







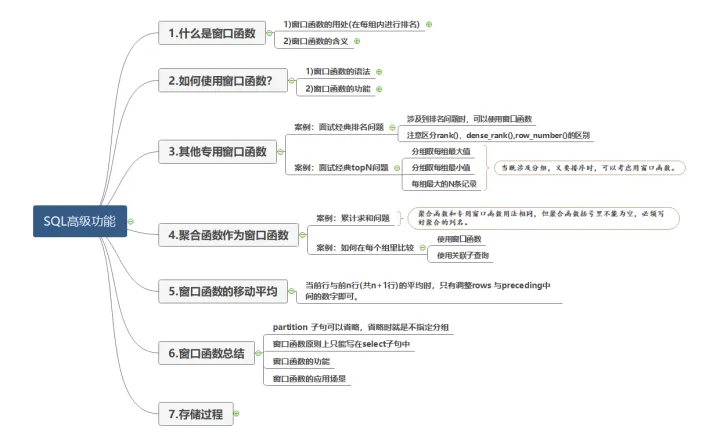
 本文详细介绍了SQL中的窗口函数,包括partitionby与groupby的区别,以及rank、dense_rank和row_number等专用窗口函数的用法。同时,文章讨论了如何使用窗口函数解决排名和topN问题,并举例说明了存储过程的概念和应用,包括无参数、有参数和默认参数的存储过程定义与调用。
本文详细介绍了SQL中的窗口函数,包括partitionby与groupby的区别,以及rank、dense_rank和row_number等专用窗口函数的用法。同时,文章讨论了如何使用窗口函数解决排名和topN问题,并举例说明了存储过程的概念和应用,包括无参数、有参数和默认参数的存储过程定义与调用。
转载于:SQL高级功能:窗口函数、存储过程及经典排名问题、topN问题等 2323- 知乎
本篇文章主要是以下内容:
1.窗口函数:
partition by窗口函数 和 group by分组的区别:
partition by关键字是分析性函数的一部分,它和聚合函数(如group by)不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录。
partition by用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组。
partition by与group by不同之处在于前者返回的是分组里的每一条数据,并且可以对分组数据进行排序操作。后者只能返回聚合之后的组的数据统计值的记录。
partition by相比较于group by,能够在保留全部数据的基础上,只对其中某些字段做分组排序(类似excel中的操作),而group by则只保留参与分组的字段和聚合函数的结果
分区函数Partition By的用法_partitionby_惊寂123的博客-CSDN博客
row_number() over(partition by … order by …)
rank() over(partition by … order by …)
dense_rank() over(partition by … order by …)
count() over(partition by … order by …) 求分组后的总数
max() over(partition by … order by …) 求分组后的最大值
min() over(partition by … order by …) 求分组后的最小值
sum() over(partition by … order by …) 求分组后的总和
avg() over(partition by … order by …) 求分组后的平均值
first_value() over(partition by … order by …) 求分组后的第一个值
last_value() over(partition by … order by …) 求分组后的最后一个值
lag() over(partition by … order by …) 取出分组后前n行数据
lead() over(partition by … order by …) 取出分组后后n行数据

1)窗口函数的基本语法如下:
<窗口函数> over ( partition by<用于分组的列名>
order by <用于排序的列名>)2)以上语法中<窗口函数>的位置,可以放置以下函数:

窗口函数是对where或者group by子句处理后的结果进行处理,所以窗口函数原则上只能写上select子句中。
2.如何使用窗口函数?
