






本篇主要解决数据清洗和数据的特征处理问题,数据清洗包括缺失值、重复值的处理、字符串数据转换等,此项过程为数据分析的前序环节起铺垫作用。
2 第二章:数据清洗及特征处理
知识概要
- 缺失值和重复值的观察与处理
- 数据的分箱处理
- 文本变量转换
数据加载
import numpy as np
import pandas as pd
df = pd.read_csv('train.csv')
2.1 缺失值观察与处理
2.1.1 缺失值观察
(1)查看每个特征缺失值个数
>>>df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
或看数据的整体信息以判断缺失值个数
>>>df.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
(2) 请查看Age, Cabin, Embarked列的数据
df[['Age','Cabin','Embarked']]

还可以用到之前学习过的loc命令
df.loc[:,['Age','Cabin','Embarked']].head(3)
df.iloc[:,[6,10,11]].head(3)
2.1.2 对缺失值进行处理
【处理缺失值的一般思路】:删除或填充(补0、中位数、平均值、向下/上填充等)
【提醒】可使用的函数有:dropna函数与fillna函数
#对Age列的缺失值都补0
#利用fillna函数
df1 = df.fillna({'Age':0})
df1
#利用loc函数
df.loc[df['Age'].isnull(),'Age'] = 0
df.isnull().sum()
#对整张表的缺失值处理
* 缺失值都补为0
>>>df.fillna(0)
>>>df.isnull.sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64
* 删除含缺失值的列
drop.dropna().head(3)

2.2 重复值观察与处理
2.2.1查看数据中的重复值
df[df.duplicated()]
#下图表示没有重复行

以某一数据为例,演示去掉重复行(默认保留重复值的第一行)
a = pd.DataFrame({'brand':['Yum Yum','Yum Yum','Indomie','Indomie','Indomie'],
'style':['cup','cup','cup','pack','pack'],
'rating':[4,4,3.5,15,5]})
a

#判断a中有无重复值
>>>a.duplicated()
0 False
1 True
2 False
3 False
4 False
dtype: bool
