






目录
仅为个人练习ACM使用,题目来源:牛客笔试
1.1 修改字符串
1. 三个同样的字母连在一起,一定是拼写错误,去掉一个的就好啦:比如 helllo -> hello
2. 两对一样的字母(AABB型)连在一起,一定是拼写错误,去掉第二对的一个字母就好啦:比如 helloo -> hello
3. 上面的规则优先“从左到右”匹配,即如果是AABBCC,虽然AABB和BBCC都是错误拼写,应该优先考虑修复AABB,结果为AABCC
n = int(input())
for i in range(n):
s = input()
temp = ""
for i in range(len(s)):
if i >= 2 and s[i] == s[i - 1] and s[i - 1] == s[i - 2]:
continue
else:
temp += s[i]
res = ""
i = 0
while i < len(temp):
if (
len(temp) >= i >= 3
and temp[i] == temp[i - 1]
and temp[i - 2] == temp[i - 3]
):
if i + 4 < len(temp):
res += temp[i + 1 : i + 4]
elif i + 4 >= len(temp):
res += temp[i + 1 :]
i += 4
continue
else:
res += temp[i]
i += 1
print(res)
1.2 特工埋伏
1. 两个特工不能埋伏在同一地点
2. 三个特工是等价的:即同样的位置组合( A , B , C ) 只算一种埋伏方法,不能因“特工之间互换位置”而重复使用
第一行包含空格分隔的两个数字 N和D(1 ≤ N ≤ 1000000; 1 ≤ D ≤ 1000000) 第二行包含N个建筑物的的位置,每个位置用一个整数(取值区间为[0, 1000000])表示,从小到大排列(将字节跳动大街看做一条数轴)
输入例子:
4 3 1 2 3 4
输出例子:
4
例子说明:
可选方案 (1, 2, 3), (1, 2, 4), (1, 3, 4), (2, 3, 4)
n, d = map(int, input().split())
nums = list(map(int, input().split()))
i = 0 # 第一个特工的位置索引
j = 2 # 第三个特工的位置索引(从第三个位置开始搜索)
res = 0 # 结果变量,记录符合条件的组合数
while i < n - 2:# 外层循环,i 控制第一个特工的位置范围
while j < n and nums[j] - nums[i] <= d:# 内层循环,j 找到满足条件的第三个特工的位置
j += 1
if j - 1 - i >= 2:# 如果存在第二个特工
# 计算符合条件的特工组合数量
num = j - i - 1
# 计算在满足条件的 num 个建筑物中选择任意两个建筑物的组合数
res += num * (num - 1) // 2
i += 1
res = res % 99997867
print(res)
1.3 雀魂
小包最近迷上了一款叫做雀魂的麻将游戏,但是这个游戏规则太复杂,小包玩了几个月了还是输多赢少。
于是生气的小包根据游戏简化了一下规则发明了一种新的麻将,只留下一种花色,并且去除了一些特殊和牌方式(例如七对子等),具体的规则如下:
- 总共有36张牌,每张牌是1~9。每个数字4张牌。
- 你手里有其中的14张牌,如果这14张牌满足如下条件,即算作和牌
- 14张牌中有2张相同数字的牌,称为雀头。
- 除去上述2张牌,剩下12张牌可以组成4个顺子或刻子。顺子的意思是递增的连续3个数字牌(例如234,567等),刻子的意思是相同数字的3个数字牌(例如111,777)
例如:
1 1 1 2 2 2 6 6 6 7 7 7 9 9 可以组成1,2,6,7的4个刻子和9的雀头,可以和牌
1 1 1 1 2 2 3 3 5 6 7 7 8 9 用1做雀头,组123,123,567,789的四个顺子,可以和牌
1 1 1 2 2 2 3 3 3 5 6 7 7 9 无论用1 2 3 7哪个做雀头,都无法组成和牌的条件。
现在,小包从36张牌中抽取了13张牌,他想知道在剩下的23张牌中,再取一张牌,取到哪几种数字牌可以和牌。
1.4 多少种硬币
找零,贪心
Z国的货币系统包含面值1元、4元、16元、64元共计4种硬币,以及面值1024元的纸币。现在小Y使用1024元的纸币购买了一件价值为𝑁(0<𝑁≤1024)N(0<N≤1024)的商品,请问最少他会收到多少硬币?
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 32M,其他语言64M
输入描述:
一行,包含一个数N。
输出描述:
一行,包含一个数,表示最少收到的硬币数。
n = int(input())
m = 1024
target = m - n
res = 0
while target >= 64:
target -= 64
res += 1
while target >= 16:
target -= 16
res += 1
while target >= 4:
target -= 4
res += 1
while target >= 1:
target -= 1
res += 1
print(res)1.5 图片特征提取
小明是一名算法工程师,同时也是一名铲屎官。某天,他突发奇想,想从猫咪的视频里挖掘一些猫咪的运动信息。为了提取运动信息,他需要从视频的每一帧提取“猫咪特征”。一个猫咪特征是一个两维的vector<x, y>。如果x_1=x_2 and y_1=y_2,那么这俩是同一个特征。
因此,如果喵咪特征连续一致,可以认为喵咪在运动。也就是说,如果特征<a, b>在持续帧里出现,那么它将构成特征运动。比如,特征<a, b>在第2/3/4/7/8帧出现,那么该特征将形成两个特征运动2-3-4 和7-8。
现在,给定每一帧的特征,特征的数量可能不一样。小明期望能找到最长的特征运动。
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 32M,其他语言64M
输入描述:
第一行包含一个正整数N,代表测试用例的个数。 每个测试用例的第一行包含一个正整数M,代表视频的帧数。 接下来的M行,每行代表一帧。其中,第一个数字是该帧的特征个数,接下来的数字是在特征的取值;比如样例输入第三行里,2代表该帧有两个猫咪特征,<1,1>和<2,2> 所有用例的输入特征总数和<100000 N满足1≤N≤100000,M满足1≤M≤10000,一帧的特征个数满足 ≤ 10000。 特征取值均为非负整数。
输出描述:
对每一个测试用例,输出特征运动的长度作为一行
示例1
输入例子:
1 8 2 1 1 2 2 2 1 1 1 4 2 1 1 2 2 2 2 2 1 4 0 0 1 1 1 1 1 1
输出例子:
3
例子说明:
特征<1,1>在连续的帧中连续出现3次,相比其他特征连续出现的次数大,所以输出3
x = int(input())
for i in range(x):
dic = {}
n = int(input())
nums = []
# n= 8
tezheng_list = {}
for _ in range(n):
nums = list(map(int, input().split()))
for j in range(1,nums[0] + 3,2):
tezheng = tuple(nums[j:j + 2])
if tezheng in tezheng_list:
tezheng_list[tezheng].append(_ + 1)
else:
tezheng_list[tezheng] = [_ + 1]
res = 1
for key, value in tezheng_list.items():
if not key:
continue
dp = [0 for _ in range(len(value))]
dp[0] = 1
for j in range(1, len(value)):
if value[j] - value[j - 1] == 1:
dp[j] = dp[j - 1] + 1
else:
dp[j] = 1
if dp[j] > res:
res = dp[j]
print(res)
1.6 完美矩阵