1)专用窗口函数rank。
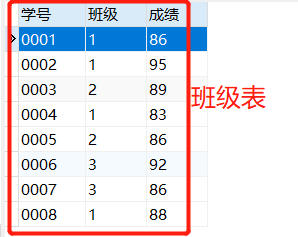
若要在每个班级内按成绩排名,则sql语句则为:
select *,
rank() over (partition by 班级
order by 成绩 desc) as ranking from 班级表;
以上sql语句中的select子句,rank是排序的函数,要求是“每个班级内按成绩排名”。这句话分为两部分理解:
a)每个班级内:按班级分组
partition by用来对表分组,在这个例子中,需要按“班级”进行分组(partition by 班级)
b)按成绩排名:
order by子句的功能是对分组后的结果进行排序,默认按升序排列,但是在本例中用了desc,表示按降序排序。
2)窗口函数已经具备了前几节中group by和order by子句的分组和排序的功能,但仍要用窗口函数是因为,group by分组汇总后改变了表的行数,一行只有一个类别,而partition by和rank函数不会减少原表中的行数。
-- group by分组汇总改变行数
select 班级,count(学号)
from 班级表
group by 班级
order by 班级;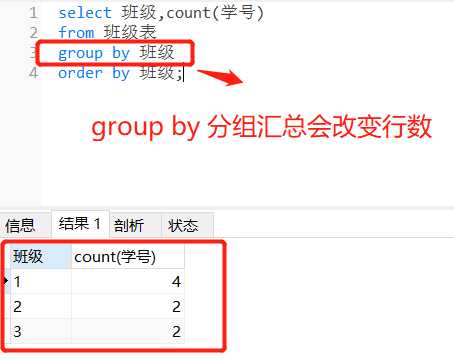
-- partition by分组汇总行数不变
select 学号,
count(学号) over (partition by 班级
order by 班级) as current_count from 班级表;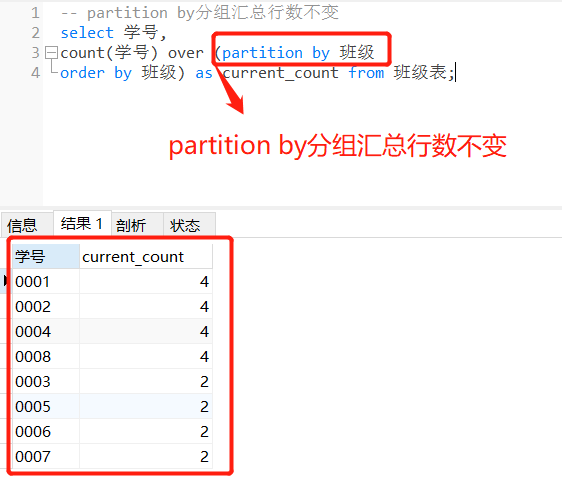
“窗口函数”之所以叫“窗口”函数,是因为partition by分组后的结果就称为“窗口”,这里的窗口是表示“范围”的意思。
3)窗口函数主要有以下功能:
a.同时具备分组和排序的功能
b.不减少原表的行数
c.语法如下:
<窗口函数> over ( partition by<用于分组的列名>
order by <用于排序的列名>)3.其他专用窗口函数
1)专用窗口函数rank,dense_rank,row_number有什么区别?
-- 专用窗口函数rank,dense_rank(),row_number的区别
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num from 班级表;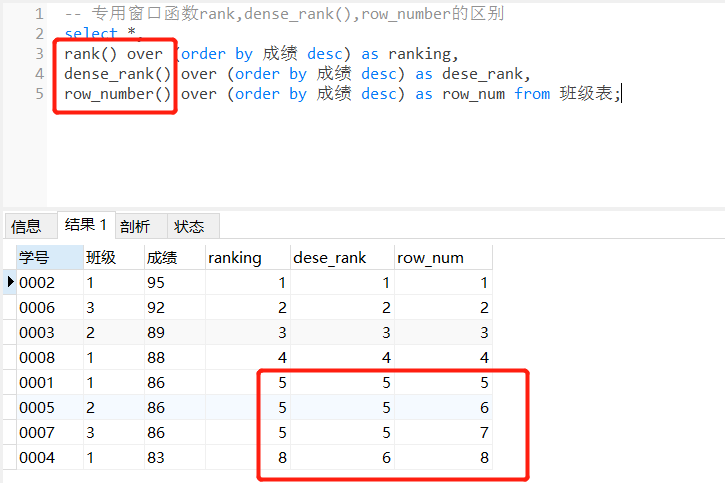
从以上结果来看:
rank()函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一个名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,所以结果是:1,1,1,4.
dense_rank()函数:这个例子中是5位,5位,5位,6位,也就是如果有并列的名次,它不会占用下一个名次的位置,比如比如正常排名是1,2,3,4,但是现在前3名是并列的名次,所以结果是:1,1,1,2.
row_number()函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列的情况,比如前3名是并列的名次,排名是正常的1,2,3,4.
最后需要注意的是,以上三个专用窗口函数,函数后面的括号不需要任何参数,保持括号()为空即可。
案例1:面试经典排名问题
当涉及到排名问题时,可以使用窗口函数,但使用窗口函数前,要注意区份rank()函数、dense_rank()函数以及row_number()函数的区别。
例子:编写一个sql查询来实现分数排名,若两个分数相同,则分数排名相同。请注意:平分后下一个名字应该是下一个连续的整数值,换句话说就是,名次之间不该有“间隔”。因此考虑用dense_rank()函数。
sql查询语句应为:
select *,
dense_rank() over (order by 成绩 desc) as dens_rank
from 班级表;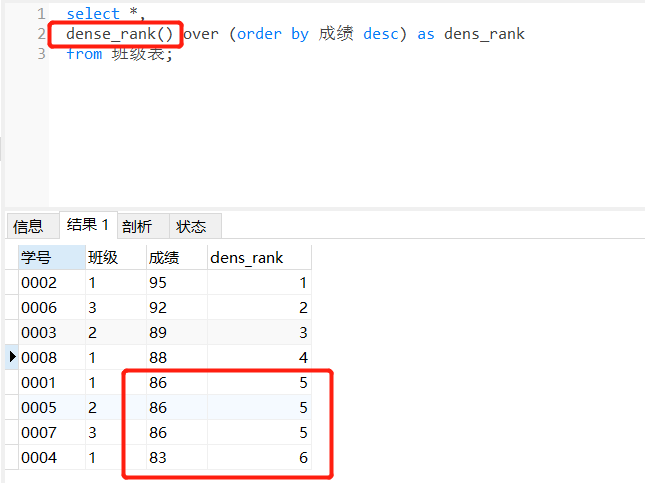
案例2:面试经典topN问题
工作中常会遇到这样的业务问题:找出每个国家中进口最多的产品是哪个?找出每个国家进口贸易前5的商品是什么?诸如此类问题,都是常见的:分组取每组最大值,最小值,每组最大的N条(top N)记录。
面对这类问题,我们将通过以下例子给出答案?