#去掉第一、二行重复值
a.drop_duplicates()

2.2.3 将前面清洗的数据保存为csv格式
另存为csv格式,文件名为train_clear
df.to_csv('train_clear.csv')
2.3 特征观察与处理
观察特征后,可以对特征分为两大类:
数值型特征:
Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征
文本型特征:
Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征。
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化;文本型特征往往需要转换成数值型特征才能用于建模分析。
2.3.1 对年龄进行分箱(离散化)处理
(1) 分箱操作是什么?
数据分箱处理, 即把一段连续的值切分成若干段,每一段的值看成一个分类。通常把连续值转换成离散值的过程,我们称之为分箱处理。
一般在建立分类模型时,需要对连续变量离散化,特征离散化后,模型会更稳定,降低了模型过拟合的风险。离散化通常采用分箱法。
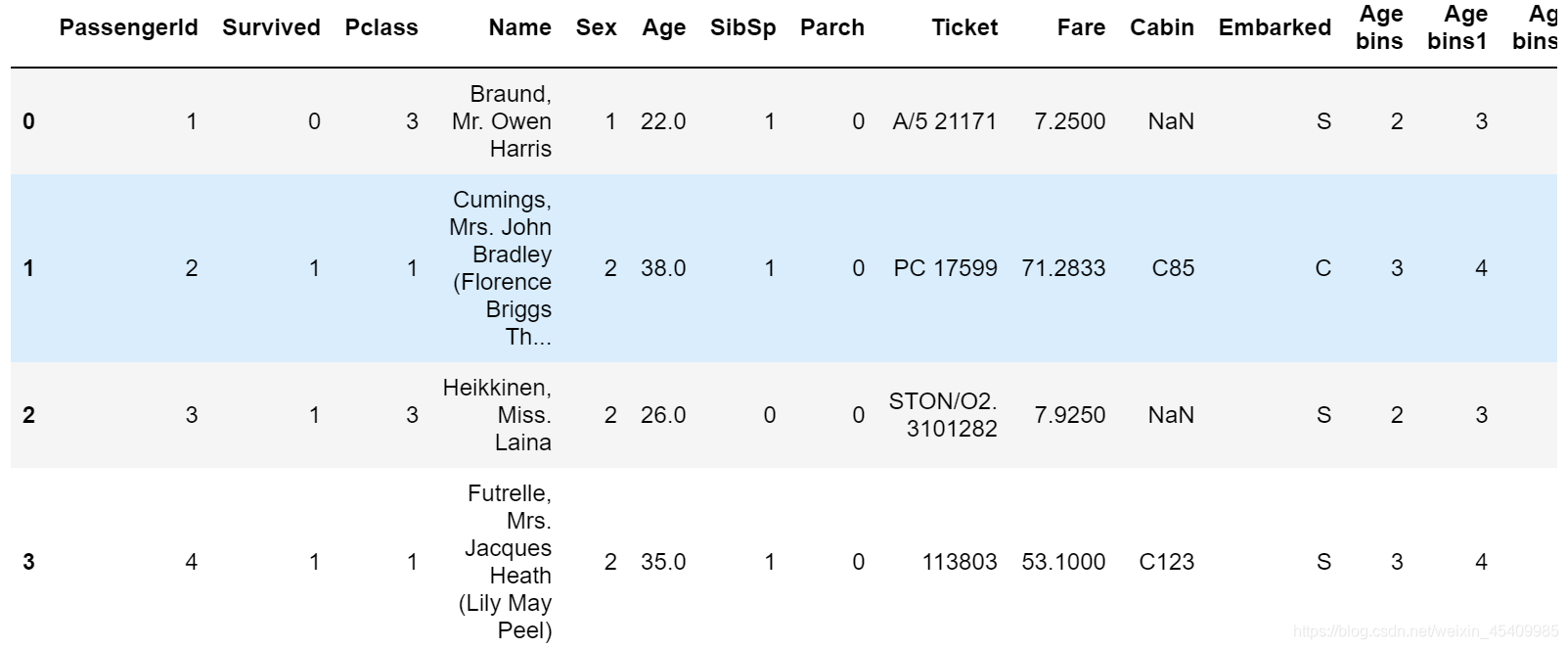
(2) 将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
>>>df['Age bins'] = pd.cut(df['Age'],5,labels = list('12345'))
>>>df['Age bins']
0 2
1 3
2 2
3 3
..
887 2
888 1
889 2
890 2
Name: Age bins, Length: 891, dtype: category
Categories (5, object): [1 < 2 < 3 < 4 < 5]
>>>df.head()
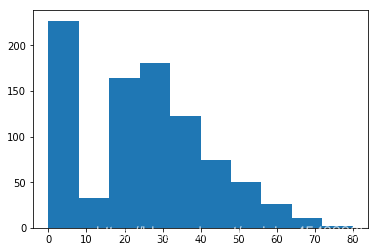
使用直方图来直观查看,均分后划分为五个区间[0,16) 、[16,32) 、[32,48)、 [48,64)、[64,80)。
from matplotlib import pyplot as plt
plt.hist(df['Age'])
(3) 将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
df['Age bins1'] = pd.cut(df['Age'],[0,5,15,30,50,80],labels = list('12345'),right = False)
#right参数默认true区间为左开右闭,现在要改为左闭右开
df.head()
