







高可用存储架构旨在提高数据存储的可靠性、可用性和扩展性,确保即使在硬件或软件故障时,数据仍然可访问并保持一致。 以下是几种常见的高可用存储架构的详细解释:
1. 主备架构(Active-Standby / Primary-Backup)
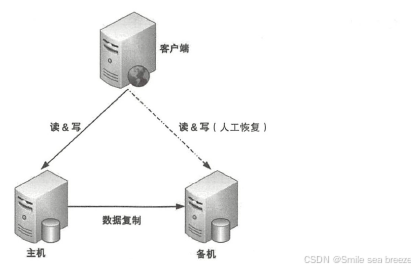
概念:
主备架构中,一个主节点(Primary)负责所有的读写操作,而一个或多个备节点(Backup)作为热/冷备份,仅在主节点故障时接管服务。
特点:
备节点通常与主节点保持数据同步(同步或异步复制)。
备节点不处理请求(冷备)或仅作为只读节点(热备)。
发生故障时,系统会切换到备节点(Failover)。
优点:
✅ 容易实现,配置简单。
✅ 备份节点可提供数据冗余,增强数据安全性。
缺点:
❌ 备节点资源利用率低,性能浪费。
❌ 主节点故障后,可能需要一定时间才能完成故障切换(Failover),导致短暂不可用。
适用场景:
传统数据库(如 MySQL 主备架构)。
关键业务系统(如金融交易系统)。
2. 主从架构(Master-Slave / Primary-Replica)
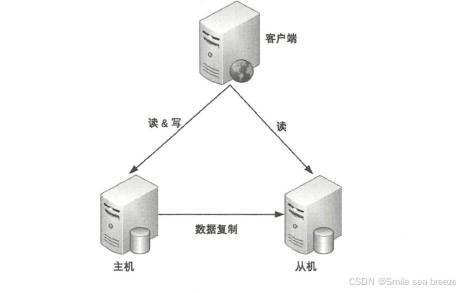
概念:
主从架构类似主备架构,但从节点(Slave)可以用于读操作,以分担主节点的负载,提高系统吞吐量。
特点:
主节点(Master)负责所有写操作。
从节点(Slave)通过异步或半同步复制数据,可提供读操作。
适用于读多写少的场景。
优点:
✅ 读写分离,提高查询性能。
✅ 提供基本的高可用性,主节点故障时从节点可以提升为主节点(需额外实现 Failover 机制)。
缺点:
❌ 复制通常是异步的,可能会有数据延迟(Replication Lag)。
❌ 需要额外的负载均衡器来分发读请求。
适用场景:
高并发数据库(如 MySQL、PostgreSQL 读写分离架构)。
日志存储系统(如 ELK)。
3. 主主架构(Active-Active / Multi-Master)
概念:
主主架构允许多个主节点同时处理读写请求,并相互同步数据,以提供高可用性和负载均衡能力。
特点:
多个主节点(Primary)共同承担读写任务。
需要冲突检测和一致性协议(如两阶段提交 2PC、Paxos、Raft)来保证数据一致性。
适用于读写均衡的场景。
优点:
✅ 无需主备切换,提供高可用性和负载均衡。
✅ 单个节点故障不会影响整个系统。
缺点:
❌ 数据一致性维护复杂(可能出现数据冲突)。
❌ 复制开销较大,可能影响写入性能。
适用场景:
分布式数据库(如 Galera Cluster for MySQL, CockroachDB, YugabyteDB)。
企业级存储系统(如 Ceph)。
4. 集群架构(Cluster)
概念:
集群架构指多个存储节点组成一个集群,通常采用分布式存储技术,实现高可用性和负载均衡。
特点:
采用分布式一致性协议(如 Paxos、Raft)保证数据一致性。
支持横向扩展(Scale-Out),提升存储能力和访问速度。
具有副本机制,保证数据可靠性。
优点:
✅ 高可用、高吞吐,适用于大规模存储。
✅ 具备自动故障恢复能力。
✅ 可扩展性强,可动态增加或减少存储节点。
缺点:
❌ 设计和维护复杂,需要分布式一致性协议支持。
❌ 一致性保证机制可能会影响写入性能。
适用场景:
分布式数据库(如 TiDB、Cassandra、HBase)。
大规模对象存储(如 Hadoop HDFS、Ceph、MinIO)。
5. 分区架构(Sharding / Partitioning)
概念:
分区架构将数据按特定规则分割到多个存储节点(Shards)上,以提升读写并发能力。
特点:
数据按某个字段(如用户 ID、订单 ID)划分到不同节点。
分片策略包括范围分片(Range Sharding)、哈希分片(Hash Sharding)和一致性哈希(Consistent Hashing)。
适用于超大规模存储系统,提供横向扩展能力。
优点:
✅ 解决单点性能瓶颈,提高并发处理能力。
✅ 支持水平扩展(Scale-Out),适合大数据存储。
缺点:
❌ 事务支持较难实现,跨分片查询性能较低。
❌ 分片策略不合理可能导致数据热点问题。
适用场景:
超大规模数据库(如 MySQL Sharding、MongoDB Sharding)。
高并发系统(如互联网应用、大型电商数据库)。
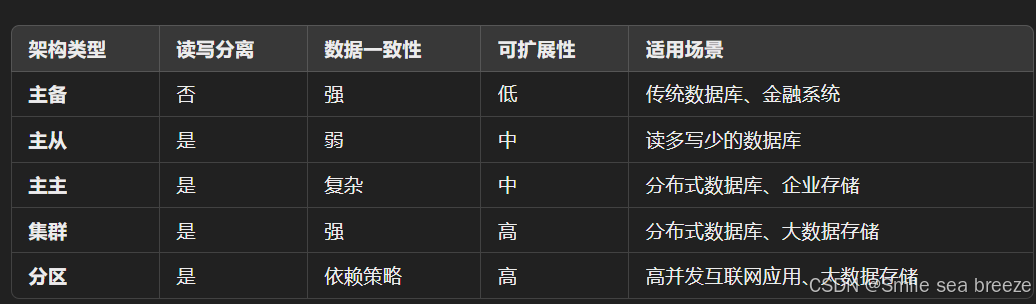
总结对比



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