成绩表里包含了学生的学号,课程号(学生选修课程的课程号),成绩(学生选修该课程取得的成绩).
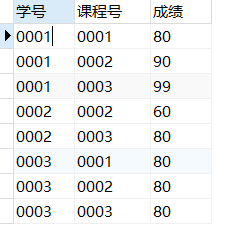
1)分组取每组最大值:按课程号分组取成绩最大值所在行的数据。
(由于分组group by和汇总函数得到的是每组的一个值(最大值,最小值或平均值),而无法得到对应那一行的所有数据,所以group by不可用)。因此我们可以使用关联子查询来实现:
select * from score as a
where 成绩=(select max(成绩) from score as b
where a.课程号=b.课程号);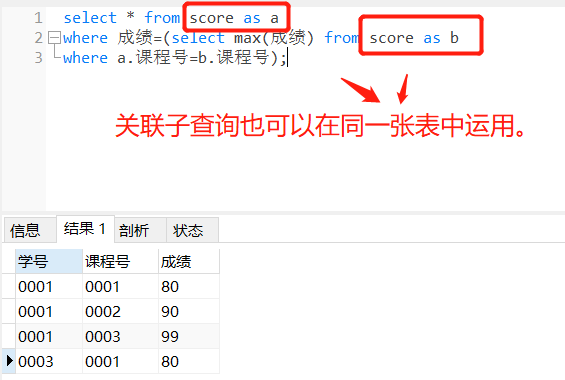
以上查询结果中课程号0001有2行数据是因为最大成绩80有2个。
2)分组取每组最小值:按课程号分组取成绩最小值所在行的数据。
select * from score as a
where 成绩=(select min(成绩) from score as b
where a.课程号=b.课程号);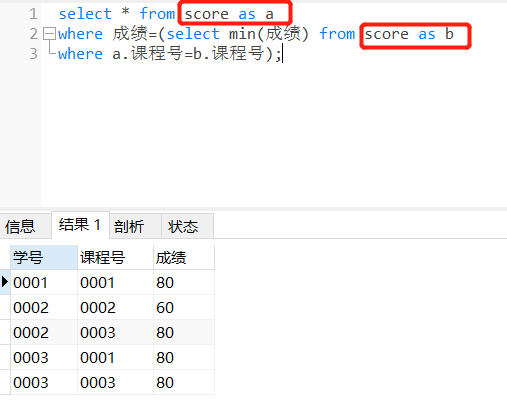
3)每组最大的N条记录:
案例:现有“进口贸易表”,记录了每个国家各商品的进口额,表内容如下。问题:查找每个国家进口额最大的2个商品。
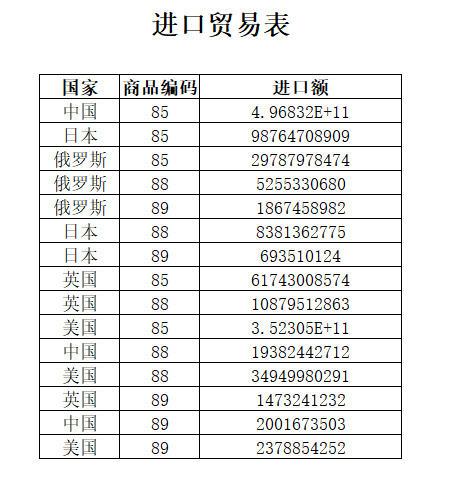
解题思路:
1.看到问题中要查找“每个”国家进口额最高的商品。当题目中出现“每个”时,首先要想到分组。这里指每个国家,所以要按国家来分组。
2.当表按国家分组后,按进口额降序排列,排在最前面2个就是我们想要查找的进口额最大的2个商品。
3.分组排序后,不能减少原表的行数,所以要用窗口函数。
4.对比各窗口函数,为不受并列进口额的影响,于是决定用row_number。
解题步骤:
步骤一:按国家分组(partition by 国家)、并按进口额降序排列(order by 进口额 desc),套入窗口函数后,sql语句为:
select *,
row_number() over (partition by 国家
order by 进口额 desc) as ranking from 进口贸易表;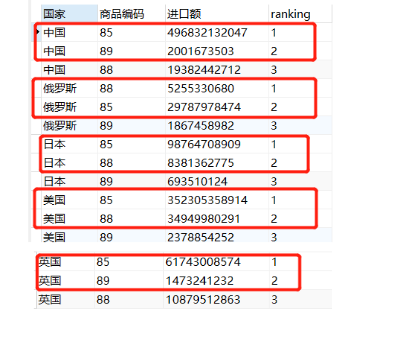
步骤二:上表中红色框框内的数据,就是每个国家进口额最大的两个商品,也就是题目的解。要想得到只有这些解的答案,只需要提取出“ranking“值小于等于2的数据即可。这时候只需要在之前的sql语句中加入条件子句where就可以了。但是这样就会报错,原因是sql的书写顺序和运行顺序不一致,在运行过程中,select语句是最后运行的。