(4) 将连续变量Age按10% 30% 50% 70% 90%五个年龄段,并用分类变量12345表示
df['Age bins'] = pd.qcut(df['Age'],[0,0.1,0.3,0.5,0.7,0.9],duplicates='drop',label=list('1234'))
#duplicates参数表示分类的临界值是唯一的,默认为drop以加以区分;标签只有1234是因为qcut中标签数不能超过分段数
df.head()
(5) 将上面的获得的数据分别进行保存,保存为csv格式
df.to_csv('train_bin.csv')
2.3.2对文本变量进行转换
(1) 查看文本变量名及种类
>>>df['Sex'].unique()
array(['male', 'female'], dtype=object)
>>>df['Cabin'].unique()
array([nan, 'C85', 'C123', 'E46', 'G6', 'C103', 'D56', 'A6',
'C23 C25 C27', 'B78', 'D33', 'B30', 'C52', 'B28', 'C83', 'F33',
'F G73', 'E31', 'A5', 'D10 D12', 'D26', 'C110', 'B58 B60', 'E101',
'F E69', 'D47', 'B86', 'F2', 'C2', 'E33', 'B19', 'A7', 'C49', 'F4',
'A32', 'B4', 'B80', 'A31', 'D36', 'D15', 'C93', 'C78', 'D35',
'C87', 'B77', 'E67', 'B94', 'C125', 'C99', 'C118', 'D7', 'A19',
'B49', 'D', 'C22 C26', 'C106', 'C65', 'E36', 'C54',
'B57 B59 B63 B66', 'C7', 'E34', 'C32', 'B18', 'C124', 'C91', 'E40',
'T', 'C128', 'D37', 'B35', 'E50', 'C82', 'B96 B98', 'E10', 'E44',
'A34', 'C104', 'C111', 'C92', 'E38', 'D21', 'E12', 'E63', 'A14',
'B37', 'C30', 'D20', 'B79', 'E25', 'D46', 'B73', 'C95', 'B38',
'B39', 'B22', 'C86', 'C70', 'A16', 'C101', 'C68', 'A10', 'E68',
'B41', 'A20', 'D19', 'D50', 'D9', 'A23', 'B50', 'A26', 'D48',
