
if (a.xxx == -1 || b.xxx == -1) {
return a.xxx > b.xxx;
} else {
//第二级排序
}
}⑤经历步骤4之后,链表中的有效结点都在数组左端了,且已经按照结点性质排好序。
【PAT A1052】Linked List Sorting
A linked list consists of a series of structures, which are not necessarily adjacent in memory. We assume that each structure contains an integer key and a Next pointer to the next structure. Now given a linked list, you are supposed to sort the structures according to their key values in increasing order.
Input Specification:
Each input file contains one test case. For each case, the first line contains a positive N (<105) and an address of the head node, where N is the total number of nodes in memory and the address of a node is a 5-digit positive integer. NULL is represented by −1.
Then N lines follow, each describes a node in the format:
Address Key Nextwhere Address is the address of the node in memory, Key is an integer in [−105,105], and Next is the address of the next node. It is guaranteed that all the keys are distinct and there is no cycle in the linked list starting from the head node.
Output Specification:
For each test case, the output format is the same as that of the input, where N is the total number of nodes in the list and all the nodes must be sorted order.
Sample Input:
5 00001
11111 100 -1
00001 0 22222
33333 100000 11111
12345 -1 33333
22222 1000 12345
结尾无空行Sample Output:
5 12345
12345 -1 00001
00001 0 11111
11111 100 22222
22222 1000 33333
33333 100000 -1
结尾无空行#include<bits/stdc++.h>
using namespace std;
const int maxn = 100010;
//第1步
struct Node{
int address, data, next;
bool flag;
}node[maxn];
//第4步
bool cmp(Node a, Node b) {
if (a.flag == false || b.flag == false) {
return a.flag > b.flag ;
} else{
return a.data < b.data;
}
}
int main(){
ios::sync_with_stdio(false);
cin.tie(0);
//第2步
for (int i = 0; i < maxn; i ++) {
node[i].flag = false;
}
int n, begin, address;
cin >> n >> begin;
//第3步
for (int i = 0; i < n; i ++) {
cin >>address;
cin >> node[address].data >> node[address].next ;
node[address].address = address;
}
int count = 0, p =begin;
while(p != -1) {
node[p].flag = true;
count ++;
p = node[p].next;
}
if(count == 0) {
cout<<"0 -1";
} else {
//第4步
sort(node,node+maxn, cmp);
printf("%d %05d\n",count,node[0].address);
for (int i = 0; i < count; i ++) {
if (i != count -1) {
printf("%05d %d %05d\n",node[i].address, node[i].data, node[i+1].address);
} else {
printf("%05d %d -1\n",node[i].address, node[i].data);
}
}
}
return 0;
}
8.1 深度优先搜索
8.1.1 问题1

对每件物品都有选和不选两种操作,死胡同就是题目要求的物品总量不能超过V。
每次都需要对物品进行选择,因此DFS函数的参数必须记录当前处理的物品编号的index。同时需要记录当前已选物品的总重量和总价值。
void DFS(int index, int sumW, int sumC) {
if (index == n) {//死胡同
if (sumW <= V && sumC > maxValue) {
maxValue = sumC;
}
return;
}
DFS(index + 1, sumW, sumC);//不选第index件物品
DFS(index + 1, sumW + w[index], sumC + c[index]);
}
优化后:
void DFS(int index, int sumW, int sumC) {
if (index == n) {//死胡同
return;
}
DFS(index + 1, sumW, sumC);//不选第index件物品
if (sumW + w[index] <= V) {
if(sumC + c[index] > maxValue) {
maxValue = sumC + c[index];
}
DFS(index + 1, sumW + w[index], sumC + c[index]);//选第index件物品
}
}8.1.2 问题2
给定N个整数,从中选择K个数,使得这K个数之和恰好等于一个给定的整数X;如果有多种方案,选择出它们中元素平方和最大的一个。数据保证这样的方案唯一。
解析:
此处仍然需要记录当前处理的整数编号index,还要一个参数nowK记录当前已经选择的数的个数,另外还需要参数sum和sumSqu记录当前已经选的整数之和与平方和。
//从序列A中n个数选k个数使得和为x,最大平方和为maxSumSqu
int n, k, x, maxSumSqu = -1, A[maxn];
vector<int> temp, ans;//temp存放临时方案,ans存放最大方案
void DFS(int index, int nowK, int sum, int SumSqu) {
if(nowK == k && sum == x) {
if(sumSqu > maxSumSqu) {
maxSumSqu = sumSqu;
ans = temp;
}
return;
}
if(index == n || nowK > k || sum > x ) return;
temp.push_back(A[index]);
//选index数
DFS(index + 1, nowk + 1, sum + A[index], sumSqu + A[index] * A[index]);
temp.pop_back();
//不选index 数
DFS(index + 1, nowK, sum, sumSqu);
}如果题目稍微修改为:每个数可以选多次,则只需要把选index数这行代码改为:
DFS(index, nowK + 1,sum + A[index], sumSqu + A[index] * A[index]);
8.2 广度优先搜索
深度优先搜索模板
void BFS(int s) {
queue<int> q;
q.push(s);
while(!q.empty()) {
取出队首元素top;
访问队首元素top;
将队首元素出队;
将top的下一层结点中未曾入队的结点全部入队,并设置为已入队。
}
}8.2.1 问题1