因此不能将sql语句写成如下:
select *,
row_number() over (partition by 国家
order by 进口额 desc) as ranking from 进口贸易表
where rangking<=2;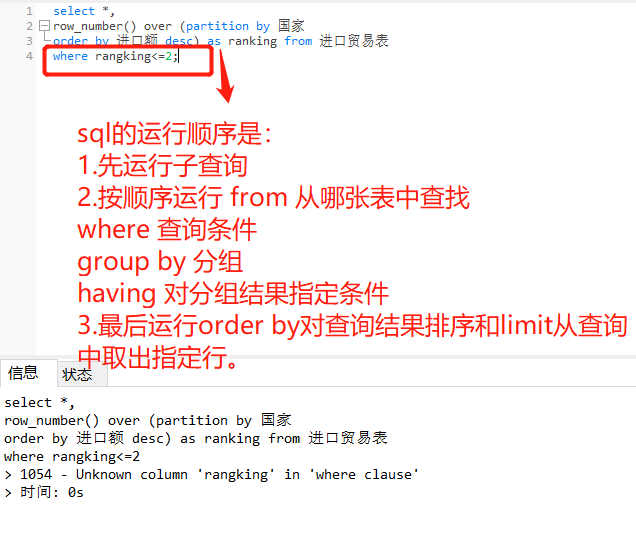
以上出错原因就是因为我们以为运行顺序是按书写顺序来运行的,这样是不对的,所以运行sql子句的时候,就会出错。运行where ranking的时候,select子句还没有运行,ranking列还未出现。
步骤三:这时候只能采用子查询,将第一步得到的查询结果作为一个新表,最后再运行where子句。
select * from
(select *, row_number() over (partition by 国家
order by 进口额 desc) as ranking from 进口贸易表) as a
where rangking<=2;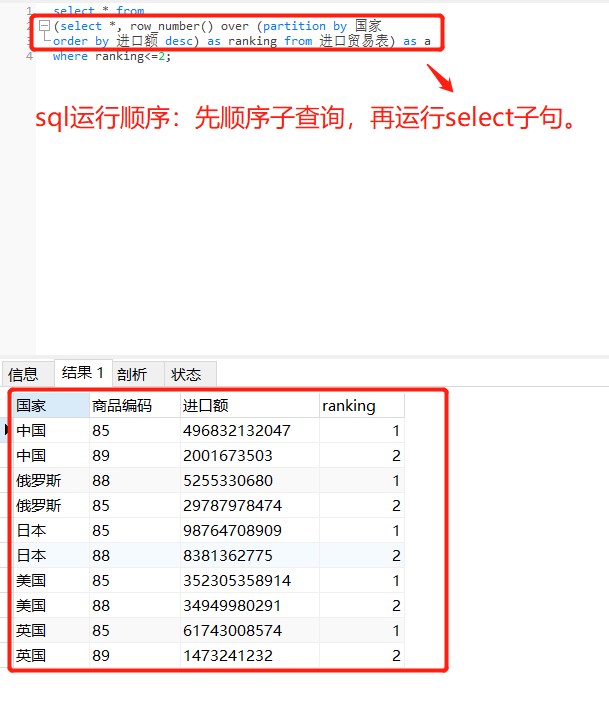
举一反三:
经典topN问题:每组最大的N条记录。这类问题既涉及分组,又涉及排序,这时候要用窗口函数来实现,这时候只需要将where子句中的2改成N即可。
select * from
(select *, row_number() over (partition by 要分组的列名
order by 要排序的列名 desc) as ranking from 表名) as a
where rangking<=N;4.聚合函数作为窗口函数
聚合函数作为窗口函数和专用窗口函数用法相同,只需要把聚合函数写在窗口函数的位置即可,但聚合函数括号里不能为空,必须写好聚合的列名。
select *,
sum(成绩) over ( partition by 课程号 order by 学号) as current_sum,
avg(成绩) over (partition by 课程号 order by 学号) as current_avg,
max(成绩) over (partition by 课程号 order by 学号) as current_max,
min(成绩) over (partition by 课程号 order by 学号) as current_min,
count(成绩) over (partition by 课程号 order by 学号) as current_count
from score;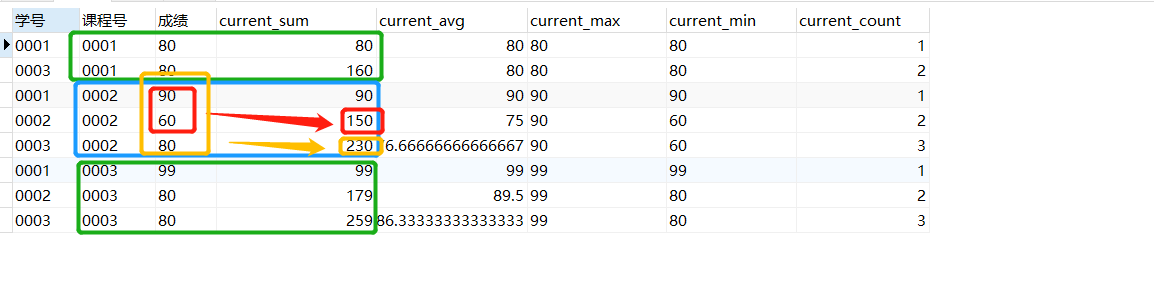