(1)前缀和通过9/30,
二维数组前缀和:
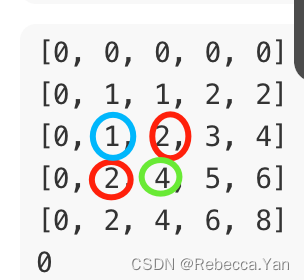
红色➕红色➖蓝色➕绿色位置的原数组数,就是以绿色为右下角矩形的前缀和
n = int(input())
matrix = [[] for _ in range(n)]
for i in range(n):
s = input()
for c in s:
matrix[i].append(int(c))
# print(nums)
prefix_sum = [[0] * (n + 1) for _ in range(n + 1)]
# 计算前缀和
for i in range(1, n + 1):
for j in range(1, n + 1):
# 使用前缀和公式计算当前位置的值
prefix_sum[i][j] = prefix_sum[i - 1][j] + prefix_sum[i][j - 1] - prefix_sum[i - 1][j - 1] + matrix[i - 1][j - 1]
result = []
# 检查每个可能的正方形区域
for i in range(1, n + 1):
# 初始化当前边长的正方形中完美矩形的数量
count = 0
# 如果矩阵大小为odd*odd那么完美矩阵一定为0
if i % 2 == 1:
print(count)
continue
# 遍历所有可能的正方形左上角的x,y坐标
for x in range(n - i + 1):
for y in range(n - i + 1):
# 使用前缀和数组计算当前正方形内1的数量
ones = prefix_sum[x + i][y + i] - prefix_sum[x][y + i] - prefix_sum[x + i][y] + prefix_sum[x][y]
# 计算0的数量(即正方形面积减去1的数量)
zeros = i * i - ones
# 如果0和1的数量相等,则增加计数
if ones == zeros:
count += 1
print(count)


n, m, q = map(int, input().split())
a_dic = {i:[] for i in range(1, n + 1)}
for _ in range(m):
i, j = map(int, input().split())
a_dic[i].append(j)
a_dic[j].append(i)
# 递归实现dfs
def dfs(m, visited, graph):
# print(f"Visiting node {m}")
visited[m] = True
for neibor in graph[m]:
if not visited[neibor]:
dfs(neibor, visited, graph)
for _ in range(q):
choose, i, j = map(int, input().split())
# print(a_dic)
if choose == 1 and i in a_dic[j]:
a_dic[j].remove(i)
a_dic[i].remove(j)
if choose == 2:
visited = [False for _ in range(len(a_dic) + 1)]
dfs(i, visited, a_dic)
if visited[j]:
print("Yes")
else:
print("No")

n, k = map(int, input().split())
a = list(map(int, input().split()))
pre = []
for i in range(len()):
pre.append(num *= num)
res = 0
for i in range(n):
for j in range(i, n):
temp = 1
while i <= j:
temp = temp * a[j]
j -= 1
s = str(all_chengji // temp) #.rstrip('0').rstrip('.')
# print(s)
if len(s) > k and s[-k:] == '0'*k:
res += 1
continue
print(res)

















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