#include<cstdio>
#include<queue。
using namespace std;
const int maxn = 100;
struct node {
int x, y;
}Node;
int n, m;//矩阵大小为n * m
int matrix[maxn][maxn];//01矩阵
bool inq[maxn][maxn] = {false};//标记是否访问过
int X[4] = {0,0,1,-1}
int Y[4] = {1,-1,0,0};
bool judge(int x, int y) {
if (x >= n || x < 0 || y >= m || y < 0) return false;
if (matrix[x][y] == 0 || inq[x][y] = true) return false;
return true;
}
void BFS(int x, int y) {
queue<node> Q;
Node.x = x, Node.y = y;
Q.push(Node);
inq[x][y] = true;
while(!Q.empty()) {
node top = Q.front();
Q.pop();
for (int i = 0; i < 4; i ++) {
int newX = top.x + X[i];
int newY = top.y + Y[i];
if(judge(newX,newY)) {
Node.x = newX, Node.y = newY;
Q.push(Node);
inq[newX][newY] = true;
}
}
}
}
int main() {
scanf("%d%d",&n,&m);
for (int x = 0; x < n; x++) {
for (int y = 0; y < m; y ++) {
scanf("%d",&matrix[x][y]);
}
}
int ans = 0;//块数
for (int x = 0; x < n; x ++) {
for (int y = 0; y < m; y ++) {
if(matrix[x][y] == 1 && inq[x][y] == false) {
ans ++;
BFS(x,y);
}
}
}
printf("%d\n",ans);
return 0;
}当使用STL的queue时,元素入队的push操作只是制造了该元素的一个副本入队,因此在入队之后对原元素进行修改不会影响队列中的副本。对队列中副本的修改也不会改变原元素。
8.2.2 问题2
![]()
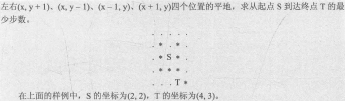
#include<cstdio>
#include<cstring>
#include<queue>
using namespace std;
const int maxn = 100;
struct node {
int x, y;
int step;//步数
}S,T,Node;
int n, m;//矩阵大小为n * m
char maze[maxn][maxn];//迷宫信息
bool inq[maxn][maxn] = {false};//标记是否访问过
int X[4] = {0,0,1,-1}
int Y[4] = {1,-1,0,0};
bool judge(int x, int y) {
if (x >= n || x < 0 || y >= m || y < 0) return false;
if (maze[x][y] == '*' || inq[x][y] = true) return false;
return true;
}
int BFS() {
queue<node> q;
q.push(S);
while(!q.empty()) {
node top = Q.front();
q.pop();
if (top.x == T.x && top.y == T.y) {
return top.step;
}
for (int i = 0; i < 4; i ++) {
int newX = top.x + X[i];
int newY = top.y + Y[i];
if(judge(newX,newY)) {
Node.x = newX, Node.y = newY;
Node.step = top.step + 1;
q.push(Node);
inq[newX][newY] = true;
}
}
}
return -1;
}
int main() {
scanf("%d%d",&n,&m);
for (int x = 0; x < n; x++) {
getchar();
for (int y = 0; y < m; y ++) {
maze[x][y] = getchar();
}
maze[i][m+1] = '\0';
}
scanf("%d%d%d",&S.x,&S.y,&T.x,&T.y);
S.step = 0;
printf("%d\n",BFS());
return 0;
}














 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