如上图,聚合函数sum在窗口函数中,对自身记录以及位于自身以上的数据进行求和,如课程号0002对应的学号0002后面的sum结果就是课程号0002中学号为0001和0002对应的成绩之和,课程号0002对应的学号0003后面的sum结果就是课程号0002中学号0001、0002和0003对应的成绩之和。除此之外,avg()、max()、min()等聚合函数作为窗口函数时,结果都与sum()函数类似。
这样使用窗口函数的用处是:聚合函数作为窗口函数,可以在每一行的数据里直观看到,截止到本行数据,统计数据有多少,最大值、最小值是多少等,从而可以看出每一行数据,对整体数据的影响。
举例:累计求和问题
下表为确诊人数表,包含日期和该日期对应的新增确诊人数,
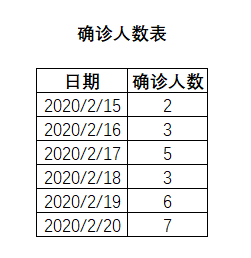
按照日期进行升序排列,查找日期,确诊人数以及对应的累计确诊人数。
select 日期,确诊人数,
sum(确诊人数) over(order by 日期) as 累计确诊人数
from 确诊人数表;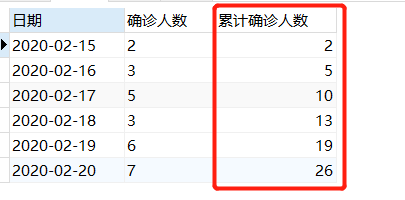
案例:如何在每个组里比较
题目:现有进口贸易表,记录了每个国家各商品的进口额,表内容如下:
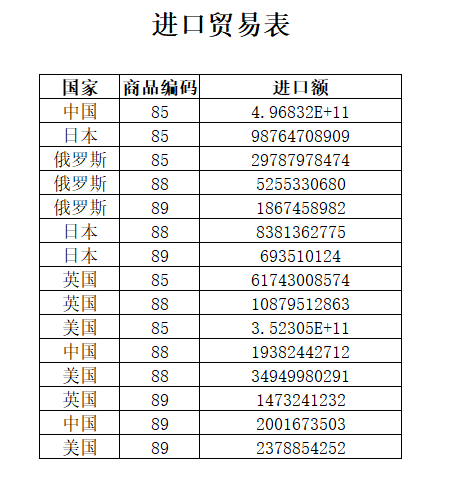
问题:查找单个商品进口额高于该商品平均进口额的国家名单。
解题思路:
1.查找单个商品高于该商品平均进口额,也就是要在每个商品里比较,这就涉及到分组,而sql中有分组功能的就:group by和窗口函数partition by。
2.使用聚合函数avg()求出每个商品的平均进口额后,找出进口额大于平均进口额的数据。并且要求分组后不减少原表的行数。
3.由于group by分组汇总后会改变表的行数,一行只有一个类别,而partition by不会减少原表行数,因此用partition by。
解题步骤:
1.将avg()作为窗口函数,将每个商品的平均进口额求出。
select *,
avg(进口额) over (partition by 商品编码 ) as 平均进口额
from 进口贸易表;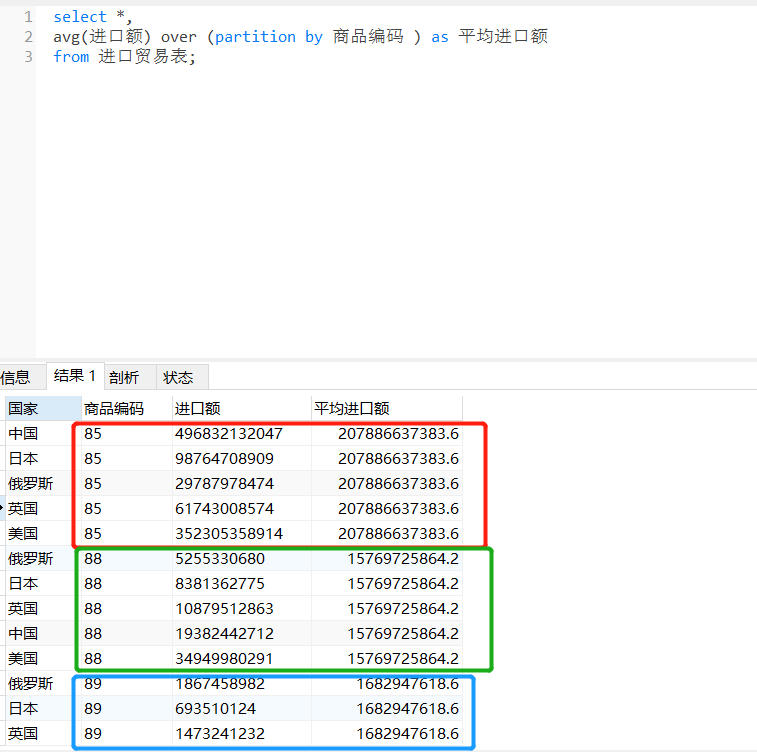
2.在第1步的基础上,筛选出大于平均进口额的数据即可。这时,就需要在上一步的sql语句中加入条件子句where即可。在写sql子句前,要注意sql的书写顺序与运行顺序。
select *
from (select *,
avg(进口额) over (partition by 商品编码 ) as 平均进口额
from 进口贸易表) as b
where 进口额>平均进口额;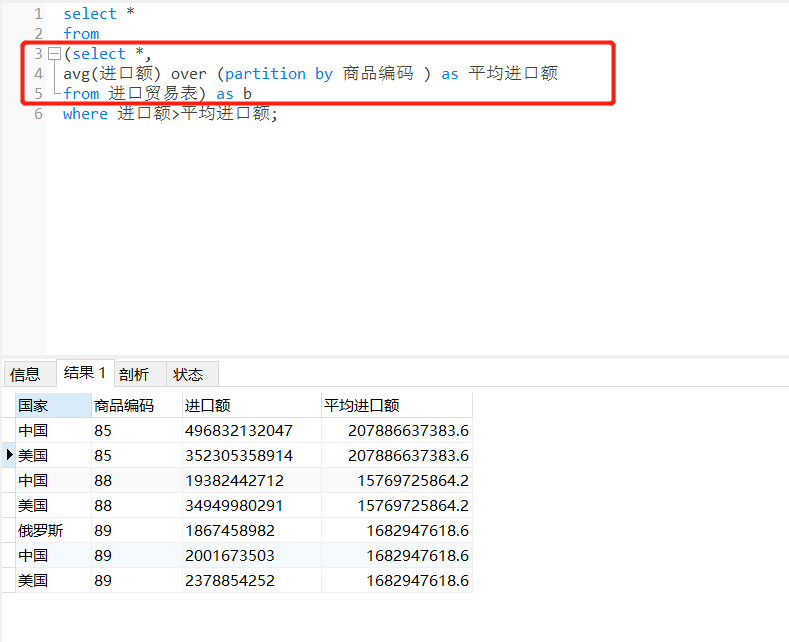
举一反三:
查找每个组里大于平均值的数据,可以有两种方法:
1)使用以上的窗口函数
2)使用关联子查询。
5、窗口函数的移动平均
select *,
avg(成绩) over (order by 学号 rows 2 preceding) as current_avg
from score;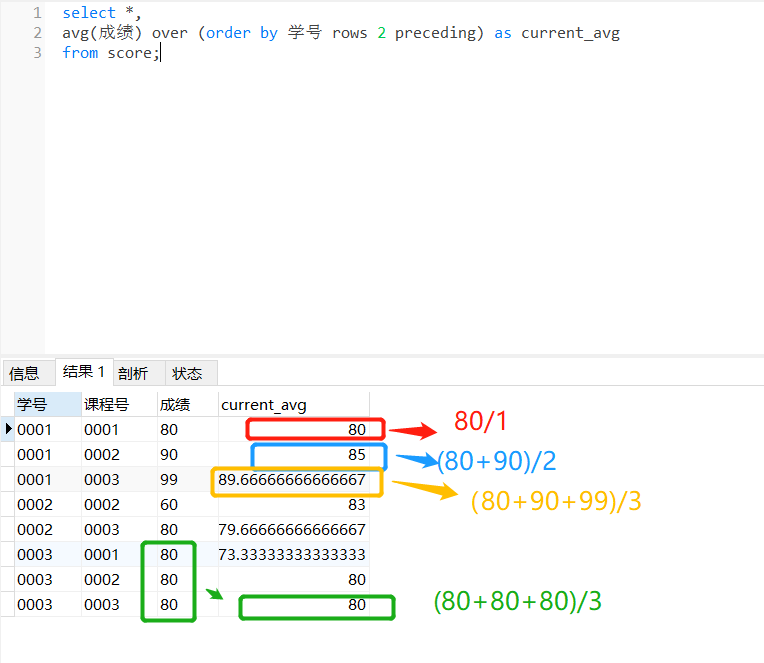
以上窗口函数,用了rows和preceding这两个关键字,是“之前~行“的意思,在上面也就是之前2行的意思,也就是得到的结果是自身记录及前2行的平均。
例如学号0002、课程号0002成绩60的结果为:学号0001课程号0002和学号0001课程号0003以及学号0002、课程号0002对应的三个成绩的平均值。也就是学号0002课程号0002这位以及其前两行同学的平均成绩。
想要计算当前行与前n行(共n+1行)的平均时,只有调整rows 与preceding中间的数字即可。这样使用窗口函数注意是可以通过preceding关键字调整作用范围,在以下的场景中非常适用:
在公司业绩名单排名中,可以通过移动平均,直观地查看与相邻名次业绩的平均、求和等统计数据。
6.窗口函数总结
1)注意事项:
partition 子句可以省略,省略时就是不指定分组,且窗口函数原则上只能写在select子句中
2)窗口函数语法:
select *
<窗口函数> over (partition by <分组的列名> order by <排序的列名>)
as <自己定义的列名> from 从哪张表中查找;其中窗口函数的位置可以放:
a.专用窗口函数:rank()、dense_rank()、row_number等。
b.聚合函数:sum()、avg()、max()、min()等。
3)窗口函数的功能:
a.同时具备分组partition by和排序order by的功能。
b.不减少原表的行数,所以经常用来在每组内排名。
4)窗口函数使用场景:

7、触发器
触发器概念:触发器是一种特殊的存储过程,它在试图更改触发器所保护的数据时自动执行。
触发器与存储过程的异同
相同点:1. 触发器是一种特殊的存储过程,触发器和存储过程一样是一个能够完成特定功能、存储在数据库服务器上的SQL片段。
不同点:2. 存储器调用时需要调用SQL片段,而触发器不需要调用,当对数据库表中的数据执行DML操作时自动触发这个SQL片段的执行,无需手动调用。
MySQL的触发器_mysql触发器_莱维贝贝、的博客-CSDN博客
8.存储过程。
MySQL中的存储过程(详细篇)_mysql存储过程学习_普通网友的博客-CSDN博客(学习该博客)