'E58', 'C126', 'B71', 'B51 B53 B55', 'D49', 'B5', 'B20', 'F G63',
'C62 C64', 'E24', 'C90', 'C45', 'E8', 'B101', 'D45', 'C46', 'D30',
'E121', 'D11', 'E77', 'F38', 'B3', 'D6', 'B82 B84', 'D17', 'A36',
'B102', 'B69', 'E49', 'C47', 'D28', 'E17', 'A24', 'C50', 'B42',
'C148'], dtype=object)
>>>df['Embarked'].unique()
array(['S', 'C', 'Q', nan], dtype=object)
(2) 将文本变量Sex, Cabin ,Embarked用数值变量12345表示
法一:直接对该列replace
df['Sex'].replace(['male','female'],[1,2],inplace = True)
#inplace = True表示直接作用于dataframe本身否则返回为副本
df.head()
法二:map函数
df['Sex_num']=df['Sex'].map({'male': 1, 'female': 2})
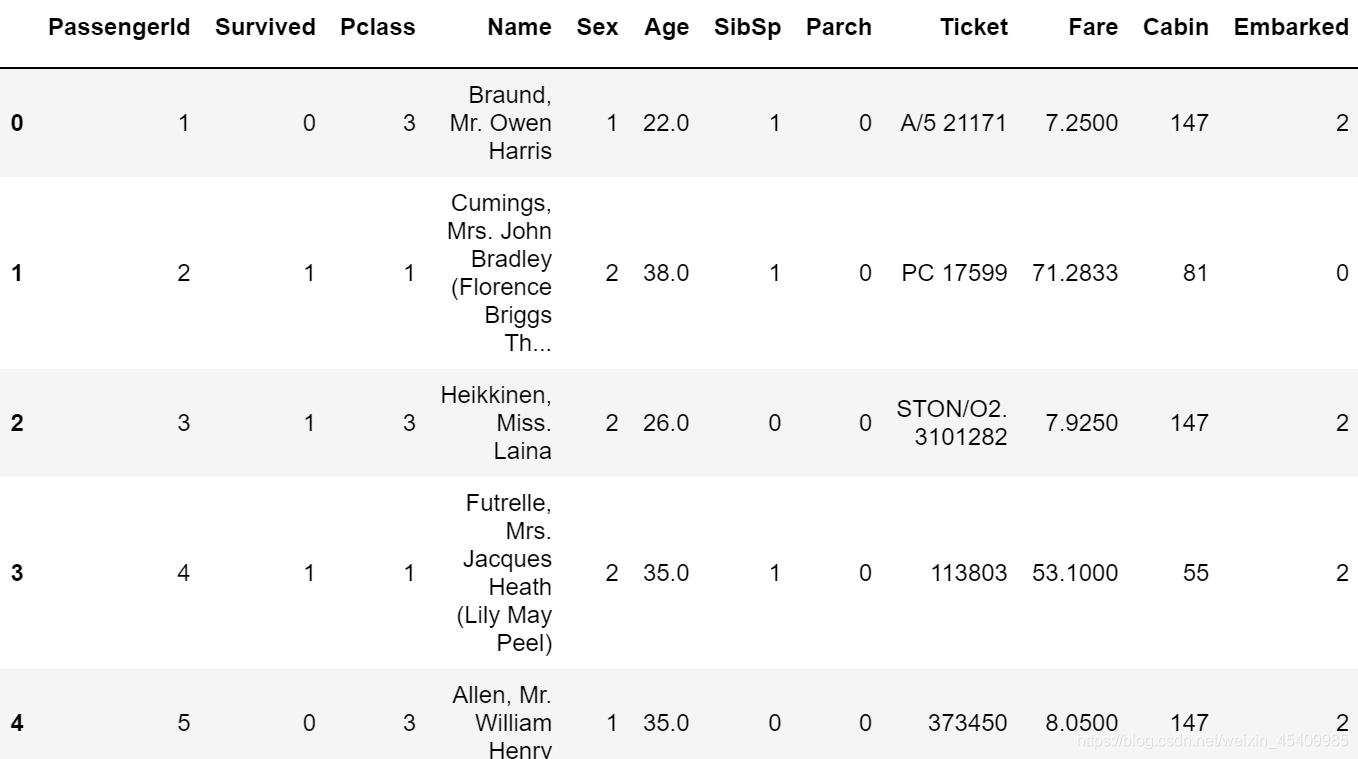
Cabin的类型很多手动改很麻烦,这里调用sklearn中的包LabelEncoder
from sklearn.preprocessing import LabelEncoder
df['Cabin'] = LabelEncoder().fit_transform(df['Cabin'].astype(str))
df.head()
对Embark如上同理
df['Embarked'] = LabelEncoder().fit_transform(df['Embarked'].astype(str))
df.head()
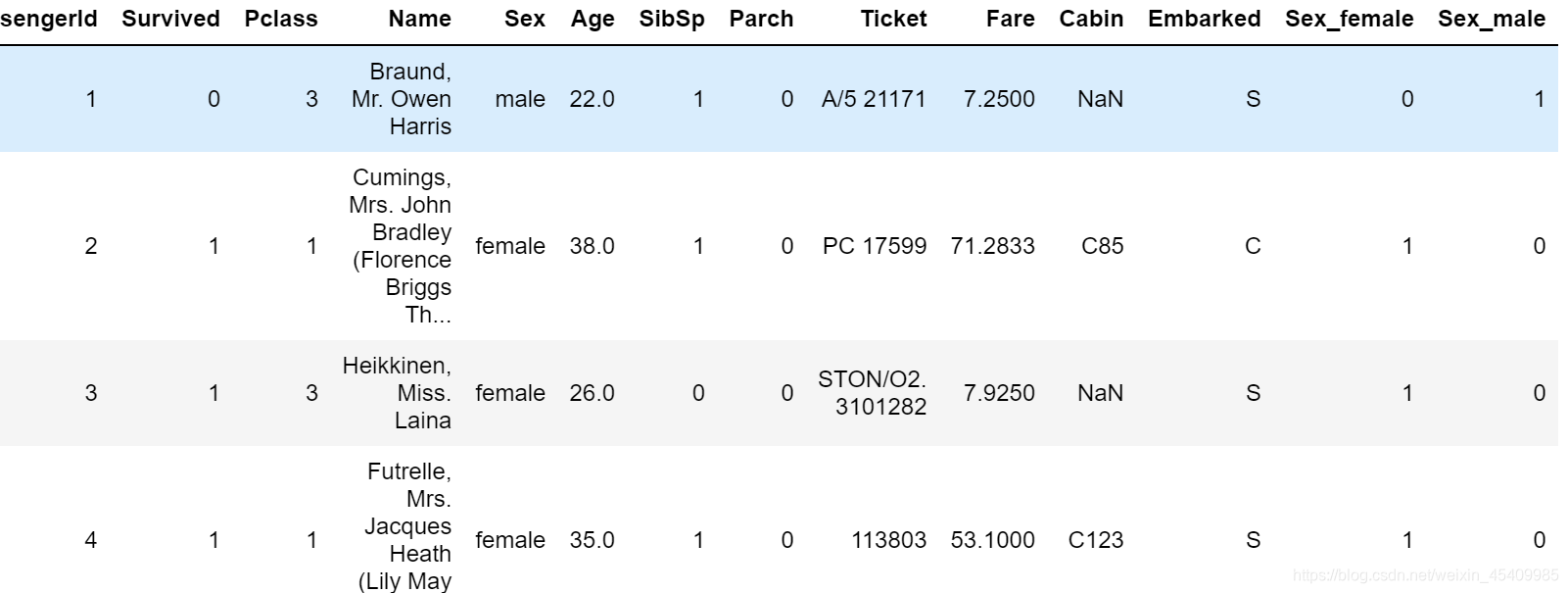
(3) 将文本变量Sex, Cabin, Embarked用one-hot编码表示
【注】one-hot编码可以理解类似于处理问卷数据中的选择题数据,将已有数据看成一个个选项,对应的数值在该选项上设为1,其他为0。python中需要用到get_dummies命令
对Sex变量
x = pd.get_dummies(df['Sex'],prefix = 'Sex')
df = pd.concat([df,x],axis = 1)
df.head()
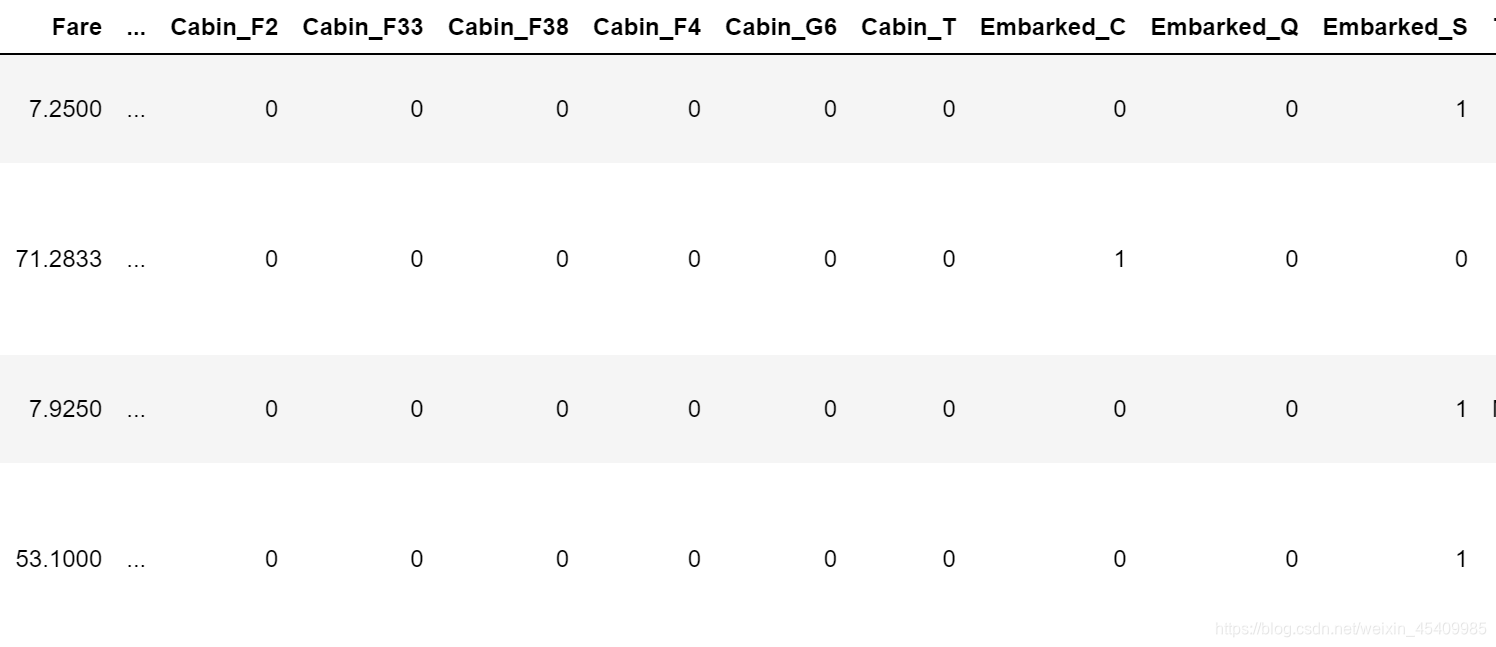
