






 该博客主要介绍如何从起点小说网获取小说目录和章节网址。通过搜索小说,利用开发者工具找到JSON数据源,解析获取章节信息,并构建小说章节的网址。虽然VIP资源后期被封锁,但提供了继续下载的可能性。
该博客主要介绍如何从起点小说网获取小说目录和章节网址。通过搜索小说,利用开发者工具找到JSON数据源,解析获取章节信息,并构建小说章节的网址。虽然VIP资源后期被封锁,但提供了继续下载的可能性。
小说目录和网址的获取
进入官网,点击输入书名,点击搜索,进入免费试读。
打开开发者工具,刷新页面,找到小说目录json格式对应的网址
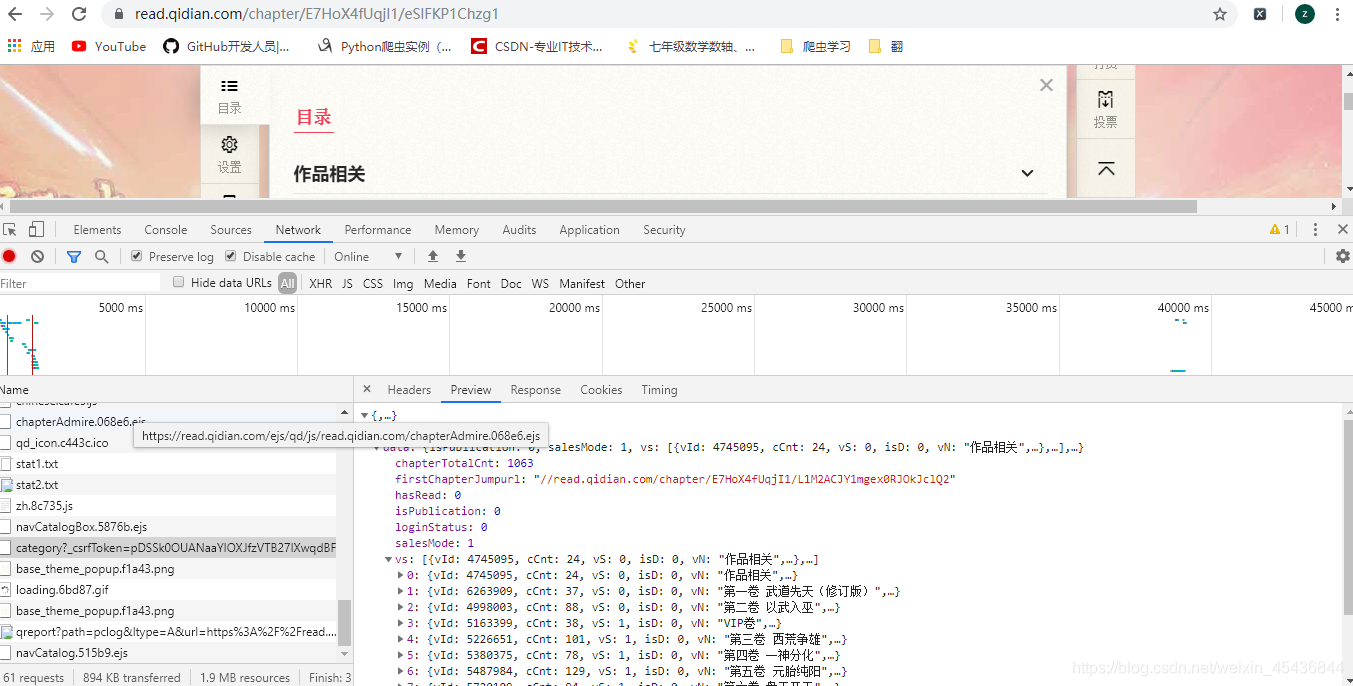
先获取json格式的数据
url = 'https://read.qidian.com/ajax/book/category?_csrfToken=pDSSk0OUANaaYIOXJfzVTB27IXwqdBF2qx0MEBqe&bookId=1924072'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0', }
response = requests.get(url=url, headers=headers)
# 用原编码格式,防止乱码
response.encoding = response.apparent_encoding
novel_json = json.loads(response.text)
然后获取json中小说对应的章节以及内容所对应的部分网址并构建小说的网址并保存到本地
# 此书一共10卷,若没有VIP限制则可全部下载,获取每一卷的章节及部分网址
for i in range(1, 11):