1)在工作中经常遇到重复性的工作,这时候就可以把常用的sql写好存储起来,这个过程就是存储过程。这样下次遇到同样的问题,就可以直接使用存储过程了,这样就可以极大地提高工作效率。
2)如何使用存储过程?
使用存储过程需要先定义存储过程,然后是使用已经定义好的存储过程。
a.无参数的存储过程。
定义存储过程的语法形式:
create procedure 存储过程名称() begin <sql语句> ;end;语法中的begin……end用于表示sql语句的开始和结束。语法中的sql语句就是重复的sql语句。
举个例子:查找进口贸易表中的国家名称。
sql语句就是:
select 国家from 进口贸易表;把这个sql语句放入存储过程的语法里,并给这个存储过程起名叫a_trade1:
create procedure a_trade1 ()
begin select 国家from 进口贸易表;end;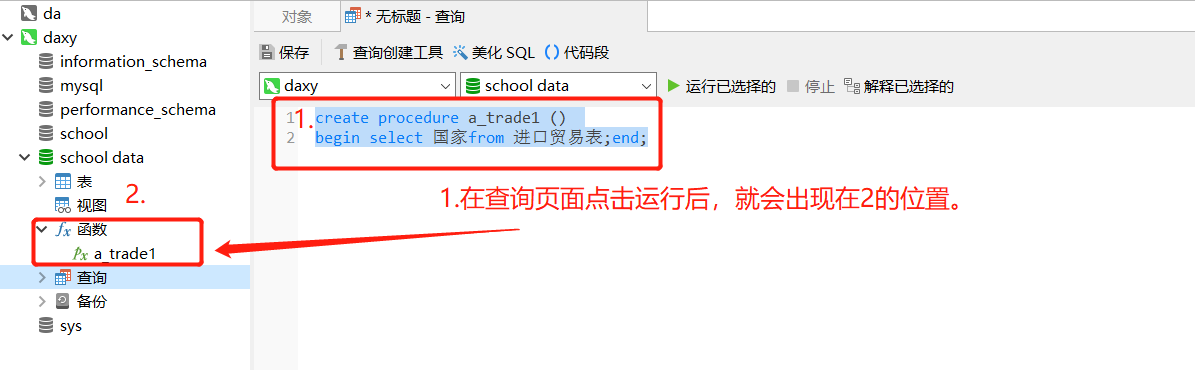
在navicat-查询中运行后,建立的存储过程就会出现在以上位置,这样下次就可以用以下的sql语句直接使用了,就不用另外再写一次sql语句了。
call 存储过程名();
如:call a_trade1 ();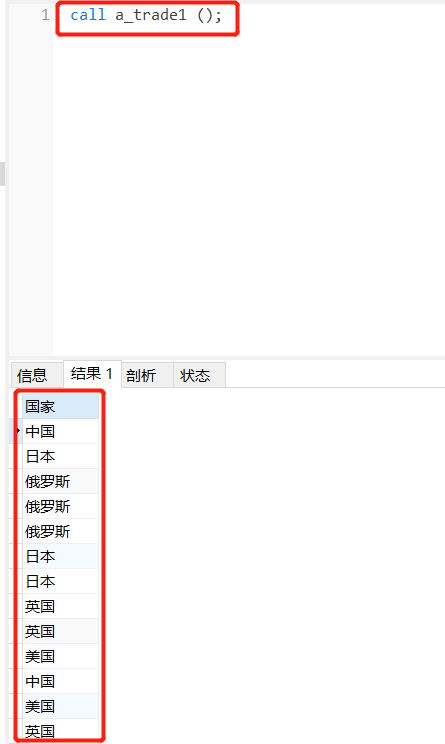
b.有参数的存储过程:
a.中的存储过程名称后是(),括号里没有参数,当括号有参数时,就是以下的语法:
create procedure 存储过程名称(参数1,参数2,…) begin <sql语句>;end;例如:要在进口贸易表中查找指定商品编码的国家有哪些?如果指定商品编码为88,那么sql语句是:
select 国家 from 进口贸易表 where 商品编码=88;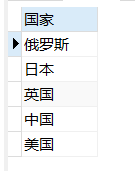
在实际工作中,有时候并不能一次就能指定国家是哪个,有时候业务需要指定国家为中国,有时候需要指定成美国,这个时候就需要参数,来灵活应对这种情况。这时候把sql放入存储过程就是:
create procedure getNum2(num varchar(100))
begin select 国家 from 进口贸易表 where 商品编码=num;end;其中getNum2是存储过程的名称,后面括号里面的num varchar(100)是参数,参数由两部分组成,参数名称是num;参数类型是varchar(100);这里表示字符串类型。存储过程里面的sql语句(where 商品编码=num)使用了这个参数num,这样在使用存储过程时,给定参数值就可以灵活地运用了。
比如现在要查商品编码是89的国家名称,那么就可以在使用存储过程的参数来实现了,也就是下面括号里的89.
call getNum2(89);