还可以用到for loop 应用于Cabin和Embarked变量如下
for column in ['Cabin','Embarked']:
x = pd.get_dummies(df[column],prefix = column)
df = pd.concat([df,x],axis = 1)
df.head()
2.3.3 从纯文本Name特征中提取出Titles的特征(即Mr,Miss,Mrs等)
# 注意到titles是以.点为结尾,要加一个\ 且前后分别为小写和大写字母
>>>df['Title'] = df.Name.str.extract('([A-Za-z]+)\.',expand = False)
>>>df['Title']
0 Mr
1 Mrs
2 Miss
3 Mrs
...
888 Miss
889 Mr
890 Mr
Name: Title, Length: 891, dtype: object
保存最终完成的清洗完成的数据
# 保存上面的为最终结论
df.to_csv('test_fin.csv')
问题补充
- 检索空缺值用np.nan,None以及 .isnull() 哪个更好,这是为什么?如果其中某个方式无法找到缺失值,原因又是为什么?
A: 数值列读取数据后,空缺值的数据类型为float64,所以用None一般索引不到,比较的时候最好用np.nan
- pd.cut()与pd.qcut()
- pd.cut() 将指定序列 x,按指定数量等间距的划分(根据值本身而不是这些值的频率选择均匀分布的bins),或按照指定间距划分
- pd.qcut() 将指定序列 x,划分为 q 个区间,使落在每个区间的记录数一致
参考文档
官方文档-‘dropna’ https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.cut.html
官方文档-‘fillna’ https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.qcut.html
官方文档-‘cut’ https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.cut.html
官方文档-‘qcut’ https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.qcut.html
数据清洗之缺失值、重复值的处理方式https://blog.csdn.net/weixin_44941795/article/details/101026535
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