chapters_info = novel_json['data']['vs'][i]['cs']
for item in chapters_info:
ids = item['cU']
name = item['cN']
url = 'https://read.qidian.com/chapter/'
url = url + ids
response = requests.get(url=url, headers=headers)
response.encoding = response.apparent_encoding
html = etree.HTML(response.text)
contents = html.xpath('//*[@class="text-wrap"]/div/div[2]/p/text()')
length = len(contents)
content = ''
for p in range(length):
content = content + contents[p]
content.replace('\u3000\u3000', '')
print(content)
chapter = name + '\n' + content + '\n'
with open('独步天下.txt', 'a') as f:
f.write(chapter)
效果图如下
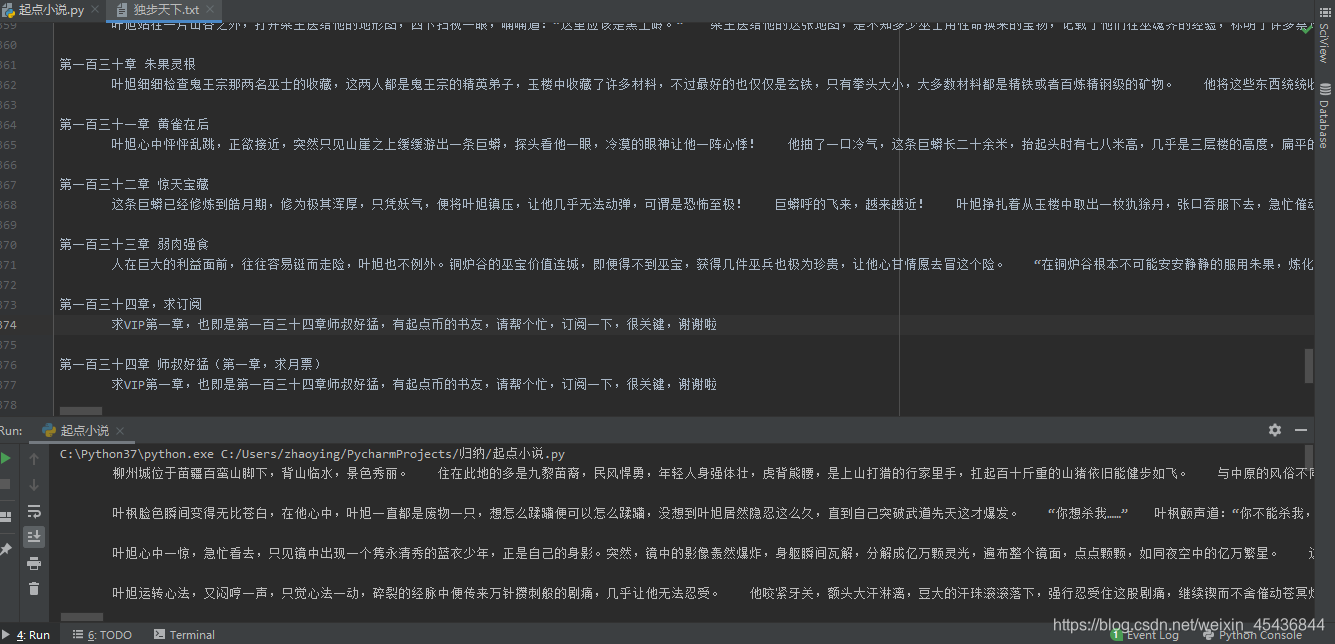
下载前两卷后,vip资源已被封锁,不过可以从小网站下载。

















 6516
6516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