c.默认参数的存储过程*
前面的存储过程名称后是(参数1,参数2,…),括号里面只包含了参数的类型和名称,方便调用。其实存储过程还包含了一种情况,就是存在默认参数的情况。
in输入参数:
参数初始值在存储过程前被指定为默认值,在存储过程中修改该参数的值不能被返回。
set @num=0;-- 初始化参数
-- 初始化存储过程
create procedure in1(in num int)
begin
select num;
set num=1;
select num;
end;
-- in参数调用
call in1(@num);
select num;
out输出参数:
参数初始值为空,该值可在存储过程内部被改变,并可返回。
set @num=0;-- 初始化参数
-- 初始化存储过程
create procedure out1(out num int)
begin
select num;
set num=1;
select num;
end;
-- out参数调用
call out1(@num);
select num;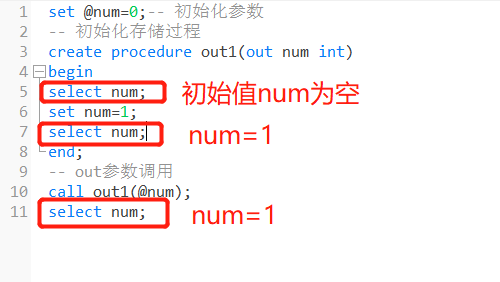
inout输入输出参数:
参数初始值在存储过程前被指定为默认值,并且可在存储过程中被改变和在调用完毕后可被返回。
set @num=0;-- 初始化参数
-- 初始化存储过程
create procedure inout1(inout num int)
begin
select num;
set num=1;
select num;
end;
-- inout参数调用
call inout1(@num);
select num;
3)注意事项
a.定义存储过程语法里的sql语句代码块必须是完整的sql语句,必须用分号;结尾。
create procedure 存储过程名称(参数1,参数2,…) begin <sql语句>;end;b.定义不同的存储过程,要用不同的存储过程名称,相同的存储过程名字会引起系统报错。
9、WITH 语句
WITH 子句提供了一种编写辅助语句的方法,以便在更大的查询中使用。
WITH 子句有助于将复杂的大型查询分解为更简单的表单,便于阅读。这些语句通常称为通用表表达式(Common Table Express, CTE),也可以当做一个为查询而存在的临时表。
SQL常用语法( WITH 语句)_sql with-CSDN博客
with as 和with recursive 用法_with recursive as-CSDN博客

















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









